Kiểm thử big data - hướng dẫn hoàn chỉnh cho người mới bắt đầu (phần 2)
Bài đăng này đã không được cập nhật trong 8 năm
Tiếp theo phần 1
Tại sao cơ sở dữ liệu quan hệ truyền thống (relational databases ) không thể được sử dụng để hỗ trợ big data
-
Các cơ sở dữ liệu quan hệ truyền thống như Oracle, MySQL, SQL Server không thể được sử dụng cho big data vì hầu hết dữ liệu được định dạng phi cấu trúc
-
Dữ liệu có thể ở dạng hình ảnh, video, hình ảnh, văn bản, âm thanh ... Đây có thể là hồ sơ quân sự, video giám sát, hồ sơ sinh học, dữ liệu gen, dữ liệu nghiên cứu ... Dữ liệu này không thể được lưu giữ trong hàng và cột của RDBMS.
-
Khối lượng dữ liệu được lưu trữ trong big data là rất lớn. Dữ liệu này cần được xử lý nhanh và điều này đòi hỏi phải xử lý song song dữ liệu. Việc xử lý song song dữ liệu RDBMS sẽ rất tốn kém và không hiệu quả.
-
Cơ sở dữ liệu truyền thống không được xây dựng để lưu trữ và xử lý dữ liệu với số lượng/ kích cỡ lớn. Ví dụ: Hình ảnh vệ tinh cho Hoa Kỳ, Bản đồ đường đi cho thế giới, tất cả hình ảnh trên Facebook.
-
Vận tốc tạo dữ liệu - Các cơ sở dữ liệu truyền thống không thể xử lý nhanh chóng với khối lượng dữ liệu lớn được tạo ra. Ví dụ: 6000 tweets được tạo ra mỗi giây. 510.000 nhận xét được tạo ra mỗi phút. Cơ sở dữ liệu truyền thống không thể xử lý nhanh chóng được.
Chiến lược kiểm thử và các bước kiểm thử ứng dụng big data
Một phần trong quy trình/ luồng làm việc của dự án big data yêu cầu kiểm thử. Kiểm thử trong các dự án big data thường liên quan đến việc kiểm tra cơ sở dữ liệu, cơ sở hạ tầng và kiểm thử hiệu năng, chức năng. Nếu chúng ta có một chiến lược kiểm thử rõ ràng sẽ góp phần vào thành công của dự án.
Kiểm thử cơ sở dữ liệu trong các ứng dụng big data
Trước khi đi vào chi tiết chúng ta hãy tìm hiểu về luồng dữ liệu của một ứng dụng big data. Luồng làm việc như ảnh dưới đây.
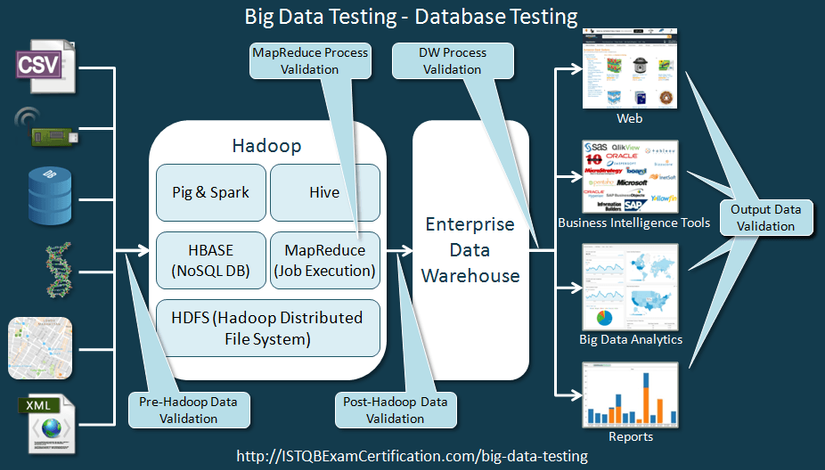
- Data có thể thu thập từ nhiều nguồn khác nhau: sensors, IOT devices, scanners, CSV, thông tin điều tra, log, mạng xã hội, RDBMS ...
- Ứng dụng big data sẽ làm việc với các bộ dữ liệu này. Dữ liệu này có thể phải được xử lý và xác minh để đảm bảo rằng dữ liệu chính xác .
- Vì dữ liệu này sẽ rất lớn, chúng ta sẽ phải đưa nó vào Hadoop (hoặc một framework tương tự), nơi chúng ta có thể làm việc với dữ liệu.
- Khi dữ liệu được đưa vào Hadoop rồi, chúng ta sẽ phải xác minh liệu dữ liệu đã được nhập vào là đúng hay không.
- Chúng ta sẽ phải kiểm tra tính chính xác và đầy đủ dữ liệu.
- Để làm việc với Hadoop, bạn nên biết các lệnh được sử dụng trong Hadoop.
- Để xác nhận dữ liệu nguồn, bạn nên có kiến thức về SQL vì dữ liệu nguồn có thể là một hệ thống RDBMS
- Các ứng dụng big data sẽ làm việc trên Hadoop và xử lý nó theo logic yêu cầu
- Mặc dù ứng dụng big data được xử lý dữ liệu trong Hadoop, chúng ta cũng sẽ phải xác nhận rằng nó đã được xử lý đúng theo yêu cầu của khách hàng.
- Để kiểm tra ứng dụng chúng ta sử dụng test data. Dữ liệu có sẵn trong Hadoop rất lớn và chúng ta không thể sử dụng tất cả dữ liệu để kiểm thử. Chúng ta chọn một tập con của dữ liệu để thử và gọi đó là test data.
- Chúng ta cũng sẽ kiểm thử ứng dụng sử dụng testdata như dữ liệu thật, theo yêu cầu của khách hàng.
- Sau đó chúng ta sẽ so sánh nó với kết quả xử lý từ ứng dụng big data để xác nhận rằng ứng dụng đang xử lý dữ liệu chính xác.
- Để xử lý testdata, bạn sẽ cần một số kiến thức về Hive, Pig Scripting, Python và Java. Bạn sẽ phải viết script để trích xuất và xử lý dữ liệu cho kiểm thử.
- Bạn có thể nghĩ về ứng dụng big data như các ứng dụng khác mà ở đó xử lý một lượng dữ liệu khổng lồ. Ví dụ: Hãy xem xét rằng bạn đang làm việc cho Facebook và các lập trình viên đang phát triển một ứng dụng big data, nơi bất kỳ nhận xét nào chứa cụm từ "Thẻ tín dụng miễn phí" được đánh dấu là spam. Đây là một ví dụ quá đơn giản, thường là các ứng dụng phức tạp hơn và liên quan đến việc xác định các mẫu dữ liệu và đưa ra dự đoán bằng cách sử dụng khoa học dữ liệu để phân biệt spam.
- Dữ liệu được xử lý sau đó được lưu trữ trong kho dữ liệu.
- Sau khi dữ liệu được lưu trữ trong kho dữ liệu, nó có thể được xác nhận lại để đảm bảo rằng nó phù hợp với dữ liệu đã được tạo ra sau khi xử lý, bởi các ứng dụng big data.
- Dữ liệu từ kho dữ liệu thường được phân tích và mô tả dưới dạng trực quan.
- Khi dữ liệu đã trực quan, nó sẽ phải được xác minh lại.
- Các dịch vụ Web có thể được sử dụng để chuyển dữ liệu từ kho dữ liệu sang hệ thống BI. Trong những trường hợp như vậy, các dịch vụ web cũng sẽ phải được kiểm tra và người kiểm thử phải có kiến thức về kiểm thử web services.
Theo như các bước trên, kiểm thử cơ sở dữ liệu sẽ là một thành phần chính của kiểm thử ứng dụng bigdata. Tóm lại, các bước trên có thể được phân thành 3 nhóm chính:
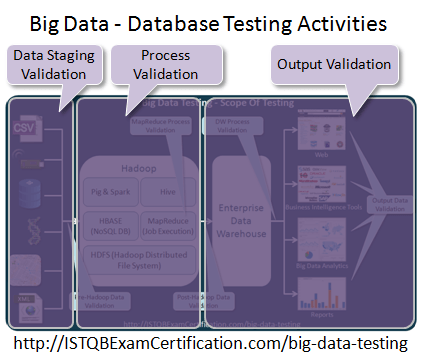
- Data Staging Validation (Xác thực dữ liệu) : chúng ta xác thực dữ liệu được lấy từ nhiều nguồn khác nhau như cảm biến, scanner, logs vv. Chúng ta xác nhận xem dữ liệu được đẩy vào Hadoop (hoặc các frameworks khác) hay chưa>
- Process Validation (Xác nhận quá trình) : Trong bước này, xác nhận rằng dữ liệu thu được sau khi xử lý thông qua big data là chính xác. Điều này cũng bao gồm việc kiểm tra tính chính xác của dữ liệu được tạo .
- Output Validation (Xác nhận đầu ra) : Trong bước này, xác nhận rằng đầu ra từ ứng dụng big data được lưu trữ chính xác trong kho dữ liệu. Đồng thời xác minh rằng dữ liệu được thể hiện chính xác trong hệ thống thông tin nghiệp vụ hoặc bất kỳ giao diện người dùng mục tiêu nào khác.
Kiểm thử hiệu năng trong ứng dụng big data
Các dự án big data liên quan đến việc xử lý một lượng lớn dữ liệu trong một khoảng thời gian ngắn.
Hoạt động này đòi hỏi nguồn tài nguyên máy tính mạnh và luồng dữ liệu mạng mượt mà.
Các vấn đề về kiến trúc hệ thống có thể dẫn đến tắc nghẽn trong quá trình thực hiện, có thể ảnh hưởng đến tính khả dụng của ứng dụng. Điều này có thể ảnh hưởng đến thành công của dự án.
Kiểm thử hiệu năng của hệ thống là cần thiết để tránh các vấn đề trên. Ở đây chúng ta đo lường các số liệu như thông lượng (throughput), sử dụng bộ nhớ, sử dụng CPU, thời gian thực hiện để hoàn thành một nhiệm vụ vv
Cũng nên chạy các thử nghiệm chuyển đổi dự phòng để xác nhận tính chịu lỗi của hệ thống và đảm bảo rằng nếu một số nút bị hỏng, các nút khác sẽ không ảnh hưởng trong quá trình xử lý.
Kiểm thử hiệu năng Big data/Hadoop
Kiểm thử hiệu năng của ứng dụng big data tập trung vào những yếu tố sau:
Dữ liệu tải và thông lượng (Data Loading And Throughput): Người kiểm thử quan sát tốc độ dữ liệu được tiêu thụ từ các nguồn khác nhau như cảm biến, logs vv vào hệ thống. Người kiểm thử cũng kiểm tra tốc độ dữ liệu được tạo ra trong kho dữ liệu. Trong trường hợp xảy ra hàng đợi , chúng tôi kiểm tra thời gian để xử lý một số lượng thông tin nhất định. Tốc độ xử lý dữ liệu (Data Processing Speed): Chúng ta đo tốc độ bằng dữ liệu được xử lý bằng MapReduce. Hiệu năng của hệ thống con (Sub-System Performance): Chúng ta đo hiệu suất của các thành phần riêng biệt khác nhau trong một phần của ứng dụng tổng thể. Nó có thể có lợi để thử nghiệm các thành phần cô lập để xác định những nút cổ chai trong ứng dụng. Việc này có thể bao gồm kiểm tra quá trình MapReduce, thực hiện các truy vấn vv
Còn nữa
Link bài viết phần 1 tại đây: https://viblo.asia/p/kiem-thu-big-data-huong-dan-hoan-chinh-cho-nguoi-moi-bat-dau-phan1-QpmleQrMlrd
Bài viết được dịch lại từ nguồn: http://istqbexamcertification.com/big-data-testing/
All rights reserved
