Kiểm thử big data - Hướng dẫn hoàn chỉnh cho người mới bắt đầu (Phần1)
Bài đăng này đã không được cập nhật trong 8 năm
Với sự gia tăng số lượng lớn các ứng dụng big data trên thế giới, nhu cầu và cơ hội cho kiểm thử viên có kiến thức về kiểm thử big data cũng tăng theo. Theo IDC, thị trường bigdata sẽ trở thành ngành công nghiệp 50 triệu đô vào năm 2019
Bài viết dưới đây đưa ra ý tưởng cho kiểm thử viên hay bất cứ ai muốn bắt đầu kiểm thử big data.
Bài viết gồm các mục sau:
- Big data là gì
- Ví dụ và cách sử dụng big data
- Định dạng dữ liệu trong bigdata
- Tại sao cơ sở dữ liệu quan hệ truyền thống (relational databases ) không thể được sử dụng để hỗ trợ big data
- Chiến lược kiểm thử và các bước kiểm thử ứng dụng big data
- Kiểm tra cơ sở dữ liệu của ứng dụng big data
- Kiểm thử hiệu năng (performance) của ứng dụng big data
- Kiểm tra thử hiệu năng (performance) big data/ hadoop
- Phương pháp tiếp cận kiểm thử hiệu năng (performance)
- Kiểm thử chức năng (functional) của ứng dụng big data
- Vai trò và Trách nhiệm của người kiểm thử trong ứng dụng big data
- Ưu điểm của việc sử dụng big data / Hadoop
- Nhược điểm của việc sử dụng big data / Hadoop
- Kiến trúc Hadoop
- Công cụ / thuật ngữ chung của big data
- Công cụ kiểm thử tự động big data
- Dịch vụ kiểm thử big data
Với những kiểm thử viên mới bắt đầu kiểm thử big data sẽ đặt câu hỏi - big data là gì? làm thế nào để kiểm thử ứng dụng big data? các bước và quy trình kiểm thử ứng dụng big data. Chúng ta sẽ trả lời tất cả các câu hỏi trên và mở rộng thêm nữa ngay sau đây.
Big data là gì?
Big data đề cập đến khối lượng dữ liệu lớn, không thể xử lý bằng cơ sở dữ liệu truyền thống (relational databases). Khi chúng ta có lượng dữ liệu hợp lý, chúng ta thường sử dụng các cơ sở dữ liệu quan hệ truyền thống như Oracle, MySQL, SQL Server để lưu và làm việc với dữ liệu. Tuy nhiên khi chúng ta có khối lượng lớn dữ liệu thì cơ sở dữ liệu truyền thống sẽ không thể xử lý dữ liệu.

Cơ sở dữ liệu truyền thống làm việc tốt với dữ liệu có cấu trúc (structured data) được lưu trữ trong các hàng và cột. Tuy nhiên, nếu chúng ta có dữ liệu phi cấu trúc thì việc sử dụng cơ sở dữ liệu quan hệ không phải là sự lựa chọn đúng.
Trong trường hợp dữ liệu lớn chúng ta có số lượng lớn dữ liệu có thể ở bất kỳ định dạng nào như hình ảnh, tệp, âm thanh ... có cấu trúc và định dạng có thể không giống nhau cho mỗi bản ghi.
Kích thước của dữ liệu lớn, lượng dữ liệu được tạo ra theo thời gian, có thể lớn hơn đáng kể so với cơ sở dữ liệu truyền thống. Điều này sẽ rất khó để xử lý với cơ sở dữ liệu truyền thống.
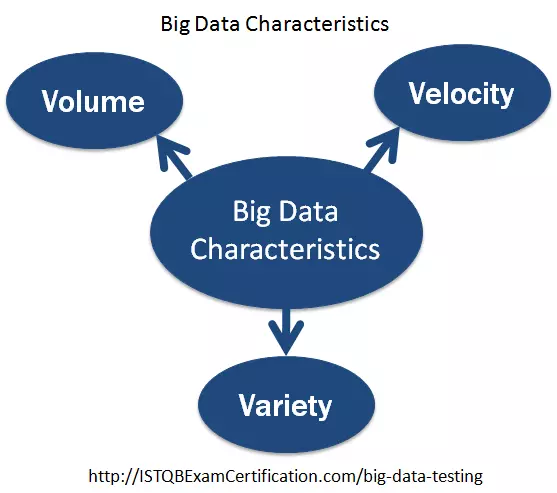
Big data được đặc trưng bởi 3V - Volume (dung lượng) , Velocity (tốc độ), Variety (sự khác nhau về định dạng)
-
Volume : Khối lượng dữ liệu được thu thập lớn và đến từ nhiều nguồn khác nhau: cảm biến, giao dịch nghiệp vụ …
-
Velocity : Dữ liệu được tạo ra ở tốc độ cao và phải được sử lý nhanh chóng, các dụng cụ như thiết bị IOT, thẻ RFID, dụng cụ đo thông mình và các thiết bị khác dẫn tới việc tự động tạo ra dữ liệu ở tốc độ chưa từng thấy
-
Variety : Có rất nhiều định dạng khác nhau. Có thể là âm thanh, video, văn bản, email, hình ảnh vệ tinh, cảm biến khí quyển …
Ví dụ và cách sử dụng big data
Lưu trữ dữ liệu mà không phân tích nó để có được cái nhìn sâu sắc có ý nghĩa từ các dữ liệu sẽ là một sự lãng phí. Trước khi chúng ta kiểm tra big data, sẽ rất hữu ích nếu hiểu nó được sử dụng như thế nào trong thế giới thực.
Thương mại điện tử ( E-commerce)
Amazon, Flipkart và các trang thương mại điện tử khác có hàng triệu khách truy cập mỗi ngày với hàng trăm nghìn sản phẩm. Amazon sử dụng big data để lưu trữ thông tin liên quan đến sản phẩm, khách hàng và mua hàng.
Ngoài các dữ liệu tập trung vào các tìm kiếm sản phẩm, lượt xem, còn có sản phẩm được thêm vào giỏ hàng, xoá sản phẩm từ giỏ hàng, sản phẩm được mua cùng nhau ...
Tất cả dữ liệu này được lưu trữ và xử lý để gợi ý các sản phẩm mà khách hàng có nhiều khả năng mua nhất.
Nếu bạn mở một trang sản phẩm, bạn có thể thấy hoạt động này trong phần “Các sản phẩm thường được mua cùng nhau“, “Các khách hàng đã mua sản phẩm này cũng xem sản phẩm dưới đây” và "Khách hàng đã xem các sản phẩm này cũng xem sản phẩm dưới đây“.
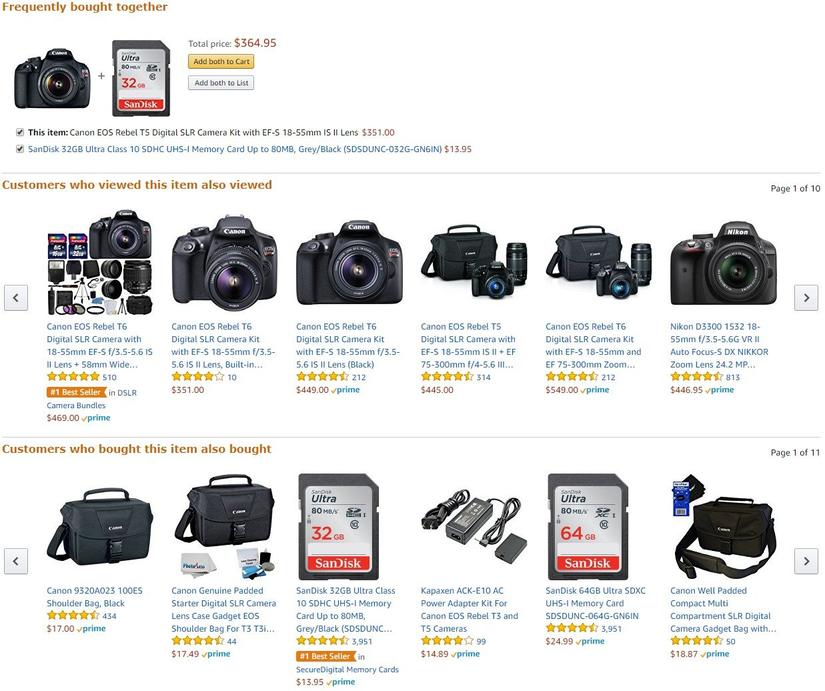
Thông tin này cũng được sử dụng để đề nghị giao dịch / giảm giá và xếp loại sản phẩm trong kết quả tìm kiếm.
Tất cả các dữ liệu này phải được xử lý rất nhanh và điều này không khả thi với các cơ sở dữ liệu truyền thống.
Mạng xã hội (social media)
Các trang mạng xã hội tạo ra lượng dữ liệu khổng lồ về hình ảnh, video, số lượt thích, bài đăng, nhận xét ... Không chỉ dữ liệu được lưu trữ trong các nền tảng big data, chúng còn được xử lý và phân tích để cung cấp các đề xuất về nội dung bạn muốn.

- Có 310 triệu người dùng hoạt động hàng tháng trên Twitter
- Tổng cộng có 1,3 tỷ tài khoản đã được tạo ra trên Twitter
- Mỗi ngày 500 triệu người gửi tin nhắn được gửi bởi người dùng, khoảng 6000 tweets mỗi giây
- Hơn 618.725 bài viết đã được gửi đi trong một phút trong trận chung kết FIFA World Cup vào năm 2014
- Có 1,9 tỷ người dùng hoạt động hàng tháng trên Facebook
- Hơn 1,28 tỷ người dùng đăng nhập vào Facebook hàng ngày
- 350 triệu ảnh được tải lên hàng ngày
- 510.000 nhận xét và 293.000 trạng thái được cập nhật mỗi phút
- 4 petabyte dữ liệu mới được tạo ra mỗi ngày
- Video hàng ngày tạo ra 8 tỷ lượt xem
- 700 triệu người sử dụng Instagram mỗi tháng
- 40 tỷ ảnh đã được chia sẻ trên Instagram
- Người dùng thích 4,2 tỷ hình ảnh mỗi ngày
- 95 triệu ảnh được tải lên hàng ngày
Không chỉ dữ liệu được lưu trữ trong các nền tảng big data, chúng cũng được xử lý và phân tích để cung cấp các đề xuất về những điều bạn có thể quan tâm.
Ví dụ: nếu bạn tìm kiếm máy giặt trên Amazon sau đó sử dụng Facebook, Facebook sẽ hiển thị quảng cáo cho bạn.
Đây là trường hợp sử dụng dữ liệu lớn vì có hàng triệu trang web quảng cáo trên Facebook và có hàng tỷ người dùng.
Lưu trữ và xử lý thông tin này để hiển thị đúng quảng cáo cho đúng người dùng không thể được thực hiện bằng các cơ sở dữ liệu truyền thống trong cùng một khoảng thời gian.
Nhắm mục tiêu vào đúng khách hàng với đúng quảng cáo là quan trọng bởi vì một người tìm kiếm máy giặt có nhiều khả năng nhấp vào quảng cáo của máy giặt hơn quảng cáo cho Tivi.
Chăm sóc sức khỏe
FDA và CDC đã tạo ra chương trình GenomeTrakr xử lý 17 terabytes dữ liệu được sử dụng để xác định và điều tra sự bùng phát thực phẩm. Điều này đã giúp FDA xác định được một trung tâm sản xuất bơ hạt mỡ làm nguồn lây lan của nhiều loại Salmonella. FDA cho ngừng sản xuất tại nhà máy để ngăn chặn sự bùng nổ. Aetna, nhà cung cấp dịch vụ bảo hiểm đã xử lý 600.000 kết quả xét nghiệm và 18 triệu yêu cầu bồi thường trong một năm để đánh giá yếu tố nguy cơ của bệnh nhân và tập trung điều trị vào một hoặc hai tác động đáng kể và cải thiện sức khoẻ của cá nhân.
Định dạng dữ liệu trong bigdata
Một câu hỏi phổ biến mà mọi người đặt ra là tại sao chúng ta không thể sử dụng cơ sở dữ liệu quan hệ cho big data? Để trả lời câu hỏi này, trước tiên cũng ta sẽ cùng tìm hiểu về các định dạng dữ liệu khác nhau trong big data.
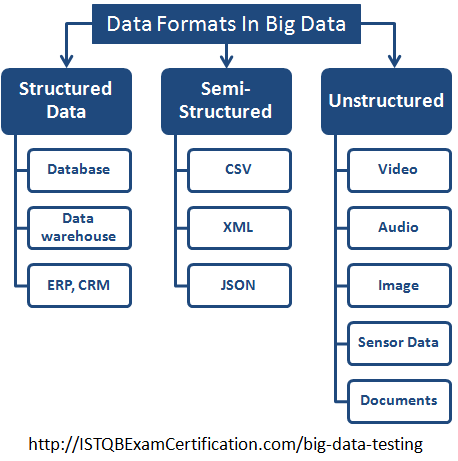
Định dạng dữ liệu trong big data có thể phân chia thành 3 loại
- Dữ liệu có cấu trúc
- Dữ liệu bán cấu trúc
- Dữ liệu phi cấu trúc
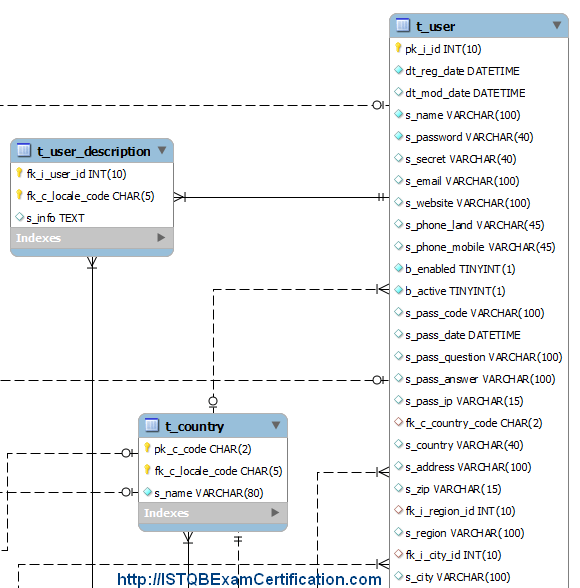
Dữ liệu có cấu trúc
Dữ liệu có cấu trúc được tổ chức ở mức cao, có thể lưu trữ một cách dễ dàng trong bất kỳ cơ sở dữ liệu quan hệ nào. Nó có thể dễ dàng truy xuất/ tìm kiếm sử dụng các câu truy vấn đơn giản Ví dụ Hình ảnh dưới đây mô tả mô hình dữ liệu cho một ứng dụng. Ở đây bạn có thể thấy các bảng và các cột liên quan trong các bảng. Trong ví dụ này người sử dụng bảng t_user lưu trữ các chi tiết như tên người dùng, mật khẩu, email, số điện thoại ... Độ dài của các trường và loại dữ liệu của họ được xác định trước và có một cấu trúc cố định.
Dữ liệu bán cấu trúc
. Dữ liệu bán cấu trúc không được tổ chức một cách cứng nhắc theo 1 định dạng cụ thể, nó cho phép dễ dàng truy cập và tìm kiếm dữ liệu . Dữ liệu bán cấu trúc thường không được lưu trữ trong cơ sở dữ liệu quan hệ. Tuy nhiên, chúng có thể được lưu trữ một cơ sở dữ liệu quan hệ. Tuy nhiên, chúng có thể được lưu trữ trong một cơ sở dữ liệu quan hệ sau khi xử lý và chuyển đổi sang định dạng có cấu trúc. Dữ liệu bán cấu trúc nằm giữa các dữ liệu có cấu trúc và không có cấu trúc. Chúng có thể chứa các thẻ và các siêu dữ liệu khác để thực hiện một hệ thống phân cấp. Trong dữ liệu bán cấu trúc, cùng một loại thực thể có thể có các thuộc tính khác nhau theo thứ tự khác nhau.
Ví dụ dữ liệu bán cấu trúc
CSV, XML và JavaScript Object Notation (JSON) là các ví dụ về dữ liệu bán cấu trúc được sử dụng trong hầu hết các ứng dụng.
Ví dụ về file XML được đưa ra dưới đây. Chúng ta có thể thấy rằng file XML chứa catalog và book là con của catalog. Dữ liệu này có thể được lưu trữ trong một cơ sở dữ liệu quan hệ sau khi xử lý.
<?xml version="1.0"?>
<catalog>
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
<book id="bk102">
<author>Ralls, Kim</author>
<title>Midnight Rain</title>
<genre>Fantasy</genre>
<price>5.95</price>
<publish_date>2000-12-16</publish_date>
<description>A former architect battles corporate zombies,
an evil sorceress, and her own childhood to become queen
of the world.</description>
</book>
</catalog>
Trong ví dụ về JSON dưới đây, chúng ta có address và phone number của 1 user với một số thông tin chi tiết kèm theo. Thông tin này có thể được lưu trữ trong cở sở dữ liệu quan hệ sau khi xử lý
{
"firstName": "Adam",
"lastName": "Levine",
"age": 22,
"address":
{
"streetAddress": "18 Elm Street",
"city": "San Jose",
"state": "CA",
"postalCode": "94088"
},
"phoneNumber":
[
{
"type": "home",
"number": "845-156-5555"
},
{
"type": "fax",
"number": "789-658-9874"
}
]
}
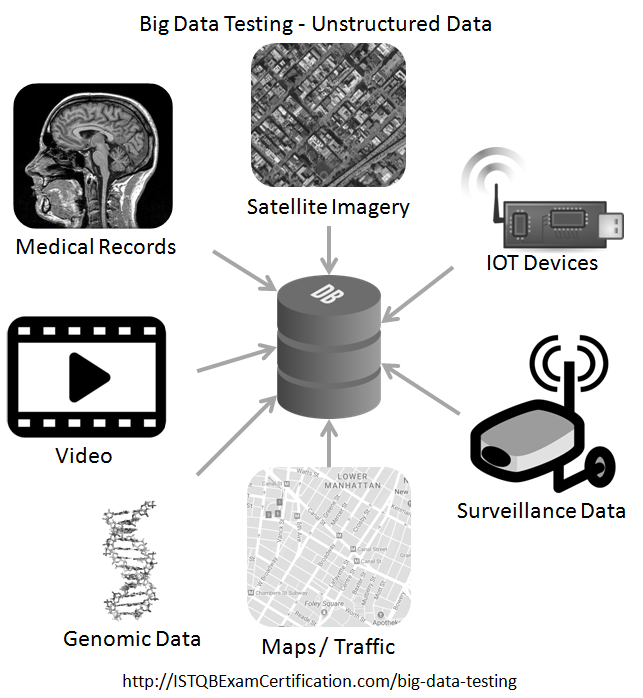
Dữ liệu phi cấu trúc
Dữ liệu phi cấu trúc không có định dạng được xác định trước. Nó không theo một mô hình dữ liệu có cấu trúc. Nó không được tổ chức thành một cấu trúc được xác định trước. Hình ảnh, video, văn bản, file mp3 có thể được coi là dữ liệu phi cấu trúc ngay cả khi chúng có cấu trúc bên trong Sự thiếu vắng cấu trúc khiến việc lưu trữ và truy xuất dữ liệu từ cơ sở dữ liệu quan hệ trở nên khó khăn Có tới 80% dữ liệu được tạo ra là dữ liệu phi cấu trúc
Ví dụ về dữ liệu phi cấu trúc
Hình ảnh, video, văn bản, file mp3…
Còn tiếp...
Bài viết được dịch lại từ nguồn: http://istqbexamcertification.com/big-data-testing/
All rights reserved
