
Một số hàm mất mát sử dụng cho Object Detection
Bài đăng này đã không được cập nhật trong 4 năm
Object Detection hay phát hiện đối tượng là một trong các tác vụ chính được quan tâm nhiều nhất của thị giác máy, thường hướng tới việc phát hiện các thể hiện của các đối tượng của một lớp nhất định trong một ảnh. Trong suốt thời gian nghiên cứu xung quanh tác vụ này có rất nhiều mô hình và các thành phần bổ trợ như hàm mất mát được đề xuất cũng như không ngừng được cải tiến. Bài viết này liệt kê một số hàm mất mát được sử dụng trong các mô hình Object Detection cũng như trình bày về cách chúng hoạt động và lý do tại sao chúng lại được sử dụng nhiều như vậy.
Focal Loss Function
Nguồn gốc ra đời
Nếu như đã từng tìm hiểu về các mô hình Object Detection, ta có thể dễ dàng nhận thấy rằng các mô hình có độ chính xác cao nhất cho đến nay hầu hết được dựa trên các phương pháp 2-stage, trong đó bộ phân loại được áp dụng cho một tập hợp các vị trí đối tượng ứng viên của đối tượng cần phát hiện. Ngược lại, các mô hình dựa trên các phương pháp 1-stage (mà đại diện cho nó là các mô hình với cái tên kháy đểu cực mạnh: YOLO - You Only Look Once) được cho là nhanh hơn và đơn giản hơn bằng cách áp dụng cho việc lấy mẫu thường xuyên, dày đặc các vị trí đối tượng có thể có tiềm năng, nhưng cho đến nay đã kéo theo độ chính xác của mô hình 2-stage.
Để giải quyết vấn đề trên, nhóm tác giả Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár đã tìm tòi nghiên cứu và chỉ ra rằng sự mất cân bằng dữ liệu giữa các nhóm foreground-background là nguyên nhân chính dẫn tới sự kém hiệu quả trong bài báo Focal Loss for Dense Object Detection.
Nguyên văn: In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause.
Tiếp đó, để giải quyết vấn đề này, nhóm tác giả giải quyết sự mất cân bằng lớp này bằng cách định hình lại hàm lỗi entropy chéo tiêu chuẩn để giảm trọng số lỗi được gán cho các ví dụ được phân loại tốt. Chi tiết cách tái định hình này sẽ được trình bày cụ thể hơn ở bên dưới.
Vấn đề mất cân bằng và một số hướng giải quyết trước đó
Như đã trình bày trên, sự mất cân bằng dữ liệu giữa các nhóm foreground-background là nguyên nhân chính dẫn tới sự kém hiệu quả. Vậy sự mất cân bằng này ảnh hưởng như thế nào quá trình huấn luyện cũng như độ chính xác của mô hình?
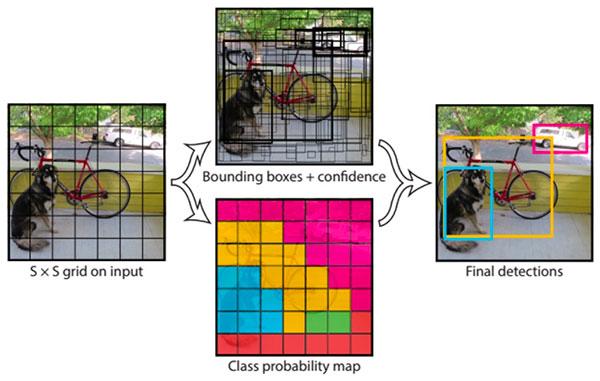
Hình ảnh từ bài viết https://www.pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
Như hình mình họa cho cách thức hoạt động của mô hình YOLO, ta có thể thấy rằng có rất nhiều bounding box được xác định, tuy nhiên trong số chúng chỉ có 4 box thuộc lớp cần xác định. Bởi vậy, đây là một ví dụ rõ nét cho thấy sự mất cân bằng giữa các nhóm foreground-background. Tiếp đến với hàm lỗi thông thường được sử dụng là Cross Entropy có công thức như sau:
Do các nhãn bằng 0 không có giá trị đóng góp vào hàm lỗi nên công thức có thể viết lại như sau:
Có thể thấy rằng đóng góp của tất cả các lớp đều bằng nhau và bằng và dẫn đến khả năng dự đoán đối với các lớp thiểu số bị ảnh hưởng xấu do vốn đã có sự mất cân bằng giữa các nhóm foreground và background. Vậy nên để giải quyết vấn đề này, một hàm mất mát mới đã được đề xuất với tên Balanced Cross Entropy bằng cách cải tiến thêm trọng số cho công thức trên như sau:
Với là tần xuất của lớp và là một giá trị rất nhỏ được thêm vào để tránh trường hợp mẫu bằng 0. Mặc dù được kì vọng như vậy nhưng hàm lỗi này vẫn không thu được kết quả quá khả quan và từ đó hàm Focal Loss ra đời.
Focal Loss Function
Focal Loss Function hay hàm lỗi tiêu điểm được đề xuất trên cơ sở phát triển hàm lỗi Cross Entropy và cải tiến bằng cách bổ sung hai tham số và trong đó:
- được sử dụng nhằm thể hiện tỉ lệ số box sinh ra chứa thông tin của backgroung và foreground nhằm giúp cân bằng lại việc mất cân bằng giữa background và foreground lúc sinh ra các box.
- thể hiện “tập trung” vào các vùng khó phân biệt, nếu càng lớn thì giá trị lỗi ở vùng dễ phân biệt sẽ càng nhỏ và giá trị lỗi của càng vùng khó phân biệt sẽ đóng góp nhiều hơn vào tổng giá trị chung của mô hình.
Bằng cách sử dụng trên sử dụng hai tham số trên, công thức của Focal Loss Function sẽ là:
Do đó, có thể thấy rằng, việc cách sử dụng thêm nhân tử đã có tác dụng rất lớn đến việc thay đổi ảnh hưởng của từng nhóm lớp đến giá trị hàm lỗi cũng như quá trình lấy đạo hàm và cập nhật trọng số. Một cách rõ ràng hơn, focal loss function giảm sự ảnh hưởng của các vùng dễ nhận biết và giảm ít hơn với các vùng khó nhận biết bằng cách sử dụng giá trị vốn tăng dần theo độ khó của quá trình nhận biết với là xác suất thuộc lớp đó. Sự chênh lệch này càng tăng lên với mỗi giá trị tăng dần của $\gamma, thường được chọn trong khoảng thừ 0 đến 5.
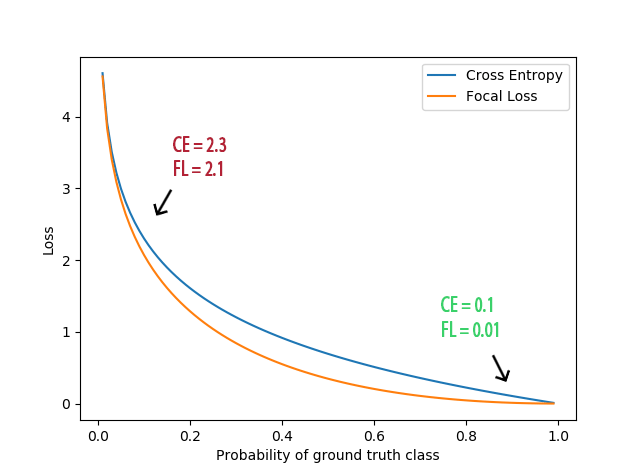
Hình ảnh từ https://forum.machinelearningcoban.com/t/focal-loss-for-dense-object-detection/5220/2
Về mấy cái liên quan đến đạo hàm, mình định viết nhưng tìm đọc thì có anh Phạm Đình Khánh đã viết rồi, mình viết lại chắc cũng chẳng rõ hơn được nên mọi người đọc tiếp ở blog của anh ấy nhé.
Kết quả thực nghiệm
Để chứng mình tính hiệu quả của Focal Loss Function, nhóm tác giả của bài báo đã cài đặt và dùng chung với kiến trúc mô hình RetinaNet. Tại thời điểm năm 2018 khi bài báo được công bố, kết quả thu được của mô hình khá ấn tượng (khi so sánh với một số mô hình nổi trội trong thời gian đó như Faster-RCNN và YOLOv2) và hứa hẹn sẽ còn nhiều được phát triển tiếp trong tương lai.
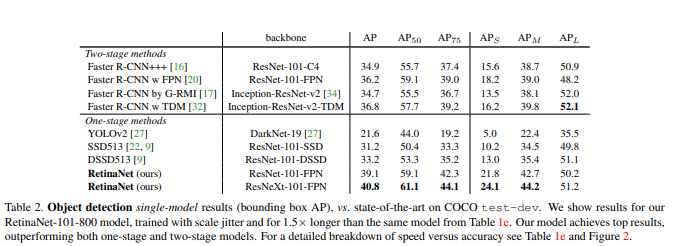
Ngay sau nghiên cứu này (khoảng 2 tháng) Focal Loss Function cũng được thử nghiệm khi nhóm tác giả của YOLOv3 phát triển mô hình này. Tuy nhiên, theo như những gì đã được chia sẻ, hàm mất mát này không hoạt động tốt với YOLOv3 có vẻ như họ đã giải quyết tốt được vấn đề này.
Cuối cùng, một mô hình nữa cũng đã sử dụng Focal loss function có thể kể đến đó là CenterNet được công bố trong bài báo CenterNet: Keypoint Triplets for Object Detection . Về mô hình này thì idol team mình đã có một bài viết khá chi tiết, mọi người có thể tìm đọc ở đây.
Varifocal Loss và Iou-aware Classification Score
Varifocal Loss function (tạm dịch là hàm mất mát đa tiêu) là một hàm mát mát được sử dụng để đào tạo các mô hình dense object detector nhằm dự đoán IACS (Iou-aware Classification Score , một khái niệm được định nghĩa trong cùng paper), lấy cảm hứng từ Focal Loss Function. Tuy vậy, không giống như Focal Loss Function, Varifocal Loss function xử lý các mẫu positives và negatives không đối xứng.
Nguồn gốc ra đời
Có thể dễ dàng nhận thấy rằng, hầu hết các mô hình object detection, bất kể thuộc nhóm 1-stage hay 2-stage thường tạo một tập hợp các bounding box cùng với điểm phân loại từ đó dùng một số phương pháp chẳng hạn như non-maximum suppression nhằm loại bỏ các ox trùng lặp trên một vật thể. Tuy vậy, theo ý kiến được trình bày ở paper VarifocalNet: An IoU-aware Dense Object Detector điều này có thể ảnh hướng xấu đến hiệu xuất phát hiện bởi họ cho rằng không phải lúc nào điểm phân loại cũng là một ước lượng tốt nhằm ̀ xác định độ chính xác độ chính các về localization của các bounding box và các localized bouding box với điểm phân loại thấp có thể bị xóa nhầm trong NMS.
Để hình dùng rõ hơn về vấn đề này, ta cần đọc thêm về paper đã được trích dẫn có tên là Acquisition of localization confidence for accurate object detection. Tuy vậy trước hết, ta hãy cùng ôn lại cách thức hoạt động của non-maximum suppression. Nói một cách ngắn gọn thì thường được sử dụng để giảm bớt số lượng các khung hình được sinh ra một cách đáng kể̉ và để thực hiện điều đó, non-maxium suppression gồm hai bước:
- Giảm bớt số lượng các bounding box bằng cách lọc bỏ toàn bộ những bounding box có xác suất chứa vật thể nhỏ hơn một ngưỡng threshold nào đó, thường là 0.5.
- Đối với các bouding box giao nhau, non-max suppression sẽ lựa chọn ra một bounding box có xác xuất chứa vật thể là lớn nhất. Sau đó tính toán chỉ số giao thoa IoU với các bounding box còn lại.
- Dựa trên kết quả đã tính toán, ta xác định 2 hoặc nhiều các bounding boxes đang overlap nhau rất cao bằng cách so sánh chỉ số IOU với một ngưỡng xác định trước và từ đó, ta sẽ xóa các box có có xác xuất thấp hơn và giữ lại bouding box có xác xuất cao nhất nhằm thu được một bounding box duy nhất cho một vật thể.

Hình ảnh từ https://www.analyticsvidhya.com/blog/2020/08/selecting-the-right-bounding-box-using-non-max-suppression-with-implementation/
Vậy vấn đề ở đây là gì? Ta đều biết rằng khi loại bỏ các box overlap trong quá trình non-maximum suppression được trình bày ở quá trình trên thông tin về localization hay có thể diễn giải là độ phù hợp của vùng đề xuất với ground-truth lại không được sử dụng trong quá trình loại bỏ và giữ lại một box duy nhất đại diện cho vật thể. Để dễ hình dùng hơn, ta cùng quan sát ví dụ sau:

Như được thể hiện trong hình trên, các bounding box được phát hiện có mức độ phân loại cao hơn trái ngược lại có phần trùng lặp nhỏ hơn với ground-truth tương ứng. Khi đó sự sai lệch giữa độ tin cậy của phân loại và độ chính xác của bản địa hóa có thể dẫn đến các bounding box được bản địa hóa chính xác bị loại bỏ khi so sánh với các hộp kém chính xác hơn trong NMS. Vấn đề này được nói khá kĩ ở trong paper nên mình cũng không trình bày lại nữa.
Vậy để có thể sử dụng thêm thông tin về localization trong wuas trình này, một số phương pháp chẳng hạn như dự đoán điểm IoU bổ sung (Iou-aware single-stage object detector for accurate localization) hoặc sử dụng điểm trung tâm (Fully convolutional one-stage object detection.) được đề xuất nhằm sử dụng chúng như một ước lượng cho độ chính xác bản địa hóa và nhân chúng với điểm phân loại để xếp hạng các phát hiện trong NMS với hi vọng sẽ làm giảm bớt vấn đề lệch lạc giữa điểm phân loại và độ chính xác bản địa hóa đối tượng. Tuy nhiên, chúng có thể khiến hiệu xuất trở nên kém hơn vì nhân hai dự đoán không hoàn hảo có thể dẫn đến cơ sở xếp hạng kém hơn cũng như việc thêm một nhánh mạng bổ sung để dự đoán điểm nội địa hóa không phải là một giải pháp hay và gây thêm gánh nặng tính toán.
Từ những lý do trên cùng với lý do được trình bày ở phần Focal Loss, IoU-aware classification score và Varifocal Loss được công bố sau một quá trình dài nghiên cứu và thử nghiệm của nhóm tác giả Haoyang Zhang, Ying Wang, Feras Dayoub, Niko Sünderhauf.
Nguyên lý hoạt động
Iou-aware Classification Score
Iou-aware Classification Score hay IACS được định nghĩa là phần tử vô hướng của vectơ điểm phân loại, trong đó giá trị tại vị trí nhãn lớp chân lý cơ bản là IoU giữa hộp giới hạn được dự đoán và giá trị cơ bản của nó, và 0 ở các vị trí khác. Để tính toán giá trị này, một sô phương pháp đã được sử dụng, cụ thể bao gồm:
Biểu diễn đặc trưng box sao
Nhằm phục vụ cho quá trình đoán nhận IACS một phương pháp thể hiện đặc trưng của bounding box hình sao đã được sử dụng. Phương pháp này sử dụng đặc trưng tại 9 điểm lấy mẫu cố định để biểu diễn một bounding box với deformable convolution. Cách biểu diễn này có thể nắm bắt được hình dạng của bouding box cũng như thông tin ngữ cảnh của chúng điều này rất cần thiết để công thức hóa sự sai lệch giữa bouding box được dự đoán và ground-truth.
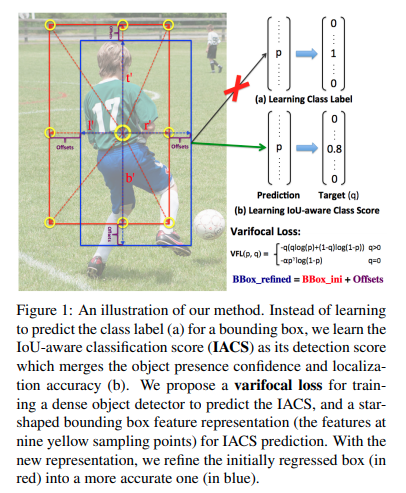
Cụ thể, với một vị trí lấy mẫu (x, y) trên mặt phẳng hình ảnh (hoặc một điểm chiếu trên bản đồ đối tượng địa lý), trước tiên ta hồi quy một bounding box ban đầu từ nó với tích chập 3x3. Theo FCOS, hộp giới hạn này được mã hóa bởi vectơ 4D có nghĩa là khoảng cách từ vị trí (, ) đến bên trái, trên, phải và dưới cùng của hộp giới hạn tương ứng. Với vectơ khoảng cách này, ta chọn theo phương pháp phỏng đoán chín điểm lấy mẫu tại: , , , , , , , và , rồi ánh xạ chúng lên bản đồ đối tượng địa lý và sau đó các đặc trưng tại chín điểm chiếu này được tích chập bởi deformable convolution để biểu diễn một bounding box. Vì các điểm này được chọn theo cách thủ công mà không có thêm gánh nặng dự đoán, nên biểu diễn mới này được cho rằng sẽ giúp tính toán trở nên hiệu quả hơn.
Công thức và cách tính toán
Để ước lượng sự sai lệch về Iou-aware Classification Score, nhóm tác giả giới thiệu một hàm lỗi mới có tên gọi là Varifocal Loss được lấy ý tưởng từ Focal Loss. Cụ thể hơn, nhóm tác giả đã mượn ví dụ về ý tưởng trọng số từ Focal Loss để giải quyết vấn đề mất cân bằng lớp khi đào tạo dense object detector để hồi quy IACS liên tục. Tuy nhiên, không giống như Focal Loss xử lý các mẫu positives và negatives như nhau, họ đã xử lý chúng không đối xứng. Từ đó, hàm Varifocal Loss cũng dựa trên hàm lỗi entropy chéo nhị phân và được định nghĩa là:
trong đó là giá trị IACS đã dự đoán và q là giá trị điểm mục tiêu. Đối với foreground, cho lớp ground-truth được gắn bằng IoU giữa bounding box được tạo và ground truth của nó (gt IoU) trong khi với các background, giá trị của sẽ bằng 0.
Như được thể hiện ở trên, Varifocal Loss chỉ làm giảm đóng góp tổn thất từ các ví dụ tiêu cực ( = 0) bằng cách giảm giá trị lỗi của chúng với hệ số và không giảm tỷ lệ tổn thất của các ví dụ dương (q> 0) theo cách tương tự. Bên cạnh đó, bằng cách lấy cảm hứng từ PISA (Iou-balanced loss functions for single-stage object detection) , các mẫu positive được đánh trọng số với training target nhằm mục đích khiến cho đóng góp của các mẫu positive sẽ tỉ lệ thuận với giá trị IoU với ground truth của chúng.
Kết quả thực nghiệm với VarifocalNet
Để kiểm tra tính hiệu quả của Iou-aware Classification Score cũng như hàm lỗi mới, nhóm tác giả đã cài đặt chúng trong VarifocalNet bằng cách gắn ba thành phần trên vào kiến trúc mạng FCOS và loại bỏ nhánh trung tâm ban đầu. Sau quá trình huấn luyện và kiểm tra trên tập COCO test-dev, kế quả cho thấy so với các strong baseline ATSS, VFNet được ∼2.0 AP gaps với các backbone khác nhau, ví dụ: 46.0 AP so với 43.6 AP với backbone ResNet-10. Chi tiết kết quả được thể hiện trong paper, vì hình khá lớn nên mình sẽ không chụp và thêm vào bài viết.
Tiếp đó, nhóm tác giả cũng so sánh hiệu xuất khi sử dụng hàm lỗi mới của họ với khi sử dụng một số hàm lỗi khác. Kết quả thu được như sau:
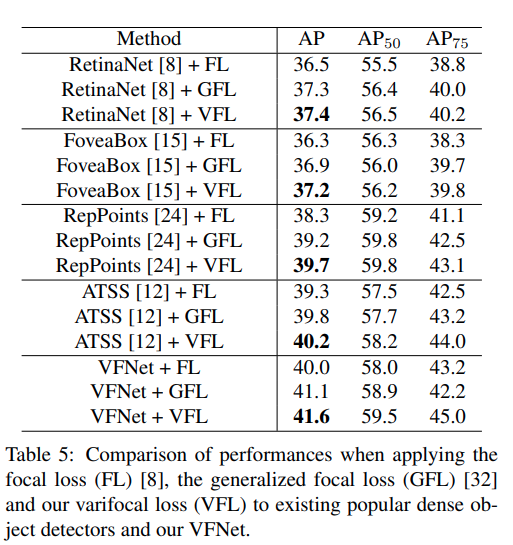
Kết luận
Bài viết này trình bày về một số hàm lỗi đã được cải tiến nhằm giải quyết một số vấn đề của Object Detection bao gồm Focal Loss và Varifocal Loss cũng như trình bày về cách chúng hoạt động và lý do tại sao chúng lại được sử dụng nhiều như vậy. Có thể thấy rằng tương tự như ta chỉ có thể sửa sai khi biết mình sai như thế nào, việc chọn hàm lỗi phù hợp cũng đóng góp không nhỏ vào việc cải thiện hiệu năng của các mô hình. Bài viết đến đây là kết thúc cảm ơn mọi người đã giành thời gian đọc.
Tài liệu tham khảo
- Focal Loss trong RetinaNet
- Focal Loss for Dense Object Detection
- VarifocalNet: An IoU-aware Dense Object Detector
- Iou-aware single-stage object detector for accurate localization
- Fully convolutional one-stage object detection.
- Acquisition of localization confidence for accurate object detection
- Non Maximum Suppression
All rights reserved
