[MongoDB P2] Kiến trúc hệ thống của mongodb
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Hello các bạn trở lại với series bài viết "Những gì mình biết về MongoDB", series nói về một NoSQL DB cực kỳ phổ biến là MongoDB.
Trong nội dung bài này mình sẽ chia sẻ về kiến trúc hệ thống của MongoDB. Từ đó, các bạn sẽ hiểu được từng thành phần của MongoDB là gì và làm nhiệm vụ gì.
MongoDB Standalone
Thực ra thì cũng không có gì để nói nhiều về kiến trúc của "standalone" vì cái tên của nó cũng đủ nói lên hết cả.
Standalone mongodb nó sinh ra vốn để dùng cho việc dev, lab hay demo. Thường khi đó người ta quan tâm hơn về việc sử dụng nó ở tầng nghiệp vụ hơn là việc db hoạt động với cơ chế như thế nào.
Và standalone thì DB sẽ không có tính sẵn sàng cao (High Availability) cũng như không có khả năng mở rộng (Scalable). Do vậy trong thực tế để giải quyết bài toán High Availability thì người ta sẽ dùng Replication, và để có thể dễ dàng scale hệ thống thì sẽ sử dụng Sharding.
Chúng ta sẽ cùng tìm hiểu các kỹ thuật này nhé!
Sử dụng Replication
Replication là gì
Với standalone mongodb, nếu server của bạn gặp sự cố thì dữ liệu của bạn sẽ bị gián đoạn, service thì không connect được còn data có thể bị mất.
Vậy thì một suy nghĩ tự nhiên là sẽ phải có phương án gì để tăng tính chịu lỗi của hệ thống lên để khi 1 service chạy dịch vụ bị down thì cũng sẽ không bị mất dữ liệu. Và câu trả lời chính là sử dụng Replication.
Ý tưởng của Replication là tạo ra một replica set, là một tập hợp của các process mongod và cùng duy trì một bộ dữ liệu. Replica set sẽ mang lại tính dư thừa (redundancy) và tính khả dụng cao (HA) cho database.
Kiến trúc của mongodb sử dụng replica set như sau:
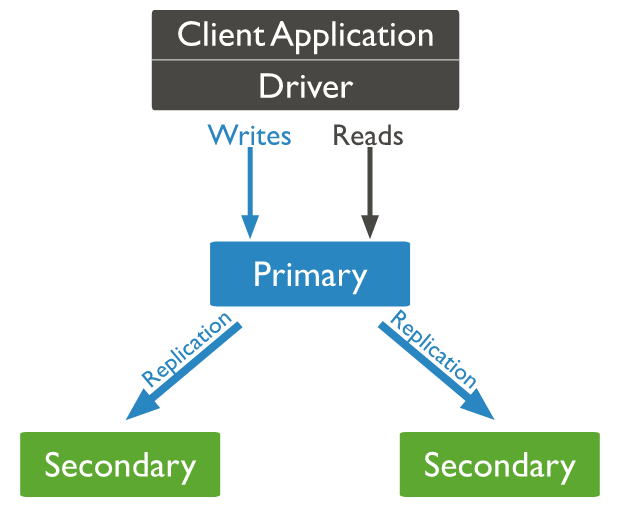
Quá trình hoạt động thì mọi thao tác ghi dữ liệu được thực hiện vào node primary và sau đó dữ liệu được nhân bản (replicate) sang các node secondary (hay gọi là các replicas)
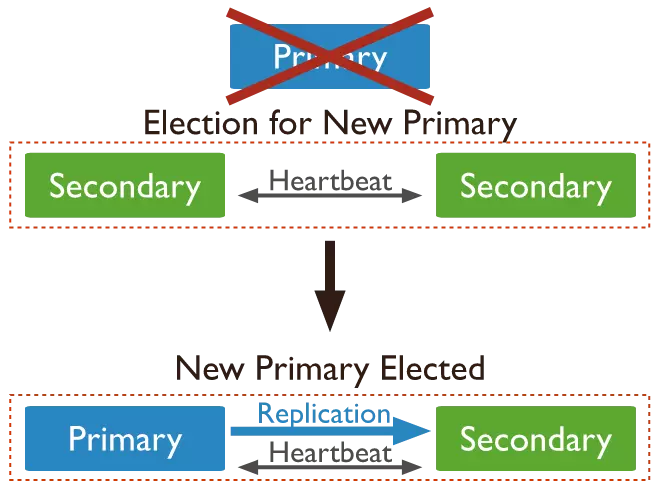
Khi node primary bị lỗi thì trong số node secondary (replicas node) còn lại sẽ bầu ra một node mới lên làm primary để tiếp tục xử lý.
Có một số lưu ý về cơ chế replication này:
- Trong một replicaset chỉ có thể có 01 primary node và có thể có nhiều secondary node (là các replicas) và có thể có 01 arbiter node
- Việc ghi dữ liệu vào DB chỉ được thực hiện thông qua primary node, việc đọc dữ liệu có thể được thực hiện qua các secondary node
- Arbiter node chỉ đóng vai trò thực hiện bầu chọn khi cần chọn ra primary mới, bản thân nó không lưu dữ liệu của db
- Arbiter thì luôn là arbiter, còn primary thì có thể chuyển thành secondary và ngược lại secondary có thể chuyển thành primary
- Để đảm bảo việc bầu chọn primary thì số lượng node phải là lẻ
Automic Failover
Node primary được coi là bị lỗi nên như nó không trao đổi với các node khác trong replicaset trong một khoảng thời gian nhất định, được quy định bởi tham số "electionTimeoutMillis" và có giá trị mặc định là 10 giây.
Một node secondary phù hợp sẽ thực hiện bầu chọn primary mới và tự đề cử nó lên làm primary mới. Cluster sẽ thực hiện bầu chọn để chọn ra primary mới và trở lại hoạt động đọc/ghi như bình thường. Các node có thể được cấu hình một trọng số nhất định để ưu tiên lên làm primary trong quá trình bầu chọn.
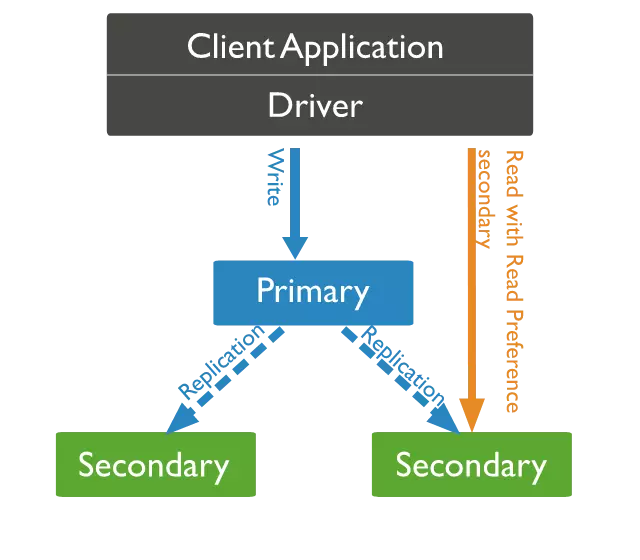
Đọc dữ liệu từ node secondary
Mặc định thì các client sẽ đọc dữ liệu từ node primary. Tuy nhiên client có thể cấu hình đọc dữ liệu đến các node secondary.
Nhưng lưu ý rằng các node secondary được đồng bộ dữ liệu từ node primary về, do đó dữ liệu đọc từ node secondary có thể không phải là dữ liệu mới nhất. Do vẫn có thể có những khoảng gap giữa primary và secondary.
Vì vậy các bạn cũng phải xem xét kỹ nếu muốn thực hiện đọc từ node secondary.
Sử dụng Sharding
Sharding là gì
Với việc sử dụng Replication thì chúng ta đã giải quyết được bài toán về việc an toàn cho dữ liệu, không lo bị mất dữ liệu hay gián đoạn dịch vụ khi node primary bị lỗi nữa.
Tuy nhiên bài toán tiếp theo là nếu như hệ thống của chúng ta ngày càng lớn và đòi hỏi một khả năng xử lý lớn hơn hay dung lượng lữ trữ lớn hơn thì Replication không giải quyết được bài toán đó. Ta cần một giải pháp để có thể dễ dàng scale hệ thống khi cần.
Chúng ta có thể xem xét phương án sử dụng Vertical scale: Đơn giản là ta tăng dung lượng RAM/CPU/Disk cho các node. Nhưng cách này có giới hạn về phần cứng. Vì server thì cũng có số lượng hữu hạn khe cắm RAM, CPU..
Và để giải quyết tốt bài toán scale thì mongodb cung cấp tính năng Sharding, tức là hỗ trợ chia nhỏ dữ liệu database thành nhiều phần (gọi là các shard) và mỗi phần đó sẽ được xử lý một một shard server. Phương án này gọi là "Horizontal Scale" và nó cực kỳ hiệu quả.
Do vậy khi cần scaleup hệ thống ta chỉ cần đơn giản tăng số lượng shard cho db và tương ứng là tăng số lượng Shard server lên.
Và một mongodb sử dụng sharding sẽ được gọi là một "sharded cluster"
Kiến trúc hệ thống Sharding
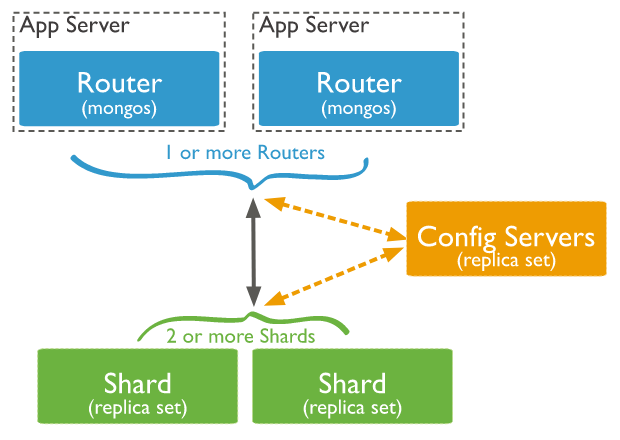
Một MongoDB sharded cluster bao gồm các thành phần chính sau:
- shard: Mỗi shard chứa một phần của dữ liệu đã được shard. Mỗi shard này lại có thể được triển khai dưới dạng một replicaset để tăng tính dự phòng cho dữ liệu của nó quản lý.
- mongos: Hoạt động như một query router, là phần giao diện với các client với sharded cluster. Client sẽ chỉ cần biết kết nối tới mongos, phần còn lại là kết nối tới shard nào, replicas nào sẽ do mongos điều phối và trong suốt với client
- config servers: Chứa thông tin metadata và các tham số cấu hình cho cluster. Ví dụ thông tin cấu hình các shard, các replicaset.. được lưu ở config server này. Và config server cũng có thể triển khai dưới dạng replicaset.
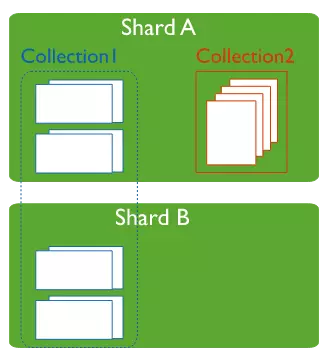
Shard Keys
MongoDB sử dụng shard key để phân phối các bản ghi (document) của các bảng (collection) tới các shard tương ứng. Shard key có thể gồm 1 hoặc nhiều field trong bảng đó.
Việc lựa chọn shard key được thực hiện ngay khi thực hiện shard một collection (bảng). Lưu ý rằng khi một collection đã được shard thì nó sẽ không thể được "unshard".
Trong một database, ta có thể shard một số collection cụ thể chứ không nhất thiết phải shard toàn bộ collection của database đó.
Best Practice: Kết hợp Sharding và Replication
Cả Replication và Sharding đều mang lại những giải pháp cho các vấn đề của một standalone mongodb. Và trong thực tế thì người ta sẽ luôn sử dụng cả 2 kỹ thuật này khi thiết kế và triển khai các mongodb cluster.
Kiến trúc tổng quan sẽ như sau:
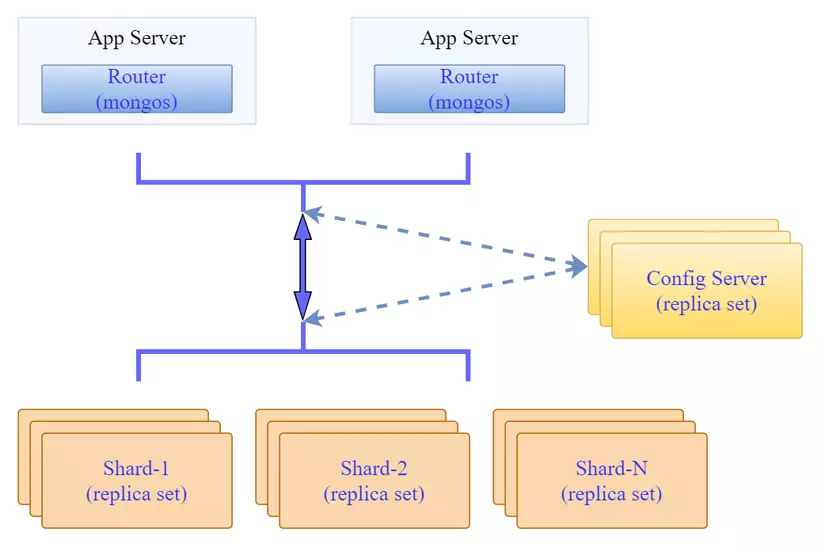
Trong đó các thành phần như Config server hay shard đều được triển khai dưới dạng replica set. Từ đó từng thành phần này đều có tính dự phòng về dữ liệu, và các shard thì cung cấp khả năng mở rộng cho cụm mongodb của chúng ta.
Tới đây thì hy vọng các bạn đã nắm được các khái niệm cơ bản và các thành phần trong một cụm sharded cluser của mongodb. Trong bài tiếp theo mình sẽ hướng dẫn cách cài đặt một standalone mongodb và một cụm sharded cluster theo đúng mô hình trên.
Nếu thấy bài viết hữu ích thì các bạn hãy ủng hộ bằng cách upvote bài viết để mình thêm động lực viết bài nhé!
Hẹn mọi người ở phần tiếp theo!
All rights reserved
