[Machinlearning] Nhận diện hành động với Temporal Segment Networks(TSN)
Bài đăng này đã không được cập nhật trong 4 năm
Trong phần này sẽ đưa ra các mô tả chi tiết về việc thực hiện nhận dạng hành động với TSN. Trước tiên sẽ giới thiệu các khái niệm cơ bản được sử dụng trong TSN. Sau đó sẽ mô tả chi tiết các yếu tố liên quan khác.
Temporal Segment Network (TSN)
Như đã đề cập trong phần trước, một trong những yếu điểm của ConvNet two-streams đó là không thể mô hình hóa các cấu trúc long-range temporal. Điều này chủ yếu là do hạn chế về sử lý các nội dung temporal bởi vì nó được thiết kể để xử lý tốt trên 1 frame ảnh duy nhất(spatial networks) hoặc một stack các frames trong một phân đoạn ngắn(temporal network). Tuy nhiên với các hành động phức tạp như hoạt dộng thể thao, bạo lực,... thường bao gồm nhiều giai đoạn và trong 1 khoảng thời gian tương đối dài. Vì vậy không thể áp dụng ConvNets two-streams cho các hành động như vậy. Để giải quyết vấn đề này TSN đã ra đời để giải quyết vấn đề này, nó cho phép mô hình hóa chuyển động trong toàn video.
Cụ thể, TSN nhằm mục đích sử dụng thông tin của toàn bộ video để dự đoán và TSN cũng bao gồm spatial stream ConvNets và temporal stream ConvNets. Thay vì chỉ làm việc trên các frame đơn lẻ hay stack frames thì TSN hoạt động trên một chuỗi các đoạn ngắn (snippets) được lấy mẫu không liên tục trên toàn bộ videos. Mỗi snippet này sẽ tạo ra một kết quả dự đoán sơ bộ về hành động trong chính nó. Sau đó dựa vào các kết quả của snippet để dự đoán. Trong các quy trình xử lý, TSN được tối ưu bằng cách cập nhật lặp lại các tham số của mô hình.
Cho một video V sẽ được chia ra thành K segments {S1, S2, .. SK} có thời lượng bằng nhau. Sau đó, TSN mô hình một chuỗi các snippets như sau
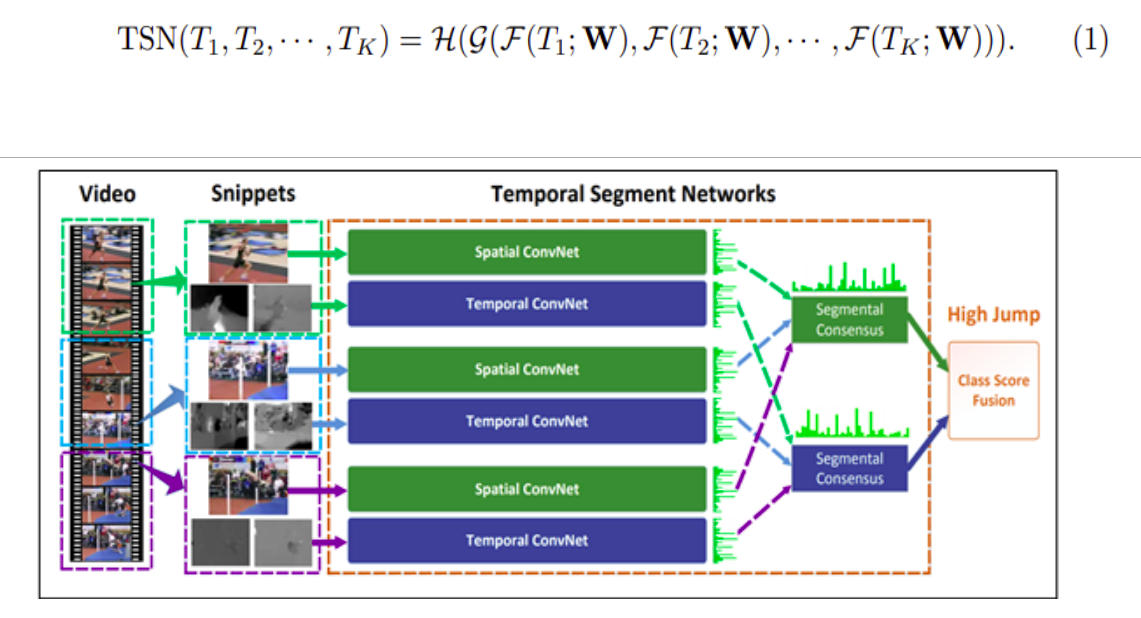
Mỗi video sẽ được chia thành K segments và một snippet ngắn sẽ được chọn ngẫu nhiễn từ mỗi segments này. Class score của các snippets khác nhau sẽ được hợp nhật bởi một hàm đồng thuận (segmental consensus function) để tạo ra sự đồng nhất, class score là giá trị dùng để dự đoán. Các kết quả dự đoán từ tất cả các phương thức sẽ được hợp nhất để đưa ra dự đoán cuối cùng. ConvNets trên tất cả các phân đoạn sẽ chia sẻ tham số với nhau.
Ở đây theo công thức (1) ta có (T1, T2,..., Tk) là một chuỗi các phân đoạn. Mỗi một Tk sẽ được lấy ngẫu nhiên từ segment Sk tương ứng. là hàm đại diện cho ConvNet với các tham số W hoạt động trên snippet Tk và cung cấp class score cho tất cả các lớp. Hàm đồng thuận sẽ kết hợp output từ nhiều snippets để có được sự đồng thuận về class giữa chúng. Dựa trên sự đồng thuận này, hàm dự đoán sẽ dự đoán xác suất của từng lớp hành động cho video V đã cho. Hàm Softmax sẽ được dùng làm hàm dự đoán. Kết hợp với cross-entropy tiêu chuẩn, final loss function liên hệ biểu thức đồng thuận G được định nghĩa như sau:
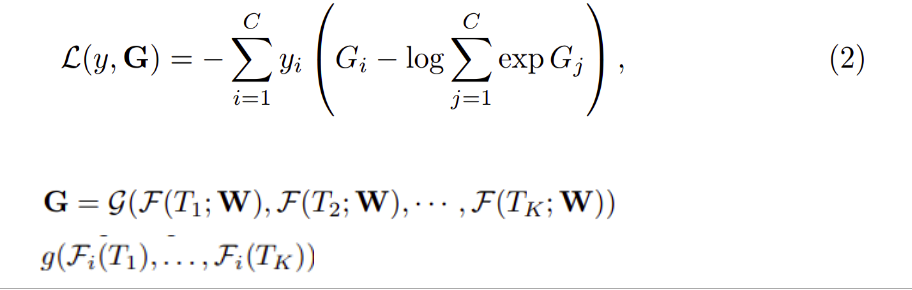
Trong đó, C là số lớp cần phân loại và yi là label groundtruth của lớp i. Theo các nghiến cứu trước đó, số snippets K=3 theo các tài liệu trước đây vể các temporal model . Ở đây hàm đồng thuận G được sử dụng với dạng đơn giản nhất trong đó Gi. Trong đó class score Gi được suy ra từ scores của class tương ứng trên tất cả các snippets, sử dụng hàm tổng g chính là tính trung bình để tính toán độ chính xác.
Tùy vào việc lựa chọn phương thức tính toán cho hàm tổng mà chúng ta sẽ có các thể hiện của TSN khác nhau. Điều này có ý nghĩa là cho phép sử dụng nhiều snippets kết hợp lại để tối ưu các tham số W với thuật toán back-propagation. Trong quá trình back-propagation, độ dốc(gradient) của các tham số W liên quan đến loss value L có thể được tính toán theo công thức sau:
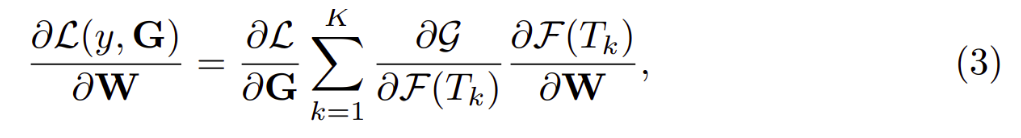
Với K là số lượng các segments mà TSN sử dụng. Khi sử dụng giải pháp tối ưu dựa trên gradient, ví dụ như là stochastic gradient descent (SGD) để tìm ra các tham số mô hình. Công thức (3) được dùng để đảm bảo rằng việc cập nhật các tham số sử dụng G phải được xuất phát từ tất cả snippet-level prediction. Tối ưu hóa mô hình theo cách này, TSN có thể học các tham số mô hình từ toàn bộ video thay vì chỉ sử dụng 1 snippet. Ngoài ra, khi cố định giá trị K cho tất cả các videos sẽ đảm bảo việc lấy mẫu theo các đoạn rời rạc và không cần phải sử dụng tất cả các frames của video. Nó làm giảm đáng kể chi phí để tính toán và đánh giá ConvNets so với các phương pháp trước đó.
Learning Temporal Segment Networks
TSN cung cấp một framework mạnh mẽ để thực hiện việc video-level learning, nhưng để đạt được hiệu suất tối ưu nhất cần phải quan tâm đến một số yếu tố ảnh hưởng đến hiệu suất như giới hạn số lượng mẫu huấn luyến. Trong phần này sẽ trình bày một số kỹ thuật nâng cao hiệu suất training của ConvNets cũng như là TSN.
Kiến trúc Mạng.
Kiến trúc mạng là một yếu tố cực kỳ quan trọng trong thiết kế neural network. Một số nghiên cứu trước đây đã chỉ ra rằng các cấu trúc sâu hơn giúp cải thiện hiệu suất nhận dạng [9,10]. Tuy nhiên, ConvNet two-streams lại sử dụng kiến trúc khá là nông. Trong cấu trúc của TSN sử dụng Inception with Batch Normalization (BN-Inception) làm build block, do nó cân bằng giữu độ chính xác và hiệu quả. Ban đầu BN-Inception được tinh chỉnh để thiết kế nên ConvNets two-stream. Cũng giống như ConvNets two-streams trong kiến trúc của TSN thì spatial stream ConvNet hoạt động trên các ảnh RGB đơn lẻ và temporal stream ConvNet sử dụng một stack các optical flow là đầu vào.
Đầu vào của mạng.
TSN kế thừa kiến trúc ConvNet two-streams nhưng có những cải tiến tiến bộ hơn. Ban đầu ConvNet two-streams sử dụng ảnh RGB cho spatial stream và stacked optical flow cho temporal stream. Ở đây, TSN sử dụng kết hợp thêm 2 phương thức input mới là RGB difference và warped optical flow fields.
Một ảnh RGB đơn lẻ thường chỉ mô tả thông tin tĩnh tại một thời điểm nào đó mà thiếu đi thông tin theo ngữ cảnh về các frame trước hoặc sau. Như được mô tả theo hình 3.6, sự khác biệt RGB giữa 2 frames liên tiếp mô tả sự thay đổi ngoại hình, có thể làm nổi bật vùng chuyển động tương ứng. Ứng dụng tài liệu TSN sử dụng stacked RGB defference làm phương thức input mới.
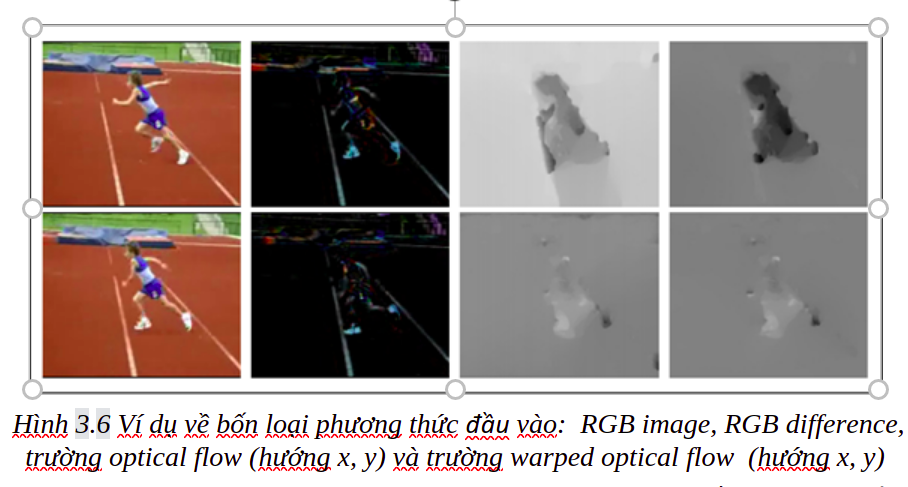
Temporal stream ConvNet sử dụng optical flow làm đầu vào và nhằm mục đích nắm bắt được thông tin chuyển động của đối tượng. Tuy nhiên, trong các video thực tế thường có thêm chuyển động của camera và các optical flow có thể không tập chung vào hành động của con người. Như trong hình 3.6 một lượng lớn chuyển động theo phương ngang được làm nổi bật trong trong background do chuyển động ngang của máy ảnh. Để giảm thiểu sự ảnh hưởng của camera, TSN sử dụng các trường warped optical flow để làm phương thức đầu vào bổ sung. Trích xuất warped optical flow bằng cách ước tính ma trận homography và sau đó bù chuyển động của camera [2]. Warped optical flow có vai trò triệt tiêu chuyển động của background và tập chung chuyển động vào đối tượng.
Huấn luyện mạng.
Vì các bộ dữ liệu để nhận dạng hành động là tương đối nhỏ, việc huấn luyện ConvNets gặp thách thức có nguy cơ bị over-fitting. Để giảm thiểu vấn đề này, một số chiến lược đã được thiết kế để đào tạo ConvNets trong TSN như sau
Cross Modality Pre-training. Pre-training là một cách hiệu quả để khởi tạo ConvNets khi mà dataset không có đủ mẫu để đào tạo. Vì spatial network lấy ảnh RGB làm input, nên tận dụng các mô hình đã được training trên ImageNet khi khởi tạo mạng này. Đối với các phương thức khác như optical flow và difference RGB, về cơ bản chúng thu được từ các khía cạnh khác nhau của dữ liệu video và phân phối của chúng khác với hình ảnh RGB. Sử dụng kỹ thuật cross modality pre-training, trong đó sử dụng các mô hình RGB để khởi tạo các giá trị cho temporal network. Đầu tiên, phân tách các optical flow fields thành khoảng từ 0 đến 255 bằng cách chuyển đổi tuyến tính. Bước này làm cho phạm vị của optical flow giống với cấu trúc một ảnh RGB. Sau đó, sửa đổi các trọng số lớp chập đầu tiên của các mô hình RGB để xử lý đầu vào của các optical flow fields. Cụ thể, tính trung bình các trọng số trên các channels RGB và sao chép các trọng số này theo số channels của input temporal network. Phương pháp này hoạt động tốt với các temporal networks và làm giảm khả năng bị over-fitting.
Regularization Techniques. Batch Normalization (BN) là một thành phần quan trọng để đối phó với vấn đề dịch chuyển đồng biến. Trong quá trình học, batch normalization sẽ ước tính giá trị trung bình và phương sai với mỗi batch và sử dụng chúng để chuyển đổi các giá trị kích hoạt này thành phân bố Gaussian tiêu chuẩn. Hoạt động này tăng tốc độ hội tụ của quá trình training nhưng cũng dẫn đầu khả năng bị over-fitting trong quá trình chuyển giao, do ước tính sai lệch của sự phân phối kích hoạt từ việc số lượng mẫu đào tạo hạn chế. Do đó, sau khi khởi tạo với các mô hình pre-training, ta sẽ cố định các tham số trung bình và phương sai của tất cả các lớp Batch Normalization trừ lớp đầu tiên. Do phân phối optical flow khác với hình ảnh RGB, giá trị kích hoạt của lớp chập đầu tiên sẽ có phân phối khác và cần ước tính lại giá trị trung bình và phương sai sao cho phù hợp. Giải pháp được đưa ra có tên là partial BN. Trong giải pháp này, sẽ bổ sung một extra dropout layer ngay sau global pooling layer trong kiến trúc BN-Inception để giảm hiệu ứng over-fitting. Tỷ lệ của dropout là 0.8 cho spatial stream ConvNets và 0.7 cho temporal stream ConvNets.
Data Augmentation. Thêm nhiều dữ liệu có thể tạo ra các mẫu đào tạo đa dạng và ngặn trặn khả năng over-fitting. Trong ConvNets two stream đã sử dụng cắt xén tự nhiên và xoay lật dữ liệu để gia tăng các mẫu đào tạo. Với TSN thì sử dụng 2 kỹ thuật khác: corner cropping (cắt góc.) và scale-jittering (chia tỉ lệ). Trong kỹ thuật cắt xén góc, các vùng được trích xuất chỉ được chọn từ các góc hoặc trung tâm của hình ảnh để tránh tập trung vào khu vực trung tâm của hình ảnh. Trong kỹ thuật mutil-scale scropping, đã điều chỉnh kỹ thuật scale-jitter được sử dụng trong phân loại ImageNet để nhận dạng hành động. Theo như tài liệu, khi cố định kích thước ảnh đầu vào (input image) hoặc luồng quang (optical flow) là 256x340, cùng với chiều rộng và chiều cao của vùng bị cắt được chọn ngẫu nhiên từ tập {256, 224, 192, 168} thì scale-jittering sẽ đạt hiệu quả tốt nhất. Cuối cùng, các vùng bị cắt ở phía trên sẽ được resize thành 224x224 để training trong mạng. Trong thực tế triển khai, để tăng dữ liệu training còn kết hợp cả scale jettering và ratio jittering.
Testing Temporal Segment Networks
Trong thực tế khi triển khai TSN thì tất cả các snippet-level ConvNets sẽ chia sẽ các tham số mô hình (model parameters) nên các mô hình đã được học có thể thực hiệc đánh giá frame-wise như là một ConvNets thông thường. Điều này cho phép chúng ta thực hiện so sánh bình đẳng với các mô hình đã học nhưng không sử dụng TSN framework. Cụ thể ở đây đã thử sử dụng mô hình của ConvNet two-streams như trong phần trươcs mình chia sẻ với 25 frames RGB hoặc stacked optical flow từ các video hành động và sử dụng phương pháp cắt góc để cắt lấy 4 góc và 1 trung tâm đồng thời xoay các frame được lấy mẫu để đánh giá ConvNets. Với hàm tổng từ các mạng không-thời gian sử dụng phương pháp trung bình trọng số. Khi đào tạo trong TSN framework thì hiệu suất giữa spatial stream ConvNet và optical stream ConvNet thấp hơn đáng kể so với ConvNets two-stream ban đầu. Theo như thử nghiệm của tác giả thì sẽ đặt trọng số cho các thông tim của spatial stream là 1 và optical stream là 1.5. Khi kết hợp với wraper optical flow thì trọng số sẽ được phân chia theo tỷ lệ 1 cho optical flow và 0.5 cho wraper optical flow. Và các trọng số này được sử dụng trong phương thức segmental consensus (đồng thuận) trước khi được chuẩn hóa bằng Softmax.
Vậy nên để kiểm tra các mô hình có đúng với quá trình huấn luyện sẽ sử dụng prediction scores của 25 frames hợp nhất với các luồng khác nhau trước khi chuẩn hóa với Softmax.
Đánh giá Temporal Segment Networks
Trong phần đánh giá này chủ yếu đánh giá và so sánh giữa ConvNets two-stream với TSN. Đầu tiên sẽ tìm hiểu ảnh hưởng của segmental consensus function và các kiến trúc ConvNets khác nhau. Để khách quan trong phần này chủ chỉ sử dụng ảnh RGB và optical flows làm các trường dữ liệu đầu vào cho 2 kiến trúc mạng trên. Như trong phần 3.1 đã đề cập rằng trong TSN thì số các segments K=3. Theo như số liệu trong tài liệu ta có bảng số liệu sau:
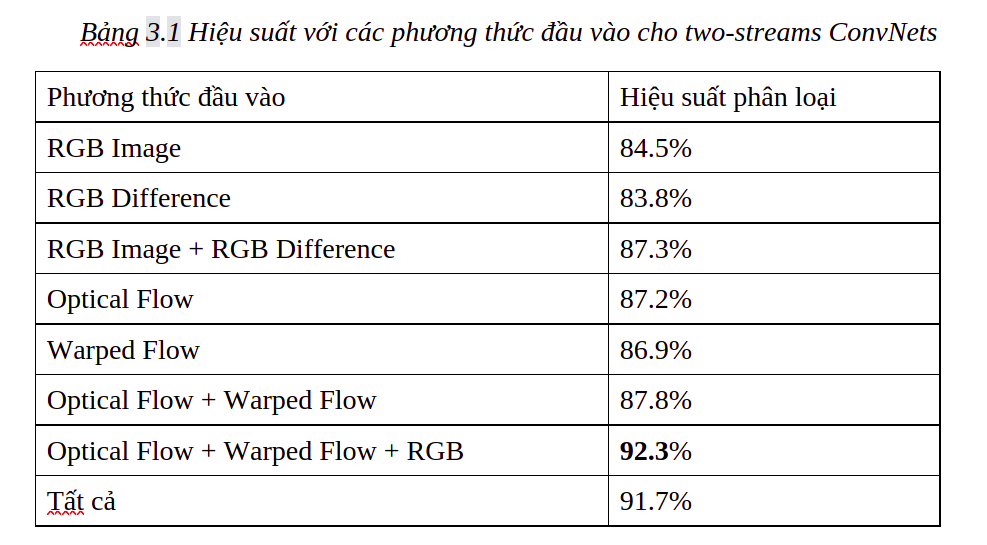
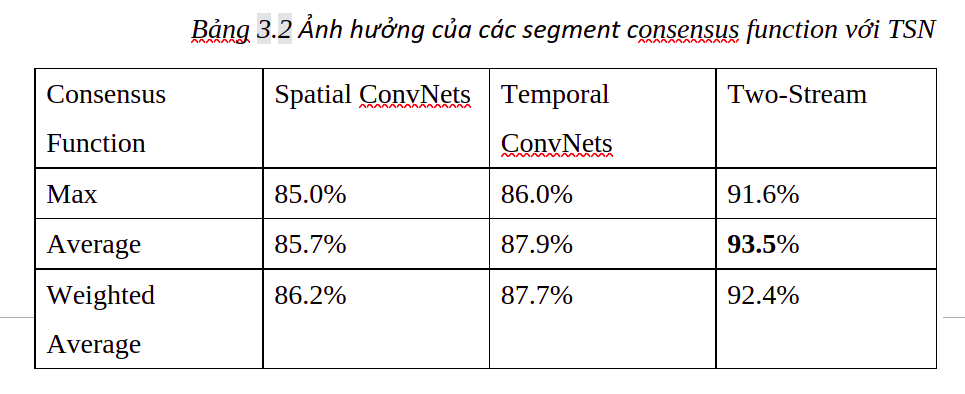
Theo công thức (1) một hàm đồng thuận được xác định bởi hàm tổng hợp g của nó. Ở đây ta có 3 đề cử cho g: (1) max pooling, (2) average pooling, (3) weighted average. Dựa vào kết quả của bảng 3.2, ta thấy rằng average pooling đạt được hiệu suất tốt nhất nên lựa chọn average pooling làm hàm tổng mặc định cho TSN.
Tổng hợp
Trong bài này đã trình bày các lý thuyết liên quan để phục vụ cho việc phân loại hành động của con người trong video. Trình bày một số giải pháp phân loại hành động con người trong video đã có trước đó, cũng như chỉ ra một số nhược điểm của các giải pháp này. Đây là những kiến thức cơ bản và nền tảng quan trọng trong việc phát triển giải pháp nhận diện các hành động bạo lực sẽ được trình bày trong bài sau.
Tài liệu tham khảo
[8] Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: NIPS. (2014) 568–576
[9] Soomro K, Zamir A R and Shah. UCF101: A dataset of 101 human actions classes from videos in the wild arXiv preprint arXiv 1212.0402, 2012
[10] Tran, D., Bourdev, L.D., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: ICCV. (2015) 4489–4497
[11] Wang, A. Klaser, C. Schmid, and C.-L. Liu. Action recognition by dense trajectories. In ¨ Proc. CVPR, pages 3169–3176, 2011.
[12] Wang L, Xiong Y, Wang Z, Qiao Y, Lin D, Tang X and Van Gool L 2016. Temporal segment networks: towards good practices for deep action recognition In European Conf. on Computer Vision Springer International Publishing pp 20-36
[13] Zeiler and R. Fergus. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013.
All rights reserved
