[GPU in AI] Bài 9: GPU memory hoạt động trong PyTorch
Ở bài này mình sẽ nói về 2 khái niệm khá quan trọng trong Pytorch GPU memory là Allocated - Reserved
Allocated - Reserved
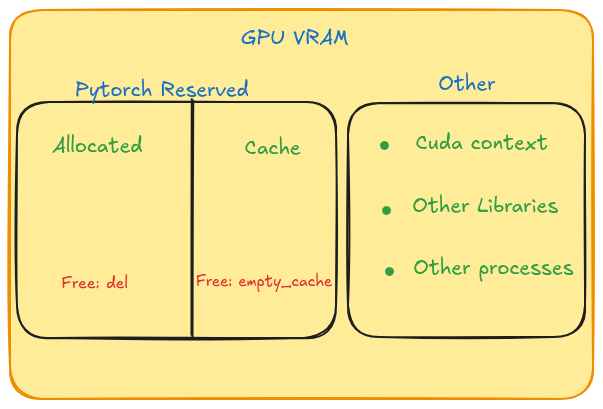
Allocated memory: là GPU memory đang thực sự được tensor sử dụng tại thời điểm hiện tại.
Tạo tensor => Allocated tăng
Xóa tensor => Allocated giảm
Chúng ta có thể kiểm tra bằng: torch.cuda.memory_allocated()
Reserved memory: là tổng GPU memory mà PyTorch gọi thông qua CUDA API ( backend: cudaMallocAsync). Reserved gồm Allocated (memory đang được tensor sử dụng) và cả Cached memory — tức là các block đã từng được sử dụng nhưng hiện chưa có tensor nào giữ.
Mục đích của cache là để tái sử dụng các block này cho những lần sau, thay vì phải gọi lại CUDA API để cấp phát bộ nhớ. Vì vậy, khi một tensor bị xóa, phần memory của nó sẽ không được trả ngay về CUDA, mà được chuyển sang trạng thái cached để phục vụ cho các tác vụ sau.
Chúng ta có thể kiểm tra bằng: torch.cuda.memory_reserved()
Other: Là phần GPU memory không do PyTorch quản lý. Bao gồm:
- CUDA context (được tạo khi khởi tạo CUDA)
- Các thư viện backend như cuDNN, cuBLAS, NCCL…
- Các process khác đang sử dụng GPU
Vì không nằm trong quyền kiểm soát của Pytorch nên: không thể giải phóng được bằng del hoặc empty_cache() và vẫn hiển thị trong nvidia-smi
Demo
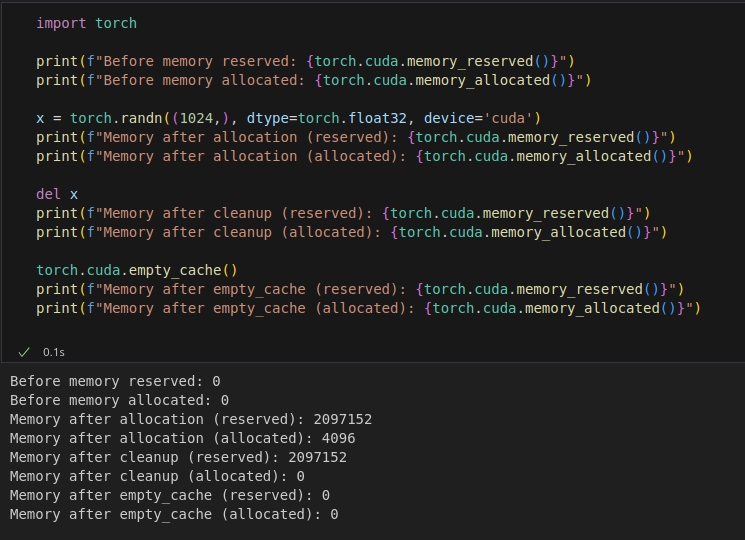
Các bạn có thể thử đổi thứ tự của del và empty_cache() để hiểu rõ hơn cách memory hoạt động
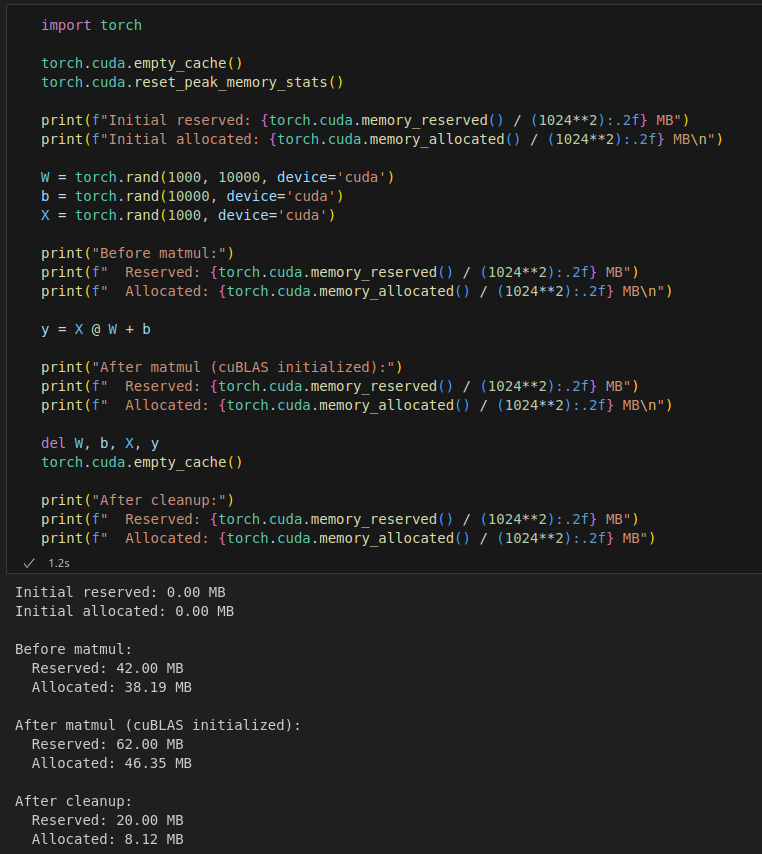
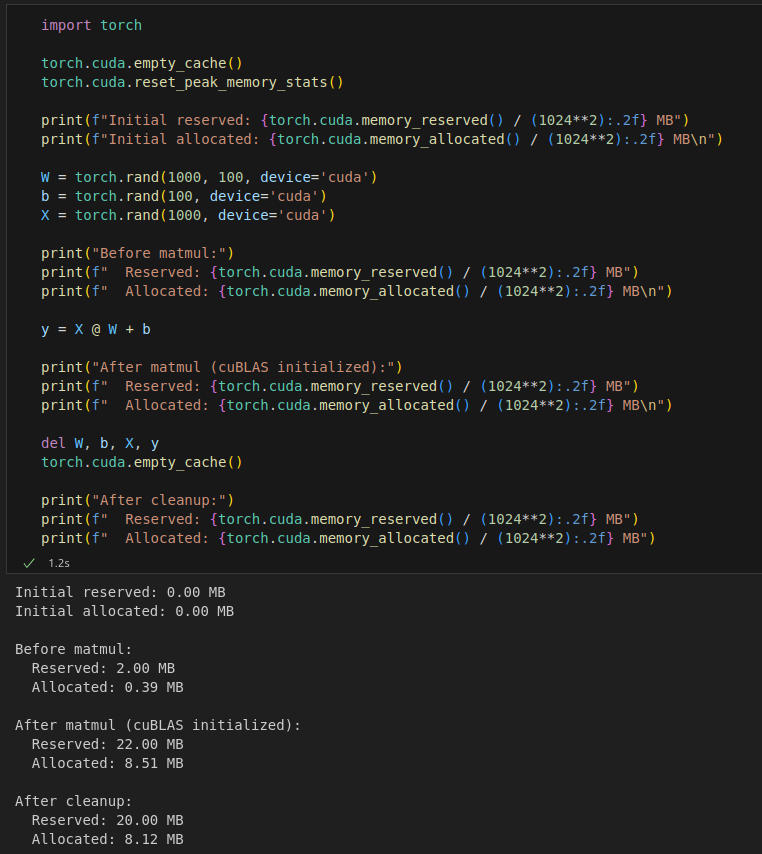
Ở đây các bạn có thể thấy after cleanup = after matmul - before matmul và quan trọng là thay đổi before matmul thì after cleanup vẫn như cũ là vì other ( cụ thể ở đây là CuBLAS ) và như mình đã nói là other vẫn còn hiện thị trên nvidia-smi
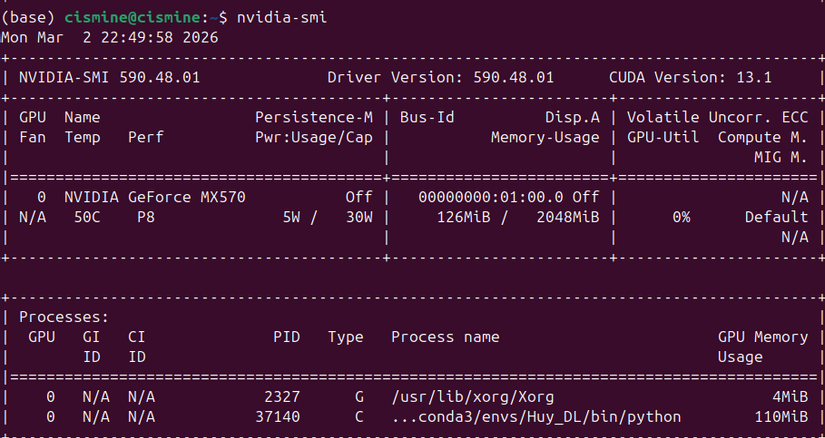
Ở đây là vì other không thuộc quyền kiểm soát của Pytorch nên memory khi xem bằng Pytorch và nvidia-smi sẽ khác nhau
Các bạn có thể tìm hiểu sâu hơn ở đây
All rights reserved
