[Object Detection Part 1] Cùng nhau tìm hiểu những thuật ngữ "khó nhằn" trong AI
Bài đăng này đã không được cập nhật trong 7 năm
1. Mở đầu
Trong thời gian gần đây cùng với sự phát triển vượt bậc của công nghệ thì khái niệm về AI, Machine Learning dần trở nên gần gũi hơn với giới lập trình viên chúng ta, với những người còn bỡ ngỡ như mình thì AI là gì, Nerual Network, Machine Learning là gì (??)
Trong bài này chúng ta cùng nhau tìm hiểu về những thuật ngữ cơ bản của AI để chúng ta có cái nhìn tổng quát về nó và có được những nền tảng cơ bản để có thể bắt đầu với kiến thức mới  . Bài viết này nặng tính lý thuyết nhưng mình sẽ cố gắng làm nó sinh động nhất có thể
. Bài viết này nặng tính lý thuyết nhưng mình sẽ cố gắng làm nó sinh động nhất có thể 
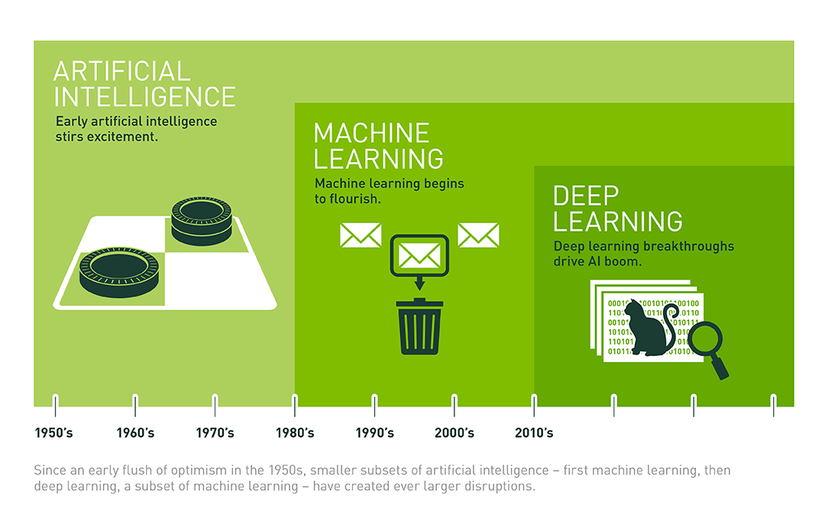
2. Các khái niệm cơ bản
1. AI
Trí tuệ nhân tạo (Artificial Intelligence) là các kỹ thuật giúp cho máy tính thực hiện được những công việc của con người chúng ta. Ví dụ như một chương trình cờ vua tự động có thể coi là một chương trình có sử dụng AI hay viết tắt là một chương trình AI.
2. Machine Learning
Định nghĩa: Machine Learning là một lĩnh vực con của AI và hiện tại có 2 định nghĩa về thuật ngữ này
- Cổ điển:
Machine Learning is the field of study that gives computers the ability to
learn without being explicitly programmed.
Machine Learning là một ngành học nghiên cứu về cách giúp cho máy tính
điện tử có được khả năng có thể học tập mà không cần phải được lập trình
một cách tỉ mỉ trước đó.
(Arthur Samuel – 1959)
Theo như định nghĩa này thì mình cảm thấy là nó giống như việc dịch sát nghĩa từ Machine Learning vậy. Vẫn chưa hiểu rõ Machine Learning là gì? Làm sao để thực hành Machine Learning  . Vậy nên một định nghĩa khác mở hơn được đưa ra giúp cho mọi người có cái nhìn dễ dàng hơn về Machine Learning.
. Vậy nên một định nghĩa khác mở hơn được đưa ra giúp cho mọi người có cái nhìn dễ dàng hơn về Machine Learning.
- Hiện đại:
A computer program is said to learn from experience E with respect to some
class of tasks T and performance measure P, if its performance at tasks
in T, as measured by P, improves with experience E.
Một chương trình máy tính được gọi là học cách thực thi 1 nhóm nhiệm vụ
tương đồng T thông qua trải nghiệm E dựa trên tiêu chí đánh giá P khi
kết quả thực thi các nhiệm vụ trong nhóm T của chương trình đó, tăng
lên theo trải nghiệm E thông qua đánh giá bằng tiêu chí P.
(Tom Mitchell – 1998)
Dưới góc nhìn mới , mọi bài toán đều có input và output, ở giữa của quy trình đó là một hàm. Hàm là một tập hợp các quy tắc được dùng để các phần tử ở tập nguồn đến các phần tử ở tập đích sao cho mỗi một phần tử ở tập nguồn chỉ có một và chỉ một phần tử ở tập đích.
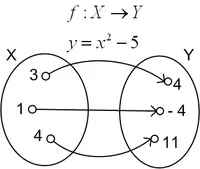
Nguyên tắc cốt lõi của Machine Learning là các máy tiếp nhận dữ liệu và tự học. Machine learning là một phương pháp phân tích dữ liệu mà sẽ tự động hóa việc xây dựng mô hình phân tích. Chúng học từ các tính toán trước đó để tạo ra những quyết định cũng như kết quả lặp lại và đáng tin cậy. Ví dụ Alpha Go là một ví dụ hoàn hảo về Machine Learning, khi nó tiếp nhận và học hỏi một lượng lớn dữ liệu từ cách bước đi cũng như tính toán của các cao thủ để đánh bại nhà vô địch thế giới Lee Sedol
Machine Learning chia các bài toán ra làm hai loại chính là Supervised Learning và Un-Supervised Learning. Ở bài này chúng ta chỉ đi vào tìm hiểu về Supervised Learning để tránh lượng kiến thức quá lớn
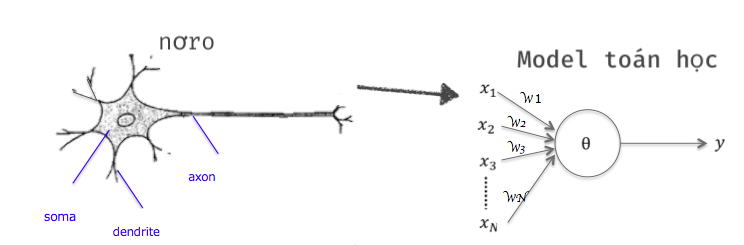
3. Mạng Neural
-
Mạng Neuron nhân tạo (Artificial Neural Network- ANN) là mô hình xử lý thông tin được mô phỏng dựa trên hoạt động của hệ thống thần kinh của sinh vật, bao gồm số lượng lớn các Neuron được gắn kết để xử lý thông tin. Một mạng nơ-ron được cấu thành bởi các nơ-ron đơn lẻ được gọi là các perceptron. ANN giống như bộ não con người, được học bởi kinh nghiệm (thông qua huấn luyện), có khả năng lưu giữ những kinh nghiệm hiểu biết (tri thức) và sử dụng những tri thức đó trong việc dự đoán các dữ liệu chưa biết (unseen data).
-
Kết hợp với các kĩ thuật học sâu (Deep Learning - DL), NN đang trở thành một công cụ rất mạnh mẽ mang lại hiệu quả tốt nhất cho nhiều bài toán khó như nhận dạng ảnh, giọng nói hay xử lý ngôn ngữ tự nhiên.
-
Áp dụng trong bài toán Object Detection, khi ta xấy dựng một mạng neural để huấn luyện nhận dạng phân biệt vật thể thì ta sẽ đưa 1 tập dữ liệu bao gồm hình ảnh và chỉ đích danh vật thể đó là gì (gán nhãn) sau đó dùng để cho máy học sau mỗi lần sẽ lấy kết quả thu được cho máy học tiếp cho đến khi đạt được kết quả tốt nhất đay được gọi là học có giám sát, chúng ta sẽ tìm hiểu về nó ở phần tiếp theo nhé
-
-
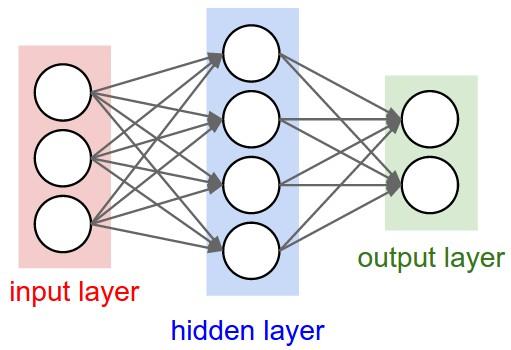
Kiến trúc mạng NN
- Mạng NN là sự kết hợp của của các tầng perceptron hay còn được gọi là perceptron đa tầng (multilayer perceptron) như hình vẽ bên dưới:
-
Một mạng NN sẽ có 3 kiểu tầng:
-
Tầng vào (input layer): Là tầng bên trái cùng của mạng thể hiện cho các đầu vào của mạng.
-
Tầng ra (output layer): Là tầng bên phải cùng của mạng thể hiện cho các đầu ra của mạng.
-
Tầng ẩn (hidden layer): Là tầng nằm giữa tầng vào và tầng ra thể hiện cho việc suy luận logic của mạng.
-
Lưu ý rằng, một NN chỉ có 1 tầng vào và 1 tầng ra nhưng có thể có nhiều tầng ẩn. Thử thách lớn nhất trong việc tạo mạng nơ ron là quyết định số lượng các hidden layer này, cũng như số các nơ ron cho mỗi layer.
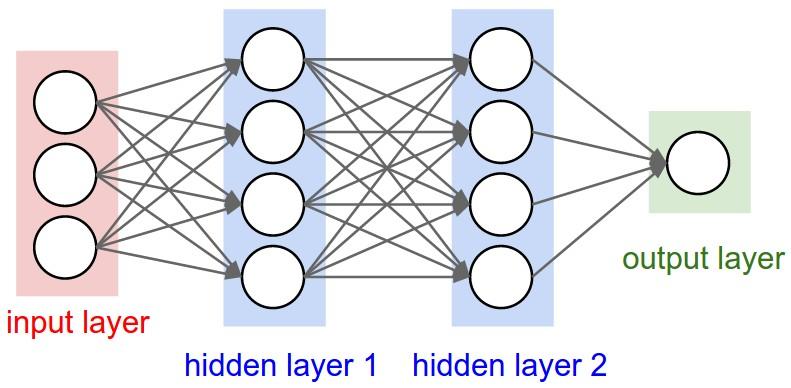
Trong mạng NN, mỗi nút mạng là một sigmoid nơ-ron nhưng hàm kích hoạt của chúng có thể khác nhau. Tuy nhiên trong thực tế người ta thường để chúng cùng dạng với nhau để tính toán cho thuận lợi.
Ở mỗi tầng, số lượng các nút mạng (nơ-ron) có thể khác nhau tuỳ thuộc vào bài toán và cách giải quyết. Nhưng thường khi làm việc người ta để các tầng ẩn có số lượng nơ-ron bằng nhau. Ngoài ra, các nơ-ron ở các tầng thường được liên kết đôi một với nhau tạo thành mạng kết nối đầy đủ (full-connected network). Khi đó ta có thể tính được kích cỡ của mạng dựa vào số tầng và số nơ-ron.
4. Supervised Learning
-
Học có giám sát là việc có sẵn một tập nguồn và một tập đích tương ứng để làm cơ sở xây dựng ra model mong muốn. Tập hợp kết hợp bởi hai tập này được gọi là tập Train(gồm object và label) . Theo thời gian, khi đưa bài toán vào áp dụng thực tế, dữ liệu mới lại được sử dụng để train lại nhằm cải tiến model hiện tại. Điều này chính là mô tả cho khái niệm học có giám sát. Điển hình cho kỹ thuật này là mạng Neuron lan truyền ngược (Backpropagation).
-
Các thuật toán nằm trong nhóm các bài toán học có giám sát được chia nhỏ thành hai phần dựa trên đặc tính của tập đích trong tập train.
- Classification
Khi dữ liệu của tập đích là một nhóm hữu hạn và có thể labled được,
bài toán được xếp vào dạng classification.
Đây sẽ là dạng bài toán được chúng ta sử dụng trong bài viết này ;)
- Regression
Dạng còn lại được gọi là regression (Bài toán hồi quy). Hồi quy là những cái
gì có tính liên tục và tiếp nối với nhau . Vậy khi tập đích trong tập train
là một tập dữ liệu có dạng liên tục không thể phân thành nhóm mà là một dữ
liệu cụ thể thì bài toán được xếp vào dạng hồi quy. Bài toán tiêu biểu cho
dạng này là tính toán giá cả của sản phẩm dựa trên thông số trước đó,
hoặc dự đoán biến động tài chính ...
- Lan truyền ngược (backpropagation) là giải thuật cốt lõi giúp cho các mô hình học sâu có thể dễ dàng thực thi tính toán được. Với các mạng NN hiện đại, nhờ giải thuật này mà thuật toán tối ưu với đạo hàm (gradient descent) có thể nhanh hơn hàng triệu lần so với cách thực hiện truyền thống giúp cho việc học dữ liệu trở nên nhanh hơn hàng triệu lần.
5. Deep Learning
Cái tên Deep Learning ra đời với mục đích nhấn mạnh các Hidden layers của Neural Network. Có thể hiểu Deep Learning chính là Neural Network với nhiều Hidden layers. Nó cho phép chúng ta huấn luyện một AI có thể dự đoán được các đầu ra dựa vào một tập các đầu vào. Cả hai phương pháp có giám sát và không giám sát đều có thể sử dụng để huấn luyện.
Ví dụ về học có giám sát chúng ta đã đề cập ở trên. Còn về học không giám sát thực hiện khi ta đưa 1 tập dữ liệu đầu vào để học nhưng không gán nhãn cho các vật thể nhưng sau khi triển khai mô hình nó vẫn có khả năng phân biệt chính xác vật thể (tỉ lệ nhỏ)
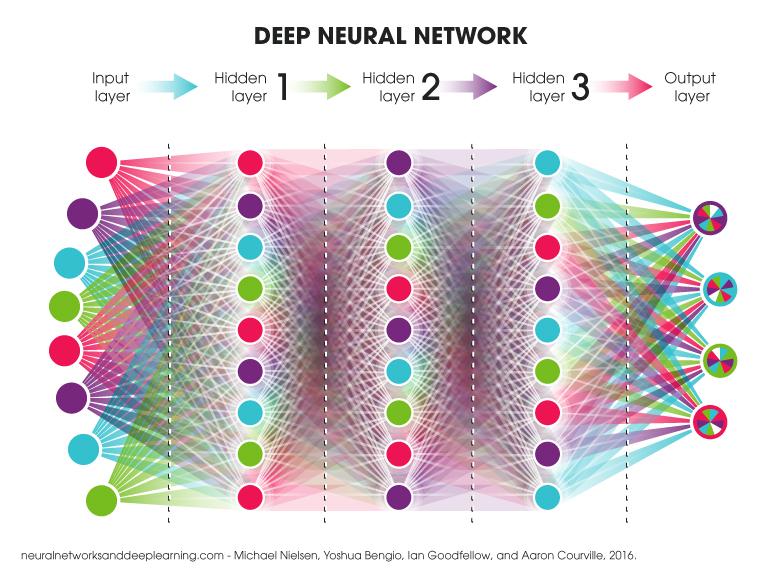
À thế sao lại cần nhiều Hidden layers làm gì ? Ở Deep Learning không có cách nào đi tắt đón đầu, mỗi Hidden layers sẽ có một nhiệm vụ, output của tầng này sẽ là input của tầng sau. Nếu tìm hiểu kĩ hơn các bạn thấy rõ điều này.
-
Các bước học máy : Một bài toán học máy cần trải qua 3 bước chính:
- Chọn mô hình: Chọn một mô hình thống kê cho tập dữ liệu.
- Tìm tham số: Các mô hình thống kê có các tham số tương ứng, nhiệm vụ lúc này là tìm các tham số này sao cho phù hợp với tập dữ liệu nhất có thể.
- Suy luận: Sau khi có được mô hình và tham số, ta có thể dựa vào chúng để đưa ra suy luận cho một đầu vào mới nào đó.
-
Tiêu chuẩn của dữ liệu đầu vào
-
Chuẩn hoá: Tất cả các dữ liệu đầu vào đều cần được chuẩn hoá để máy tính có thể xử lý được. Việc chuẩn hoá này ảnh hưởng trực tiếp tới tốc độ huấn luyện cũng như cả hiệu quả huấn luyện.
-
Phân chia: Việc mô hình được chọn rất khớp với tập dữ liệu đang có không có nghĩa là giả thuyết của ta là đúng mà có thể xảy ra tình huống dữ liệu thật lại không khớp. Vì vậy khi huấn luyện người ta phải phân chia dữ liệu ra thành 3 loại để có thể kiểm chứng được phần nào mức độ tổng quát của mô hình. Cụ thể 3 loại đó là:
- Tập huấn luyện (Training set): Chiếm 60%. Dùng để học khi huấn luyện
- Tập kiểm chứng (Cross validation set): Chiếm 20%. Dùng để kiểm chứng mô hình khi huấn luyện.
- Tập kiểm tra (Test set): Chiếm 20%. Dùng để kiểm tra xem mô hình đã phù hợp chưa sau khi huấn luyện.
-
Lưu ý rằng, tập kiểm tra ta phải lọc riêng ra và không được sờ tới, sử dụng nó trong khi huấn luyện. Còn tập huấn luyện và tập kiểm chứng thì nên xáo trộn đổi cho nhau để mô hình của ta được huấn luyện với các mẫu ngẫu nhiên nhất có thể.
Kết luận
Ở phần này mình chỉ giới thiệu qua những thuật ngữ cơ bản liên quan đến bài toán nhận diện vật thể do lượng kiến thức quá lớn sẽ khiến chúng ta bị miss , ở phần sau mình sẽ áp dụng những lý thuyết này vào phân tích thuật toán được sử dụng và thực hành nhận dạng vật thể thông qua Tensor Flow.
Mình là beginer nên còn nhiều sai sót hi vọng các bạn góp ý để bài viết trở nên chất lượng hơn.
Cảm ơn các bạn đã theo dõi
Tham khảo
https://en.wikipedia.org/wiki/Machine_learning
All rights reserved
