
Nhận diện khuôn mặt với mạng MTCNN và FaceNet (Phần 2)
Bài đăng này đã không được cập nhật trong 4 năm
Chào mừng các bạn đã quay lại với series "Nhận diện khuôn mặt với mạng MTCNN và FaceNet" của mình. Ở phần 1, mình đã giải thích qua về lý thuyết và nền tảng của 2 mạng là MTCNN và FaceNet. Nếu chưa đọc phần 1, các bạn có thể đọc qua trước khi qua phần này để hiểu cơ chế hoạt động dễ dàng hơn nhé, link phần 1 tại đây. Về bài này, mình sẽ hướng dẫn các bạn cách để xây dựng và inference một model hoàn chỉnh cho bài toán Face Recognition. Toàn bộ phần code bên dưới được mình viết bằng ngôn ngữ Python với Framework chính là PyTorch, áp dụng module được implement sẵn theo paper mang tên facenet-pytorch và một số thư viện phụ trợ khác như OpenCV. OK, let's get started!

Examples về Face Detection từ GitHub của facenet-pytorch
1. Chuẩn bị:
Trước hết, mình muốn nhắc lại rằng chúng ta chỉ đang inference lại model đã được pretrain, không tiến hành xây dựng và train model từ đầu. Vì vậy, nếu các bạn muốn biết cách tự xây dựng và train từ đầu các kiến trúc mạng này thì có thể comment phía bên dưới để mình soạn một bài hướng dẫn cách implement lại 2 model trên nhé.
Đầu tiên, ngoài Python với phiên bản mình khuyến khích là 3.8, ta cần cài một số thư viện cần thiết cho quá trình xây dựng và chạy code. Các thư viện và phiên bản đi kèm bao gồm:
torch==1.8.0
torchvision==0.9.0
numpy==1.19.2
opencv-python==4.5.1.48
Các bạn có thể lấy file requirements.txt ở trên GitHub của mình (mình có để link ở phần cuối bài) và tiến hành cài đặt bằng một câu lệnh đơn giản là pip install -r requirements.txt. Mình khuyến khích các bạn cài đặt toàn bộ thư viện và chạy trên một môi trường ảo như Anaconda để tránh vấn đề conflict với các thư viện đã cài sẵn trong máy. Về hướng dẫn cài đặt và sử dụng Anaconda thì các bạn có thể tìm kiếm dễ dàng trên Google nhé.
Tiếp theo, chúng ta sẽ cần tìm kiếm một model implement từ paper của cả MTCNN lẫn FaceNet. Vì chúng ta chỉ thực hiện inference nên cần tìm các repo đã được train để file pretrained trên các tập dữ liệu lớn. Rất tiện lợi cho chúng ta khi đã có Repository này trên Github, các bạn có thể clone về và sử dụng. Tuy nhiên, đối với bài này, để đơn giản hóa quá trình inference, các bạn chỉ cần chạy câu lệnh sau để tiến hành cài đặt module trên vào máy:
pip install facenet-pytorch
Vậy là chúng ta đã xong các bước chuẩn bị, phần tiếp theo mình sẽ giới thiệu cách sử dụng MTCNN ngay trong module facenet-pytorch để detect khuôn mặt và capture để lưu trữ thông tin khuôn mặt.
2. Face Detection với MTCNN:
Nhận diện khuôn mặt của các bạn trực tiếp ngay trên webcam, tại sao không?
2.1 Detect Face bằng OpenCV và MTCNN:
Trước hết, ta cần khai báo thư viện và check xem sẽ sử dụng CPU hay GPU với CUDA-support cho bài này. Thực tế cho thấy mạng MTCNN rất nhẹ, có thể dễ dàng chạy trên CPU của những laptop mỏng nhẹ hay đời cũ (mình có test trên con i5-6200U và khả năng detect vẫn khá ổn)
import cv2
from facenet_pytorch import MTCNN
import torch
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
Tiếp theo, ta sẽ gọi ra 1 object từ class MTCNN đi kèm một số config như sau:
mtcnn = MTCNN(thresholds= [0.7, 0.7, 0.8] ,keep_all=True, device = device)
Thresholds chính là mức thresholds cho 3 lớp mạng P, R và O. Mặc định sẽ là [0.6, 0.7, 0.7] nhưng vì mình muốn tăng độ chính xác nên truyền vào 3 mức cao hơn như trên. Keep_all để xác định việc chúng ta có detect và trả về tất cả các mặt có thể trong bức hình hay không, mình muốn nên để giá trị True.
Về việc load video từ webcam, ta sẽ sử dụng hàm cv2.VideoCapture() của OpenCV để gọi webcam và ghi lại từng frame ảnh. Set cho kích thước của webcam về theo kích thước mong muốn (Như trong code của mình là 640x480) và tiến hành khoanh box cho từng frame:
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH,640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT,480)
while cap.isOpened():
isSuccess, frame = cap.read()
if isSuccess:
boxes, _ = mtcnn.detect(frame)
if boxes is not None:
for box in boxes:
bbox = list(map(int,box.tolist()))
frame = cv2.rectangle(frame,(bbox[0],bbox[1]),(bbox[2],bbox[3]),(0,0,255),6)
cv2.imshow('Face Detection', frame)
if cv2.waitKey(1)&0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
2 câu lệnh while và if trên dùng để khẳng định rằng chúng ta sẽ thu được 1 frame từ camera, tránh gây ra lỗi khi thực hiện detect phía dưới. Class MTCNN cung cấp cho ta một hàm tên detect, giúp trả về một list các boxes hình chữ nhật, mỗi box bao gồm 2 tọa độ tương ứng 2 góc của box(bbox[0], bbox[1] là cặp tọa độ (x,y) của điểm góc trái trên của hình chữ nhật, góc phải dưới tương tự). Khi đó, công việc của chúng ta chỉ còn là kiểm tra xem có box nào được trả về không và dùng lệnh cv2.rectangle để tạo ra một hình hộp chữ nhật với 2 góc đã cho ở trên (và màu đỏ  )
)
Cuối cùng thì ta sẽ đặt nút tắt bằng nút ESC và release khi kết thúc chương trình. Kết quả sau khi chạy chương trình:
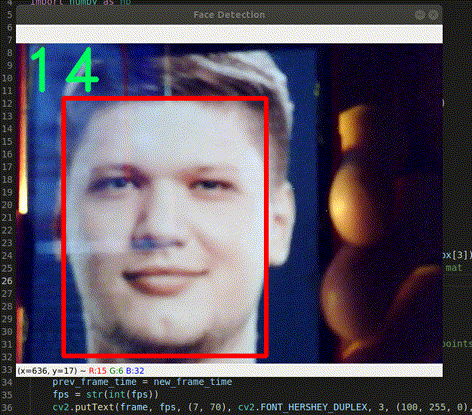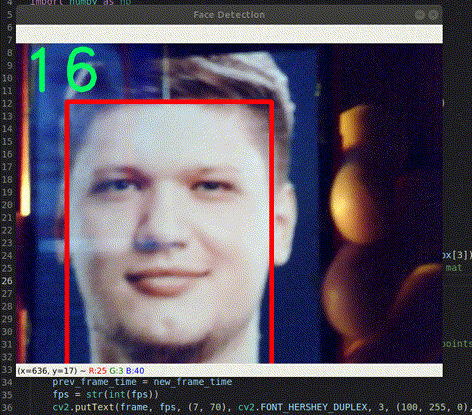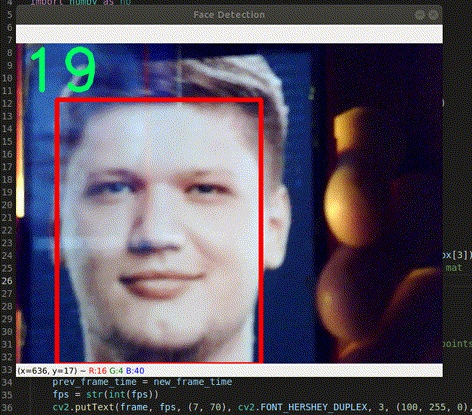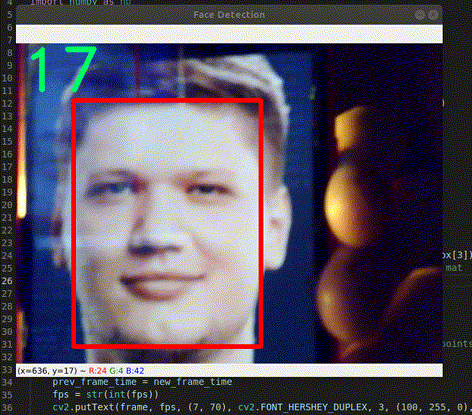
Hình 1. Face Detection với S1mple
Vậy là các bạn đã hoàn thành được một mô hình theo dõi khuôn mặt đơn giản rồi. Hãy đến với công việc tiếp theo: Lưu trữ khuôn mặt của bạn để tiến hành phân biệt khuôn mặt sau đó.2.2 Capture Face:
Về cơ bản, phần code của Capture sẽ không khác gì lắm so với phần Detect, chỉ thêm vào một số biến như count - dùng để đếm số lượng ảnh; leap - bước nhảy, tức máy sẽ lấy ảnh sau mỗi leap frame. Ngoài ra, biến truyền vào cho Class MTCNN cũng có chút thay đổi, như việc thêm margin nhằm lấy box to hơn hay thay đổi giá trị post_process về False, nhằm giữ cho những pixel ảnh được lưu sẽ không bị normalization về khoảng [-1,1] (sẽ rất cần thiết khi inference, tuy nhiên để lưu thì chúng ta không cần để như vậy)
Code:
import cv2
from facenet_pytorch import MTCNN
import torch
from datetime import datetime
import os
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
IMG_PATH = './data/test_images/'
count = 50
usr_name = input("Input ur name: ")
USR_PATH = os.path.join(IMG_PATH, usr_name)
leap = 1
mtcnn = MTCNN(margin = 20, keep_all=False, post_process=False, device = device)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH,640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT,480)
while cap.isOpened() and count:
isSuccess, frame = cap.read()
if mtcnn(frame) is not None and leap%2:
path = str(USR_PATH+'/{}.jpg'.format(str(datetime.now())[:-7].replace(":","-").replace(" ","-")+str(count)))
face_img = mtcnn(frame, save_path = path)
count-=1
leap+=1
cv2.imshow('Face Capturing', frame)
if cv2.waitKey(1)&0xFF == 27:
break
cap.release()
cv2.destroyAllWindows()
Lúc này, ta sẽ không dùng hàm detect() có trong class nữa, mà dùng hàm forward thẳng qua class. Hàm này sẽ trả về ảnh dựa trên 2 tọa độ góc của box chứa mặt người, sau khi đã crop&resize ảnh về đúng kích thước đầu ra mong muốn của mạng FaceNet dưới (160x160)
Trong paper gốc của MTCNN có nói tới Face Alignment (Căn chỉnh khuôn mặt). Face Alignment giúp khuôn mặt dù có bị quay ngang, bị chéo mặt hay thậm chị bị mất nhiều chi tiết do điều kiện ngoại cảnh, lệch ra khỏi khung hình... cũng có thể "căn chỉnh" lại về trung tâm bức ảnh với hướng mặt thẳng chính giữa như mong muốn được.
Tuy nhiên, trong Repo mà mình đang sử dụng hoặc trong một Repo nổi tiếng khác implement lại MTCNN và FaceNet bằng Tensorflow, Alignment thực chất chỉ là việc crop ảnh theo tọa độ, resize theo kích thước mong muốn và margin thêm vào kết quả cuối cùng chứ không align ảnh khuôn măt về đúng dạng "thẳng, trung tâm". Hình dưới đây sẽ cho bạn cái nhìn rõ nét hơn về Face Alignment "thực sự' là như thế nào.
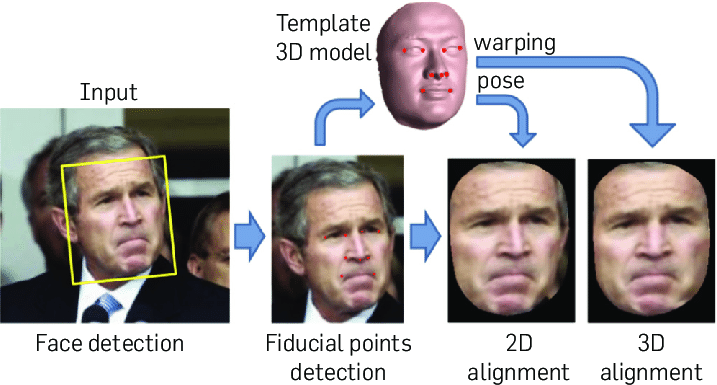
Hình 2. Face Alignment dựa theo phương pháp 2D Alignment và 3D Alignment
Quay trở lại bài toán, tổng cộng sẽ có 50 ảnh được lưu vào máy theo đường dẫn như IMG_PATH. Tên của file ảnh sẽ theo định dạng "năm-tháng-ngày-giờ-phút-giây-số thứ tự ảnh.jpg". Ví dụ: 2021-07-03-22-39-2216.jpg là ảnh thứ 50-16=34 của lần lấy, trong ngày 3/7/2021 và vào lúc 22'39''22'''.
Vậy là xong, chúng ta đã có một folder với 50 chiếc ảnh mặt (mình xin phép không show lên đây vì nó khá là kinh dị  ). Alright, giờ ta sẽ tống toàn bộ chỗ ảnh này vào trong mạng FaceNet và tiến hành inference nhận dạng khuôn mặt nhé!
). Alright, giờ ta sẽ tống toàn bộ chỗ ảnh này vào trong mạng FaceNet và tiến hành inference nhận dạng khuôn mặt nhé!
3. Update FaceList và Face Recognition với FaceNet:
Chắc chắn rồi, khi đã khoanh vùng được khuôn mặt, tại sao không phân biệt xem đây là mặt ai cơ chứ? Ăn bún đậu thì phải có mắm tôm đi kèm đúng không
3.1 Cập nhật FaceList:
Đầu tiên, vẫn là khai báo thư viện và khai báo các biến toàn cục. Lần này, ta sẽ sử dụng thêm một số thư viện khác:
import glob
import torch
from torchvision import transforms
from facenet_pytorch import InceptionResnetV1, fixed_image_standardization
import os
from PIL import Image
import numpy as np
IMG_PATH = './data/test_images'
DATA_PATH = './data'
embeddings = []
names = []
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
Lúc nãy mình có nói tới việc normalize rất quan trọng trong inference: Khi dữ liệu được chuẩn hóa về 1 khoảng cố định, thuật toán tối ưu Gradient Descent sẽ đưa ra được kết quả converge nhanh chóng hơn và tránh bị các vấn đề liên quan tới Vanishing/Exploding Gradient. Hàm sau là một hàm normalize đơn giản, giúp đưa pixel ảnh về trong khoảng [-1,1] mà vẫn giữ được distribution gốc của nó:
def trans(img):
transform = transforms.Compose([
transforms.ToTensor(),
fixed_image_standardization
])
return transform(img)
Trong đó, hàm fixed_image_standardization được viết như sau:
def fixed_image_standardization(image_tensor):
processed_tensor = (image_tensor - 127.5) / 128.0
return processed_tensor
Tiếp theo, ta sẽ khai báo về model sẽ sử dụng. Như mình có trình bày ở phần 1 và paper gốc, FaceNet sử dụng cấu trúc mạng InceptionV1 và đầu ra là một Feature Vector 128 chiều. Tuy nhiên do cấu trúc mạng InceptionV1 đã cũ, tỷ lệ chính xác đã bị các mạng bây giờ vượt xa cũng như tốc độ tính toán của máy tính đã có sự cải thiện đáng kể so với năm 2015, tác giả của repository trên đã sử dụng kiến trúc mạng mới là InceptionResnetV1 với đầu ra là một Feature Vector 512 chiều. Ngoài ra, mạng được pretrained trên tập dữ liệu mới là VGGFace2 và CASIA-WebFace, trong code mình sử dụng pretrained của tập thứ 2:
model = InceptionResnetV1(
classify=False,
pretrained="casia-webface"
).to(device)
model.eval()
Tham số classify được gán bằng False, nhằm đảm bảo đầu ra sẽ là 1 Feature Vector chứ không phải kết quả đã được classify theo tập pretrained. Lệnh model.eval() để khai báo cho PyTorch rằng mình đang evaluation, không phải training. Giờ chúng ta đã sẵn sàng để tạo lập embed từ ảnh các khuôn mặt rồi:
for usr in os.listdir(IMG_PATH):
embeds = []
for file in glob.glob(os.path.join(IMG_PATH, usr)+'/*.jpg'):
try:
img = Image.open(file)
except:
continue
with torch.no_grad():
embed = model(trans(img).to(device)
embeds.append(embed.unsqueeze(0))) #1 anh, kich thuoc [1,512]
if len(embeds) == 0:
continue
embedding = torch.cat(embeds).mean(0, keepdim=True) #dua ra trung binh cua 50 anh, kich thuoc [1,512]
embeddings.append(embedding) # 1 cai list n cai [1,512]
names.append(usr)
user là tên của các folder trong IMG_PATH, đồng nghĩa là tên của user. Khi đó, list names sẽ là danh sách tên của các user trong folder. Với mỗi folder (user), ta xét toàn bộ ảnh, mỗi ảnh sẽ dùng model đã được load pretrained trên để sinh ra một embed với kích thước [1,512]. Quay trở lại lúc nãy, chúng ta đã lấy tổng cộng là 50 ảnh, vậy ta sẽ có tổng cộng là 50 embeds cho 1 cá nhân. Tuy nhiên, ta chỉ cần 1 embeds, đại diện cho 1 cá nhân. Vì vậy, ta sẽ sử dụng hàm torch.cat() để đưa list về 1 tensor 2 chiều và sử dụng hàm torch.mean() để lấy giá trị trung bình cho toàn bộ embeds. Kết quả cuối cùng sẽ được thêm vào list embeddings, đại diện cho tập hợp các embedding của các user, ứng với đó là 1 giá trị name của user với cùng index trên tập names.
Sau cùng, ta sẽ một lần nữa concatenate list embeddings lại dưới dạng tensor và lưu thành một file .pth, còn tập hợp tên user sẽ được lưu dưới dạng .npy:
embeddings = torch.cat(embeddings) #[n,512]
names = np.array(names)
torch.save(embeddings, DATA_PATH+"/faceslist.pth")
np.save(DATA_PATH+"/usernames", names)
Vậy là chúng ta đã có cách để tạo và cập nhật danh sách khuôn mặt dưới dạng embedding-name. Giờ sẽ là bước cuối, classify khuôn mặt dựa theo FaceList đã có sẵn.
3.2 Face Recognition dựa theo FaceList:
Nếu nói vui vui thì phần này như là tổng hợp của toàn bộ những gì mình làm ở trên vậy (cả nghĩa đen lẫn nghĩa bóng luôn
). Mình sẽ bỏ qua phần khai báo thư viện, các biến toàn cục và tập trung vào triển khai các hàm trong phần này.
Lần này, mình sẽ trình bày theo cách ngược lại, đi từ hàm main chính và triển khai sang các hàm phụ. Cấu trúc hàm main chính khá giống phần Face Detection: Lấy frame từ camera, lấy tọa độ các box khuôn mặt và vẽ ô chữ nhật. Tuy nhiên, vì đây là bài toán Face Recognition cho nên ta cần phải thêm một số bước nữa để thu được kết quả đúng ý muốn. Code như sau:
embeddings, names = load_faceslist()
while cap.isOpened():
isSuccess, frame = cap.read()
if isSuccess:
boxes, _ = mtcnn.detect(frame)
if boxes is not None:
for box in boxes:
bbox = list(map(int,box.tolist()))
face = extract_face(bbox, frame)
idx, score = inference(model, face, embeddings)
if idx != -1:
frame = cv2.rectangle(frame, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 6)
score = torch.Tensor.cpu(score[0]).detach().numpy()*power
frame = cv2.putText(frame, names[idx] + '_{:.2f}'.format(score), (bbox[0],bbox[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0,255,0), 2, cv2.LINE_8)
else:
frame = cv2.rectangle(frame, (bbox[0],bbox[1]), (bbox[2],bbox[3]), (0,0,255), 6)
frame = cv2.putText(frame,'Unknown', (bbox[0],bbox[1]), cv2.FONT_HERSHEY_DUPLEX, 2, (0,255,0), 2, cv2.LINE_8)
cv2.imshow('Face Recognition', frame)
if cv2.waitKey(1)&0xFF == 27:
break
Đầu tiên, ta sẽ cần load lại FaceList và usernames từ 2 file lưu ở trên bằng hàm load_facelitst(). Hàm này sẽ trả về 2 tập là embeddings và usernames:
def load_faceslist():
embeds = torch.load(DATA_PATH+'/faceslist.pth')
names = np.load(DATA_PATH+'/usernames.npy')
return embeds, names
Sau đó, ta vẫn sẽ cho frame vào hàm detect của MTCNN để trả về list tọa độ các box có chứa mặt. Bên dưới, chúng ta thấy điểm khác biệt đầu tiên là câu lệnh face = extract_face(bbox, frame). Câu lệnh này dùng để trích xuất các khuôn mặt từ những tọa độ box vừa nhận được.
Nhiều bạn lúc này sẽ có thắc mắc: "Tại sao không dùng hàm forward thẳng từ Class MTCNN như trong phần Face Capture mà phải tự xây hàm riêng?"
Ý tưởng của mình trong bài này sẽ cần tới 2 thứ: Tọa độ bounding box và ảnh mặt chứa trong box đó. Tọa độ mình sẽ dùng để khoanh vùng trên frame ảnh để hiển thị; Ảnh mặt dùng để tạo embedding để tìm độ similarity với các embedding khác trong FaceList. Vì vậy, theo lý thuyết mình hoàn toàn có thể sử dụng cả 2 hàm là detect() và forward() để đưa ra 2 thứ trên.
Tuy nhiên, mình không thể đảm bảo việc liệu 2 hàm trên, khi sử dụng độc lập, sẽ đưa ra cùng thứ tự identity với nhau hay không (nghĩa là, với cùng 1 index trong 2 tập boxes và faces sẽ đưa ra 1 cặp box-face, và mình không chắc liệu cặp đó sẽ cùng là 1 người hay không). Vì vậy, mình sẽ lấy từng tọa độ bounding box, sau đó dựa vào tọa độ đó để crop&resize ra ảnh măt, tương tự như hàm forward() có sẵn:
def extract_face(box, img, margin=20):
face_size = 160
img_size = frame_size
margin = [
margin * (box[2] - box[0]) / (face_size - margin),
margin * (box[3] - box[1]) / (face_size - margin),
]
box = [ #box[0] và box[1] là tọa độ của điểm góc trên cùng trái
int(max(box[0] - margin[0] / 2, 0)), #nếu thêm vào margin bị ra khỏi rìa ảnh => đưa về điểm 0
int(max(box[1] - margin[1] / 2, 0)),
int(min(box[2] + margin[0] / 2, img_size[0])), #nếu thêm vào margin bị ra khỏi rìa ảnh => đưa về tọa độ của ảnh gốc
int(min(box[3] + margin[1] / 2, img_size[1])),
] #tạo margin mới bao quanh box cũ
img = img[box[1]:box[3], box[0]:box[2]]
face = cv2.resize(img,(face_size, face_size), interpolation=cv2.INTER_AREA)
face = Image.fromarray(face)
return face
frame_size chính là kích thước frame đầu vào lấy từ webcam (như trong bài mình là 640x480); margin sẽ có giá trị = 20 để tương ứng như margin khi capturing face. Chúng ta sẽ đi sâu vào câu lệnh này một chút: margin * (box[2] - box[0]) / (face_size - margin). Đặt box[2] - box[0] là chiều rộng của bounding box, ta giả sử rằng chiều rộng đó bằng đúng img_size - margin, tức 140. Khi đó, margin[0] mới sẽ trở thành 20*140/140 = 20, tức là giữ nguyên margin = 20 do chiều rộng sau khi cộng với margin mới sẽ có kích thước = 140+20 = 160, tức bằng chính img_size. Ngược lại, nếu chiều rộng nhỏ hơn, vào khoảng 130, khi đấy ta sẽ cần margin một khoảng nhỏ hơn 20, vào khoảng 18,5px.
Tại sao margin lại có giá trị nhỏ hơn mà không phải lớn hơn để đưa ảnh về đúng img_size? Vì margin ở đây được tính sau khi chúng ta sử dụng câu lệnh cv2.resize() về 160x160, nghĩa là, ta phải đảm bảo cho phần margin sau khi được resize sẽ có giá trị đúng bằng 20px. Việc này giải thích lý do vì sao ảnh nhỏ hơn mà chúng ta lại không sử dụng margin lớn hơn để "bù đắp" cho phần thiếu đó.
Các câu lệnh sau đó sẽ cập nhật tọa độ của box theo margin mới, crop từ ảnh gốc theo tọa độ mới và resize về kích thước 160x160px. Hàm trả về một PIL Image chứa ảnh mặt đã qua cắt tỉa.
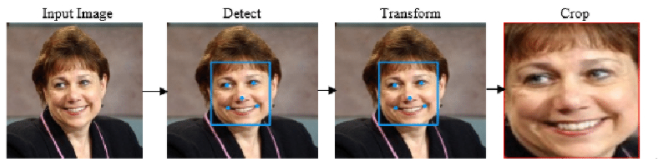
Hình 3. Ảnh mặt khi đã được extract
Cuối cùng là hàm inference. Chúng ta sẽ dùng hàm này để kết xuất embedding cho từng ảnh mặt - thứ đã được extract từ hàm extract_face() ở trên. Chú ý là đầu vào của mình có một thuộc tính là threshold, thuộc tình này sẽ quyết định viêc mạng có lấy mặt của các bạn hay không. Vì vậy, nếu có thể, các bạn hãy thử brute-force tìm threshold phù hợp với điều kiện bài toán của mình nhé:
def inference(model, face, local_embeds, threshold = 3, power):
#local: [n,512] voi n la so nguoi trong faceslist
embeds = []
embed = model(trans(face).to(device)
embeds.append(embed.unsqueeze(0)))
detect_embeds = torch.cat(embeds) #[1,512]
norm_diff = detect_embeds.unsqueeze(-1) - torch.transpose(local_embeds, 0, 1).unsqueeze(0)
norm_score = torch.sum(torch.pow(norm_diff, 2), dim=1) #(1,n)
min_dist, embed_idx = torch.min(norm_score, dim = 1)
print(min_dist*power, names[embed_idx])
if min_dist*power > threshold:
return -1, -1
else:
return embed_idx, min_dist.double()
Dễ thấy, phần kết xuất embedding sẽ tương tự như trong phần Update Facelist. Tuy nhiên, ta không lưu lại vào FaceList mà sẽ tiến hành so sánh khoảng cách giữa embedding vừa nhận được với các embeddings khác có trong FaceList. Câu lệnh norm_diff sẽ tính toán ra một ma trận với kích thước [1,512,n], là khoảng cách (hiệu) của từng chiều trong 512 chiều của embedding nhận được với các embeddings trong FaceList. Sau đó, norm_score sẽ là tổng bình phương (vì chúng ta quan tâm khoảng cách, không quan tâm giá trị là âm hay dương) các khoảng cách của n tập hiệu khoảng cách trên. Để dễ hình dung hơn, các bạn có thể tham khảo quá trình biến đổi mà mình đã minh họa dưới đây:

Hình 4. Minh họa về quá trình biến đổi embedding và kết xuất kết quả
Kết quả cuối cùng là một dãy các score, mỗi cột là score điểm khác biệt giữa face nhận được với faces trong FaceList. Điểm khác biệt càng nhỏ, độ similarly giữa 2 face càng lớn. Vì vậy chúng ta sẽ trả về index của khuôn mặt trong FaceList có score nhỏ nhất so với face cần inference. Như ở phần chú ý đầu tiên, mình có đặt thêm 1 mức threshold - nếu min_score > threshold thì ta có thể đánh giá rằng khuôn mặt này chưa có trong FaceList. Khi đó, giá trị index trả về sẽ là -1, tức sẽ không nhận dạng khi gặp giá trị này và trả về box Unknown.
Giờ chỉ còn công cuộc in kết quả ra màn hình thôi. Sử dụng thêm cv2.putText() ở rìa ngoài của box và ta sẽ có thành quả như này:
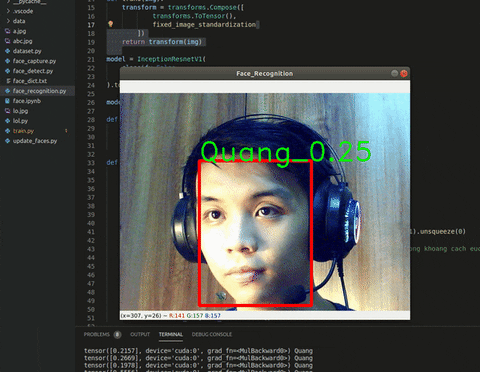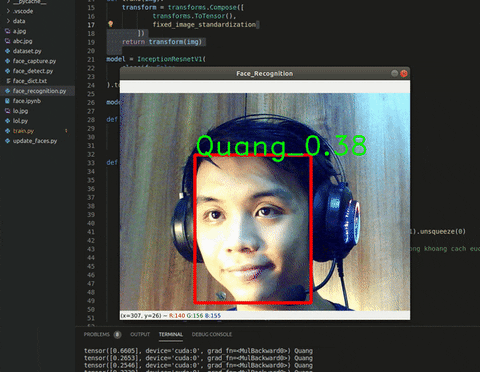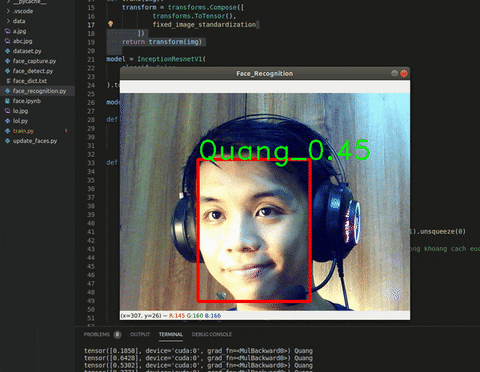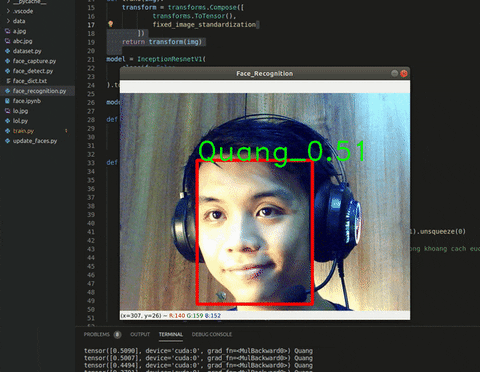
Hình 5. Kết quả
4. Một số hạn chế:
Mặc dù kết quả thu được là khá khả quan, tuy nhiên vẫn còn nhiều tồn tại trong phần inference của mình. Một số vấn đề mình có thể liệt kê ra như:
- Do phần implement của tác giả chưa có công cụ Align mặt như trong paper nên khi người dùng có những góc cạnh khác nhau, embedding tương ứng cũng sẽ bị sai lệch khá nhiều (mình đang phát triển một phần code align đơn giản ngay trong Git của mình, tuy nhiên mình chưa tích hợp vào bài này do còn một số vấn đề liên quan tới việc crop ảnh)
- Phần Classifier dựa chủ yếu vào việc tính khoảng cách giữa các embeddings (khá giống thuật toán k-NN với k = 1) cho nên kết quả chưa thực sự quá tốt. Để khắc phục, chúng ta có thể xây dựng một đầu Classifier đơn giản mà mạnh mẽ hơn như SVM hoặc một mạng FCN nhỏ và áp dụng phương pháp Online Training.
- Khi gặp những điều kiện bất lợi về độ sáng (đặc biệt là trời tối, thiếu ánh sáng) và các yếu tố ngoại cảnh, độ chính xác của mạng sẽ giảm khá đáng kể. Ta có thể tăng mức threshold để chấp nhận score cao, hoặc thêm dữ liệu ở các điều kiện đó. Tuy nhiên, do mình muốn nén mô hình lại (lấy giá trị mean của các embeddings cùng 1 user) cho nên thêm dữ liệu ở nhiều điều kiện khác nhau lại có thể là điểm trừ (?)
- Như các bạn đã thấy ở gif demo phần 2.1 Face Detection, mình có sử dụng một bức hình từ điện thoại và mạng vẫn có thể nhận diện được. Kết quả như vậy là do MTCNN chưa có khả năng nhận diện vật thể sống (Liveness Detection). Trong tương lai mình sẽ hướng dẫn xây dựng một phần code về bài toán này, các bạn muốn tìm hiểu thêm có thể theo dõi mình để không bị bỏ lỡ khi mình ra bài nhé.
5. Tổng kết:
Qua bài đọc trên, mình đã hướng dẫn các bạn hiểu rõ hơn về cơ chế hoạt động của 2 mạng MTCNN và FaceNet cũng như tự build một hệ thống nhận diện khuôn mặt hoàn chỉnh. Mọi source code về phần inference trên đã được mình up lên tại: https://github.com/pewdspie24/FaceNet-Infer
Nếu các bạn thấy bài viết hay, hãy cho mình một upvote để tiếp thêm động lực cho nhiều bài sắp tới nhé; Còn nếu các bạn có phần nào chưa hiểu rõ hoặc muốn góp ý với mình thì hãy comment ở phần phía dưới nhé. Cảm ơn các bạn đã theo dõi và đọc bài của mình. See ya!
6. Tài liệu tham khảo:
All rights reserved
