Giới thiệu về Prometheus, công cụ monitoring hiệu quả!
Bài đăng này đã không được cập nhật trong 4 năm

Một trong số các công cụ hữu ích mà mình sử dụng cho việc monitoring servers đó là Prometheus - An Opensource Time Series Database. Bài viết này dành cho các bạn đang tìm hiểu về Prometheus, với mục đích giúp các bạn nhanh chóng hiểu về cách mà Prometheus hoạt động, cách cài đặt và cấu hình prometheus trước khi biến các số liệu (metrics) thành những thứ ảo diệu hơn. Bây giờ hãy cùng mình tìm hiểu về nó nhé!
Time series database
Về Time Series Database - Là khái niệm được dùng để ám chỉ những database chuyên dụng, được tối ưu để lưu trữ dữ liệu theo các mốc thời gian. Prometheus cũng vậy. 
Dữ liệu mà nó lưu trữ có thể là các metrics (thông số) về tình trạng server như lượng RAM, CPU đã dùng của mỗi service, số lượng requests tới server, dung lượng đĩa..., bất cứ thứ gì bạn muốn.
Các metrics luôn gắn với một mốc thời gian, tạo thành một chuỗi dữ liệu theo thời gian, do vậy bạn có thể thông qua Prometheus để xem lại dữ liệu của server tại 1h trước đó hay 1month trước đó để điều tra sự cố trên server, hay cũng có thể giúp phát hiện ra những điều gì đó bất thường sớm. Quả thực đúng với slogan: From metrics to insight!
Cho một ví dụ: Server của bạn bị chậm đi trông thấy trong 3 ngày gần đây. Thông qua dữ liệu query từ Prometheus và visualize thành biếu đồ, bạn dễ dàng thấy server đột nhiên CPU luôn tăng cao trong những ngày này. Bạn bắt đầu đi kiểm tra các process và phát hiện những process lạ bị hacker cài cắm vào để thực hiện mục đích xấu như lợi dụng để đào coin. Đó! Prometheus đã giúp bạn rồi đấy!
Prometheus hoạt động như nào?
Prometheus sẽ chủ động pull (kéo) các metrics về qua HTTP mỗi 10s hay 30s do chúng ta thiết lập. Bản thân các service thì thường không thể tự export được các metrics cho Prometheus mà cần đến các Instructmentation/Exporter. Hai khái niệm này đều chung mục đích, nhưng có thể tạm hiểu như sau:
- Exporter là những app được viết cho mấy cái thông dụng như Database, Server. Chúng ta chỉ cần chạy nó và nó sẽ export các metrics thu thập được cho mình.
- Instructmentation thì ám chỉ nhưng client-libraries được cung cấp bởi Prometheus hoặc một bên thứ 3 nào đó, để mình cài vào ứng dụng của mình, giúp tùy biến những metrics riêng của hệ thống. Kiểu như số lượng người đã login vào website của mình từng giờ chẳng hạn.
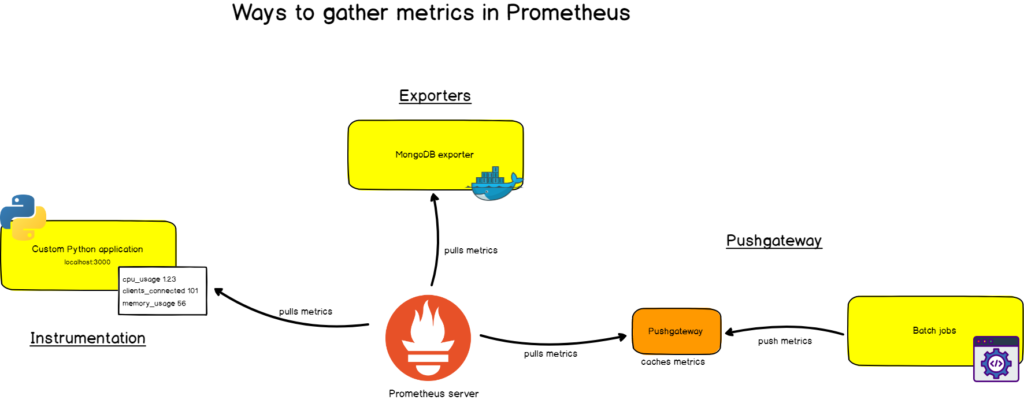
Một số exporter mình kể qua như:
- Prometheus: chính bản thân prometheus cũng có một built-in exporter, export các metrics về service prometheus ra tại URI: http://prometheus.lc:9090/metrics
- cAdvisor (xi ợt vai zờ): export các metrics của các docker service, các process trên server.
- Node Exporter: export các metrics một con node (hiểu là một server) như CPU, RAM của node, dung lượng ổ đĩa, số lượng request tới node đấy, .etc.
- Postgres Exporter, giúp đọc dữ liệu từ các bảng trong Postgres và export ra cho Prometheus
- HAProxy Exporter
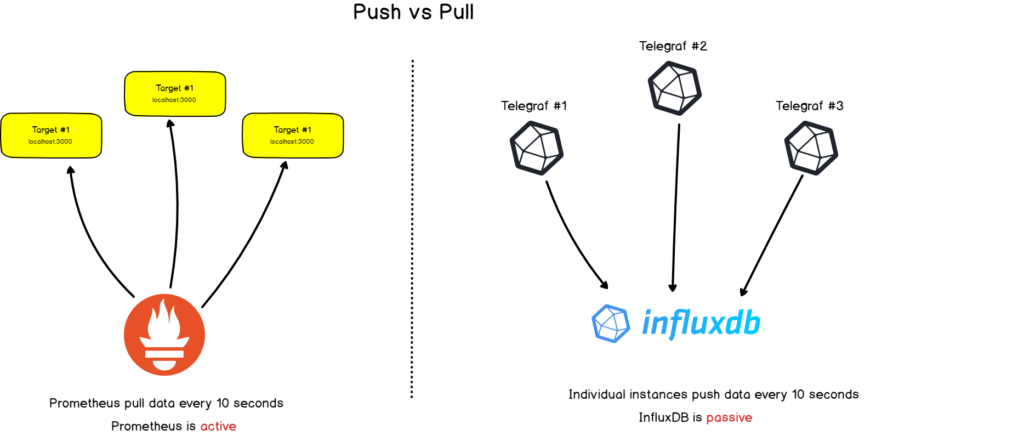
Trong một bài viết mình tham khảo cũng có so sánh cách hoạt động của Prometheus vs InfluxDB. Theo đó thì Prometheus chủ động tạo request tới các exporter để lấy dữ liệu về trong khi InfluxDB thì ở thế bị động, là các "exporter" sẽ đẩy dữ liệu tới InfluxDB.
Chúng ta cũng có thể tự viết riêng cho mình một Exporter theo document này: Writing Exporter - Prometheus Documentation!
Cài đặt Prometheus
Trong bài viết này mình sẽ sử dụng docker để cài đặt Prometheus, phần cài cặt Prometheus không sử dụng Docker cũng khá đơn giản. Các bạn có thể tham khảo tại đây: Installation - Prometheus Documentation. Cài đặt với Docker còn đơn giản và nhanh gọn hơn nữa, cùng mình bắt đầu nhé!
Scrape metrics từ built-in exporter
File cấu hình đề prometheus scrapes metrics từ built-in exporter:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
scrape_configs:
- job_name: prometheus
scrape_interval: 30s
static_configs:
- targets:
- localhost:9090
Phần global là cấu hình chung cho tất cả các scrape_configs, các config bên trong mỗi job scrape sẽ được ưu tiên dùng hơn cái global nếu có trùng lặp. Theo cấu hình trên, prometheus sẽ có một target để pull metrics về có tên là prometheus, tự động scrape mỗi 30s tới service đang chạy ở localhost:9090.
Thiết lập Prometheus với docker
Và đây là cấu hình để chạy prometheus lên với docker:
version: '3.6'
volumes:
grafana-data:
prometheus-data:
services:
prometheus:
image: prom/prometheus:v2.12.0
command:
- --config.file=/etc/prometheus/prometheus.yml
ports:
- 9090:9090
volumes:
- prometheus-data:/prometheus
Bây giờ dùng docker-compose để up prometheus rồi truy cập http://locahost:9090, bạn sẽ thấy trang Dashboard của Prometheus như hình sau:
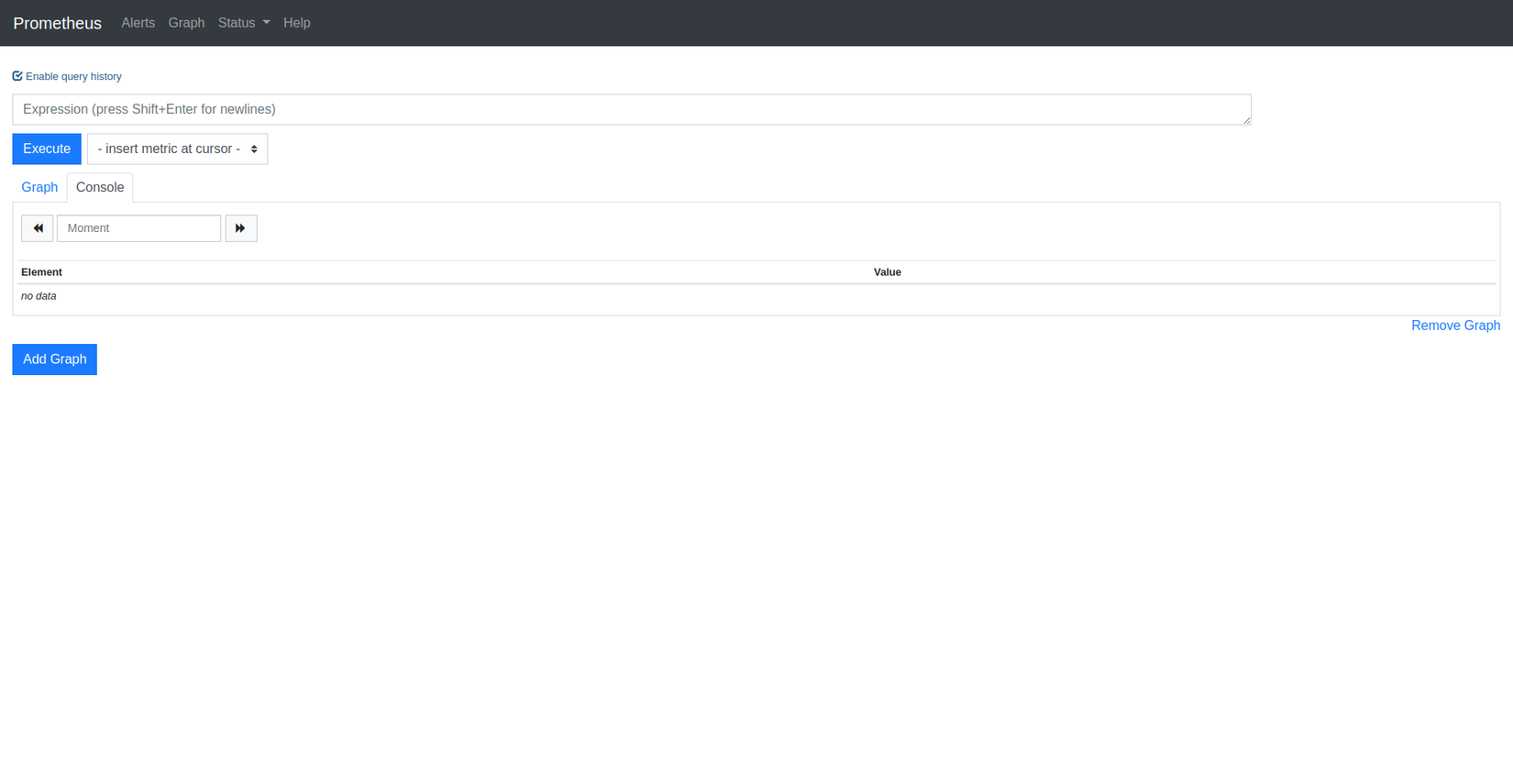
Dashboard của nó có gì?
Khám phá qua trang chủ, bạn sẽ thấy một Input là Expression, là chỗ để mình nhập các câu query PromQL - là một ngôn ngữ truy vấn dữ liệu được Prometheus tự tạo ra. Với ưu điểm là câu truy vấn siêu ngắn gọn và dễ hiểu.  Sau khi execute một query thì result sẽ hiển thị bên dưới ở tab
Sau khi execute một query thì result sẽ hiển thị bên dưới ở tab Console. Chúng ta có thể nhấn sang tab Graph để xem biểu đồ mà Prometheus vẽ sẵn cho chúng ta. Cái Graph này nó thực sự quá simple với nhu cầu thực tế  Vì vậy nên mọi người hay kết hợp với
Vì vậy nên mọi người hay kết hợp với Grafana để visualize kết quả.
Bạn hãy thử nhập tên một metric prometheus_http_requests_total mà prometheus đã scrape được vào Expression rồi chạy thử để lấy dữ liệu của metric này trong 5m vừa qua (5m = minutes, 5h = 5 hours, 5d = 5 days):
prometheus_http_requests_total
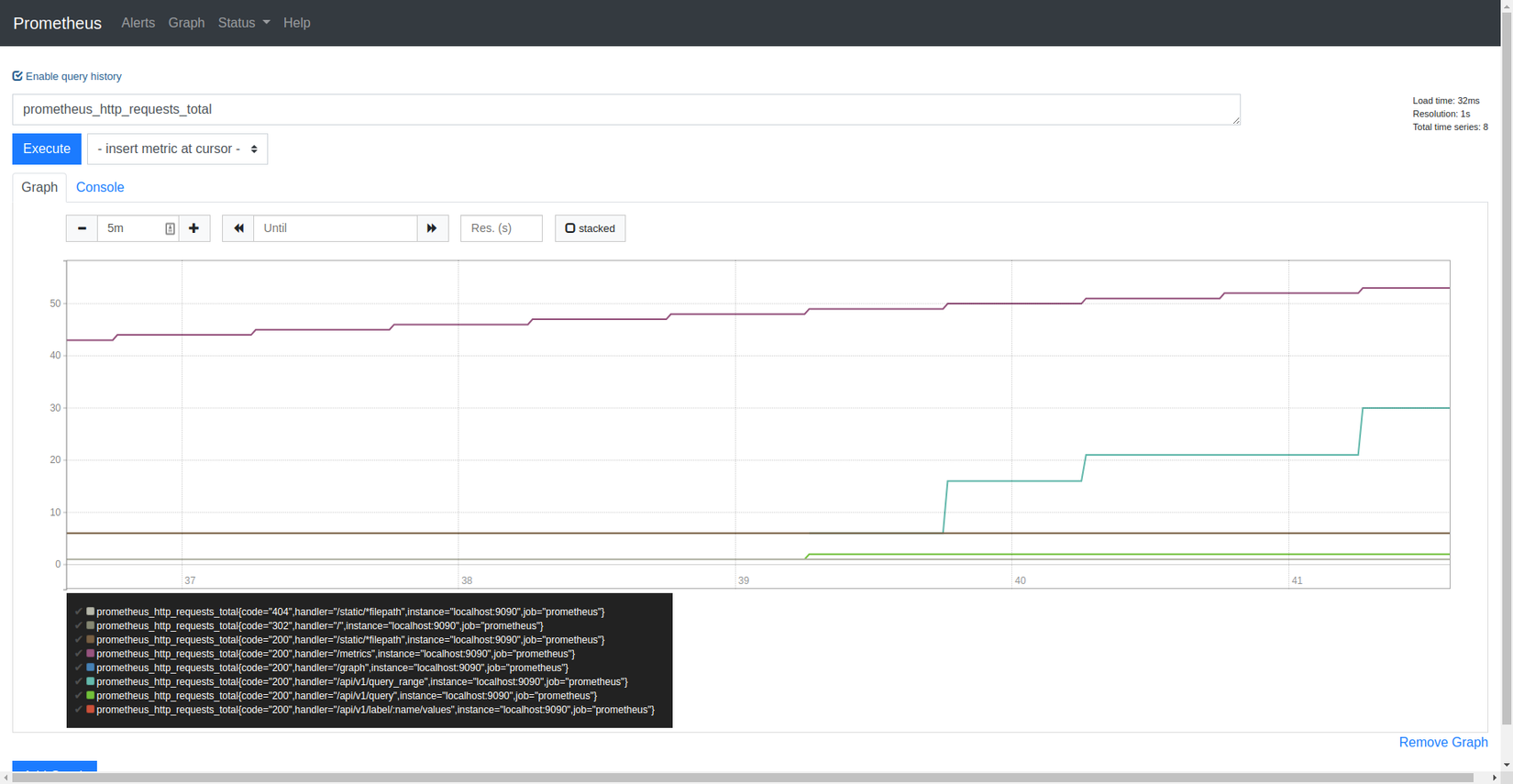
Về vấn đề truy vấn dữ với PromQL, mình sẽ có một bài viết khác để nói về nó. Các bạn hãy follow mình nhận thông báo ngay khi mình publish nhé!
Prometheus + cAdvisor
Ở phần trên, chúng ta đã thiết lập Prometheus tự động scrape dữ liệu từ chính nó. Để collect thêm các thông số của các service khác trên máy, chúng ta sẽ scrape thêm metrics từ cAdvisor.
Add cAdvisor vào docker-compose:
services:
prometheus:
...
cadvisor:
image: google/cadvisor:latest
volumes:
- /:/rootfs:ro
- /var/run:/var/run
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- 8008:8080
Tương tự, chúng ta sửa file cấu hình /configs/prometheus.yml để scrape metrics thêm từ cAdvisor.
scrape_configs:
- job_bane: prometheus
...
- job_name: cadvisor
scrape_interval: 10s
static_configs:
- targets:
- cadvisor:8080
Prometheus + Grafana
Chạy Grafana rất đơn giản, bạn chỉ cần thêm đoạn sau vào file docker-compose.yml:
services:
...
grafana:
image: grafana/grafana:6.3.5
ports:
- 3000:3000
environment:
GF_SECURITY_ADMIN_PASSWORD: secret
volumes:
- grafana-data:/var/lib/grafana
Truy cập http://localhost:3000 để vào trang dashboard của Grafana với username là admin và password là secret. Add data-source từ Prometheus như sau (URL tên service prometheus vì đang chạy trong docker network):
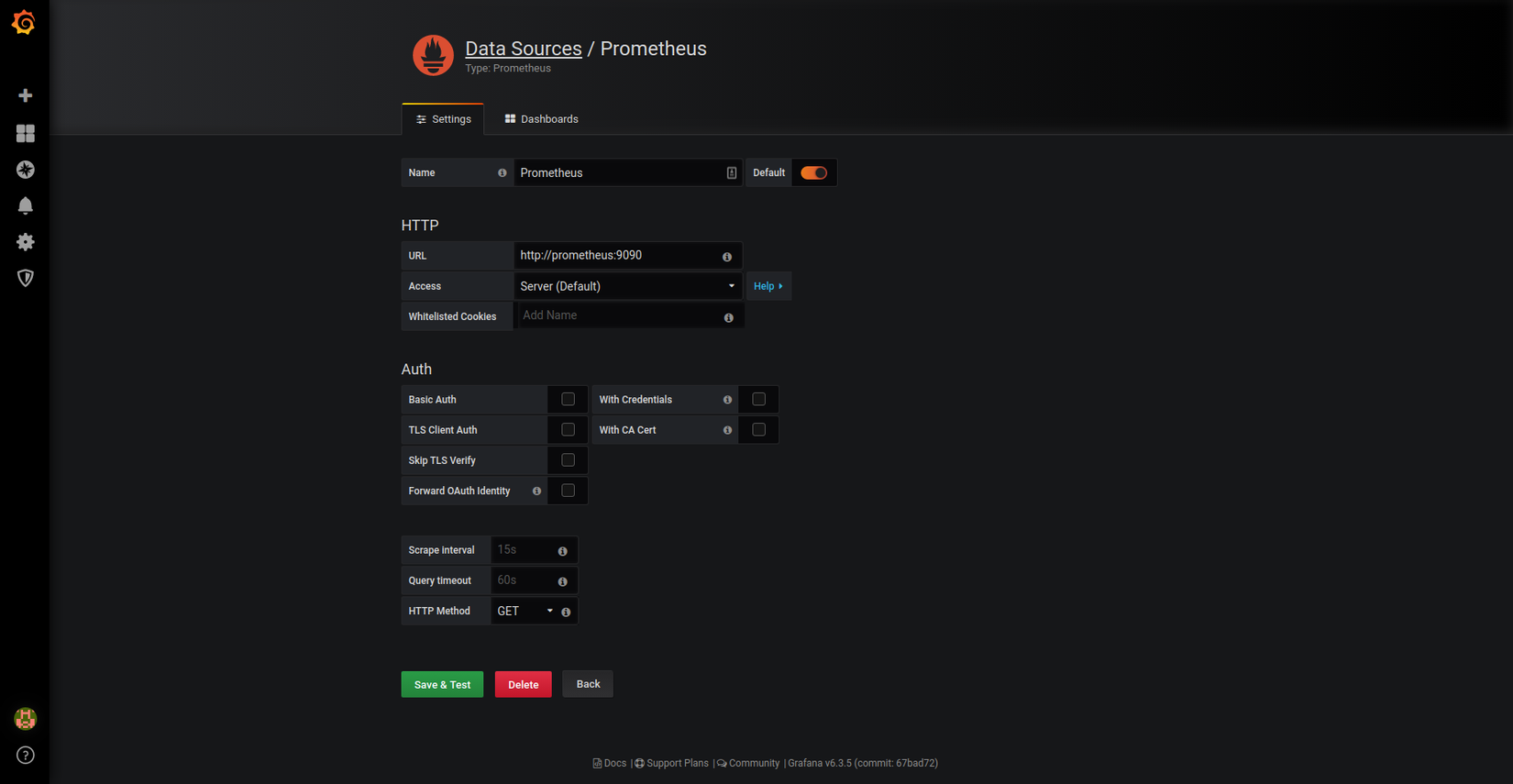
Chúng ta hãy tự mình thử visualize một metric là lưu lượng traffic đã nhận của mỗi container, bằng query data từ Prometheus như dưới đây:
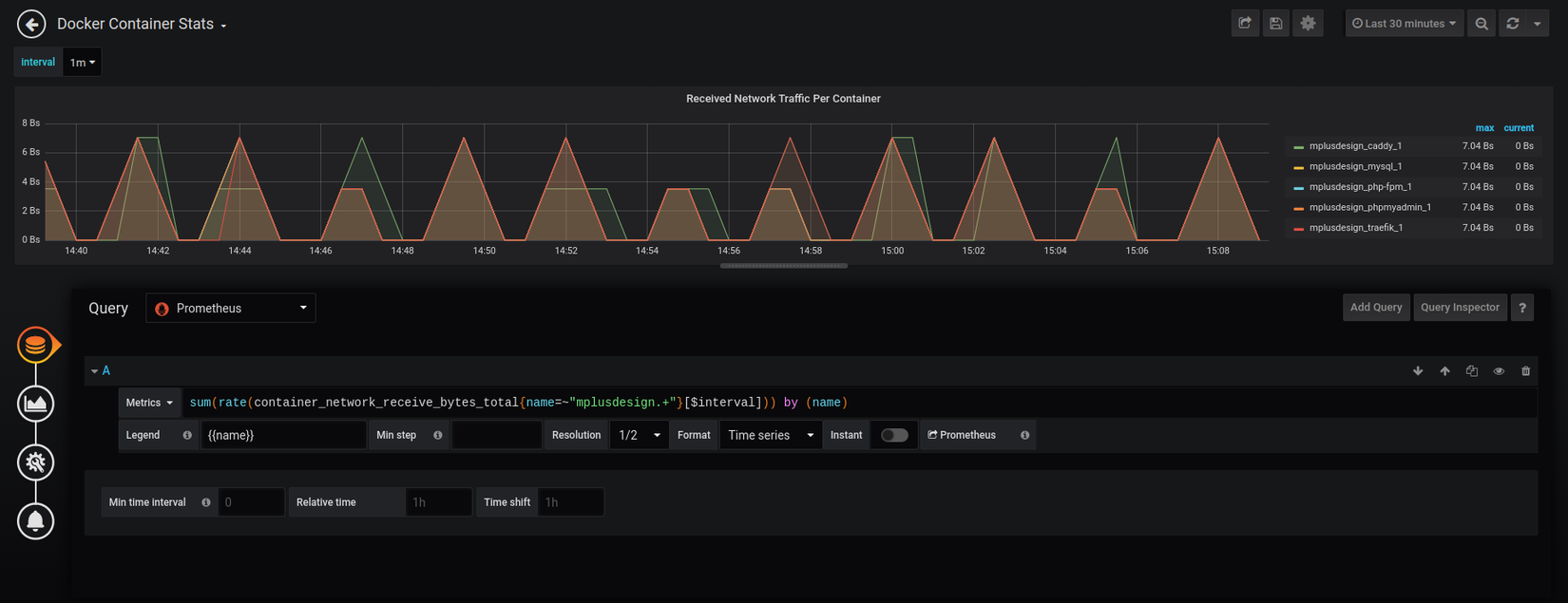
Grafana cũng cho phép mọi người chia sẻ các cấu hình Dashboard cho nhau, bạn có thể lên Grafana Dashboards tại đây để tìm và import vào hệ thống của mình.
Alerting
Ngoài khả năng lưu trữ, nó còn cung cấp cho chúng bạn một bộ alerting mạnh mẽ, giúp gửi thông báo tới các kênh mà bạn cài cắm khi các metrics đạt một mức giới hạn nào đó. Một số channel mình hay dùng như:
- Email (cách truyền thống nhưng khá hữu ích)
- Slack (anh em IT thì chắc là hay dùng rồi ha. )
- Webhook: Bạn có thể viết một API nhận dữ liệu có cấu trúc được prometheus chỉ định sẵn và Prometheus sẽ gửi request tới đúng chỗ.

Về cơ bản, bộ Alerting của Prometheus được tách ra thành hai thành phần (wtf)  :
:
- Một phần được gọi là
Alerting Ruleschạy cùng ngay trong service Prometheus. - Một phần còn lại gọi là
Alert Managerđược tách ra thành một service độc lập.
Alerting Rules sẽ gửi alerts tới AlertManager. AlertManager sẽ chịu trách nhiệm quản lý chúng, tổng hợp các alerts và thực hiện gửi chúng tới nơi cần đến. Sẽ thật là "TÙ" nếu một công cụ monitoring mà lại không có chức năng gửi thông báo.
Tới đây, liệu bạn có nghĩ như mình rằng nguyên nhân tại sao mà Prometheus lại tách biệt Alerting ra thêm một thành phần riêng biệt là Alert Maanger không?
Một trong số lý do mình có thể kể đến đó là các metrics thì có thể thay đổi lên xuống liên tục và thất thường, do đó sẽ cần có một thành phần để tránh gửi các thông báo trùng lặp. Hay một trường hợp khác là prometheus cần gửi alert về việc chúng ta đang có một service web bị down, lúc này prometheus cũng cần chặn các alerts ngay sau khi đã có một alert được gửi đi thành công. Nếu không thì email hay stack của chúng ta bị ngập tràn trong hàng nghìn thông báo mất. 

Ngoài ra, Alert Manager cũng có thể gom nhóm các alert lại rồi mới gửi đi hoặc là kích hoạt chế độ im lặng trong một khoảng thời gian nào đó nữa.
Tổng kết
Trên đây là cái nhìn tổng quan về Prometheus mà muốn chia sẻ tới anh em trên công đồng Viblo. Bài viết có sử dụng một số hình ảnh cũng của DevConnected. Link các tài liệu tham khảo + source code được sử dụng trong bài viết này ở phía dưới.
Nếu có bất kỳ câu hỏi thắc mắc nào, vui lòng comment vào phía cuối bài viết để chúng ta cùng thảo luận nhé! Cảm ơn 500ae Viblo đã đón đọc bài viết này. Đừng quên nhấn follow mình để nhận thông báo ngay khi các bài viết tiếp theo về Prometheus nhé! Bye bye! 
Tài liệu tham khảo
- Prometheus monitoring: The Definitive Guide in 2019 + Hình minh họa
- Getting Started - Prometheus Documentation
- Installation - Prometheus Documentation
- Alerting Configuration - Prometheus Documentation
- Writing Exporter - Prometheus Documentation
- Source code - kimyvgy-labs/hello-grafana
 Nếu thấy nội dung này bổ ích, hãy mời tôi một tách cà phê nha! https://kimyvgy.webee.asia
Nếu thấy nội dung này bổ ích, hãy mời tôi một tách cà phê nha! https://kimyvgy.webee.asia
All rights reserved
