Kaggle Competition: Two Sigma: Using News to Predict Stock Movements
Bài đăng này đã không được cập nhật trong 7 năm
Xin chào các bạn, trong bài viết lần này mình sẽ giới thiệu với các bạn bài toán "Dự đoán xu hướng giá cổ phiếu". Bài toán này khá phổ biến trong Machine Learning, bài toán mà nếu giải quyết được thì chúng ta sẽ rất giàu  Đây cũng là một "challenge" của Kaggle với tổng trị giá giải thưởng lên tới 100k Trumps
Đây cũng là một "challenge" của Kaggle với tổng trị giá giải thưởng lên tới 100k Trumps  Now Let's Go!!
Now Let's Go!!
1. Nội Dung
Cụ thể chúng ta sẽ giải quyết bài toán: Using News to Predict Stock Movements hiểu một cách đơn giản là sử dụng nội dung tin tức để dự đoán xu hướng giá cổ phiếu.
Như mọi người cũng biết cổ phiếu có thể đem lại cho chúng ta rất rất nhiều tiền nhưng cũng có thể đưa một người thẳng ra đê  vậy nên người ta luôn luôn có ham muốn dự đoán được rằng ngày mai, ngày kia giá cổ phiếu nào tăng, giá cổ phiếu nào giảm. Trước đây người ta thường sử dụng phương pháp phân tích dữ liệu lịch sử giá cổ phiếu để đưa ra dự đoán. Tuy nhiên với bài toán này, chúng ta có một cách tiếp cận rộng hơn đó là kết hợp giữa dữ liệu lịch sử giá và các tin tức trên thị trường để đưa ra dự đoán. Nhưng một vấn đề đặt ra là lượng thông tin trôi nổi hàng ngày là rất lớn, đâu là những thông tin cần thiết, hữu ích với việc dự đoán, làm thế nào để kết hợp được dữ liệu giá và dữ liệu tin tức... Đó là những vấn đề chúng ta cần phải giải quyết trong challenge này.
vậy nên người ta luôn luôn có ham muốn dự đoán được rằng ngày mai, ngày kia giá cổ phiếu nào tăng, giá cổ phiếu nào giảm. Trước đây người ta thường sử dụng phương pháp phân tích dữ liệu lịch sử giá cổ phiếu để đưa ra dự đoán. Tuy nhiên với bài toán này, chúng ta có một cách tiếp cận rộng hơn đó là kết hợp giữa dữ liệu lịch sử giá và các tin tức trên thị trường để đưa ra dự đoán. Nhưng một vấn đề đặt ra là lượng thông tin trôi nổi hàng ngày là rất lớn, đâu là những thông tin cần thiết, hữu ích với việc dự đoán, làm thế nào để kết hợp được dữ liệu giá và dữ liệu tin tức... Đó là những vấn đề chúng ta cần phải giải quyết trong challenge này.
2. Dữ liệu
Dữ liệu của challenge bao gồm 2 phần:
- Dữ liệu thị trường: Là các thông tin của thị trường chứng khoán như giá mở phiên, giá đóng phiên, khối lượng giao dịch... từ năm 2007 đến nay được cung cấp bởi Intrinio
- Dữ liệu tin tức: Là các thông tin về các bài báo, báo cáo, như nội dung bài viết, xu hướng đánh giá của bài viết, bình luận... từ năm 2007 đến nay được cung cấp bởi Thomson Reuters
NOTE: Có một lưu ý quan trọng trong challenge này là chúng ta không thể download được dữ liệu về mà bắt buộc phải thao tác trên Kaggle Kernel!!!
3. Cách đánh giá mô hình
Trong challenge này chúng ta cần phải dự đoán confidence value (hiểu theo nghĩa đen là giá trị niềm tin) là ŷ
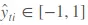
Nếu bạn dự đoán một mã cổ phiếu có lợi nhuận tăng trong vòng 10 ngày tới thì giá trị của ŷ sẽ dương, "niềm tin" của bạn vào dự đoán này càng cao thì giá trị của ŷ sẽ càng ~1.0. Ngược lại, nếu bạn dự đoán lợi nhuận của mã đó giảm thì giá trị của ŷ sẽ âm. Nếu bạn không chắc chắn vào dự đoán của mình giá trị của ŷ sẽ ~0.0. Và như vậy, với mỗi ngày trong khoảng thời gian đánh giá mô hình ta sẽ có:
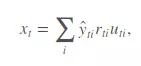
Trong đó:
- ŷ: Confidence value mà chúng ta dự đoán
- rti: Lợi nhuận của mã cổ phiếu i trong ngày thứ t
- uti(0/1): Đây là giá trị của trường universe trong bộ market data. Nếu giá trị là 1 nghĩa là mã cổ phiếu i được xem xét để đánh giá vào ngày t và ngược lại, nếu giá trị bằng 0 thì mã đó không được đánh giá
Và score cuối cùng xếp hạng mô hình của chúng ta sẽ được tính như sau:
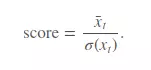
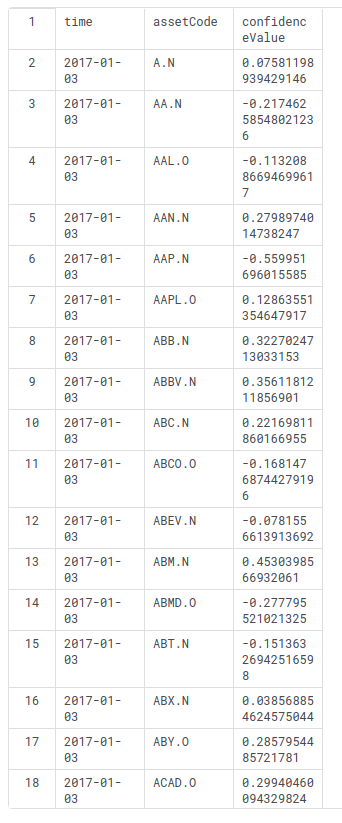
Và cuối cùng, Submission File của chúng ta sẽ có dạng như sau:
time,assetCode,confidenceValue
2017-01-03,RPXC.O,0.1
2017-01-04,RPXC.O,0.02
2017-01-05,RPXC.O,-0.3
NOTE: Một điều đặc biệt là trong giai đoạn Evaluation của challenge này mô hình của bạn sẽ được chấm điểm dựa trên tình hình thị trường cổ phiếu trong thời gian thực tế trong vòng 4 tháng.
4. Giải thưởng:
Giải thưởng của challenge khá hấp dẫn (Cổ phiếu mà )
- 1st place - $25,000
- 2nd place - $20,000
- 3rd place - $15,000
- 4th through 7th place - $10,000 each
5. Các bước giải quyết bài toán
5.1. Data preprocessing
Như chúng ta đã biết giai đoạn tiền xử lý dữ liệu là giai đoạn vô cùng quan trọng đối với một bài toán machine learning. Đặc biệt với bài toán này theo mình thì giai đoạn tiền xử lý dữ liệu thậm chí còn quan trọng hơn cả việc tunning mô hình. Bởi lẽ, lượng dữ liệu của bài toán này khá lớn (market data: 4072956x16, news data: 9328827x35) và thuộc hai tập dữ liệu khác nhau, nên việc rất quan trọng đó là làm thế nào để join được hai bộ dữ liệu này lại và dữ những trường nào để phục vụ bài toán của chúng ta. Cách load môi trường và data như sau:
from kaggle.competitions import twosigmanews
import numpy as np
import pandas as pd
pd.options.mode.chained_assignment = None
env = twosigmanews.make_env()
market_df, news_df = env.get_training_data()
Sau bước này ta có 2 tập dữ liệu là market_df (dữ liệu thị trường) và news_df (dữ liệu tin tức) có dạng như sau:
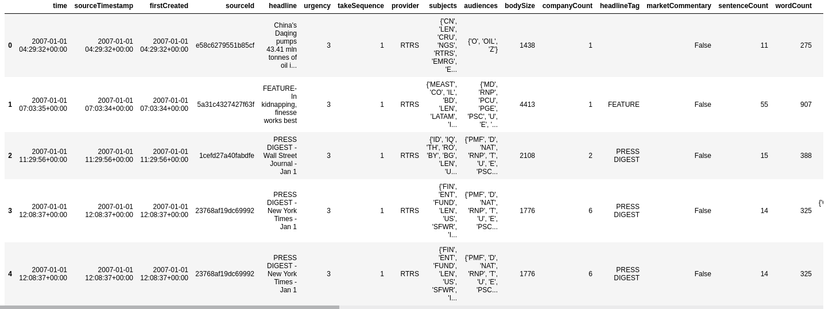

Về ý nghĩa của các trường của dữ liệu các bạn có thể tham khảo tại đây. Như vậy nhìn qua chúng ta có thể thấy rằng ở tập market data một bài báo có thể liên quan đến một hoặc nhiều mã cổ phiếu khác nhau nên bước tiếp theo mình sẽ thực hiện việc mapping giữa hai tập dữ liệu bằng mã cổ phiếu và thời gian xuất bản bài viết (trường firstCreated)
5.1.1. Tiền xử lý với tập Market Data
- Trích chọn đặc trưng (bước này mình có thực hiện một vài round với lượng nhỏ dữ liệu để xem xét các trường của market data tuy nhiên kết quả mình ghi lại trên giấy khá là rối
 ) kết quả cuối cùng mình chọn ra các feature như dưới đây. Có thể thấy rằng các feature mình chọn chủ yếu liên quan đến việc đánh giá cảm xúc của bài viết đó đối với tình hình cổ phiếu. Theo logic bình thường nếu tin tức mang lại cảm xúc tốt thì giá cổ phiếu đó sẽ khả quan và ngược lại.
) kết quả cuối cùng mình chọn ra các feature như dưới đây. Có thể thấy rằng các feature mình chọn chủ yếu liên quan đến việc đánh giá cảm xúc của bài viết đó đối với tình hình cổ phiếu. Theo logic bình thường nếu tin tức mang lại cảm xúc tốt thì giá cổ phiếu đó sẽ khả quan và ngược lại.
news_df_columns = ['assetCodes', 'firstCreated', 'wordCount', 'sentenceCount',
'firstMentionSentence', 'sentimentClass',
'sentimentNegative', 'sentimentNeutral', 'sentimentPositive',
'sentimentWordCount']
news_df = news_df[news_df_columns]
- Tiếp theo là đến việc tách riêng các row dữ liệu liên quan đến nhiều mã cổ phiếu (assetCodes) khác nhau. Về mặt tư tưởng của mình khá đơn giản là extend các row dữ liệu gồm nhiều assetCodes tương ứng với từng mã trong đó. Mọi người có thể tham khảo các function dưới đây:
def unstack_asset_codes(news_df):
codes = []
indexes = []
for i, values in news_df['assetCodes'].iteritems():
explode = values.replace('\'', '').replace('}', '').replace('{', '').split(", ")
codes.extend(explode)
repeat_index = [int(i)]*len(explode)
indexes.extend(repeat_index)
index_df = pd.DataFrame({'news_index': indexes, 'assetCode': codes})
del codes, indexes
return index_df
def merge_news_on_index(news_df, index_df):
news_df['news_index'] = news_df.index.copy()
# Merge news on unstacked assets
news_unstack = index_df.merge(news_df, how='left', on='news_index')
news_unstack.drop(['news_index', 'assetCodes'], axis=1, inplace=True)
return news_unstack
def handle_news_df(news_df):
news_df = news_df[news_df_columns]
index_df = unstack_asset_codes(news_df)
news_df = merge_news_on_index(news_df, index_df)
news_df = news_df.groupby(['firstCreated', 'assetCode'], as_index=False).mean()
del index_df
return news_df
Sau bước này ta sẽ có được tập news data như sau:

5.1.2. Merge hai tập dữ liệu
- Xử lý missing data: Các thực hiện của mình là với các dữ liệu là dạng số sẽ fill missing value = trung bình giá trị trường dữ liệu, nếu là dạng khác sẽ fill là other
def mis_impute(data):
for i in data.columns:
if data[i].dtype == "object":
data[i] = data[i].fillna("other")
elif (data[i].dtype == "int64" or data[i].dtype == "float64"):
data[i] = data[i].fillna(data[i].mean())
else:
pass
return data
- Merge hai tập dữ liệu: Các row dữ liệu có cùng assetCode và trường firstCreated của news data map với trường time của market data sẽ được merge với nhau
def data_preprocessing_for_training(market_df, news_df):
market_df['time'] = market_df['time'].dt.date
news_df['firstCreated'] = news_df['firstCreated'].dt.date
news_df = handle_news_df(news_df)
full_df = pd.merge(market_df, news_df, how='left', left_on=['time', 'assetCode'],
right_on=['firstCreated', 'assetCodes'])
label = full_df.returnsOpenNextMktres10 >= 0
full_df = full_df.drop(['assetCode', 'time', 'assetName', 'assetCodes', 'firstCreated', 'universe', 'returnsOpenNextMktres10'], axis=1)
full_df = mis_impute(full_df)
return full_df, label
- Cuối cùng ta có dữ liệu để training:
X_train, label_train = data_preprocessing_for_training(market_df, news_df)
X_train = X_train.values
# Scaling the X values
mins = np.min(X_train, axis=0)
maxs = np.max(X_train, axis=0)
rng = maxs - mins
X_train = 1 - ((maxs - X_train) / rng)
NOTE: Sở dĩ có xuất hiện label là vì mình sẽ đưa bài toán này trở thành một bài toán phân lớp với nội dung là giá cổ phiếu có tăng (hoặc giảm) hay không tại ngày mở của thứ 10 sau đó (returnsOpenNextMktres10). Lý do tại sao lại như vậy thì phần sau các bạn sẽ rõ hơn bởi cách tính confidence value.
5.2. Xây dựng mô hình
Với bài toán này mình có thử nghiệm 2 thuật toán là XGBoost và lightgbm và kết quả là lightgbm cho kết quả tốt hơn. Các bạn có thể tham khảo phần code của mình dưới đây.
import lightgbm as lgb
train_data = lgb.Dataset(X_train, label=up_train.astype(int))
# Bộ tham số dưới đây mình có tham khảo của các pro khác sau quá trình tunning của mình cho kết quả không tốt
x_1 = [0.19000424246380565, 2452, 212, 328, 202]
x_2 = [0.19016805202090095, 2583, 213, 312, 220]
params_1 = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': x_1[0],
'num_leaves': x_1[1],
'min_data_in_leaf': x_1[2],
'num_iteration': 239,
'max_bin': x_1[4],
'verbose': 1
}
params_2 = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'learning_rate': x_2[0],
'num_leaves': x_2[1],
'min_data_in_leaf': x_2[2],
'num_iteration': 172,
'max_bin': x_2[4],
'verbose': 1
}
gbm_1 = lgb.train(params_1,
train_data,
num_boost_round=100,
)
gbm_2 = lgb.train(params_2,
train_data,
num_boost_round=100,
)
5.3. Predict và ghi Submission file
- Load dữ liệu test từ environment:
days = env.get_prediction_days()
- Tiếp theo chúng ta cần dự đoán confidence value. Cách mình tính giá trị này của mình như như sau:
Trong đó p là xác suất dự đoán mã cổ phiếu i sẽ tăng hay giảm vào ngày thứ t. Ở trên các bạn có thể thấy mình xây dựng 2 mô hình với 2 bộ tham số khác nhau để đảm bảo hơn tính chính xác của kết quả. Code phần predict và ghi Submission file sẽ như sau:
#prediction
days = env.get_prediction_days()
total_market_obs_df = []
for (market_obs_df, news_obs_df, predictions_template_df) in days:
full_df = data_preprocessing(market_obs_df, news_obs_df)
X_live = full_df.drop(['assetCode', 'time', 'assetName', 'assetCodes', 'firstCreated'], axis=1)
X_live = X_live.values
X_live = 1 - ((maxs - X_live) / rng)
lp = (gbm_1.predict(X_live) + gbm_2.predict(X_live))/2
confidence = lp
confidence = (confidence-confidence.min())/(confidence.max()-confidence.min())
confidence = confidence * 2 - 1
preds = pd.DataFrame({'assetCode':market_obs_df['assetCode'],'confidence':confidence})
predictions_template_df = predictions_template_df.merge(preds,how='left').drop('confidenceValue',axis=1).fillna(0).rename(columns={'confidence':'confidenceValue'})
env.predict(predictions_template_df)
env.write_submission_file()
6. Kết quả
Trên đây là kết quả submiss của mình. Kết thúc giai đoạn Submission thì score của mình nằm trong top 18% của Public Leaderboard. Tuy nhiên sau mấy lần update lại Leaderboard (như mình nói ở trên với challenge này kết quả sẽ được update lại sau một thời gian chạy thử nghiệm thực tế trong 4 tháng) thì kết quả của mình cũng lên xuống khá là thất thường và hiện tại thì đang dừng chân tại top 12% (hạng 324/2927). Khá là cùi và dự là sẽ tiếp tục giảm trong những lần update tiếp theo.
All rights reserved
