[GPU in AI] Bài 10: Mixed Precision Phần 1
Trong bài viết này, mình sẽ giới thiệu một kỹ thuật giúp giảm bộ nhớ của model và tăng tốc quá trình train, trong khi độ chính xác gần như không thay đổi.
Trong PyTorch, khi khởi tạo tensor hoặc các tham số của model, kiểu dữ liệu mặc định thường là float32. Điều này dẫn đến quá trình train được thực hiện bởi các phép toán với độ chính xác là 32-bit. Mặc dù float32 mang lại độ chính xác cao, nhưng nó cũng khiến mô hình tiêu tốn nhiều bộ nhớ hơn và thời gian tính toán lâu hơn, đặc biệt với các mô hình lớn.
Và ở đây ý tưởng sẽ là scale từ float32 về còn float16 để tính toán, điều này giúp:
- Giảm đáng kể lượng bộ nhớ cần sử dụng
- Tăng tốc độ tính toán, đặc biệt khi chạy trên GPU hỗ trợ Tensor Core
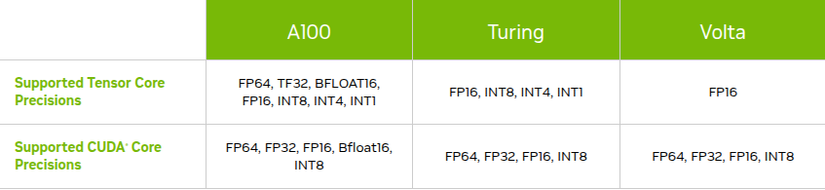
Có thể hiểu đơn giản là Cuda core dùng để tính toán các phép tính chung cùa GPU ( như +, -, * , / ).
Còn Tensor core là core chuyên dụng cho AI và được tạo ra để tối ưu các phép toán như matrix multiplication và convolution
Nhưng đều này đồng nghĩa với việc độ chính xác sẽ giảm đi rất nhiều, và để giải quyết vấn đề này mixed precision đã được ra đời
Mixed Precision
Mixed Precision: là 1 kĩ thuật kết hợp 2 kiểu dữ liệu float16 và float32 trong quá trình train. Ở đây các phép tính toán lớn sẽ được thực hiện bằng float16 ( như convolution hoặc matrix multiplication ) để giảm bộ nhớ và tăng tốc độ, còn những phần quan trọng như tính loss hoặc cập nhật weight thì vẫn sử dụng float32 để đảm bảo độ ổn định và độ chính xác của mô hình.
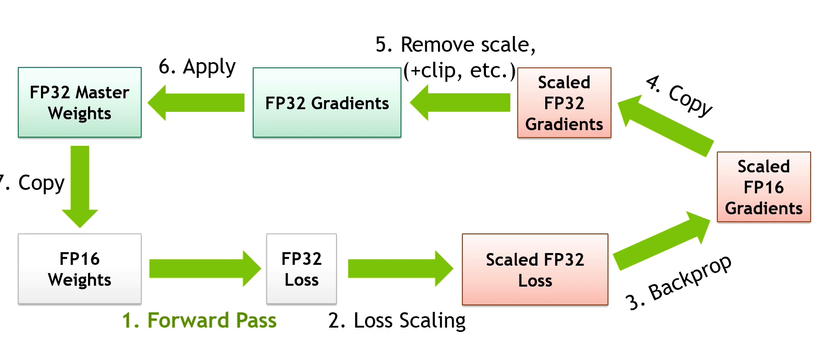
- Đầu tiên ta khởi tạo model ( mặc định sẽ là float32 ) sau đó sẽ được convert về float16 để tính forward
- Ở đây loss vẫn sẽ dùng float32 để đảm bảo độ chính xác
- Loss sẽ được scale lên ( nhân với 1 hệ số ) để tránh việc loss quá bé dẫn đến gradient không thể cập nhật khi tính toán ở float16.
- Sau khi backward bằng float16, gradient sẽ chuyển sang float32 để chuẩn bị cho bước cập nhật weight.
- Ở bước này ta chia gradient cho hệ số scale đã áp dụng trước đó để đưa gradient về giá trị ban đầu
- Cuối cùng, sử dụng FP32 gradients để cập nhật FP32 master weights thông qua optimizer. Sau đó chu trình training tiếp tục lặp lại cho batch tiếp theo.
Code
from torch.amp import autocast, GradScaler
scaler = GradScaler()
with autocast("cuda"):
output = model(x)
loss = criterion(output,y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
Ở đây autocast sẽ đảm nhiệm phép toán nào dùng float16 / float32. còn scaler sẽ giải quyết vấn đề gradient quá nhỏ (underflow) khi tính toán với float16 bằng cách scale loss trước khi backward.
Các bạn có thể thử print before và after scale của loss cũng như data-type của output để hiểu rõ hơn
Demo
Ở đây mình sẽ train trên bộ cifar10 bằng resnet18 với 2 epoch để so sánh dùng và không dùng mixed precision và kết quả đạt được
===== RESULTS =====
FP32 Accuracy: 0.7114
FP32 Memory : 3219.65 MB
FP32 Time : 309.41 sec
Mixed Accuracy: 0.6969
Mixed Memory : 1916.57 MB
Mixed Time : 252.56 sec
All rights reserved
