
Ông Toằn Vi Lốc - Ứng dụng Deep Learning tự động tạo kho nhạc beat karaoke siêu to khổng lồ
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các cháu, lại là ông dây. Ở bài trước các cháu đã cùng ông thử nghiệm làm một series truyện ma siêu to khổng lồ rồi phải không nào. Hi vọng các cháu có thể áp dụng nó để thực hiện được những chuỗi truyện kinh dị siêu siêu chất nhé. Quảng cáo sương sương cho bài viết cũ vậy thôi chứ các cháu nghe nhiều truyện ma quá cũng đến lúc cần phải giải trí phải không nào. Hôm nay ông sẽ hướng dẫn các cháu làm một trò rất tiêu khiển liên quan đến đam mê ca hát của mỗi chúng ta đó chính là Dùng Deep Learning tự động tạo beat nhạc để hát karaoke.

Ý tưởng của bài blog này thì cũng xuất phát từ nhu cầu hát hò của rất nhiều các cháu thôi. Với những cháu nào hay hát hò, đặc biệt là hát karaoke thì hẳn là các cháu sẽ gặp những trường hợp như sau:
- Cháu A rất thích bài hát Thêm một lần đau và dự định sẽ hát tặng người con gái ấy trong ngày tỏ tình nhưng khi search beat karaoke trên mạng thì lại khác hẳn với bản beat nhạc mà ca sĩ đang hát => hát không hay => người con gái ấy đi theo một người khác => Thêm một lần đau
- Cháu B rất thích hát nhạc của thằng bán gà - 5S Online và cháu ấy rất đam mê thứ âm nhạc của bộ tộc cà to nhà thằng bán gà nhưng ngặt một nỗi không có một ông nhạc công nào bỏ công sức ra để làm beat nhạc cho cháu đó hát chỉ vì sợ thằng bán gà lại lừa và chê mình là đồ nhà quê => cháu không thỏa đam mê ca hát của mình chỉ vì không có beat nhạc.
- Cháu C là một người nhạc công chuyên đi mix nhạc cho người ta với mỗi một bản karaoke muốn ra lò cháu phải ngồi hàng vài giờ đồng hồ với dống phần mềm và phải hiểu rất nhiều các khái niệm về nhạc lý. Cháu cảm thấy công việc đó rất nhàm chán hơn rất nhiều so với việc ngồi đọc blog của Ông Toằn Vi Lốc.
- Và còn khá nhiều các trường hợp, vân vân và mây mây nữa
Nếu các cháu thấy mình là một trong số các trường hợp kể trên thì đây là bài viết dành cho các cháu. Trong bài viết này ông sẽ hướng dẫn các cháu sinh trực tiếp beat của bài hát từ bản thu âm. phối khí hoàn chỉnh của bài hát đó. Ông làm vì chia sẻ thôi chứ không phải vì tiền đâu nên các cháu nhớ UPVOTE, CLIP và chia sẻ thật nhiều cho ông để ông có dộng lực ra những bài tiếp theo nhé. OK giờ chúng ta bắt đầu thôi nào
Tổng quan bài toán
Để giải quyết bài toán này chúng ta có thể thực hiện theo hai hướng tiếp cận ông tạm gọi là góc nhìn của Mixer và góc nhìn của AI Engineer
Từ góc nhìn của người mixer
Với các chuyên gia mix nhạc đang đọc bài viết này thì chắc không còn xa lạ gì rồi phải không nào. Để ông nói sơ qua một chút về cách mix nhạc nhé. Bản chất của bài hát của chúng ta là việc trộn (mix) các track âm thanh lại với nhau, trong đó có các track quan trọng như âm thanh nhạc cụ, trống, kèn, sáo ... và giọng hát (vocal) của ca sĩ. Tất cả các âm thanh đó được vang lên cùng một thời điểm tạo thành bài hát của chúng ta. Khi thu âm người ta sẽ thu riêng từng track nhạc một và mix chúng lại với nhau theo các hiệu ứng âm thanh nhất định (cái này cháu nào chuyên gia hát rap tặng người yêu chắc là rõ hơn ông nhiều. Việc mix chúng lại với nhau thì đơn giản nhưng việc làm người lại tức là từ bài hát đã được mix sẵn để khôi phục lại các track trước khi mix thì không hề đơn giản chút nào đâu các cháu ạ. Nó giống như hồi xưa cô nàng Lọ Lem bị dì ghẻ bắt ngồi nhặt thóc và gạo riêng ra từng đống ý các cháu ạ.

Với một người mixer thì việc này có thể được thực hiện bằng một vài phần mềm thu âm có chức năng xoá vocal ra khỏi bài hát như Audacity các cháu có thể tham khảo ở đây. Ông thì không đi quá sâu vào phần này nhé, các cháu cứ xem video và làm theo thôi. Và cách làm này có một số ưu điểm và nhược điểm dưới đây các cháu ạ.
Ưu điểm
- Dễ dàng thực hiện, không cần biết về kĩ thuật, chỉ xem video, đọc tutorial hướng dẫn là làm được
- Không cần hiểu về bản chất của âm thanh vì đã có tool rồi
Nhược điểm
- Với mỗi một bài nhạc khác nhau đều phải tinh chỉnh các tham số một cách thủ công, không có một bộ tham số cố định cho các bài hát
- Chỉ có thể xoá được vocal và một vài loại nhạc cụ phổ biến. Muốn tách riêng âm thanh của từng loại nhạc cụ hoặc vocal thì sẽ rất khó khăn
- Thời gian thực hiện lâu, tốn thời gian thay đổi các tham số
- Phụ thuộc rất nhiều vào cách cảm âm và kinh nghiệm của người tiến hành
Từ góc nhìn của AI Engineer
Đứng từ góc nhìn của những người làm AI thì ông cháu ta sẽ nhìn nhận bài toán này theo một hướng khác. Và tư duy của một người làm về AI đều phải dựa trên bản chất của dữ liệu. Nếu như các cháu chưa hiểu được bản chất của dữ liệu thì các cháu sẽ không biết nên lựa chọn mô hình nào cho đúng, chọn phương pháp nào cho phù hợp với bài toán hiện tại của chúng ta. Cùng đi sâu một chút nhé cac cháu, yêu cầu của chúng ta là từ file âm thanh đầu vào và bằng một cách nào đó tách riêng ra được các thành phần như trống, kèn, sáo giọng hát .... Chúng ta sẽ nghĩ ngay đến việc cần phải có một tập dữ liệu với đầu vào là một file audio và đầu ra tương ứng là audio chỉ chứa riêng phần giọng hát hoặc phần beat tương ứng với audio lúc đầu. Vậy ở giữa nó là gì các cháu nhỉ, các cháu lại phải xây dựng các mô hình AI để tiến hành việc trích chọn đó. Chúng ta có thể hình dung đầu vào và đầu ra của phương pháp này qua hình sau:

Phương pháp tiếp cận cụ thể ông sẽ nói chi tiết ở các phần sau tuy nhiên chúng ta cùng bàn luận một số cái về ưu điểm và nhược điểm của phương pháp này
Ưu điểm
- Có thể thực hiện được cho tất cả các bài hát, không cần thực hiện thủ công
- Không yêu cầu kinh nghiệm, chỉ bằng một cú click chuột là có thể thực hiện theo mong muốn
- Có thể tách được tốt với nhiều kiểu yêu cầu khác nhau như tách riêng tiếng guitar, tách riêng tiếng trống, tách riêng giọng hát, tách riêng beat
Nhược điểm
- Muốn tạo ra mộ hình phải có hiểu biết về AI - nhưng không sao đọc hết bài này của ông các cháu sẽ làm được
- Cần phải có dữ liệu training đủ đa dạng
- Cần phải có một máy tính cấu hình mạnh trong lúc training
Định hướng giải quyết
Sau khi đã phân tích các hướng giải quyết cho bài toán này thì chúng ta sẽ tập trung hơn vào hướng thứ hai các cháu nhé. Đơn giản là vì ông không phải là mixer nên ông cháu ta sẽ tiếp cận theo hướng thứ hai sẽ có nhiều điều thú vị để chia sẻ với các cháu hơn. Cũng giống như những bài hướng dẫn về AI khác của ông thì ông cháu ta sẽ cùng nhau đi qua các phần như phân tích đặc trưng của dữ liệu, lựa chọn các kiểu đặc trưng cho phù hợp với bài toán, sau đó xây dựng và training mô hình và cuối cùng là kiểm tra đánh giá kết quả. Giờ thì chúng ta sẽ bắt đầu từng phần một các cháu nhé.
Kiểu dữ liệu đầu vào - đầu ra
Như các cháu đã biết thì đầu vào của chúng ta sẽ là một file audio và tất nhiên đầu ra cũng sẽ là một file audio với chiều dài giống y hệt với audio đầu vào nhưng chỉ chứa phần nhạc nền của bài hát thôi. Hoặc chúng ta cũng có thể xây dựng mô hình để tách ra nhiều thành phần khác của đoạn nhạc đầu vào như tách riêng tiếng kèn, tiếng trống, tiếng khiên .... Để dễ hình dung thì các cháu có thể hình dung như sơ đồ sau:
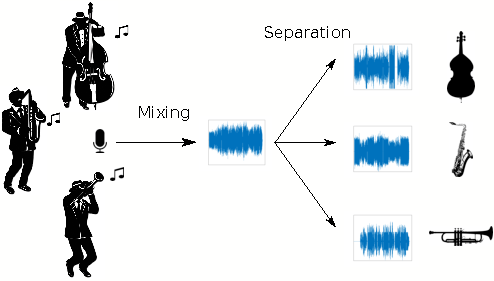
Trong đó các tín hiệu âm thanh đầu vào có thể được coi như các biên độ (các cháu có thể hiểu là độ to của âm thanh) theo thời gian
Từ độ to này thì các cháu có thể biết được những vùng nào là những vùng có âm thanh (thì cứ thấy màu xanh tức là có âm thành còn không có vùng màu xanh thì tức là chỗ đó đang là các khoảng lặng). Điều này cũng sẽ không thể giúp gì cho chúng ta trong việc tách phần nào là beat, phần nào là vocal cả vì hoàn toàn chưa có thông tin về tần số. Để làm được điều đó chúng ta cần phải chuyển đổi các thông tin của chúng ta về miền tần số và có thể sử dụng nó để tiến hành loại bỏ đi các tần số không cần thiết cho yêu cầu của chúng ta (ví dụ loại đi các tần số thể hiện giọng hátj. Cái này các cháu có thể hình dung đơn giản như việc hình thành cầu vồng ý. Nếu như các cháu để riêng tia sáng trắng (tương tự như giữ nguyên giá trị biên độ của âm thanh) thì tia sáng là không màu và các cháu không thể tách riêng từng thành phần màu của tia sáng ra được. Nhưng khi chiếu nó qua một lăng kính (tương tự như việc phân tích thành phổ tần số) thì các cháu sẽ thấy được màu của bảy sắc cầu vồng. Các cháu hiểu chưa nào.

Để hiểu rõ hơn về các phương pháp chuyển đổi sang miền tần số ông cháu ta sẽ tìm hiểu kĩ hơn trong phần sau nhé.
Chuyển đổi Fourier và Short Time Fourier Transform
Biến đổi Fourier
Biến đổi Fourier là một phép biến đổi cho phép chuyển đổi một tín hiệu từ miền thời gian sang miền tần số. Chẳng hạn như một bản nhạc có thể được phân tích dựa trên tần số của nó. Chúng ta có thể hình dung trong hình sau:
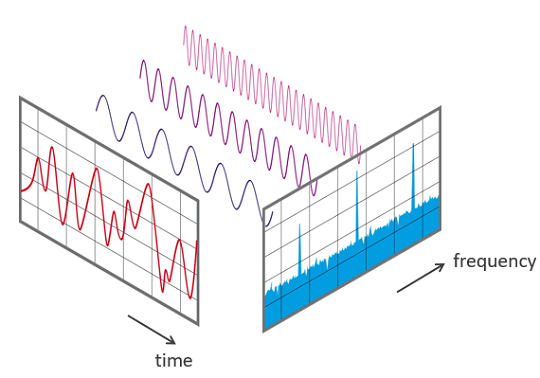
Thông thường, tên gọi biến đổi Fourier được gắn cho biến đổi Fourier liên tục, biến đổi này biểu diễn một hàm bình phương khả tích bất kì theo tổng của các hàm e lũy thừa phức với tần số góc và biên độ phức :

Đây là biến đổi nghịch đảo của biến đổi Fourier liên tục:

Biến đổi Fourier của tín hiệu này là cho ta đầy đủ thông tin trong miền tần số, nhưng hoàn toàn không có thông tin gì về miền thời gian gian vì tích phân từ đến . Do đó biến đổi Fourier không phù hợp với tín hiệu có tần số thay đổi theo thời gian. Điều đó có nghĩa là biến đổi Fourier chỉ có thể cho biết có hay không sự tồn tại của các thành phần tần số nào đó, tuy nhiên thông tin này độc lập với thời điểm xuất hiện thành phần phổ đó. Như vậy sau biến đổi Fourier, ta có thông tin trong miền tần số nhưng mất hoàn toàn thông tin về miền thời gian. Đây chính là lúc mà Short-time Fourier transform (STFT) xuất hiện.và ông cháu ta sẽ cùng tìm hiểu nó trong phần tiếp theo.
Biến đổi STFT
Ý tưởng chính của STFT là “hi sinh” một ít thông tin về các tần số thấp trong miền tần số để có thêm thông tin về miền thời gian. STFT được biểu diễn bằng 1 hàm theo hai biến là tần số góc và biến thời gian . Như vậy khi nhìn vào kết quả của STFT có thể biến được tần số xuất hiện vào thời điểm nào trong miền thời gian. Trong biến đổi STFT, thì tín hiệu được chia thành các đoạn đủ nhỏ, do vậy tín hiệu trên từng đoạn được phân chia có thể coi là dừng (stationary). Với mục đích này, hàm cửa sổ được lựa chọn. Độ rộng của cửa sổ phải bằng với đoạn tín hiệu mà giả thiết về sự dừng của tín hiệu là phù hợp. Nguyên tắc của phương pháp này là phân chia tín hiệu ra thành từng đoạn đủ nhỏ sao cho có thể xem tín hiệu trong mỗi đoạn là tín hiệu ổn định, sau đó, thực hiện biến đổi Fourier trên từng đoạn tín hiệu này.
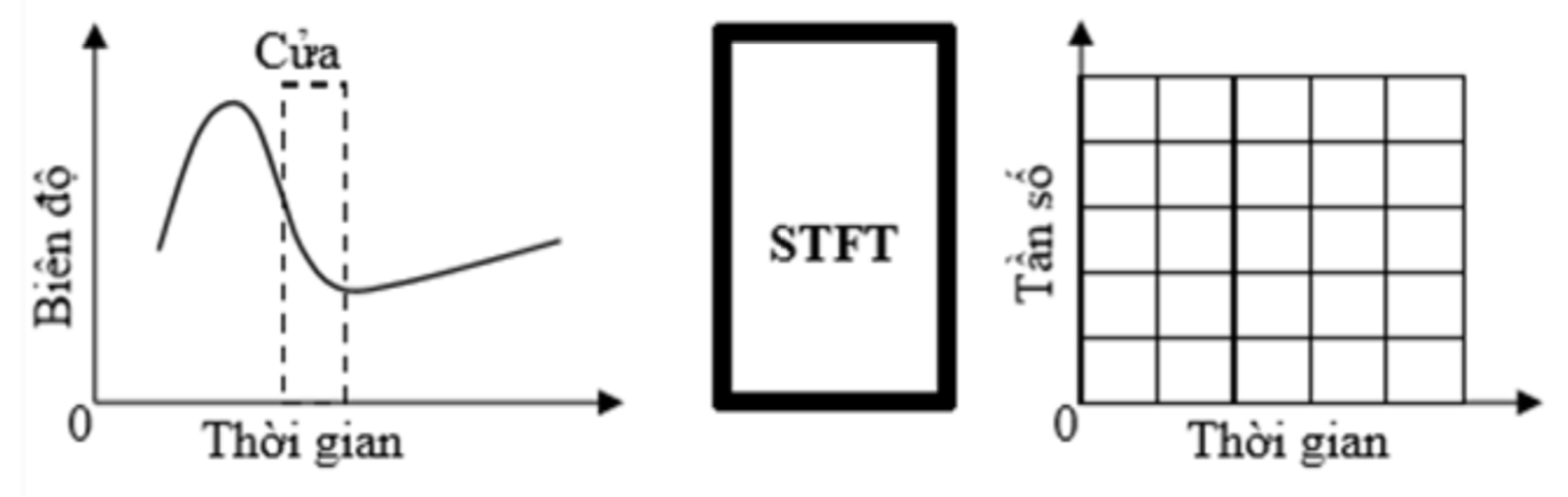
Nói chung các cháu có thể hiểu rằng sử dụng STFT thì chúng ta có thể lấy được thông tin của cả miền tần số và miền thời gian. Phép biến đổi ngược có thể giúp chúng ta khôi phục lại được tín hiệu ban đầu. Chính vì thế nên trong bài này ông sử dụng phương pháp STFT để chuyển đổi tín hiệu âm thanh sang miền tần số như một đặc trưng đầu vào cho mô hình Deep Learning của chúng ta. OK lý thuyết như vậy là đủ rồi, giờ ông cháu ta bắt tay vào phần thực hành thôi nhé.
Thu thập dữ liệu
Tập dữ liệu MUSDB18
Tập dữ liệu này là một tập dữ liệu khá phù hợp với bài toán của chúng ta. Các cháu có thể tải về tại đây. Để ông nói qua một chút về tập dữ liệu này cho các cháu nhé. Nó bao gồm 150 bài hát với khoảng 10 giờ âm thanh. Đây là dữ liệu khá tốt cho các cháu thực hành nhé. Tập này bao gồm các track nhạc được lưu dưới định dạng stems bao gồm các track chứa các loại âm thanh khác nhau như drums, bass, vocals và others. Với nhiều loại như này các cháu tha hồ lựa chọn mục đích của mô hình nhé. Nếu các cháu muốn làm mô hình tách nhạc nền như bài toán của ông cháu ta thì chỉ lấy nguyên phần others làm nhãn thôi nhé.
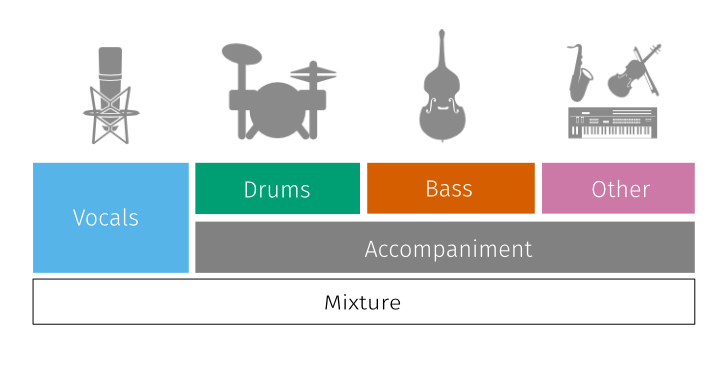
Tiền xử lý dữ liệu
Giờ đến bước chúng ta tiến hành các bước tiền xử lý dữ liệu với bài toán này. Do tập dữ liệu này lưu dưới dạng stems file nên chúng ta cần phải tách từng file nhỏ ra thành các thành phần khác nhau luôn các cháu ạ. Ở đây ông sẽ hướng dẫn các cháu viết hàm số để tách ra hai tracks là masterchứa âm thanh tổng tương ứng sẽ là đầu vào của mô hình và others chứa beat nhạc tương ứng với đầu ra của mô hình. Ngoài ra nếu cháu nào muốn thử nghiệm với vocal thì cũng có thể thực hiện được trong cùng một hàm này nhưng đầu tiên các cháu cần cài đặt và sử dụng thư viện stempeg tại đây
import stempeg
import numpy as np
def extract_vocal(fname):
stems, _ = stempeg.read_stems(fname, stem_id=[0,4,3])
stems = stems.astype(np.float32)
master = stems[0,:,:]
vocal = stems[1,:,:]
other = stems[2,:,:]
return master, vocal, other
Sau đó các cháu có thể sử dụng hàm trên để tách data từ một file bất kì thuộc tập dữ liệu MUSDB18 giả sử như sau:
master, vocal, other = extract_vocal('MUSDB18/train/Clara Berry And Wooldog - Air Traffic.stem.mp4')
Để lưu thử ra file các cháu sử dụng thư viện librosa rất phổ biến khi xử lý với dữ liệu dạng âm thanh cụ thể như sau:
import librosa
sr = 44100
librosa.output.write_wav('master.wav', master, sr)
Và cuối cùng để tạo dữ liệu cho tất cả các file trong thư mục train của tập dữ liệu MUSDB18 thì chúng ta sử dụng vòng lặp sau. Lưu ý là các cháu tạo sẵn các thư mục mixtures, others và vocals trong thư mục data nhé. Sau này chúng ta xử lý cho tiện.
import os
all_songs = os.listdir('MUSDB18/train/')
# Generate mixtures, others and vocals files
for i, fname in enumerate(all_songs):
master, vocal, other = extract_vocal(os.path.join('MUSDB18/train/', fname))
librosa.output.write_wav('data/mixtures/{}.wav'.format(i), master, sr)
librosa.output.write_wav('data/vocals/{}.wav'.format(i), vocal, sr)
librosa.output.write_wav('data/others/{}.wav'.format(i), other, sr)
Sau bướ này chúng ta sẽ có 3 thư mục tương ứng với dữ liệu đầu vào và ground truth. Việc tiếp theo chúng ta cần làm là phân chia dữ liệu các cháu ạ.
Phân chia dữ liệu
Việc này khá quan trọng đó các cháu ạ. Như các cháu thấy là mình đã tách ra được các file tương ứng với từng loại gồm bản mix, beat nhạc và giọng hát rồi. Thế như các file đó độ dài rất khác nhau, mà độ dài khác nhau thì không thể dùng làm dữ liệu được nó sẽ không thống nhất. Hơn nữa dữ liệu như vậy là chưa đủ phong phú, để làm phong phú hơn dữ liệu chúng ta thực hiện một kĩ thuật khá đơn giản đó là lấy từng đoạn âm thanh nhỏ và bước nhảy là 0.5 giây với mục đích làm cho dữ liệu của chúng ta trở nên phong phú hơn. Chúng ta làm như sau:
from tqdm import tqdm
# Skip 0.5 seconds
skip = sr // 2
# Mixtures part as training data
X_part = []
# Vocal part as label
Y_part = []
# Define win_len
length = 255
hop_size = 1024
win_len = hop_size*length
for mixture_path in tqdm(wav_path_mixtures):
vocal_path = mixture_path.replace('mixtures', 'vocals')
# Load x and y song
x, sr = librosa.load(mixture_path, sr = sr)
y, sr = librosa.load(vocal_path, sr = sr)
# Padding win_len 0 for x and y
x_pad = np.pad(x, (0, win_len), mode = "constant")
y_pad = np.pad(y, (0, win_len), mode = "constant")
l = len(x_pad)
for i in range(0, l - win_len - skip, skip):
x_part = x_pad[i:i + win_len]
y_part = y_pad[i:i + win_len]
X_part.append(x_part)
Y_part.append(y_part)
Và để thuận tiện hơn chúng ta có thể chia luôn dữ liệu training và testing. Lưu ý với các cháu là ông đang sử dụng nguyên các file trong thư mục train của tập MUSDB18 nên dữ liệu X_test và Y_test có thể hiểu tương tự như tập validate trong các bài toán thông thường (vì đã phân chia sẵn tập test độc lập rồi)
# Train test split
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X_part, Y_part, test_size=0.1, random_state=42)
Xây dựng mô hình
Kiến trúc mạng Unet
Unet là một kiến trục mạng rất phổ biến trong bài toán Image Segmentation với đặc thù của dữ liệu đầu vào và đầu ra có kích thước giống như nhau. Bài toán này của ông cháu ta rất phù hợp để áp dụng thử kiến trúc này. Mục đích của Unet là từ phổ âm thanh đầu và trích chọn ra được các phổ âm tương ứng với mục đích của chúng ta. Các cháu có thể hình dung kiến trúc Unet như trong hình sau:

Ông sẽ không nói quá sâu về phần này nhé, ông cũng sẽ xây dựng một mạng dựa trên Unet đơn giản với cơ chế Skip Connection được mô tả như trong phần bên dưới
Cơ chế Skip Connection
Cơ chế này cũng là một cơ chế rất quen thuộc trong cách thiết kế của mạng nơ ron theo dạng Auto Encoder. Các cháu có thể hiểu đơn giản đó là việc sử dụng các thông tin ở các layer ở phase encoder trước đó để đưa vào sang các layer đối xứng với nó trong phase decoder giúp cho các đặc trựng được giữ lại nhiều hơn qua Autoencoder. Người ta có thể sử dụng các hàm kích hoạt hoặc các mạng như LSTM, GRU để làm bộ chuyển đổi cho Skip Connection trong ví dụ này ông sử dụng GRU
Kíến trúc mạng sử dụng

Trong bài toán này ông sử dụng 3 lớp Convolution 1D đối xứng nhau để thiết kế Unet. Đồng thời sử dụng GRU để làm bộ chuyển đổi cho layer skip connection của lớp Convulution thứ 2 và thứ 3. Kích thước dữ liệu đầu vào phụ thuộc vào cách chọn tham số của STFT trong bài này ông để các thông số như sau:
hop_size = 1024
n_fft = 2048
Và đây là thiết kế chi tiết của mạng bằng Pytorch
# Define model
import torch.nn as nn
class VocalModel(nn.Module):
def __init__(self):
super(VocalModel, self).__init__()
self.conv1 = nn.utils.weight_norm(nn.Conv1d(1025, 1024, kernel_size = 3, padding = 1), name = "weight")
self.conv2 = nn.utils.weight_norm(nn.Conv1d(1024, 512, kernel_size = 3, stride = 2, padding = 1), name = "weight")
self.conv3 = nn.utils.weight_norm(nn.Conv1d(512, 256, kernel_size = 3, stride = 2, padding = 1), name = "weight")
self.Tconv1 = nn.utils.weight_norm(nn.ConvTranspose1d(256, 512, kernel_size = 3, stride = 2, padding = 1, output_padding = 1), name = "weight")
self.Tconv2 = nn.utils.weight_norm(nn.ConvTranspose1d(512, 1024, kernel_size = 3, stride = 2, padding = 1, output_padding = 1), name = "weight")
self.Tconv3 = nn.utils.weight_norm(nn.Conv1d(1024, 1025, kernel_size = 3, stride = 1, padding = 1), name = "weight")
self.gru1 = nn.GRU(1024, hidden_size = 1024, num_layers = 1, batch_first = True)
self.gru2 = nn.GRU(512, hidden_size = 512, num_layers = 1, batch_first = True)
self.leaky_relu = nn.LeakyReLU()
def forward(self, x):
# Encoder
x_s1 = self.leaky_relu(self.conv1(x))
x_s2 = self.leaky_relu(self.conv2(x_s1))
x = self.conv3(x_s2)
x = self.leaky_relu(x)
# Do GRU skip connection 1
x_s1 = x_s1.permute(0, 2, 1)
x_s1 = self.gru1(x_s1)[0]
x_s1 = x_s1.permute(0, 2, 1)
# Do GRU skip connection 2
x_s2 = x_s2.permute(0, 2, 1)
x_s2 = self.gru2(x_s2)[0]
x_s2 = x_s2.permute(0, 2, 1)
# Decoder
x = self.Tconv1(x)
x = self.leaky_relu(x)
# Add skip connection gru
x = torch.add(x, x_s2)
x = self.Tconv2(x)
x = self.leaky_relu(x)
# Add skip connection gru
x = torch.add(x, x_s1)
x = self.Tconv3(x)
x = self.leaky_relu(x)
return x
Sau khi đã định nghĩa được mô hình rồi chúng ta bắt đầu xây dựng Data Loader thôi các cháu nhé
Xây dựng DataLoader
Chuyển đổi STFT
Chúng ta sử dụng thư viện Pytorch để tiến hành chuyển đổi các dữ liệu tín hiệu âm thanh của chúng ta sang miền tần số
import torch.utils.data as utils
def convert_stft(x):
# Convert x data to stft
stft_label = librosa.stft(x, hop_length = 1024)
stft_label_mag = np.log1p(np.abs(stft_label))
return torch.from_numpy(stft_label_mag)
def get_phase(x):
stft_label = librosa.stft(x, hop_length = 1024)
return np.angle(stft_label)
Các cháu có thể convert thử để xem kết quả
convert_stft(X_train[2]).shape
>>> torch.Size([1025, 256])
Xây dựng data loader
Sau đó chúng ta cần xây dựng DataLoader để định nghĩa các xử lý dữ liệu đầu vào khi load data. Do ông đang thử với dữ liệu vocal nên chúng ta có thể xây dựng một class như sau:
from torch.utils.data import Dataset, DataLoader
class VocalDataset(Dataset):
def __init__(self, X, Y):
self.X = X
self.Y = Y
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return (convert_stft(self.X[idx]), convert_stft(self.Y[idx]))
Với các dữ liệu đã được phân chia thì ông cháu mình cần xây dựng hai DataLoader khác nhau phục vụ cho việc training và việc testing
train_dataset = VocalDataset(X_train, Y_train)
train_loader = DataLoader(train_dataset, batch_size=64)
test_dataset = VocalDataset(X_test, Y_test)
test_loader = DataLoader(test_dataset, batch_size=64)
Giờ là đến bước quan trọng nhất rồi các cháu ạ. Training mô hình và chờ kết quả thôi nào
Training mô hình
Định nghĩa hàm loss và optimizer
Việc định nghĩa hàm mất mát là rất quan trọng đó các cháu ạ. Ở đây các cháu có thể hiểu rằng việc tối ưu bài toán này chính là việc giúp cho phổ đâu ra của mô hình Unet các giống với phổ ground truth càng tốt và chúng ta có thể sử dụng các hàm tính khoảng các để làm hàm loss. Ở đây ông sử dụng MSE để làm hàm lỗi cho mô hình này. Các cháu định nghĩa nhé
loss = nn.MSELoss()
Tiếp theo đó là định nghĩa hàm tối ưu. Do kiến trúc mạng cũng không có gì đặc biệt nên chúng ta sử dụng Adam là phương pháp tối ưu phổ biến cho các mạng nơ ron hiện này
from torch.optim import Adam
optimizer = Adam(model.parameters(), lr=0.0001)
Bắt đầu training
Các cháu tiến hành training thuật toán và so sánh sau mỗi epochs loss trung bình trên hai tập training và validate. Để làm được điều đó các cháu thực hiện như sau:
train_dataset = VocalDataset(X_train, Y_train)
train_loader = DataLoader(train_dataset, batch_size=64)
test_dataset = VocalDataset(X_test, Y_test)
test_loader = DataLoader(test_dataset, batch_size=64)
# Training
from torch.optim import Adam
optimizer = Adam(model.parameters(), lr=0.0001)
train_loss = 1
test_loss = 1
for epoch in range(200):
train_loss_sum = []
model.train()
for i, (features, labels) in enumerate(train_loader):
features = features.cuda()
labels = labels.cuda()
optimizer.zero_grad()
out = model(features)
l = loss(out, labels)
l.backward()
optimizer.step()
train_loss_sum.append(l.item())
if (i % 50 == 49):
print("Epoch: {} Batch {}/{} Loss {}".format(epoch, i, len(train_loader), np.mean(train_loss_sum)))
# Test loss
print('Testing epoch ', epoch)
test_loss_sum = []
model.eval()
for i, (features, labels) in enumerate(test_loader):
features = features.cuda()
labels = labels.cuda()
optimizer.zero_grad()
out = model(features)
test_loss_sum.append(l.item())
test_loss_avg = np.mean(test_loss_sum)
print('Epoch {} train loss {} test loss {}'.format(epoch, np.mean(train_loss_sum), test_loss_avg))
if test_loss_avg < test_loss:
test_loss = test_loss_avg
torch.save(model.state_dict(), 'vocal_model.pth')
Sau đó các cháu tiến hành training khoảng 1 - 2 ngày là loss trên tập val sẽ gỉam còn khoảng 0.004 là được các cháu ạ. Lúc đó các cháu có thể lấy mô hình đi để test một vài mẫu được rồi
Đánh giá mô hình
Predict từng part nhỏ
Để thực hiện điều này các cháu cần thực hiện một số hàm như sau. Đầu tiên là hàm dự đoán từ một một part như các cắt dữ liệu phía trên
def predict_part(x_part, model):
feature = convert_stft(x_part)
phase = get_phase(x_part)
out_voice = model(feature[None,:,:].cuda())
out_voice = out_voice.cpu().detach().numpy()[0]
out_voice = np.exp(out_voice) - 1
out_voice = out_voice * np.exp(1j*phase)
y_voice = librosa.istft(out_voice , hop_length = 1024)
return y_voice
Sau đó các cháu thử với một vài mẫu dữ liệu trên tập test xem sao. Để kiểm chứng các cháu có thể lưu hẳn ra file và nghe thử nhé
y_voice = predict_part(X_test[10], model)
librosa.output.write_wav('y_voice.wav', y_voice, 44100)
librosa.output.write_wav('y_voice_gt.wav', Y_test[10], 44100)
Và đây là kết quả các cháu có thể nghe thử trực tiếp hai file ông vừa lưu ra nhé. Đây là ông đang lấy label chính là vocal của bài hát nhé. Các phần khác cũng tương tự như vậy thôi các cháu ạ.
Grouth Truth
Các cháu nghe thử nhé
Model Result
Các cháu nghe thử tại
Nếu các cháu nghe kĩ thì mới có thể phát hiện được hai đoạn âm thanh trên có chút khác biệt còn không thì cũng khó cảm nhận lắm đấy nhé
Predict một bài hát dài
Việc tách lời từ cả một bài hát dài sẽ mang nhiều ý nghĩa hơn là việc chỉ tách lời từ từng đoạn nhỏ. Để làm được điều đó đơn giản các cháu cần thực hiện ghép các đoạn nhỏ thành một đoạn lớn là được:
def predict_song(path, model):
model.eval()
win_len = 1024*255
x, sr = librosa.load(path, sr = 44100)
y_out = np.zeros((win_len,))
# Padding for x
x_pad = np.pad(x, (0, win_len), mode = "constant")
l = len(x)
for i in range(0, l, win_len):
x_part = x_pad[i:i + win_len]
y_part = predict_part(x_part, model)
y_out = np.concatenate((y_out, y_part), axis=0)
return y_out
Sau khi predict bằng hàm trên các cháu có thể xem kết quả
Bản master gồm tất cả âm thanh các cháu nghe thử tại đây
Bản vocal đã tách lời bằng mô hình các cháu nghe tại
Xây dựng series beat karaoke tự động siêu to khổng lồ
Trên đây ông đã thực hiện công việc tách vocal ra khỏi âm thanh tổng. Việc tách beat karaoke ra khỏi âm thanh tổng các cháu thực hiện tương tự như với label là phần others nhé. Sau khi thực hiện lại các quá trình trên các cháu cũng sử dụng để tách beat riêng ra và xây dựng beat karaoke cho bất kì bài hát nào. Các cháu muốn độ chính xác cao hơn thì cần phải thực hiện training với nhiều kiểu dữ liệu hơn để đạt được độ chính xác cao nhất nhé. Sau đây là một vài ví dụ mà ông đã tách săn các cháu nhé.
Tôi đã quên em lâu rồi thật đấy - Lil Shady: Các cháu nghe bản mixtures tại đây và bản vocal sau khi đã được tách tại đây
Cục Sì Ngầu Bà Tân Vlog ông sẽ sử dụng mô hình của chúng ta để tách lời bài hát viết về Bà Tân Vlog các cháu nhé. Các cháu có thể nghe thử tại đây
- Bản gốc tại đây
- Bản beat
- Bản vocal
Các cháu lưu ý là đây chỉ là kết quả từ model được training trong tập MUSDB18 nên có thể chất lượng chưa được tốt. Bằng cách bổ sung thêm dữ liệu các cháu sẽ có những model với chất lượng tốt hơn.
Tổng kết
Qua bài viết này ông đã hướng dẫn các cháu một cách tiếp cận mới sử dụng AI để xây dựng được những kho beat nhạc siêu to khổng lồ giúp các cháu thoả đam mê ca hát mà không cần mất quá nhiều công sức phải không nào. Hi vọng sẽ giúp được nhiều cho các cháu nhé. Các cháu thấy hay thì có thể share, like ủng hộ cho ông có động lực nhiều nha. Ông chào các cháu nhé.
All rights reserved
