[Machinelearning ] PHÁT HIỆN VÀ NHẬN DẠNG HÀNH ĐỘNG BẠO LỰC BẰNG FIGHTNET
Bài đăng này đã không được cập nhật trong 4 năm
FightNet là gì
Như chúng ta đã biết, các hành động tương tác giữa các thực thể hay giữa con người với con người luôn không đồng nhất và rất khó lường. Trong những trường hợp này, vận tốc của hành động hay tương tác luôn biến đổi, nó là con số khó có thể biết trước được. Trong việc xác định, phân lọai hành động ngoài việc nhận dạng các hình ảnh đặc trưng của hành động thì còn một yếu tố quan trọng khác nữa đó chính là các đặc trưng vận tốc của hành động. Để xác định và phân loại chính xác hành động trong video còn phải phụ thuộc vào nhiều yếu tố khác nữa. Một trong những yếu tố khó khăn nhất trong phát hiện hành động bạo lực đó là long-range temporal. Để giải quyết vấn đề này một mô hình mạng mang tên FightNet ra đời nó dựa trên cơ sở của mạng Temporal Segment Network (TSN) (đã trình bày trong bài trước). Tiếp đến, để có được hiệu xuất tốt cần có một lượng lớn dữ liệu để huấn luyện cho mô hình của ConvNets (mạng neuron tích chập).
FightNet xây dựng dựa trên mạng TSN nhưng được cải tiến và sử dụng thêm các đặc tính lên quan đến gia tốc (acceleration) để xây dựng lên FightNet dùng cho phát hiện các hành động bạo lực. Như mô tả trong hình sau sơ đồ luồng xử lý để thiết kế mô hình hóa cho toàn bộ video.
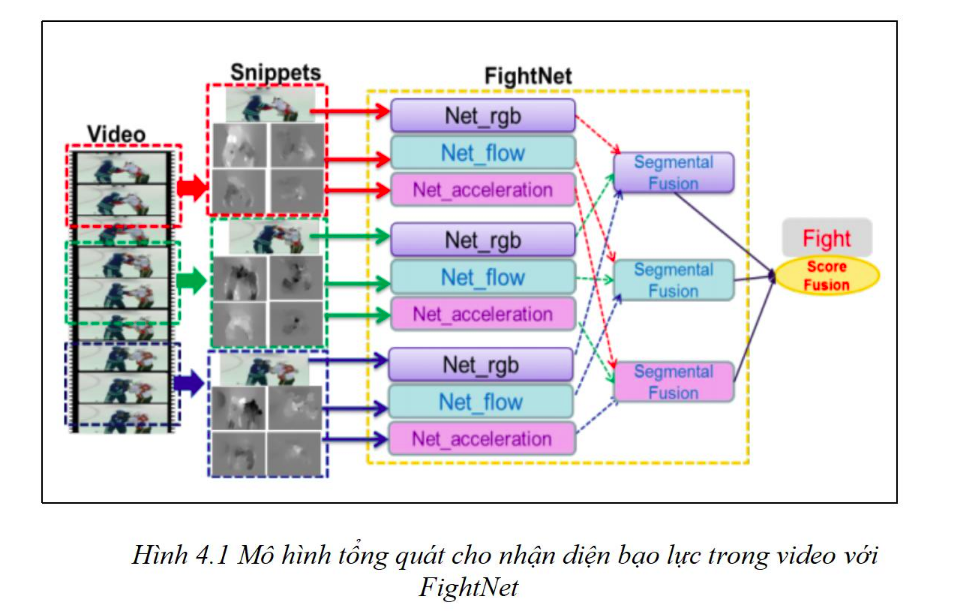
Cho một video dài V, video này được chia thành K segments {S1, S2,…, SK} với mỗi segment có độ dài bằng nhau. Và một list các đoạn ngắn (snippets) {s1, s2,..,sk} được trích xuất ngẫu nhiêu trong các phân đoạn(segments). Sau đó K các đoạn ngắn (snippets) được mô hình hóa như sau:
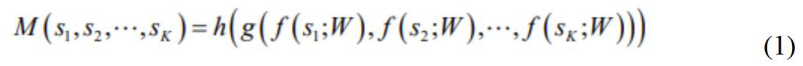
Trong công thức (1) trên, mỗi đoạn ngắn(snippet) sk được lấy một cách ngẫu nhiên từ phân đoạn (segment) Sk tương ứng. f(sk;W) là class score được cung cấp bởi FightNet với tham số W hoạt động trên snippet sk tương ứng. Hàm tổng hợp g là hàm kết hợp các kết quả đầu ra từ các đoạn ngắn(snippet) khác nhau.
Ngoài cùng là prediction function h cho biết xác suất thuộc về các lớp của toàn bộ video, ví dụ: Video đó là có bạo lực hay không. Hàm h mà hay được sử dụng ở đây là hàm Softmax. Bên cạnh đó, theo tổn thất cross-entropy tiêu chuẩn, loss-function đối với G = g(f(s1;W), f(s2;W), …, f(sk;W) được hình thành từ phương trình sau:
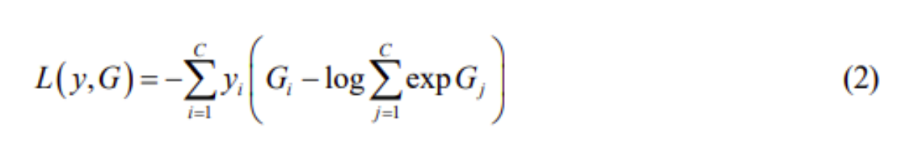
Trong đó:
- C là số lớp cần phân loại;
- yi là ground truth label của lớp i.
Ở trong trường hợp này chúng ta sẽ đơn giản hóa G với Gi = g(fi(s1), fi(s2),…, fi(sk)) và tính trung bình đều sử dụng hàm tổng g. Tùy thuộc vào chức năng của hàm tổng g mà nhiều phân đoạn nhỏ(snippets) được gộp vào để tối ưu hóa các tham số mô hình W. Để hiểu về các tham số mô hình (model parameters), độ dốc ngẫu nhiên (stochastic gradient descent SGD) được chọn làm thuật toán back-propagation và độ dốc (gradient) của tham số mô hình W liên quan đến mất mát. SGD được định nghĩa như sau:
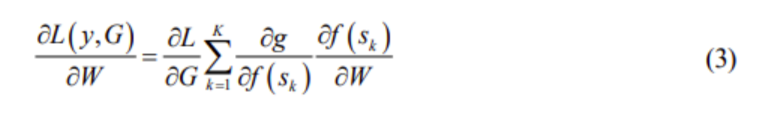
Trong đó, K là số các phân đoạn của tất cả các video.
Phân tích phương pháp mà FightNet sử dụng
Về cơ bản thì do FightNet kế thừa từ TSN nên cũng thực hiện phân đoạn video thành các temporal segments nên giảm được khá nhiều các frame dư thừa của video. Dựa trên TSN, FightNet sẽ cải tiến thêm một chút để có hiệu suất tốt hơn và tương thích hơn với việc phát hiện và phân loại hành động mang tính bạo lực
FightNet Architectures
Nói qua về TSN, TSN đã áp dụng Inception of Batch Normalization (Khởi động chuẩn hóa hàng loạt) để làm cho kiến trúc mạng rộng hơn và sâu hơn làm cho kiến trúc mạng khổng lồ lên tận 34 lớp. Nhưng về mặt toán học như ở trên đã trình bày thì việc phát hiện hành động bạo lực được mô hình hóa như là phân lớp nhị phân (binary classification) và việc làm này nó không quá phức tạp như nhận dạng hành động nói chung. Do đó về mặt kiến trúc của FightNet, cải tiến quan trọng nhất so với TSN là bỏ đi cấu trúc khởi động (inception structure) cuối cùng của 6 lớp tích chập (convoluton layers). Biện pháp này có thể giảm đáng kể over-fitting và rút gọn chí phí training.
Input data
Ban đầu, ảnh màu RGB sẽ được áp dụng cho spatial stream và các trường optical flow chồng lên nhau cho temporal stream trong ConvNets two-streams [8]. Phương pháp TSN sau đó đã đưa ra 4 dạng đầu vào để nâng cao khả năng phân biệt đó là, hình ảnh RGB ban đầu và các trường optical flow, đến sự khác biệt của các trường RGB và các wraped optical flow. Theo như kết quả trong tài liệu tham khảo đã chứng minh rằng hình ảnh RGB ban đầu và các trường optical flow có ảnh hưởng rất lớn đến độ chính xác và 2 dạng input sau là sự khác biệt của các trường RGB và các wraped optical flow có vai trò cải thiện độ chính xác của phương pháp.
Với FightNet lựa chọn 3 phương thức đầu vào đó là ảnh RGB, optical flow fields và các giá trị về gia tốc. Khi ta xem xét, đánh giá trường dữ liệu liên quan đến gia tốc như là một phương thức đầu vào vì các hành động bạo lực khác nhau sẽ có những đặc trưng về gia tốc khác nhau. Ví dụ, đặc trưng về gia tốc của hành động tát sẽ khác với hành động đá, … Vì vậy về mặt lý luận mà nói thì các trường giá trị về gia tốc rất phù hợp cho việc tìm ra các motion features cho FightNet.
Để định lượng được các giá trị gia tốc, với 2 optical flow images liên tiếp nhau là F(t-1) và F(t). Trước tiên cần tính sự khác biệt về optical flow của t. diff(t) theo công thức (4) và các trường gia tốc Accel(x,y,t) theo công thức (5):
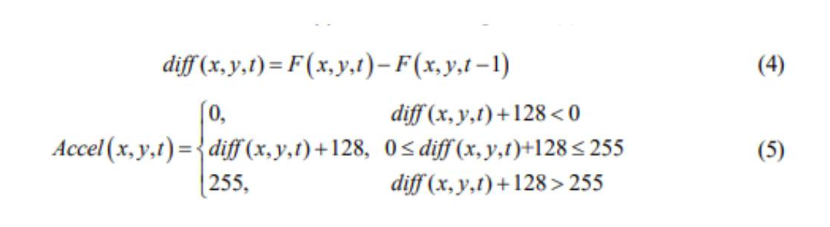
Trong đó, x={1,2,…,m}, y = {1,2,…,n}, t = {1,2,…,T} và (x,y,t) thể hiện rằng pixel (x,y) của frame thứ t. Trong trường hợp này các trường gia tốc (acceleration fields) bao gồm 2 hướng là theo chiều Ox và Oy. Các giá trị gia tốc theo mỗi hướng chúng ta có thể xem nó như là 1 bức ảnh bình thường. Hình dưới đây thể hiện ảnh RGB được sử dụng để cung cấp thông tin xuất hiện của vật thể, optical flow và acceleration fields cung cấp các thông tin về chuyển động của vật thể.

Hình trên mô tả 3 loại dữ liệu đầu vào của FightNet, (a), (b) là 2 frames liên tiếp nhau, (c), (d) mô tả optical flow của hình (b) theo chiều x, y, và (e), (f) là giá trị gia tốc của (c), (d)
Huấn luyện cho FightNet
Về tập dữ liệu, ở đây sử dụng bộ dữ liệu hành động bạo lực (VID) từ UCF101 [9], HMDB51[5] và bộ dữ liệu ở trong [7] bao gồm 2314 videos trong đó 1077 videos có chứa hành động bạo lực và số còn lại là không có. Với tập dữ liệu tương đối lớn việc training có thể sẽ tốn nhiều tài nguyên, để tránh over-fit chúng ta có thể làm như sau:
Pre-training
Trong các nghiên cứu trước đây các nhà khoa học đi trước đã chứng minh được rằng pre-training có hiệu qủa rất tốt để khởi tạo được một ConvNet tốt khi dataset có mẫu không đủ lớn. Bản chất là một ConvNet nên FightNet cũng sử dụng các tham số đã được train trong ImageNet [4] là các giá trị khởi tạo. Sau đó, Ảnh màu RGB được trích xuất từ UCF101 được áp dụng để pre-training cho spatial network của FightNet. Như đã đề cập trong TSN, ta sử dụng các mô hình RGB để khởi tạo các temporal network cho 2 phương thức khác đó là optical flow với acceleration. Cuối cùng các pre-training network sẽ được sử dụng trên các video chứa hành động bạo lực.
Data augmentation
Trong TSN, có 4 kỹ thuật để tránh over-fit đó là cắt xén góc, chia tỷ lệ, cắt ngẫu nhiên và lật ngang. Nhưng ở đây chúng ta không làm thế, trong trường hợp này sẽ sử dụng kỹ thuật video clipping. Trong kỹ thuật video clipping, các video dài quá 150 frames sẽ được cắt nhỏ thành các video khác nhau. Giả sử, một video dài 300 frames sẽ được cắt nhỏ thành 2 mẫu với mỗi mẫu chứa 150 frames. Khi sử dụng kỹ thuật này quy mô dữ liệu training sẽ được tăng lên khoảng 30% và sẽ một phần nào đó khắc vục được việc có ít dữ liệu training.
Testing FightNet
Cũng giống như testing scheme của ConvNet two-stream và TSN. FightNet sẽ trích xuất 25 frames RGB, optical flow và acceleration từ các video mẫu. Ở đây FightNet cũng sử dụng các kỹ thuật của TSN để đánh giá. Bên cạnh đó, còn sử dụng một chiến lược trung bình các trọng số để kết hợp giá trị của mạng không-thời gian. Cụ thể, trọng số lớn hơn sẽ được đánh cho các kết quả lên quan đến thời gian vì trong đặc trưng của các hành động thì thông tin về chuyển động ví dụ: gia tốc, tốc độ,... sẽ đóng vai trò quan trọng hơn so với các thông tin mô tả tĩnh của hành động và nó quyết định xem hành động đó là gì. Ví dụ: Hành động tát và sờ má về cơ bản thì hình ảnh trông khá là tương đồng nhưng điểm quan trọng để phân biệt 2 hành động trên chính là tốc độ thực hiện hành động, gia tốc của chuyển động. Vì vậy, chúng ta sẽ đặt trọng số 0.25 cho các thông tin về không gian và 0.75 cho các thông tin về thời gian. Khi sử dụng kết hợp cả optical flow và acceleration trọng số để kết hợp lúc này là 0.6 và 0.4.
Hàm đánh giá (Evaluation function)
Bộ dữ liệu (dataset)
Bộ dữ liệu được tổng hợp từ nhiều nguồn với các đoạn videos ngắn chứa các hành động bạo lực như đánh, đá, tát, đấm, … với các bối cảnh khác nhau. Do vấn đề khó khăn trong việc thu thập dữ liệu trong thang máy do đa phần các videos này được lưu trữ nội bộ và ít chia sẻ ra bên ngoài. Vậy nên phải sử dụng các bộ dữ liệu có sẵn trên Internet. Trong đó có một bộ dữ liệu chứa 1000 videos được trích xuất từ trận đấu khúc côn cầu gồm 500 videos có bao lực và 500 videos không có. Ngoài ra, còn có bộ dữ liệu các hành động bạo lực trích xuất từ film. Tổng tất cả có 2314 videos trong đó có 1077 videos có hành động bạo lực và chủ yếu là bạo lực 2 người. Bộ dữ liệu này thực sự là chưa thể hiện hết yêu cầu của bài toán đặt ra nhưng nó cũng đáp ứng được một phần tương đối lớn của bài toán.

Phân tích hàm đánh giá (Implication Details)
Để trích xuất các trường dữ liệu liên quan đến optical flow và acceleration ở đây đã sử dụng thuật toán TV-L1 optical flow ứng dụng với thư viện OpenCV trên CUDA. Cũng giống như TSN, FightNet cũng đã được cải thiện tốc độ xử lý với giải pháp dữ liệu song song(data-parallel) với phiên bản tùy biến của Caffe và OpenMPI đã được trình bày ở trên.
Như đã trình bày trong phần trước đó, trước tiên chúng ra sẽ xây dựng kiến trúc của FightNet bằng các cắt bỏ các layer dự phòng của mạng TSN. Thứ hai, FightNet lấy các giá trị trong quá trình pre-training và các tham số đã được sàng lọc trước để làm các giá trị khởi tạo ban đầu. Thứ ba, do là phân loại các hành động chỉ là bạo lực hay không nên thay vì phân loại cụ thể ra các hành động như trong tập dữ liệu thì ở đây đã thay đổi “InnerProduct” layer trong mô hình và thay đổi tên từ fc_action thành fc_action_fight trong file prototxt.
Do là không có layer nào có tên như trên nên ở quá trình trainning sẽ training với các trọng số ngẫu nhiên. Trong solver prototxt sẽ chỉnh sửa lại một số thông số cụ thể, sẽ giảm baselr thành 0.0001 cho các mạng về không gian (spatial network) và 0.0005 cho các mạng tạm thời (temporal network), nhưng sẽ tăng lrmult trên layer fcactionfight. Việc thay đổi các tham số trên có vai trò là làm cho các lớp đã có thay đổi chậm với tập dữ liệu mới nhưng sẽ làm cho layer fcactionlayer học nhanh hơn. Ngoài ra, testiter sẽ được tinh chỉnh theo kích thước của dataset. Trong dataset được sử dụng lần này sẽ có khoảng 20% làm mẫu test và các mẫu còn lại dùng để training.
Trong quá trình đào tạo, các input về không gian cụ thể ở đây là các spatial network với input là các mẫu ảnh RGB sẽ dừng lại ở 2000 lần lặp và các sẽ là 6000 lần với các mạng tạm thời(temporal network) với các inputs là optical flow và acceleration.
Kết quả và đánh giá FighNet
Trong phần này chỉ chú trọng đến phương pháp học tập của Framework FightNet trong phân tích và phát hiện hành động bạo lực. Do tìm hiểu và phát triển trực tiếp từ chức năng và kiến trúc ConvNet đã trình bày trong phần tìm hiểu về TSN nên ứng dụng trực tiếp các kết luận và đánh giá của TSN. Phương pháp “average pooling” được chọn làm hảm tổng mặc định và lựa chọn BN-Inception [24] là kiến trúc ConvNet cho hiệu suất phù hợp với nhiệm vụ phân loại hình ảnh. Trong việc đánh giá độ chính xác sử dụng định nghĩa về thống kê độ chính xác theo công thức sau:
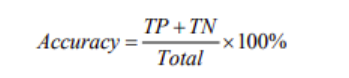
Trong đó, TP là True Positives và TN là True Negatives và Total là tổng số mẫu để làm test.
Với các lựa chọn đã được thiết kế cho FightNet khi kết hợp các dữ liệu đầu vào khác nhau chúng ta sẽ có những kết quả khác nhau. Các kết quả được mô tả trong bảng sau:
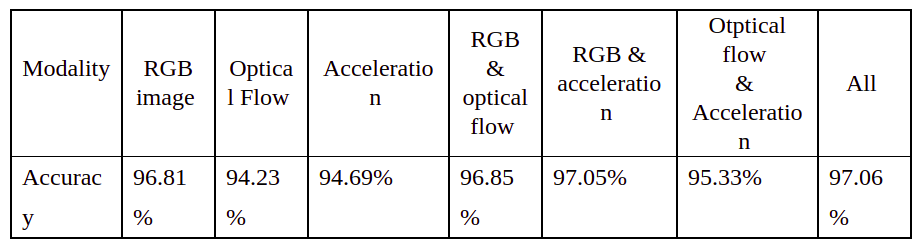
Dựa vào bảng dữ liệu trên ta thấy rằng khả năng nhận diện và độ chính xác khá là tốt và có thể áp dụng vào nhiều ứng dụng trong đời sống.
Tổng kết và tham khảo
Các phần trên đã trình bày các kiến thức về một mô hình phát hiện hành động bạo lực FightNet và đưa ra các ưu điểm vượt trội cũng như những cải tiến mô hình này so với các mô hình đã có cũng như đánh giá tính khả quan và tiềm năng của mô hình mới.
Một số kiến thức liên quan đến TSN các bạn có thể đọc ở các bài viết trước
Một số tài liệu tham khảo:
[2] Crammer and Y. Singer. On the algorithmic implementation of multiclass kernel-based vector machines. JMLR, 2:265–292, 2001.
[3] Jia. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe. berkeleyvision.org/, 2013.
[4] Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, pages 1106–1114, 2012.
[5] Kuehne H, Jhuang H, Garrote E, Poggio T and Serre T. HMDB: a large video database for human motion recognition. IEEE Int. Conf. on Computer Vision IEEE pp 2556-63, 2011
[6] LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
[7] Nievas E B, Suarez O D, García G B and Sukthankar. Violence detection in video using computer vision techniques Int. Conf. on Computer Analysis of Images and Patterns Springer Berlin Heidelberg pp 332-9, 2011
[12] Wang L, Xiong Y, Wang Z, Qiao Y, Lin D, Tang X and Van Gool L 2016. Temporal segment networks: towards good practices for deep action recognition In European Conf. on Computer Vision Springer International Publishing pp 20-36
[13] Zeiler and R. Fergus. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013.
[14] Zhou Peipei, Qinghai Ding, Haibo Luo and Xinglin Hou. Violent Interaction Detection in Video Based on Deep Learning
All rights reserved
