Observability cho Agentic Systems: Theo Dõi Quyết Định, Không Chỉ Uptime
Agent tài chính của bạn chạy ngon lành. Không lỗi. Không crash. Mọi API call đều thành công. Dashboard toàn màu xanh.
Ba tháng sau, controller phát hiện ra rằng vài bản commentary số liệu kế toán đã dùng dữ liệu cũ. Agent đã gọi đúng tool. Nó không hề fail về mặt kỹ thuật. Nhưng nó đưa ra một quyết định sai về mặt nghiệp vụ — và không ai phát hiện ra cho đến khi quy trình chốt sổ đã bị ảnh hưởng.
Đây là thách thức thực sự với agentic systems trong production. Câu hỏi chuyển từ "Hệ thống có chạy không?" sang "Agent thực sự đã làm gì, tại sao nó làm vậy, kết quả có tốt không, và khi nào nên dừng nó lại?" Nếu không có câu trả lời, bounded autonomy trở thành unmanaged risk.
Observability truyền thống tập trung vào sức khỏe kỹ thuật — latency, error rate, tốc độ database. Agentic systems đòi hỏi nhiều hơn. Một agent không chỉ thực thi code xác định. Nó suy luận, chọn tool, truy xuất context, gọi hệ thống, dùng memory, và tạo ra đầu ra xác suất. Hai lần chạy với input tương tự có thể tạo ra các đường dẫn quyết định khác nhau. Observability giờ phải trả lời ba lớp cùng lúc: chuyện gì xảy ra về mặt kỹ thuật, agent đã quyết định gì, và tác động của nó lên kết quả kinh doanh và tuân thủ chính sách.
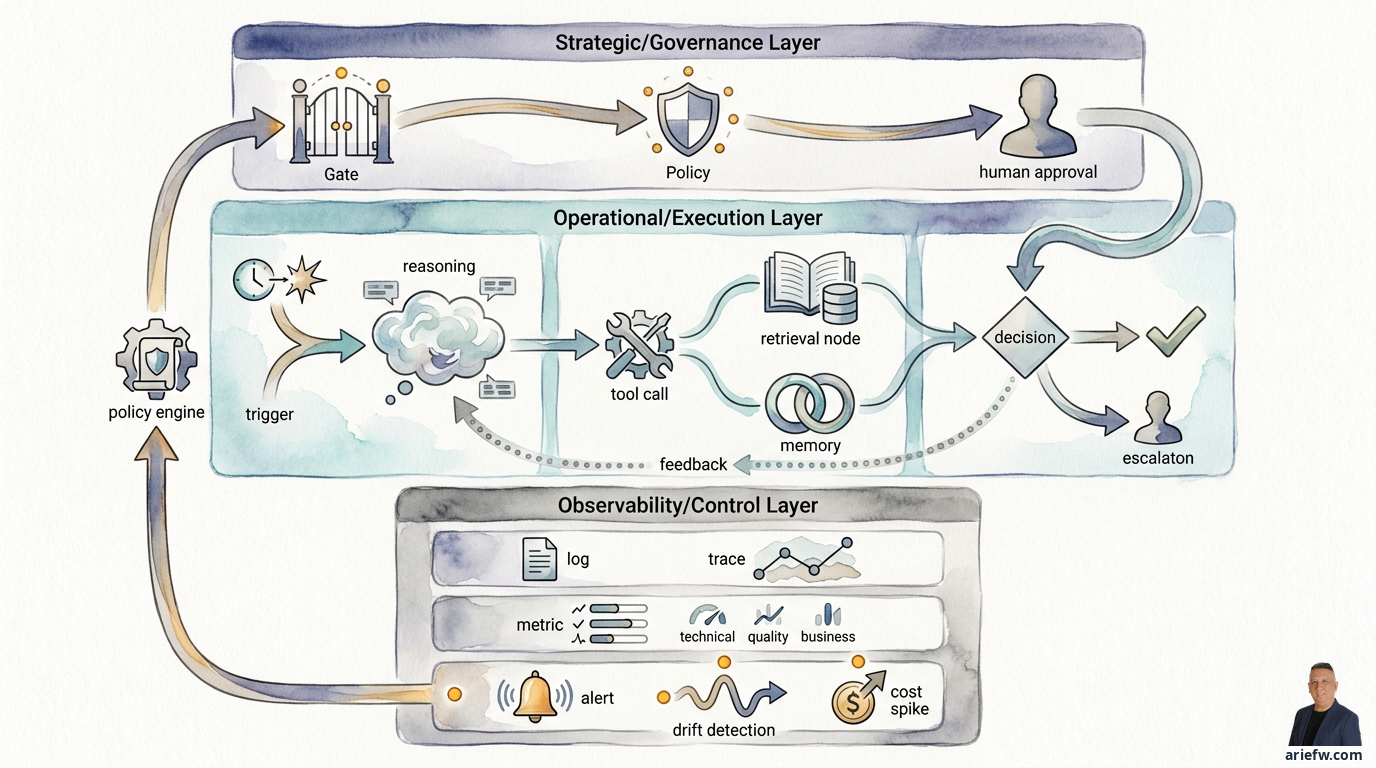
Tại Sao Observability Cho Agent Lại Khó Hơn Bạn Nghĩ
Khó khăn không phải vì công nghệ mới. Mà vì đối tượng được quan sát phức tạp hơn về bản chất. Trong ứng dụng tiêu chuẩn, luồng thực thi là tuyến tính: request vào, xử lý, đọc database, response ra. Khi có vấn đề, bạn trace logs, metrics, spans để tìm bottleneck.
Một agentic system xếp lớp: trigger từ user, event, hoặc workflow; orchestrator phân rã tác vụ; context retrieval từ RAG hoặc memory; suy luận hoặc kế hoạch do model tạo ra; các tool call tuần tự; policy engine đánh giá; human approval gate; và các hành động cuối cùng hoặc escalation.
Vấn đề: failure hiếm khi xuất hiện dưới dạng lỗi kỹ thuật. Agent có thể gọi mọi API thành công nhưng chọn sai hành động. Nó sẽ không crash, nhưng có thể dùng context cũ. Nó pass về mặt kỹ thuật nhưng vi phạm policy. Nó hoàn thành task với chất lượng quyết định kém. Hoặc nó tạo ra output nghe có vẻ thuyết phục nhưng sai về mặt nghiệp vụ.
Bản chất xác suất này thay đổi cách bạn monitor. Ngay cả với prompt, tool và dữ liệu giống hệt nhau, output vẫn khác nhau. Bạn không thể chỉ dựa vào error code. Bạn cần monitor behavioral patterns. Một refund agent không bao giờ fail về kỹ thuật có thể bắt đầu escalate các case trước đây nó tự xử lý — một behavioral drift âm thầm làm giảm năng suất. Một procurement agent vẫn tạo request nhưng bắt đầu chọn các approval path thận trọng hơn vì retrieval policies đã thay đổi. Không có technical incident, nhưng cycle time xấu đi.
Trong bối cảnh doanh nghiệp, observability không chỉ là công cụ vận hành. Nó là cơ chế governance. Risk, audit, compliance, và process owners cần trả lời: agent đã dùng context gì, tool nào được gọi, policy nào được áp dụng, khi nào agent dừng lại và yêu cầu phê duyệt, ai đã sửa output, và quyết định ảnh hưởng thế nào đến giao dịch kinh doanh? Nếu bạn không thể tái tạo chuỗi này, bạn không có nền tảng cho điều tra sự cố, kiểm toán, đánh giá chất lượng, cải thiện model, hoặc mở rộng autonomy.
Log Cái Gì: Từ Prompt Đến Kết Quả
Sai lầm phổ biến nhất là chỉ log prompts và responses. Với enterprise use case, điều đó nông một cách nguy hiểm. Logging đúng cho agentic systems phải ghi lại toàn bộ decision trail từ đầu đến cuối. Sáu thành phần quan trọng:
Trigger và initial context. Workflow bắt đầu như thế nào — user, system event, lịch trình, hay handoff từ agent khác? Log principal gốc, thời gian, kênh, và business object liên quan (số hóa đơn, ticket ID, order ID).
Prompt và runtime instructions. Không cần từng chi tiết, nhưng đủ để hiểu system instructions nào đang hoạt động, tham số nào được dùng, prompt hoặc workflow version nào đã chạy, và cấu hình model nào được áp dụng. Điều này trở nên thiết yếu khi so sánh các phiên bản agent hoặc điều tra thay đổi hành vi.
Retrieved context. Nếu agent dùng RAG, knowledge graph, hoặc memory, log document hoặc context chunk nào được truy xuất, từ nguồn nào, version hoặc timestamp của chúng, và liệu quyền truy cập có được kiểm tra không. Nếu không có, bạn không thể giải thích tại sao agent đưa ra quyết định cụ thể.
Model response và reasoning artifacts. Bạn không cần chain-of-thought thô, nhưng cần đủ cho audit và debugging: action plan summaries, intent classifications, confidence signals, hoặc structured decision outputs dùng cho các bước tiếp theo. Lưu đủ để đảm bảo trách nhiệm giải trình, nhưng tránh rò rỉ dữ liệu nhạy cảm hoặc sở hữu trí tuệ.
Tool calls và kết quả. Mỗi lần gọi tool nên ghi: tool nào, tham số chính, thành công hay thất bại, latency, số lần retry, và thay đổi trạng thái trong hệ thống đích. Với finance close, IT operations, hoặc procurement workflows, đây là nơi agent bắt đầu ảnh hưởng đến thực tế vận hành.
Policy decisions, human approvals, và final actions. Nếu policy engine, approval workflow, hoặc guardrail được sử dụng, log nó: policy nào được đánh giá, kết quả (allow, deny, escalate, require approval), người phê duyệt là ai, quyết định cuối cùng, và hành động nào thực sự được thực thi. Nếu không có lớp này, bạn có technical logs, không phải governance logs.
Log nhiều hơn đồng nghĩa với rủi ro lộ dữ liệu cao hơn. Agentic systems chạm vào dữ liệu khách hàng, thông tin lương, chi tiết nhà cung cấp, hợp đồng, dữ liệu tài chính, hoặc hồ sơ sự cố nội bộ. Thiết kế logging với:
- Redaction cho dữ liệu nhạy cảm
- Tokenization hoặc masking cho định danh
- Lưu trữ an toàn với kiểm soát truy cập
- Chính sách lưu giữ rõ ràng
- Phân tách nhiệm vụ
Khả năng kiểm toán phải tăng mà không mở rộng blast radius.
Metrics: Vượt Xa Sức Khỏe Kỹ Thuật
Sau logging và tracing, bạn cần metrics. Nhiều implementation dừng lại ở latency và error rate, tuyên bố hệ thống "observable". Agentic systems cần ba nhóm metrics riêng biệt.
Technical metrics giữ runtime khỏe mạnh. Monitor latency mỗi bước và end-to-end, token hoặc compute cost mỗi transaction, tool error rates, retry rates, timeout rates, fallback usage, phân bố failure mode, và availability của các thành phần quan trọng như model gateways, vector stores, policy engines, và tool registries. Những metrics này giúp platform teams duy trì ổn định nhưng không cho biết agent có đáng tin cậy không.
Quality metrics đánh giá liệu agent có đưa ra quyết định tốt không. Đây là điều phân biệt agentic observability với application observability. Theo dõi accuracy so với expected outcomes, hallucination hoặc unsupported answer rates, escalation rates, policy violation rates, human correction rates, rework rates sau hành động của agent, tool selection accuracy, và grounding quality so với retrieved context. Một số quality metrics không thể tự động hóa hoàn toàn — bạn cần kết hợp automated evaluation, manual sampling, user feedback, và domain expert review.
Business metrics đo lường liệu agent có thực sự cải thiện vận hành không. Kết nối observability với cycle time, cost per transaction, resolution rate, touchless rate, backlog reduction, revenue hoặc working capital impact, và customer hoặc employee satisfaction. Một agent có thể trông khỏe mạnh về kỹ thuật và điểm chất lượng cao, nhưng nếu cost per case không giảm và backlog không cải thiện, thiết kế cần được xem xét lại.
Tách biệt ba nhóm này. Trộn chúng khiến việc chẩn đoán nguyên nhân gốc rễ trở nên khó khăn. Latency spikes là vấn đề kỹ thuật. Human correction rates tăng là vấn đề chất lượng. Cycle time trì trệ là vấn đề kinh doanh hoặc thiết kế quy trình. Chúng có liên quan, nhưng không giống nhau.
Monitoring Drift Trước Khi Nó Trở Thành Sự Cố
Khi metrics đã được xác định, quyết định monitor liên tục cái gì và khi nào alert. Điều này khó hơn với agentic systems vì vấn đề thường xuất hiện dưới dạng thay đổi mẫu hình, không phải thất bại hoàn toàn.
Monitor behavioral drift — thay đổi trong escalation rates, sự dịch chuyển bất thường về độ dài output, thay đổi mẫu sử dụng tool, hoặc thay đổi phân bố classification đột ngột. Nguyên nhân có thể bao gồm model updates, prompt changes, retrieval corpus shifts, thay đổi phân bố dữ liệu, hoặc tool response modifications.
Theo dõi tool usage anomalies. Nếu một procurement agent thường gọi contract và vendor APIs bỗng nhiên bắt đầu gọi manual exception paths thường xuyên hơn, đó là tín hiệu. Nếu một IT operations agent chạy một số runbook vượt baseline xa, hãy điều tra drift, bug, hoặc thay đổi môi trường.
Theo dõi output distribution changes. Nhiều phản hồi "Tôi không biết" hơn, nhiều khuyến nghị thận trọng hơn, nhiều hành động bị human hủy hơn, hoặc nhiều case kết thúc mà không có giải pháp — những điều này thường báo hiệu chất lượng agent đang giảm trước khi chúng trở thành sự cố có thể thấy được.
Không phải mọi alert đều là technical incident. Phân loại alert thành bốn loại:
- Technical incidents (model gateway down, tool API timeout)
- Policy breaches (agent cố gắng thực hiện hành động trái phép, vi phạm truy cập)
- Quality degradation (human correction rates tăng đột biến, unsupported answers tăng)
- Cost spikes (token cost mỗi transaction tăng, tool calls quá mức, fallback sang model đắt tiền)
Mỗi loại cần một chủ sở hữu phản hồi và đường dẫn escalation khác nhau.
Áp Dụng Vào Hệ Thống Thật
Bắt đầu với một agent workflow duy nhất — không phải toàn bộ hệ thống. Vẽ bản đồ decision path của nó từ trigger đến outcome. Xác định sáu thành phần logging và ba nhóm metrics quan trọng nhất cho use case đó. Xây dựng dashboard tách biệt sức khỏe kỹ thuật khỏi chất lượng quyết định khỏi tác động kinh doanh.
Sau đó, thêm alerting cho drift patterns, không chỉ error codes. Khi bạn thấy behavioral shift, hãy điều tra trước khi nó trở thành sự cố. Và thiết kế logging với bảo mật và quyền riêng tư ngay từ ngày đầu — retrofit governance luôn khó hơn xây dựng nó từ đầu.
Sự Đánh Đổi: Đừng Xây Dựng Một Con Quái Vật Giám Sát
Có một cái bẫy ở đây. Các tổ chức có thể log quá mọi thứ mà không có ưu tiên. Chi phí lưu trữ phình to. Dashboard trở thành nhiễu. Teams không thể xác định tín hiệu quan trọng. Rủi ro quyền riêng tư tăng lên.
Thiết kế observability theo risk tier và mức độ quan trọng của use case. Một internal knowledge assistant có thể cần logging nhẹ hơn. Một refund automation system, finance exception handler, hoặc IT remediation workflow cần tracing và auditing sâu hơn nhiều.
Nguyên tắc lành mạnh: log đủ cho trách nhiệm giải trình, đo lường đủ cho việc ra quyết định, và alert đủ để teams thực sự hành động. Observability tốt không phải là nhiều dữ liệu nhất — mà là dữ liệu hữu ích nhất để thấy, giải thích và kiểm soát hành vi của agent.
Một vài dấu hiệu cảnh báo rằng observability của bạn chưa sẵn sàng cho scale:
- Bạn không thể trace một agent run từ trigger đến business outcome
- Bạn không có sự phân tách giữa technical, quality và business metrics
- Bạn chưa xác định dữ liệu nhạy cảm nào sẽ được redact và ai có thể truy cập logs
- Bạn coi tất cả alert là cùng một loại incident
- Bạn không có quy trình có hệ thống để đánh giá chất lượng agent trong production
Observability cho agentic systems không phải là một dự án dashboard. Nó là một quyết định về control plane. Làm đúng, bạn xây dựng nền tảng cho sự tin cậy, trách nhiệm giải trình và autonomy có trách nhiệm. Làm sai, bạn sẽ không biết agent của mình đang làm gì cho đến khi quá muộn — và lúc đó, chúng đã hành động thay mặt bạn rồi.
Bài viết này nằm trong series về AI governance và enterprise architecture. Để xem thảo luận đầy đủ với các diagram bổ sung và implementation patterns, hãy xem bài viết gốc.
All rights reserved
