Intent Recognition với BERT sử dụng Keras và TensorFlow 2
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
- Nhận dạng ý định (Recognizing intent - IR) từ văn bản là rất hữu ích trong ngày nay. Thông thường, bạn nhận được một văn bản ngắn và phải phân loại nó thành một (hoặc nhiều) danh mục.
- Nhiều hệ thống hỗ trợ sản phẩm (trung tâm trợ giúp) sử dụng IR để giảm nhu cầu về số lượng lớn nhân viên sao chép và dán các câu trả lời nhàm chán cho các câu hỏi thường gặp. Chatbots, trả lời email tự động, trả lời người giới thiệu (từ một cơ sở kiến thức với câu hỏi và câu trả lời) cố gắng không để bạn mất thời gian của người thật.
- Hướng dẫn này sẽ chỉ cho bạn cách sử dụng mô hình NLP được đào tạo trước có thể giải quyết vấn đề hỗ trợ (kỹ thuật) mà nhiều chủ doanh nghiệp gặp phải. Ở bài viết này là BERT. Nó thực sự dễ sử dụng. Code hoàn chỉnh trên notebook Project github
Dữ liệu
- Dữ liệu chứa các truy vấn người dùng khác nhau được phân loại thành bảy ý định. Nó được lưu trữ trên GitHub.
- Dưới đây là các ý định:
- SearchCreativeWork (ví dụ: Tìm tôi, chương trình truyền hình Robot)
- GetWeather (ví dụ: Có gió ở Boston, MA ngay bây giờ không?)
- BookR Restaurant (ví dụ: Tôi muốn đặt một nhà hàng được đánh giá cao cho tôi và bạn gái vào tối mai)
- PlayMusic (ví dụ: Chơi bản nhạc cuối cùng từ Beyoncé ngoài Spotify)
- AddToPlaylist (ví dụ: Thêm Diamonds vào danh sách phát roadtrip của tôi)
- RateBook (ví dụ: Tặng 6 sao cho Mice and Men)
- SearchScreeningEvent (ví dụ: Kiểm tra lịch chiếu cho Wonder Woman ở Paris)
- Tôi đã thực hiện một chút tiền xử lý và chuyển đổi các tệp JSON thành các tệp CSV dễ sử dụng. Hãy tải chúng xuống:
!gdown --id 1OlcvGWReJMuyYQuOZm149vHWwPtlboR6 --output train.csv
!gdown --id 1Oi5cRlTybuIF2Fl5Bfsr-KkqrXrdt77w --output valid.csv
!gdown --id 1ep9H6-HvhB4utJRLVcLzieWNUSG3P_uF --output test.csv
- Chúng tôi sẽ tải dữ liệu vào các khung dữ liệu và mở rộng dữ liệu đào tạo bằng cách hợp nhất các ý định đào tạo và xác nhận:
train = pd.read_csv("train.csv")
valid = pd.read_csv("valid.csv")
test = pd.read_csv("test.csv")
train = train.append(valid).reset_index(drop=True)
- Chúng tôi có 13,784 các ví dụ đào tạo và hai cột - text và intent. Chúng ta hãy xem số lượng văn bản cho mỗi ý định:
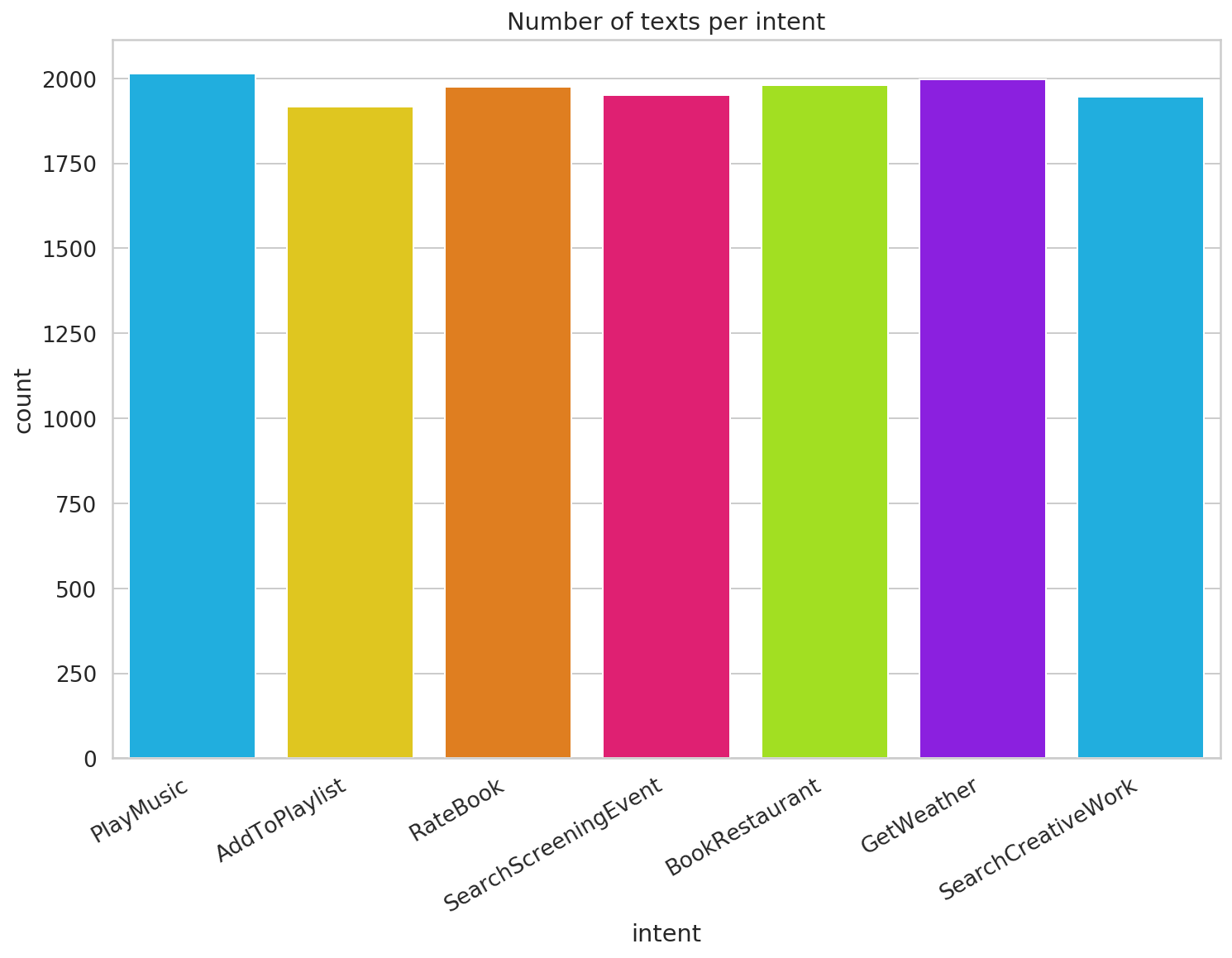
- Lượng văn bản cho mỗi ý định khá cân bằng, vì vậy chúng tôi sẽ không cần bất kỳ kỹ thuật mô hình mất cân bằng nào.
BERT
- Mô hình BERT (Bidirectional Encoder Representations from Transformers) - Đại diện bộ mã hóa hai chiều từ máy biến áp, được giới thiệu trong bài viết BERT: Đào tạo trước máy biến áp hai chiều sâu để hiểu ngôn ngữ, có thể đạt được kết quả tốt trong nhiều nhiệm vụ NLP khác nhau, cho người thực hành ML thông thường. Và bạn có thể làm điều đó mà không cần một bộ dữ liệu lớn! Nhưng làm thế nào là điều này có thể?
- BERT là một ngăn xếp Bộ mã hóa biến áp được đào tạo trước. Nó được đào tạo trên Wikipedia và bộ dữ liệu Book Corpus. Nó có hai phiên bản - Base (12 bộ mã hóa) và Large (24 bộ mã hóa).
- BERT được xây dựng dựa trên nhiều ý tưởng thông minh của cộng đồng NLP. Một số ví dụ là ELMo , The Transformer và OpenAI Transformer.
- ELMo đã giới thiệu các từ nhúng theo ngữ cảnh (một từ có thể có nghĩa khác dựa trên các từ xung quanh nó). The Transformer sử dụng các cơ chế chú ý để hiểu ngữ cảnh mà từ đó đang được sử dụng. Bối cảnh đó sau đó được mã hóa thành một vector đại diện. Trong thực tế, nó làm một công việc tốt hơn với sự phụ thuộc lâu dài.
- BERT là một mô hình hai chiều (nhìn cả về phía trước và phía sau). Và tốt nhất trong tất cả, BERT có thể dễ dàng được sử dụng như một trình trích xuất tính năng hoặc tinh chỉnh với một lượng nhỏ dữ liệu. Làm thế nào tốt là nó nhận ra ý định từ văn bản?
Nhận biết ý định với BERT
- Các tác giả của bài báo BERT đã public open sourced công việc của họ cùng với nhiều mô hình được đào tạo trước. Việc triển khai ban đầu là trong TensorFlow, nhưng cũng có những triển khai PyTorch rất tốt!
- Hãy bắt đầu bằng cách tải xuống một trong những mô hình được đào tạo trước đơn giản hơn và giải nén nó:
!wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
!unzip uncased_L-12_H-768_A-12.zip
- Điều này sẽ giải nén một checkout, cấu hình và từ vựng, cùng với các tệp khác.
- Thật không may, việc triển khai ban đầu không tương thích với TensorFlow 2. Gói bert-for-tf2 giải quyết vấn đề này.
Tiền xử lý
- Chúng ta cần chuyển đổi các văn bản thô thành các vectơ mà chúng ta có thể đưa vào mô hình của mình. Chúng ta sẽ trải qua 3 bước:
- Token hóa văn bản
- Chuyển đổi chuỗi mã thông báo thành số
- Căn các chuỗi sao cho mỗi cái có cùng độ dài
- Hãy bắt đầu bằng cách tạo BERT tokenizer:
tokenizer = FullTokenizer(vocab_file=os.path.join(bert_ckpt_dir, "vocab.txt"))
- Chúng ta sẽ tách nó:
tokenizer.tokenize("I can't wait to visit Bulgaria again!")
- Kết quả trả về là một mảng các từ đã được phân tách:
['i', 'can', "'", 't', 'wait', 'to', 'visit', 'bulgaria', 'again', '!']
- Các mã thông báo được viết thường và dấu câu có sẵn. Tiếp theo, chúng tôi sẽ chuyển đổi mã thông báo thành số. Tokenizer cũng có thể làm điều này:
tokens = tokenizer.tokenize("I can't wait to visit Bulgaria again!")
tokenizer.convert_tokens_to_ids(tokens)
- Kết quả là một mảng các số đã được chuyển đổi:
[1045, 2064, 1005, 1056, 3524, 2000, 3942, 8063, 2153, 999]
- Chúng ta sẽ tự làm phần đệm (padding). Bạn cũng có thể sử dụng các dụng cụ đệm Keras cho phần đó.
- Chúng ta sẽ đóng gói phần tiền xử lý vào một class chủ yếu dựa trên lớp từ notebook này :
class IntentDetectionData:
DATA_COLUMN = "text"
LABEL_COLUMN = "intent"
def __init__(
self,
train,
test,
tokenizer: FullTokenizer,
classes,
max_seq_len=192
):
self.tokenizer = tokenizer
self.max_seq_len = 0
self.classes = classes
((self.train_x, self.train_y), (self.test_x, self.test_y)) =\
map(self._prepare, [train, test])
print("max seq_len", self.max_seq_len)
self.max_seq_len = min(self.max_seq_len, max_seq_len)
self.train_x, self.test_x = map(
self._pad,
[self.train_x, self.test_x]
)
def _prepare(self, df):
x, y = [], []
for _, row in tqdm(df.iterrows()):
text, label =\
row[IntentDetectionData.DATA_COLUMN], \
row[IntentDetectionData.LABEL_COLUMN]
tokens = self.tokenizer.tokenize(text)
tokens = ["[CLS]"] + tokens + ["[SEP]"]
token_ids = self.tokenizer.convert_tokens_to_ids(tokens)
self.max_seq_len = max(self.max_seq_len, len(token_ids))
x.append(token_ids)
y.append(self.classes.index(label))
return np.array(x), np.array(y)
def _pad(self, ids):
x = []
for input_ids in ids:
input_ids = input_ids[:min(len(input_ids), self.max_seq_len - 2)]
input_ids = input_ids + [0] * (self.max_seq_len - len(input_ids))
x.append(np.array(input_ids))
return np.array(x)
- Chúng tôi tìm ra chiều dài đệm bằng cách lấy tối thiểu giữa văn bản dài nhất và tham số độ dài chuỗi tối đa. Chúng tôi cũng bao quanh các mã thông báo cho mỗi văn bản bằng hai mã thông báo đặc biệt: bắt đầu bằng [CLS] và kết thúc bằng [SEP].
Tinh chỉnh
- Hãy làm cho BERT có thể sử dụng để phân loại văn bản! Chúng tôi sẽ tải mô hình và đính kèm một vài lớp trên nó:
def create_model(max_seq_len, bert_ckpt_file):
with tf.io.gfile.GFile(bert_config_file, "r") as reader:
bc = StockBertConfig.from_json_string(reader.read())
bert_params = map_stock_config_to_params(bc)
bert_params.adapter_size = None
bert = BertModelLayer.from_params(bert_params, name="bert")
input_ids = keras.layers.Input(
shape=(max_seq_len, ),
dtype='int32',
name="input_ids"
)
bert_output = bert(input_ids)
print("bert shape", bert_output.shape)
cls_out = keras.layers.Lambda(lambda seq: seq[:, 0, :])(bert_output)
cls_out = keras.layers.Dropout(0.5)(cls_out)
logits = keras.layers.Dense(units=768, activation="tanh")(cls_out)
logits = keras.layers.Dropout(0.5)(logits)
logits = keras.layers.Dense(
units=len(classes),
activation="softmax"
)(logits)
model = keras.Model(inputs=input_ids, outputs=logits)
model.build(input_shape=(None, max_seq_len))
load_stock_weights(bert, bert_ckpt_file)
return model
- Chúng ta đang tinh chỉnh mô hình BERT được đào tạo trước bằng cách sử dụng đầu vào (văn bản và ý định) của chúng ta. Chúng ta cũng làm phẳng đầu ra và thêm Dropout với hai lớp được kết nối đầy đủ. Lớp cuối cùng có chức năng kích hoạt softmax. Số lượng đầu ra bằng với số lượng ý định chúng ta có - bảy.
- Bây giờ bạn có thể sử dụng BERT để nhận dạng ý định!
Đào tạo
- Đó là thời gian để đặt mọi thứ lại với nhau. Chúng ta sẽ bắt đầu bằng cách tạo data object:
classes = train.intent.unique().tolist()
data = IntentDetectionData(
train,
test,
tokenizer,
classes,
max_seq_len=128
)
- Bây giờ chúng ta có thể tạo mô hình bằng cách sử dụng độ dài chuỗi tối đa:
model = create_model(data.max_seq_len, bert_ckpt_file)
- Kết quả mô hình:
model.summar()
- Các mô hình tinh chỉnh như BERT vừa là nghệ thuật vừa thực hiện hàng tấn thử nghiệm thất bại. May mắn thay, các tác giả đã đưa ra một số khuyến nghị:
- Kích thước Batch: 16, 32
- Tỷ lệ học (Adam): 5e-5, 3e-5, 2e-5
- Số lượng epochs: 2, 3, 4
model.compile(
optimizer=keras.optimizers.Adam(1e-5),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")]
)
- Chúng ta sẽ sử dụng Adam với một tỷ lệ học khác nhau và sử dụng giao thức phân loại thưa thớt, vì vậy chúng ta không phải mã hóa one-hot các nhãn của chúng ta.
- Bây giờ truyền data model:
log_dir = "log/intent_detection/" +\
datetime.datetime.now().strftime("%Y%m%d-%H%M%s")
tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir)
model.fit(
x=data.train_x,
y=data.train_y,
validation_split=0.1,
batch_size=16,
shuffle=True,
epochs=5,
callbacks=[tensorboard_callback]
)
- Chúng ta lưu trữ nhật ký đào tạo, vì vậy bạn có thể khám phá quy trình đào tạo trong Tensorboard. Chúng ta hãy có một cái nhìn:
![]()
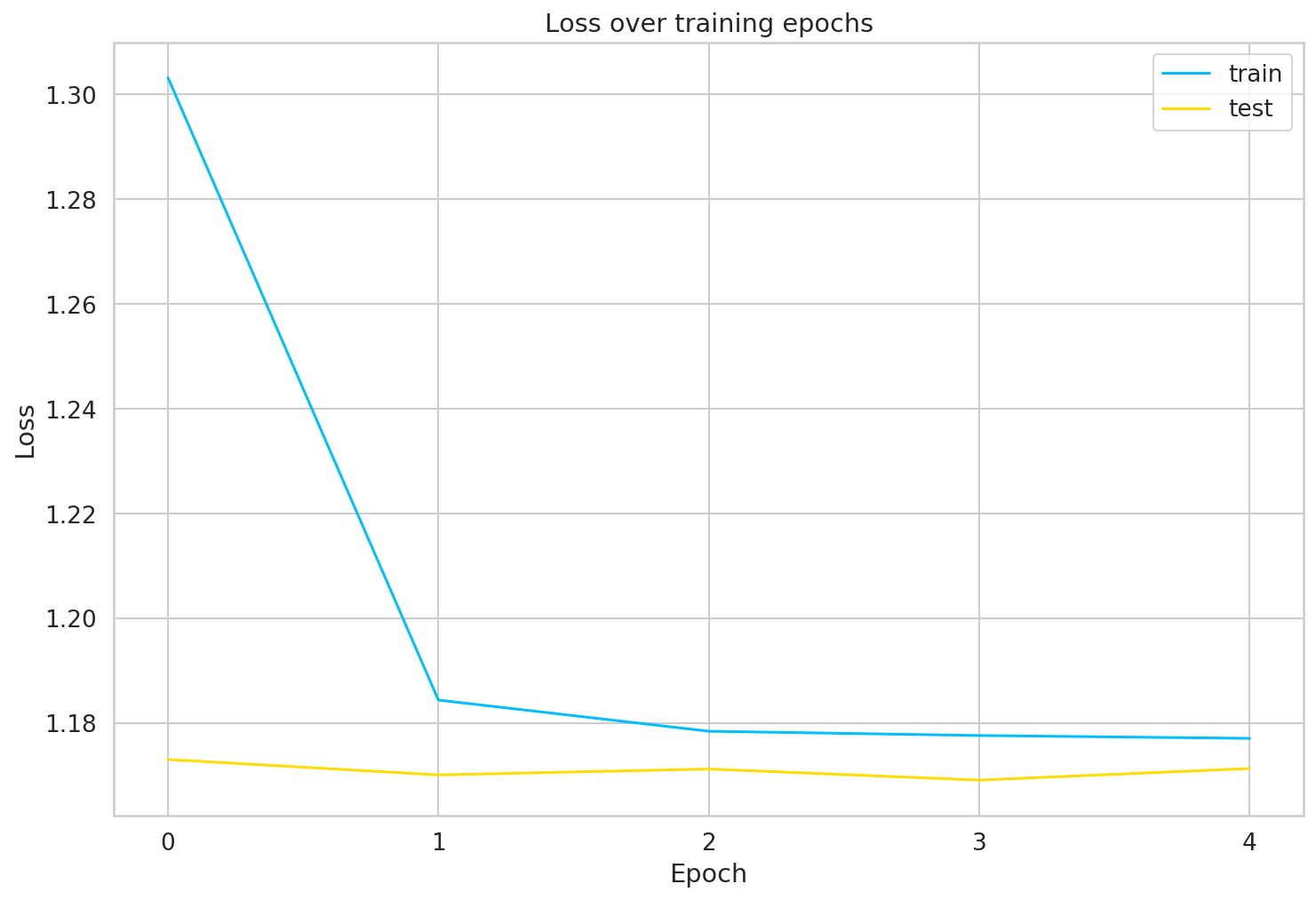
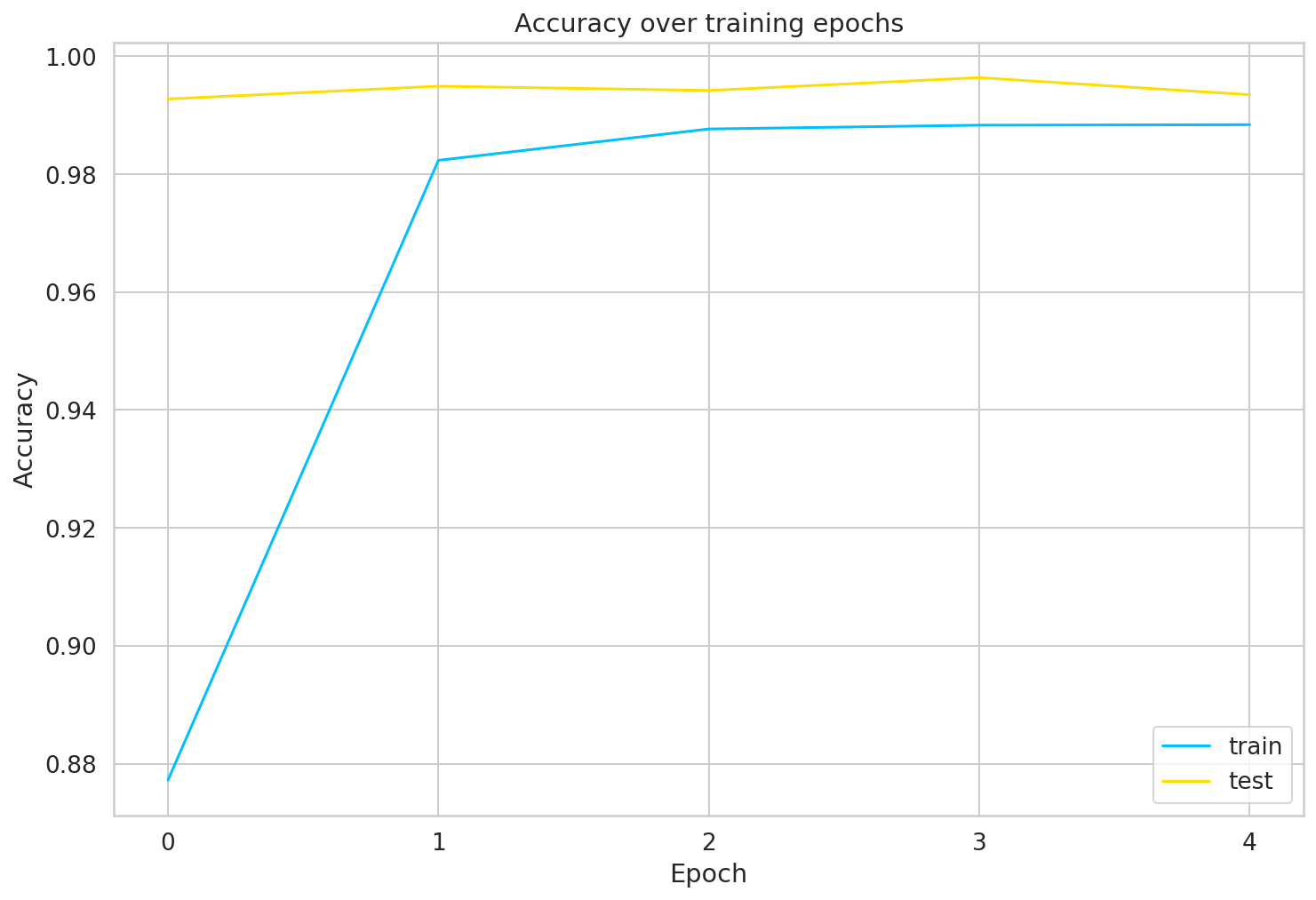
Đánh giá
- Thực sự rất ấn tượng với kết quả. Đào tạo chỉ sử dụng 12,5k mẫu chúng ta nhận được:
_, train_acc = model.evaluate(data.train_x, data.train_y)
_, test_acc = model.evaluate(data.test_x, data.test_y)
print("train acc", train_acc)
print("test acc", test_acc)
train acc 0.9915119
test acc 0.9771429
-
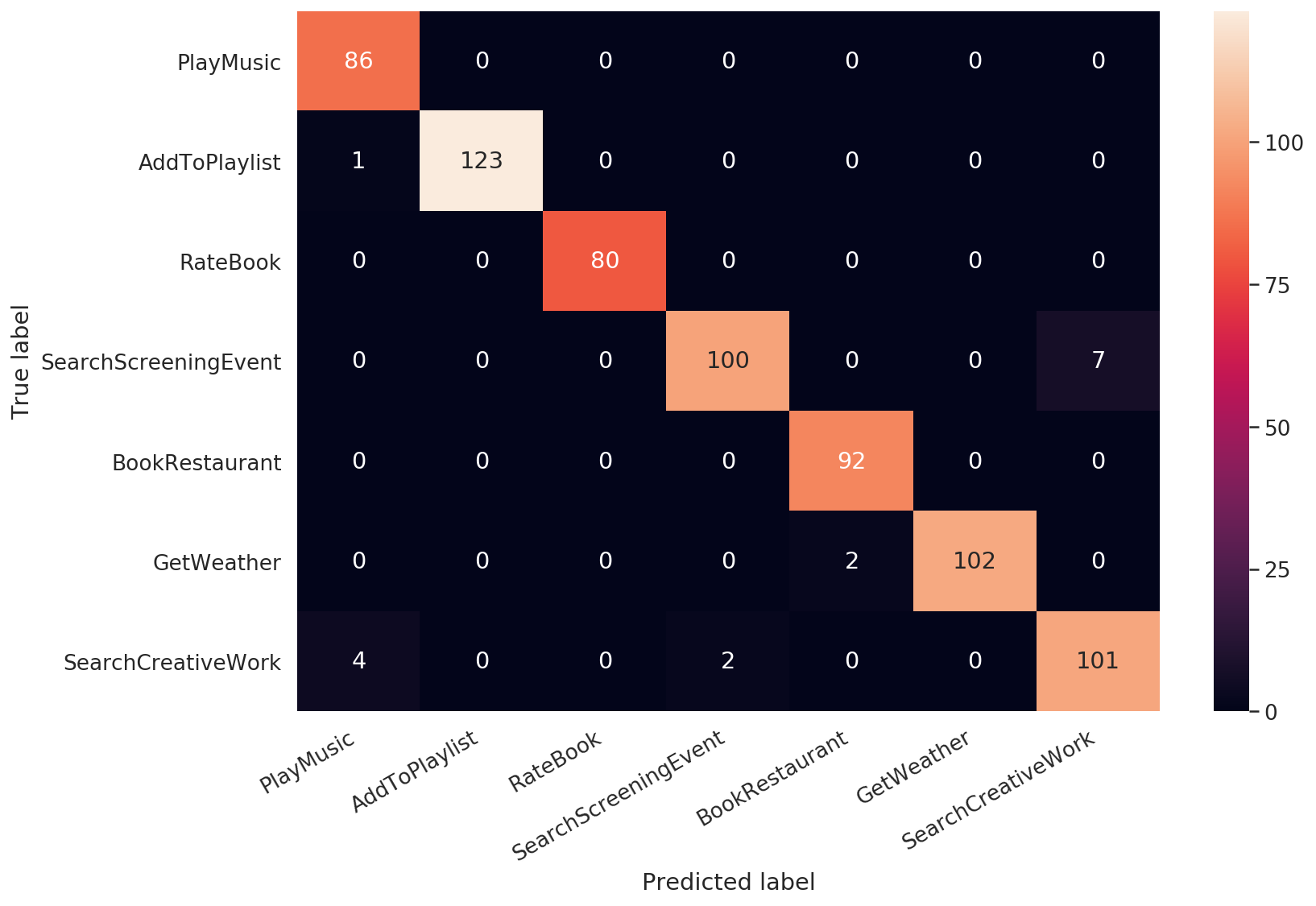
Ấn tượng phải không? Chúng ta hãy xem ma trận nhầm lẫn giữa các ý định:
![]()
-
Cuối cùng, hãy sử dụng mô hình để phát hiện ý định từ một số câu tùy chỉnh:
sentences = [
"Play our song now",
"Rate this book as awful"
]
pred_tokens = map(tokenizer.tokenize, sentences)
pred_tokens = map(lambda tok: ["[CLS]"] + tok + ["[SEP]"], pred_tokens)
pred_token_ids = list(map(tokenizer.convert_tokens_to_ids, pred_tokens))
pred_token_ids = map(
lambda tids: tids +[0]*(data.max_seq_len-len(tids)),
pred_token_ids
)
pred_token_ids = np.array(list(pred_token_ids))
predictions = model.predict(pred_token_ids).argmax(axis=-1)
for text, label in zip(sentences, predictions):
print("text:", text, "\nintent:", classes[label])
print()
- Kết quả của chúng ta:
text: Play our song now
intent: PlayMusic
text: Rate this book as awful
intent: RateBook
Kết luận
- Bây giờ bạn đã biết cách tinh chỉnh mô hình BERT để phân loại văn bản. Bạn có thể đã biết rằng bạn cũng có thể sử dụng nó cho một loạt các nhiệm vụ khác! Bạn chỉ cần mân mê với các lớp. Chúc bạn thành công!
- Nguồn bài viết: Intent Recognition with BERT using Keras and TensorFlow 2 của tác giả Venelin Valkov
All rights reserved
