
[GAN series - 4] Những khó khăn khi train GAN và những kĩ thuật cải tiến train.
Bài đăng này đã không được cập nhật trong 6 năm
Những vấn đề khi train GAN
Hồi mới học GAN, mình đã mất cả tuần để tự code 1 ứng dụng đơn giản: sinh chữ viết tay dựa trên Mnist dataset. Code chỉ mất 2 giờ, nhưng quá trình train GAN lại mất gần 1 tuần, thử đi thử lại cả trăm lần với đủ các loại model, layer, tham số. Cuối cùng vào một buổi chiều, đột nhiên quá trình train thành công khi mình thay đổi learning rate từ 0.00015 thành 0.0001.
Dù đã thành công nhưng trong đầu mình lại đặt ra 1 tỷ câu hỏi rằng: tại sao nó lại chạy được, tại sao nó thành công, thế mỗi lần train GAN lại phải thử cả trăm lần vậy sao  . Và sau một thời gian đọc và nghiên cứu sâu hơn về GAN, mình đã rút ra được nhiều kinh nghiệm và kĩ thuật cải thiện. Trong bài viết này, mình sẽ nói về các kĩ thuật cho DCGAN.
. Và sau một thời gian đọc và nghiên cứu sâu hơn về GAN, mình đã rút ra được nhiều kinh nghiệm và kĩ thuật cải thiện. Trong bài viết này, mình sẽ nói về các kĩ thuật cho DCGAN.
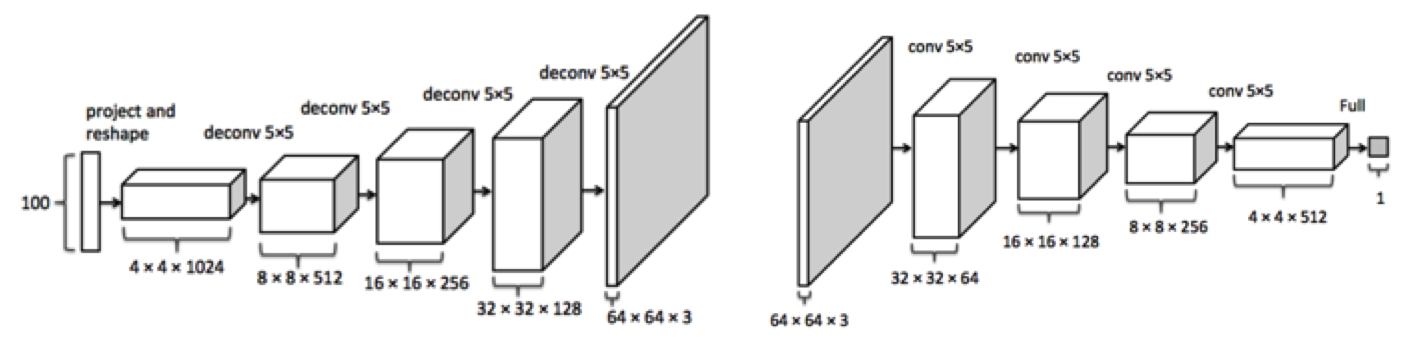
Để dễ hình dung, hãy nhìn lại 1 DCGAN trên hình với 1 generator và 1 discriminator. Trước hết, bạn phải hiểu rằng train GAN không giống với train các loại model bình thường. Bạn phải train 2 model song song với nhau với hàm mục tiêu trái nhau. GAN giống như 1 trò chơi cảnh sát tội phạm, trong khi cảnh sát cố gắng phân biệt tiền giả thì tội phạm lại cố đánh lừa cảnh sát. Nếu một trong hai người thành công 100% thì người còn lại sẽ coi như đồ bỏ. Bạn không thể tìm ra một hàm mục tiêu chung cho cả hai model nên cũng không thể xác định chính xác được điểm dừng trong quá trình train dựa vào accuracy.
Qua thực nghiệm, người ta nhận thấy cả generator và discriminator đều hội tụ khi accuracy của cả 2 đều loanh quanh ở mức 0.5. Tại điểm đó, generator đã sinh ra ảnh fake mà khiến discriminator phân biệt lúc đúng lúc sai (tức đã đánh lừa được discriminator).
Non-convergence
Một trong hai model (hoặc cả 2) không hội tụ. Nó tương tự như việc bạn train một classify model mà mãi không ra gì. Khi đó thì chắc chắn quá trình train GAN là thất bại. Lỗi train model ra kết quả không tốt thì không mấy xa lạ với người làm deep learning:
- Dữ liệu của bạn không chuẩn, unbalance.
- Model quá cùi, quá cơ bản, quá phức tạp, không phù hợp
- Dữ liệu quá thiếu, bị nhiễu
- Overfit, underfit
- Hoặc do bạn quá đen
 )
)
Mode collapse
Có một hiện tượng rất phổ biến: fake_images sinh ra giống hệt nhau, ít phụ thuộc vào input đầu vào. Điều này xảy ra khi mà generator tìm ra một điểm dữ liệu đặc biệt mà tại điểm đó discriminator không thể phân biệt được.
Giống như việc tên tội phạm vẽ lăng nhăng một tờ gì đó giống tiền, may mắn thay tờ tiền đó rơi vào "điểm mù" của người cảnh sát, người đó không thể phân biệt được. Sau khi khám phá ra điều đó, tên tội phạm sẽ vẽ đi vẽ lại tờ tiền đó mà chẳng thèm cải thiện gì. Dưới dây là một ví dụ cực kì phổ biến khi bạn mới bắt đầu train với bộ mnist.

Diminished gradient
Hiện tượng này xảy ra khi discriminator hội tụ quá nhanh (hiện tượng này xảy ra cực kì phổ biến do tại những step đầu tiên, ảnh thật và ảnh fake khác nhau rất nhiều). Ngay những epoch đầu tiên nó đã nhận biết được thật giả. Điều này gây ra hiện tượng gradient vanishes cho generator khiến cho generator học rất chậm, hoặc chẳng học được gì --> quá trình train thất bại. Nó tương tự như một thằng tội phạm mới học cách làm tiền giả đối mặt với một ông cảnh sát lão làng 31 năm kinh nghiệm ) .
Điều tương tự cũng xảy ra khi discriminator học quá chậm, hoặc generator học quá nhanh.
Nhạy cảm với hyper parameters.
Do GAN là kết hợp giữa hai model nên việc train song song 2 model này rất khó và nhạy cảm bởi các tham số như learning, các hyper parameter trong optimizer ...
Kết luận
Như vậy, mấu chốt để giải quyết vấn đề là phải làm sao cho cả generator và discriminator đều học từ từ, cùng nhau, khả năng ngang nhau, tránh hiện tượng thằng này vượt mặt thằng kia. (đôi bạn cùng tiến :3 )*.
Phương pháp cải thiện
Note: Nhiều phương pháp được người ta rút ra từ thực nghiệm nên tác giả giải thích chỉ mang tính tương đối và không phải lúc nào cũng đúng
Chiến lược train
Khi train, nên trên theo minibatch trong từng step. Trong 1 batch, không nên chứa lẫn lộn real_image, fake_image mà lần lượt real_image trước, fake_image sau. (có thể đọc lại code của mình trong 2 bài trước để thấy rõ điều này).
Chọn model
Đôi khi do model của bạn quá đơn giản, quá phức tạp nên khả năng của model không được cải thiện. Thường người ta xây dựng DCGAN - tức generator và discriminator là 2 Deep Convolution có kiến trúc điển hình. Nếu train mà mãi không thành công, bạn có thể nghĩ tới việc thêm, bớt các layer, các nhánh. Ví dụ với bộ mnist đơn giản, chỉ cần 3, 4 layer Conv trong khi với bộ Face thì cần nhiều layer hơn, cần kết hợp các loại batchnorm, dropout, các skip connection ...
Tuy không có lời giải thích thực sự rõ ràng, nhưng qua thực nghiệm người ta thấy rằng:
- Không nên dùng dropout trong generator, ngược lại với discriminator.
- Nên dùng ConvTranspose thay vì kết hợp kiểu: Upsampling+Conv, Interpolation+Conv ...
- Nên dùng hàm tanh thay cho sigmoid cho output của generator.
- Nên dùng hàm Leaky Relu thay cho Relu tại các lớp Conv.
Chọn hyper parameter, optimizer
Qua thực nghiệm, người ta nhận ra trong các thuật toán optimizer, Adam thường cho kết quả tốt nhất. Ta nên chọn learning_rate có giá trị nhỏ hơn bình thường, nên chọn learning_rate . Với Adam, nên đổi tham số beta_1 thay vì để mặc đinh (0.9).
Mẹo để chọn learning_rate là dựa vào accuracy của discriminator và generator.
- B1: Chọn learning_rate (nên )
- B2: Quan sát accuracy của cả discriminator và generator, nếu 1 trong 2 accuracy này tăng quá nhanh model học quá nhanh Diminished gradient cần giảm learning_rate xuống
- B3: Lặp đi lặp lại bước 2 cho tới khi thấy accuracy của 2 model thay đổi từ từ và đều nhau.
Thêm nhiễu vào dữ liệu.
Giả sử ta có binary label cho 4 ảnh như sau: label = Để tránh việc discriminator học quá nhanh, ta có thể thêm nhiễu vào dữ liệu theo 2 cách:
Cách 1: Đảo lại giá trị label
Với tỷ lệ nhất định, (thường là 10%), người ta đảo lại giá trị nhãn cho 1 ảnh từ và . Cách này chính là thêm nhiễu sai vào dữ liệu. Như vậy, dù discriminator học nhanh và giỏi nhất cũng chỉ có accuracy tối đa bằng 90%.
Cách 2: Đổi giá trị nhãn thành xấp xỉ.
Thay vì dùng 2 giá trị chính xác là 0 và 1, ta nên thay đổi thành các giá trị xấp xỉ hai giá trị này. VD với label trên. ta có thể đổi lại thành label = . Thường thì khi code, giá trị nhiễu được thêm vào
PatchGAN
 PatchGAN là 1 ý tưởng cải tiến mạng discriminator của GAN tại phần output. Để dễ hình dung, hãy nhìn vào hình trên đây. Thay vì thiết kế mạng có output là 1 giá trị 0/1 hoặc [0,1]/[1,0], output là 1 matrix 14 * 14. Tương tự, label cho từng ảnh cũng là 1 matrix 14 * 14 có giá trị các phần tử giống hệt nhau.
PatchGAN là 1 ý tưởng cải tiến mạng discriminator của GAN tại phần output. Để dễ hình dung, hãy nhìn vào hình trên đây. Thay vì thiết kế mạng có output là 1 giá trị 0/1 hoặc [0,1]/[1,0], output là 1 matrix 14 * 14. Tương tự, label cho từng ảnh cũng là 1 matrix 14 * 14 có giá trị các phần tử giống hệt nhau.
Việc thay đổi output mang ý nghĩa chia ảnh thành 14 * 14 phần bằng nhau (và overlap nhau). Như vậy mỗi giá trị trong output matrix 14 * 14 đaị diện cho 1 vùng local. Việc làm này giúp cho GAN dễ dàng tối ưu tới từng chi tiết.
Kết
Tuy còn khá nhiều phương pháp khác nhưng thường được dùng cho các model GAN phức tạp hơn và khó hơn, mình không tiện nói trong bài này. Trên đây là một vài cách đơn giản để cải thiện, hi vọng nó sẽ giúp ích khi mọi người bắt đầu tìm hiểu về GAN. Cảm ơn mọi người đã đọc .
Note: Các bài viết được viết trên trang https://viblo.asia , nếu trích dẫn hãy ghi nguồn trang cùng tên tác giả đầy đủ.
facebook: trungthanhnguyen0502
All rights reserved
