Những câu hỏi trong phỏng vấn Deep Learning - P1
Bài đăng này đã không được cập nhật trong 6 năm
Neuron người hoạt động như thế nào ?
 Nơ-ron là đơn vị cơ bản cấu tạo hệ thống thần kinh và là một phần quan trọng nhất của não. Não
chúng ta gồm khoảng 10 triệu nơ-ron và mỗi nơ-ron liên kết với 10.000 nơ-ron khác.
Ở mỗi nơ-ron có phần thân (soma) chứa nhân, các tín hiệu đầu vào qua sợi nhánh (dendrites)
và các tín hiệu đầu ra qua sợi trục (axon) kết nối với các nơ-ron khác. Hiểu đơn giản mỗi nơ-ron
nhận dữ liệu đầu vào qua sợi nhánh và truyền dữ liệu đầu ra qua sợi trục, đến các sợi nhánh của các
nơ-ron khác.
Mỗi nơ-ron nhận xung điện từ các nơ-ron khác qua sợi nhánh. Nếu các xung điện này đủ lớn
để kích hoạt nơ-ron, thì tín hiệu này đi qua sợi trục đến các sợi nhánh của các nơ-ron khác. => Ở
mỗi nơ-ron cần quyết định có kích hoạt nơ-ron đấy hay không.
Nơ-ron là đơn vị cơ bản cấu tạo hệ thống thần kinh và là một phần quan trọng nhất của não. Não
chúng ta gồm khoảng 10 triệu nơ-ron và mỗi nơ-ron liên kết với 10.000 nơ-ron khác.
Ở mỗi nơ-ron có phần thân (soma) chứa nhân, các tín hiệu đầu vào qua sợi nhánh (dendrites)
và các tín hiệu đầu ra qua sợi trục (axon) kết nối với các nơ-ron khác. Hiểu đơn giản mỗi nơ-ron
nhận dữ liệu đầu vào qua sợi nhánh và truyền dữ liệu đầu ra qua sợi trục, đến các sợi nhánh của các
nơ-ron khác.
Mỗi nơ-ron nhận xung điện từ các nơ-ron khác qua sợi nhánh. Nếu các xung điện này đủ lớn
để kích hoạt nơ-ron, thì tín hiệu này đi qua sợi trục đến các sợi nhánh của các nơ-ron khác. => Ở
mỗi nơ-ron cần quyết định có kích hoạt nơ-ron đấy hay không.
Tuy nhiên trong deep learning chỉ là lấy cảm hứng từ não bộ và cách nó hoạt động, chứ không phải bắt chước toàn bộ các chức năng của nó. Việc chính của chúng ta là dùng mô hình đấy đi giải quyết các bài toán chúng ta cần.
Mô hình tổng quát Neural Network như thế nào?
 Layer đầu tiên là input layer, các layer ở giữa gọi là hidden layer, layer cuối cùng gọi là output layer.
Một mạng neural network bắt buộc phải có input layer và output layer, các layer ẩn có thể có hoặc không.
Layer đầu tiên là input layer, các layer ở giữa gọi là hidden layer, layer cuối cùng gọi là output layer.
Một mạng neural network bắt buộc phải có input layer và output layer, các layer ẩn có thể có hoặc không.
Các hình tròn trong layer gọi là node, hay còn gọi là các neural. Những node này liên kết với tất cả các node trước đó và hệ số w riêng. Mỗi node đều có 1 hệ số bias b riêng và sau đó sẽ tính tổng các weight với input trước đó rồi áp dụng activation function để truyền tới các node của layer tiếp theo.
Các bước để thiết lập bài toán giải bằng deep learning là gì?
- Xử lý dữ liệu: Chia ra tập train, tập val, tập test.
- Thiết lập model để cho máy học.
- Thiết lập hàm loss function.
- Tìm tham số bằng cách tối ưu hàm loss function, trong đó cố gắng chọn learning rate phù hợp.
- Dự đoán dữ liệu test bằng model vừa train xong.
Loss function là gì ?
Loss function hay còn gọi là hàm mất mát, thể hiện một mối quan hệ giữa y* (là kết quả dự đoán của model) và y (là giá trị thực tế). Ví dụ ta có hàm loss như sau: f(y) = (y* - y)^2. Khi đó người ta đưa vào hàm loss function này mục đích là để tối ưu model của mình sao cho tốt nhất, hay cũng dùng để đánh giá độ tốt của model , y* (là kết quả dự đoán của model) càng gần y (là giá trị thực tế) thì càng tốt. Tức là dựa vào loss function, khi đó chúng ta có thể tính ra gradient descent để tối ưu loss function càng về gần 0 càng tốt. (Hiện tại mình chỉ trình bày vậy cho các bạn dễ hiểu, còn mục sau mình sẽ trình bày rõ hơn về LAN TRUYỀN NGƯỢC để các bạn hiểu rõ nhất).
Hàm activation là gì , có ý nghĩa gì ?
Hàm kích hoạt (activation function) mô phỏng tỷ lệ truyền xung qua axon của một neuron thần kinh,
là những hàm phi tuyến được áp dụng vào đầu ra của các nơ-ron trong tầng ẩn của một mô hình mạng ( có nhiệm vụ là chuẩn hoá output của neura) và được sử dụng làm input data cho tầng tiếp theo.
Cấu trúc neuron sinh học
 Cấu trúc neuron trong học máy
Cấu trúc neuron trong học máy
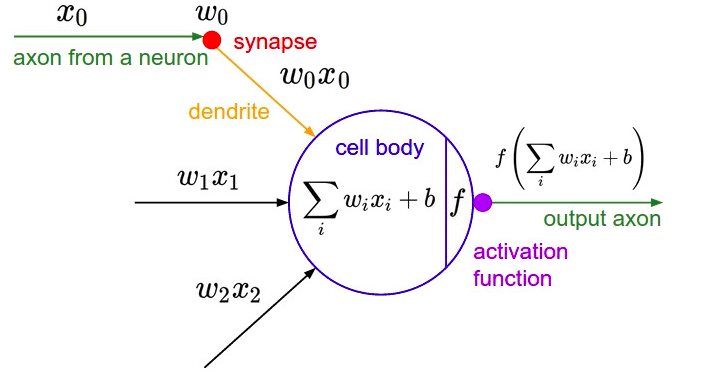
Giống như trong mô hình sinh học, các xung thần kinh được truyền qua axon với một tỷ lệ nào đó. Ở mô hình học máy mô phỏng chúng ta xây dựng, các hàm kích hoạt sẽ điều chỉnh tỷ lệ truyền này. Các hàm này thường là các hàm phi tuyến.
Chuyện gì sẽ xảy ra nếu không có các hàm phi tuyến này ?
Hãy tưởng tượng rằng thay vì áp dụng 1 hàm phi tuyến, ta chỉ áp dụng 1 hàm tuyến tính vào đầu ra của mỗi neuron. Vì phép biến đổi không có tính chất phi tuyến, việc này không khác gì chúng ta thêm một tầng ẩn nữa vì phép biến đổi cũng chỉ đơn thuần là nhân đầu ra với các weights. Với chỉ những phép tính đơn thuần như vậy, trên thực tế mạng neural sẽ không thể phát hiện ra những quan hệ phức tạp của dữ liệu (ví dụ như: dự đoán chứng khoán, các bài toán xử lý ảnh hay các bài toán phát hiện ngữ nghĩa của các câu trong văn bản). Nói cách khác nếu không có các activation functions, khả năng dự đoán của mạng neural sẽ bị giới hạn và giảm đi rất nhiều, sự kết hợp của các activation functions giữa các tầng ẩn là để giúp mô hình học được các quan hệ phi tuyến phức tạp tiềm ẩn trong dữ liệu.
Tại sao hàm activation phải non-linear? Điều gì xảy ra nếu hàm linear activation được sử dụng?
 Các activation function phải là nonlinear (phi tuyến), vì nếu không, nhiều layer hay một layer cũng là như nhau. Ví dụ với hai layer trong Hình 2, nếu activation function là một hàm linear (giả sử hàm f(s) = s) thì cả hai layer có thể được thay bằng một layer với ma trận hệ số W = W1xW2 (tạm bỏ qua hệ số bias)
Các activation function phải là nonlinear (phi tuyến), vì nếu không, nhiều layer hay một layer cũng là như nhau. Ví dụ với hai layer trong Hình 2, nếu activation function là một hàm linear (giả sử hàm f(s) = s) thì cả hai layer có thể được thay bằng một layer với ma trận hệ số W = W1xW2 (tạm bỏ qua hệ số bias)
Tại sao cần nhiều layer và nhiều node trong 1 hidden layer?
Trong neural network chúng ta cần nhiều để xử lý nhiều nhiệm vụ khác nhau, mỗi layer sẽ thực hiện một nhiệm vụ nào đó, output của tầng này sẽ là input của tầng sau. Số lượng layer là không giới hạn, nhưng với mỗi bài toán cụ thể sẽ có cách chọn layer khác nhau để phù hợp với bài toán. Thông thường với các bài toán đơn giản thì số layer sẽ ít, với các bài toán phức tạp hơn thì số layer sẽ nhiều hơn. Bạn cứ hiểu rằng qua mỗi layer là một lần xử lý dữ liệu nhằm đạt được một mục đích nào đó.
Chúng ta cần nhiều node trong 1 hidden layer để việc học hiệu quả hơn. Giả sử đầu vào là 2 chiều, tức là 2 node; hidden layer có 1 node và output layer có 1 node. thì khi đó việc điều chỉnh trọng số w1, w2 giữa node input với node hidden layer sẽ hạn chế đối với những bài toán phức tạp, dẫn đến việc học sẽ không tốt.
Số lượng node N trong input layer có phải là số lượng điểm dữ liệu trong tập train không ?
Câu trả lời là không phải. Nếu input layer có N nodes thì mỗi sample (mẫu) trong tập train sẽ có N chiều. Hay nói cách khác mỗi sample sẽ được biểu diễn bởi một vector có số chiều là N. ==> N không phải là số lượng điểm dữ liệu trong tập train.
Gradient descent
Đạo hàm là gì ?
Đạo hàm là sự biến đổi của của hàm số hay còn gọi là độ dốc của đồ thị. Ví dụ : f(x) = x^2 +1 . Khi đó f'(x) = 2x. Ở đây, với x =1 thì f'(x) = 2, với x =2 thì f'(x)=4. Ta thấy x càng tăng thì f'(x) càng tăng, hay giá trị của hàm số sẽ càng tăng. Một cách hiểu khác là hàm số f(x) sẽ càng tăng lên khi x tăng từ 1 lên.
Đạo hàm riêng ?
Khi mà hàm số có nhiều biến hơn 1. Ví dụ như f(x,y) = 2x+3y thì khi đó khái niệm đạo hàm riêng sẽ ra đời. Ở đây sẽ phân ra 2 khái niệm là đạo hàm riêng trên x, và đạo hàm riêng trên y. Đạo hàm riêng trên x, sẽ muốn xem x nó ảnh hưởng thế nào đến f(x,y). Đạo hàm riêng trên y, sẽ muốn xem y ảnh hưởng thế nào đến f(x,y).
Gradient descent
Vậy Gradient descent là gì? Về bản chất thì nó là một thuật toán giúp việc tìm giá trị nhỏ nhất của hàm số, ví dụ f(x) dựa trên đạo hàm, hoặc f(x,y,...) dựa trên đạo hàm riêng của từng biến. Ví dụ : với f(x) = x^2 +1 => f'(x) = 2x. Ta sẽ thực hiện các bước như sau để tìm giá trị nhỏ nhất của f(x):
- Khởi tạo giá trị x = x0 tùy ý
- Gán x = x - learning_rate * f’(x) ( learning_rate là hằng số không âm ví dụ learning_rate = 0.001)
- Tính lại f(x): Nếu f(x) đủ nhỏ thì dừng lại, ngược lại tiếp tục bước 2
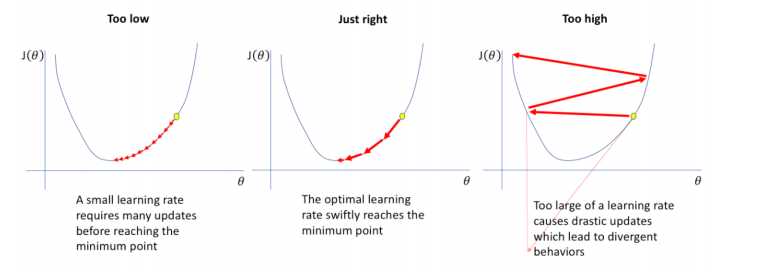
Việc chọn hệ số learning_rate cực kì quan trọng, có 3 trường hợp:
- Nếu learning_rate nhỏ: mỗi lần hàm số giảm rất ít nên cần rất nhiều lần thực hiện bước 2 để hàm số đạt giá trị nhỏ nhất.
- Nếu learning_rate hợp lý: sau một số lần lặp bước 2 vừa phải thì hàm sẽ đạt giá trị đủ nhỏ.
- Nếu learning_rate quá lớn: sẽ gây hiện tượng overshoot (như trong hình dưới bên phải) và
không bao giờ đạt được giá trị nhỏ nhất của hàm.
![]()
Scalar là gì, Vector là gì, Matrix là gì, Tensor là gì?
- Scalar là đại lượng chỉ độ lớn của cái gì đó, hay biểu diễn giá trị nào đó, mà không có hướng.
- Vector : Khi dữ liệu biểu diễn dạng 1 chiều, người ta gọi là vector.
- Matrix: Khi dữ liệu dạng 2 chiều, người ta gọi là ma trận, kích thước là số hàng * số cột
- Tensor: Khi dữ liệu nhiều hơn 2 nhiều thì sẽ được gọi là tensor, ví dụ như dữ liệu có 3 chiều.
Mình xin dừng lại tại đây, mình sẽ tiếp tục viết phần 2, mong các bạn góp ý cho mình với ạ.
Tham Khảo
[1] Sách Deep Learning Cơ Bản của Nguyễn Thanh Tuấn. Website : https://nttuan8.com/ [2] https://viblo.asia/p/mot-so-ham-kich-hoat-trong-cac-mo-hinh-deep-learning-tai-sao-chung-lai-quan-trong-den-vay-part-1-ham-sigmoid-bWrZn4Rv5xw
[3] Machine Learning Cơ Bản https://machinelearningcoban.com/
All rights reserved
