
Feature Engineering (Phần 5): Phương pháp nâng cao để xử lý dữ liệu dạng văn bản, phi cấu trúc (2/2)
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người phần đầu của bài viết Phương pháp nâng cao để xử lý dữ liệu dạng văn bản (Text Data). Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu phần còn lại của các phương pháp nâng cao hơn để xử lý dữ liệu văn bản, phi cấu trúc.
Xây dựng mô hình Skip-gram
Skip-gram là mô hình được xây dựng với mục đích ngược lại với mô hình CBOW. Nó cố gắng dự đoán các ngữ cảnh (surrounding words) bằng từ ngữ trung tâm (center word). Chúng ta hãy cùng xem xét một câu ví dụ đơn giản sau đây: "the quick brown fox jumps over the lazy dog". Với mô hình CBOW chúng ta sẽ có các cặp (context_window, target_word) và nếu sử dụng context_window có size = 2 ta sẽ có các cặp: ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy)... Bây giờ hãy xem xét mô hình Skip-gram, mô hình sẽ cố gắng dự đoán ngữ cảnh bằng từ ngữ trung tâm tương ứng của nó. Và với ví dụ trên mô hình sẽ dự đoán ngữ cảnh [quick, fox] bằng từ trung tâm "brown" hoặc [the,brown] bằng từ trung tâm "quick"...
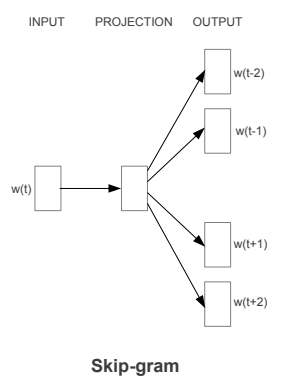
Giống như khi thảo luận về mô hình CBOW, các bạn cần mô hình hóa kiến trúc Skip-gram này như một mô hình phân lớp sử dụng target_word làm input và output là các context_words cần dự đoán. Điều này sẽ phức tạp hợp vì chúng ta có nhiều hơn một từ trong ngữ cảnh. Ta có thể giải quyết vấn đề này bằng cách đơn giản là chia nhỏ mỗi cặp (target, context_words) thành các cặp (target, context) trong đó context chỉ bao gồm một từ duy nhất. Như vậy dữ liệu đầu vào sẽ được biến đổi thành các cặp như sau: (brown, quick), (brown, fox), (quick, the), (quick, brown)... Nhưng làm thế nào ta có thể huấn luyện mô hình cái gì là ngữ cảnh, cái gì là không?
Để giải quyết vấn đề ở trên, chúng ta sẽ tạo ra dữ liệu là các cặp (X, Y) với X là input và Y là nhãn tương ứng. Như vậy, kết hợp với cặp (target, context) ở trên ta có dữ liệu sẽ có dạng như sau [(target, context), 1] nếu target và context là một cặp xuất hiện gần nhau và có liên quan đến nhau về mặt ngữ cảnh. Tương tự [(target, context), 0] với context là một tự được chọn random từ bộ từ vựng cho trước và không có liên quan gì về mặt ngữ cảnh với target. Chúng ta cần các cặp không liên quan này để mô hình có học được các cặp từ nào có liên quan đến ngữ cảnh và cặp nào không để tạo ra các vectơ embedding tương tự nhau cho các cặp từ có liên quan về mặt ngữ nghĩa.
Xây dựng mô hình Skip-gram
Bây giờ, chúng ta sẽ thử nghiệm xây dựng mô hình này từ đầu để có thể có được cái nhìn tốt hơn về cách mọi thứ hoạt động và có thể so sánh nó với việc triển khai mô hình CBOW. Chúng ta sẽ tận dụng bộ dữ liệu Bible bằng cách sử dụng biến norm_bible có được trong phần trước để huấn luyện mô hình. Việc triển khai mô hình sẽ tập trung vào năm phần chính:
-
Xây dựng vốn từ vựng
-
Xây dựng skip-gram [(target, context), relevancy] generator
-
Xây dựng kiến trúc mô hình skip-gram
-
Huấn luyện mô hình
-
Thu được word embeddings của các từ
Xây dựng bộ từ vựng
Để bắt đầu, chúng ta sẽ tuân theo quy trình chuẩn để xây dựng vốn từ vựng, nơi các bạn sẽ trích xuất từng từ duy nhất từ bộ từ vựng có sẵn và gán id cho chúng, tương tự như những gì đã xử lý với mô hình CBOW
from keras.preprocessing import text
tokenizer = text.Tokenizer()
tokenizer.fit_on_texts(norm_bible)
word2id = tokenizer.word_index
id2word = {v:k for k, v in word2id.items()}
vocab_size = len(word2id) + 1
embed_size = 100
wids = [[word2id[w] for w in text.text_to_word_sequence(doc)] for doc in norm_bible]
print('Vocabulary Size:', vocab_size)
print('Vocabulary Sample:', list(word2id.items())[:10])
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
Kết quả thu được như mong muốn, mỗi từ duy nhất trong tập văn bản là một phần của tập từ vựng và được đánh id duy nhất.
Xây dựng skip-gram [(target, context), relevancy] generator
Tiếp theo là quá trình tạo ra các cặp từ với mức độ liên quan của chúng như những gì đã thảo luận ở trên. Thật may mắn, keras cung cấp module skipgrams rất tiện lợi để sử dụng và trong bài viết này chúng ta sẽ không tạo ra mọi thứ một cách thủ công như những gì đã làm với CBOW.
Note: Hàm
skipgrams(...)được cung cấp tạikeras.preprocessing.sequenceHàm này biến đổi một chuỗi các chỉ mục từ (list các số nguyên) thành các bộ từ có format:
- (word, word in the same window), với label 1 (positive samples).
- (word, random word from the vocabulary), với label 0 (negative samples).
from keras.preprocessing.sequence import skipgrams
# generate skip-grams
skip_grams = [skipgrams(wid, vocabulary_size=vocab_size, window_size=10) for wid in wids]
# view sample skip-grams
pairs, labels = skip_grams[0][0], skip_grams[0][1]
for i in range(10):
print("({:s} ({:d}), {:s} ({:d})) -> {:d}".format(
id2word[pairs[i][0]], pairs[i][0],
id2word[pairs[i][1]], pairs[i][1],
labels[i]))
(james (1154), king (13)) -> 1
(king (13), james (1154)) -> 1
(james (1154), perform (1249)) -> 0
(bible (5766), dismissed (6274)) -> 0
(king (13), alter (5275)) -> 0
(james (1154), bible (5766)) -> 1
(king (13), bible (5766)) -> 1
(bible (5766), king (13)) -> 1
(king (13), compassion (1279)) -> 0
(james (1154), foreskins (4844)) -> 0
Như vậy bạn có thể thấy chúng ta đã tạo ra dữ liệu để đưa vào huấn luyện mô hình skip-gram. Bạn cũng có thể thấy rất rõ những từ liên quan và không liên quan dựa trên nhãn của chúng (0 hoặc 1).
Xây dựng kiến trúc mô hình Skip-gram
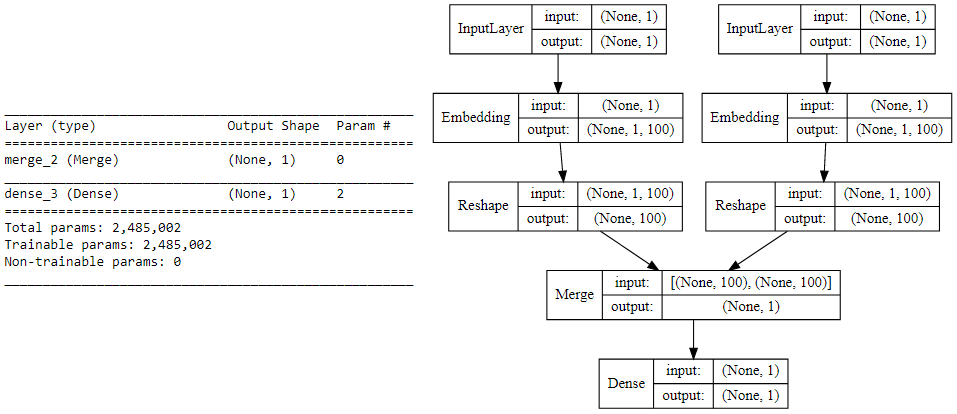
Chúng ta tiếp dụng sử dụng keras để tạo ra kiến trúc deep learning cho mô hình skip-gram với tập đầu vào thu được từ bước trên. Mỗi mẫu đầu vào sẽ được đưa qua một embedding layer (khởi tạo với weights ngẫu nhiên). Sau khi có được các word embeddings cho target_word và context_word, chúng ta tiếp tục đưa chúng qua một merge layer, nơi sẽ tính toán tích vô hướng của hai vectơ. Sau cùng cho tích vô hướng đó qua dense sigmoid layer để dự đoán giá trị output (Y') là 0 hoặc 1 tùy thuộc vào việc cặp từ input có liên quan đến ngữ nghĩa hay không. Ta sẽ so sánh giá trị (Y') và (Y) để tính mean_squared_error và thực hiện update lại các trọng số. Source code phần này sẽ như sau:
from keras.layers import Merge
from keras.layers.core import Dense, Reshape
from keras.layers.embeddings import Embedding
from keras.models import Sequential
# build skip-gram architecture
word_model = Sequential()
word_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
word_model.add(Reshape((embed_size, )))
context_model = Sequential()
context_model.add(Embedding(vocab_size, embed_size,
embeddings_initializer="glorot_uniform",
input_length=1))
context_model.add(Reshape((embed_size,)))
model = Sequential()
model.add(Merge([word_model, context_model], mode="dot"))
model.add(Dense(1, kernel_initializer="glorot_uniform", activation="sigmoid"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
# view model summary
print(model.summary())
# visualize model structure
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model, show_shapes=True, show_layer_names=False,
rankdir='TB').create(prog='dot', format='svg'))
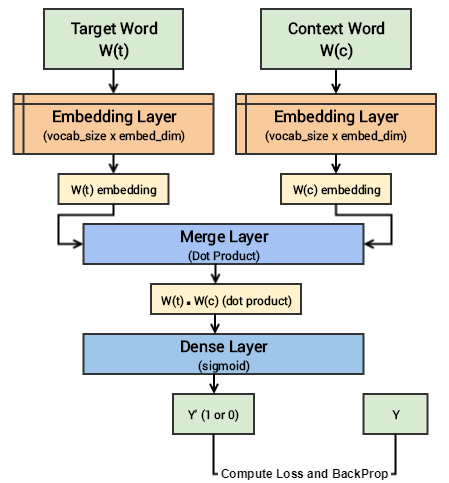
Có thể thấy kiến trúc của mô hình trên khá đơn giản. Tuy nhiên, chúng ta sẽ cố gắng tóm tắt các khái niệm cốt lõi của mô hình này bằng các thuật ngữ dễ hiểu nhất. Chúng ta có mỗi mẫu dữ liệu huấn luyện bao gồm một target_word và một context_word. Nếu hai từ này có liên quan đến nhau về mặt ngữ cảnh sẽ được gán nhãn Y = 1 ngược lại sẽ được gán Y = 0. Sau đó cho mỗi từ đó qua một embedding layer của riêng chúng ta tiếp tục thu được một one - hot - vectơ (size = 1 x embed_size). Tiếp theo là tính tích vô hướng của hai vectơ vừa có được bằng merge layer và cuối cùng đưa giá trị tích vô hướng đó qua dense sigmoid layer để có được gía trị dự đoán là 0 hoặc 1. Các bạn hay quan sát hình dưới đây để hiểu rõ hơn.
Huấn luyện mô hình
Huấn luyện mô hình với toàn bộ tập dữ liệu sẽ tốn một chút thời gian nhưng sẽ nhanh hơn việc huấn luyện CBOW. Trong bài viết này chúng ta sẽ dùng 5 epoch để huấn luyện mô hình. Các bạn có thể tăng số lượng epoch nếu thấy cần thiết.
for epoch in range(1, 6):
loss = 0
for i, elem in enumerate(skip_grams):
pair_first_elem = np.array(list(zip(*elem[0]))[0], dtype='int32')
pair_second_elem = np.array(list(zip(*elem[0]))[1], dtype='int32')
labels = np.array(elem[1], dtype='int32')
X = [pair_first_elem, pair_second_elem]
Y = labels
if i % 10000 == 0:
print('Processed {} (skip_first, skip_second, relevance) pairs'.format(i))
loss += model.train_on_batch(X,Y)
print('Epoch:', epoch, 'Loss:', loss)
Epoch: 1 Loss: 4529.63803683
Epoch: 2 Loss: 3750.71884749
Epoch: 3 Loss: 3752.47489296
Epoch: 4 Loss: 3793.9177565
Epoch: 5 Loss: 3716.07605051
Thu được word embeddings của các từ
Để lấy ra được embedding của các từ, các bạn có thể làm theo đoạn source code dưới đây.
merge_layer = model.layers[0]
word_model = merge_layer.layers[0]
word_embed_layer = word_model.layers[0]
weights = word_embed_layer.get_weights()[0][1:]
print(weights.shape)
pd.DataFrame(weights, index=id2word.values()).head()
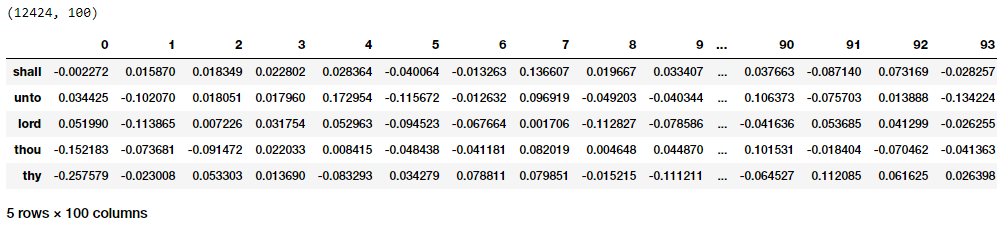
Các bạn có thể thấy một cách khá rõ ràng, với mỗi từ ta sẽ có một vectơ embedding kích thước 1 * 100 đúng với mô tả output trước đó và tương tự với kết quả thu được từ mô hình CBOW. Bây giờ hãy áp dụng khoảng cách euclidean để tính toán khoảng cách theo cặp giữa các vectơ. Sau đó các bạn có thể tìm kiếm được n hàng xóm gần nhất với mỗi từ tương tự những gì đã làm với CBOW
from sklearn.metrics.pairwise import euclidean_distances
distance_matrix = euclidean_distances(weights)
print(distance_matrix.shape)
similar_words = {search_term: [id2word[idx] for idx in distance_matrix[word2id[search_term]-1].argsort()[1:6]+1]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words
(12424, 12424)
{'egypt': ['pharaoh', 'mighty', 'houses', 'kept', 'possess'],
'famine': ['rivers', 'foot', 'pestilence', 'wash', 'sabbaths'],
'god': ['evil', 'iniquity', 'none', 'mighty', 'mercy'],
'gospel': ['grace', 'shame', 'believed', 'verily', 'everlasting'],
'jesus': ['christ', 'faith', 'disciples', 'dead', 'say'],
'john': ['ghost', 'knew', 'peter', 'alone', 'master'],
'moses': ['commanded', 'offerings', 'kept', 'presence', 'lamb'],
'noah': ['flood', 'shem', 'peleg', 'abram', 'chose']}
Các bạn có thể thấy rõ ràng từ kết quả rằng rất nhiều context_word cho mỗi target_word có ý nghĩa và kết quả thu được là tốt hơn so với mô hình CBOW. Tiếp theo, chúng ta sẽ trực quan hóa các embedding words này bằng t-SNE (t-distributed stochastic neighbor embedding)
from sklearn.manifold import TSNE
words = sum([[k] + v for k, v in similar_words.items()], [])
words_ids = [word2id[w] for w in words]
word_vectors = np.array([weights[idx] for idx in words_ids])
print('Total words:', len(words), '\tWord Embedding shapes:', word_vectors.shape)
tsne = TSNE(n_components=2, random_state=0, n_iter=10000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_vectors)
labels = words
plt.figure(figsize=(14, 8))
plt.scatter(T[:, 0], T[:, 1], c='steelblue', edgecolors='k')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
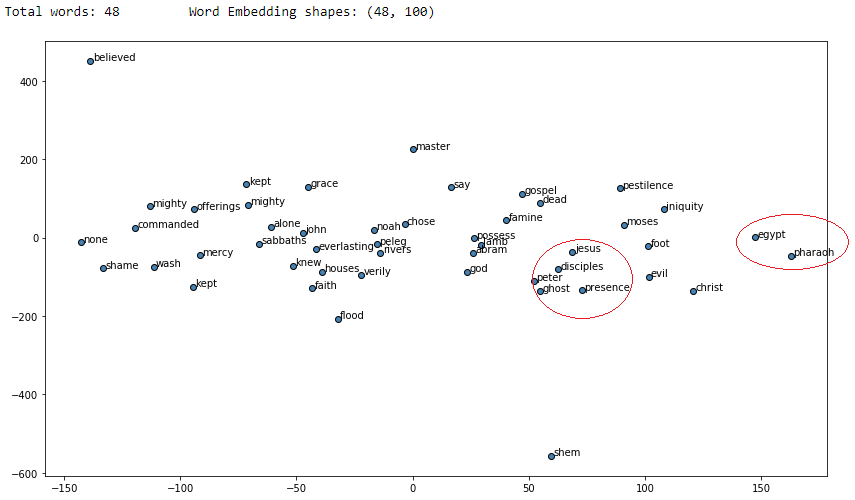
Các vòng tròn đỏ cho thấy các từ khác nhau nhưng có sự tương tự về mặt ngữ nghĩa được biểu diễn rất gần nhau trong không gian vectơ
Robust Word2Vec với Gensim
Mặc dù việc xây dựng mô hình như chúng ta đã làm ở trên có mang lại hiệu quả tuy nhiên nó sẽ không đủ tốt để áp dụng cho các tập dữ liệu lớn. Và gensim framework được tạo bởi Radim Řehůřek là một framework rất mạnh mẽ cho việc xây dựng mô hình Word2Vec. Chúng ta sẽ tiếp tục tận dụng bộ dữ liệu Bible để xem xét một ví dụ với gensim. Trong ví dụ này chúng ta sẽ tokenize bộ dữ liệu đã được chuẩn hóa và tập trung vào bốn tham số sau trong mô hình word2vec.
- size: Số chiều của word embedding
- window: kích thước của context window
- min_count: Số lượng từ tối thiểu
- sample: ngưỡng để xác định tần số giới hạn là random
Sau khi xây dựng mô hình chúng ta sẽ sử dụng center_word để kiểm tra các từ có tương đồng về ngữ nghĩa thu được từ mô hình
from gensim.models import word2vec
# tokenize sentences in corpus
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document) for document in norm_bible]
# Set values for various parameters
feature_size = 100 # Word vector dimensionality
window_context = 30 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
w2v_model = word2vec.Word2Vec(tokenized_corpus, size=feature_size,
window=window_context, min_count=min_word_count,
sample=sample, iter=50)
# view similar words based on gensim's model
similar_words = {search_term: [item[0] for item in w2v_model.wv.most_similar([search_term], topn=5)]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words

Các từ gần nghĩa thu được chắc chắn có liên quan nhiều hơn đến các center_word. Bạn có thấy điều gì thú vị không?

Bây giờ các bạn hãy tiếp tục sử dụng t-SNE để xây dựng mô hình 2-D biểu diễn các vectơ embedding để có được cái nhìn trực quan hơn
from sklearn.manifold import TSNE
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = w2v_model.wv[words]
tsne = TSNE(n_components=2, random_state=0, n_iter=10000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(14, 8))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')

Các vòng tròn màu đỏ ở hình trên cho thấy một số nhóm gần nghĩa khá thú vị. Chúng ta có thể thấy rõ rằng ví dụ đưa ra ở trên về NOAH và tên các con trai ông đứng rất gần nhau thành một cụm và có liên quan đến nhau về mặt ngữ cảnh trong thực tế.
Áp dụng đặc trưng từ Word2Vec vào các bài toán Machine Learning
Nếu bạn còn nhớ trong phần 4 của series này (Phương pháp xử lý truyền thống với dữ liệu dạng văn bản) bạn có thể thấy chúng ta có thể sử dụng các một số đặc trưng thu được từ quá trình xử lý văn bản trong một số bài toán học máy phân cụm (clustering). Bây giờ các bạn hãy sử dụng những gì thu được ở trên để thực hiện bài toán tương tự như vậy. Đầu tiên hãy xây dựng một mô hình Word2Vec và mô hình hóa chúng.
# build word2vec model
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document) for document in norm_corpus]
# Set values for various parameters
feature_size = 10 # Word vector dimensionality
window_context = 10 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
w2v_model = word2vec.Word2Vec(tokenized_corpus, size=feature_size,
window=window_context, min_count = min_word_count,
sample=sample, iter=100)
# visualize embeddings
from sklearn.manifold import TSNE
words = w2v_model.wv.index2word
wvs = w2v_model.wv[words]
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
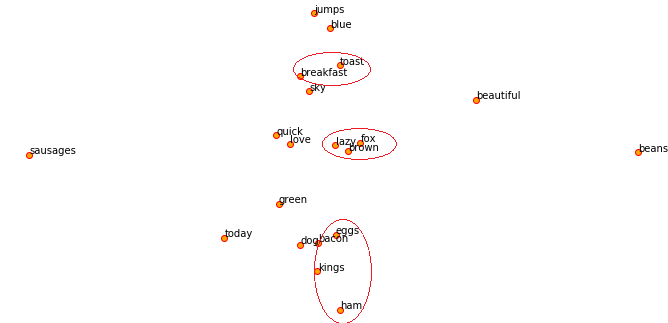
Hãy lưu ý rằng tập dữ liệu đang sử dụng là rất nhỏ để có được các word embeddings thật sự có ý nghĩa, các bạn có thể cải thiện vấn đề này nếu có nhiều dữ liệu hơn. Vậy word embeddings trong kịch bản này là gì? Nó thường là một vectơ cho mỗi từ và có thể ví dụ với từ "sky" như dưới đây
w2v_model.wv['sky']
Output
------
array([ 0.04576328, 0.02328374, -0.04483001, 0.0086611 , 0.05173225, 0.00953358, -0.04087641, -0.00427487, -0.0456274 , 0.02155695], dtype=float32)
Tiếp theo để phân cụm 8 câu từ tập dữ liệu toy chúng ta cần có được level embedding của văn bản từ các từ xuất hiện trong văn bản đó. Một trong những cách để thực hiện điều này là tính trung bình word embedding của tất cả các từ trong văn bản đó. Đây là một phương pháp rất hữu ích mà các bạn có thể áp dụng để giải quyết các vấn đề tương tự. Hãy cùng bắt đầu với đoạn code sau:
def average_word_vectors(words, model, vocabulary, num_features):
feature_vector = np.zeros((num_features,),dtype="float64")
nwords = 0.
for word in words:
if word in vocabulary:
nwords = nwords + 1.
feature_vector = np.add(feature_vector, model[word])
if nwords:
feature_vector = np.divide(feature_vector, nwords)
return feature_vector
def averaged_word_vectorizer(corpus, model, num_features):
vocabulary = set(model.wv.index2word)
features = [average_word_vectors(tokenized_sentence, model, vocabulary, num_features)
for tokenized_sentence in corpus]
return np.array(features)
# get document level embeddings
w2v_feature_array = averaged_word_vectorizer(corpus=tokenized_corpus, model=w2v_model,
num_features=feature_size)
pd.DataFrame(w2v_feature_array)
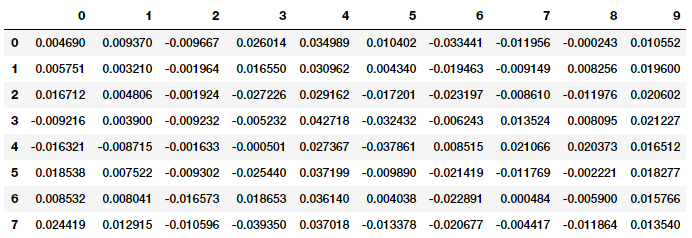
Sau khi đã có được các đặc trưng như hình trên sẽ đến việc phân cụm từng văn bản, ở ví dụ này chúng ta sẽ sử dụng thuật toán Affinity Propagation, đây là một thuật toán dựa trên khái niệm về "message passing" giữa các điểm dữ liệu và không cần quy định số cụm được phân chia như các phương pháp thông thường khác.
from sklearn.cluster import AffinityPropagation
ap = AffinityPropagation()
ap.fit(w2v_feature_array)
cluster_labels = ap.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)

Và các bạn có thể thấy rằng thuật toán của chúng ta đã phân từng văn bản vào các cụm tương ứng bằng cách sử dụng các đặc trưng thu được từ Word2Vec. Khá thú vị! Các bạn cũng có thể mô hình hóa vị trí mỗi cụm trong không gian 2-D bằng phương pháp PCA (Principal Component Analysis). Mỗi văn bản trong cùng một cụm sẽ được biểu diễn bằng màu giống nhau.
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=0)
pcs = pca.fit_transform(w2v_feature_array)
labels = ap.labels_
categories = list(corpus_df['Category'])
plt.figure(figsize=(8, 6))
for i in range(len(labels)):
label = labels[i]
color = 'orange' if label == 0 else 'blue' if label == 1 else 'green'
annotation_label = categories[i]
x, y = pcs[i]
plt.scatter(x, y, c=color, edgecolors='k')
plt.annotate(annotation_label, xy=(x+1e-4, y+1e-3), xytext=(0, 0), textcoords='offset points')
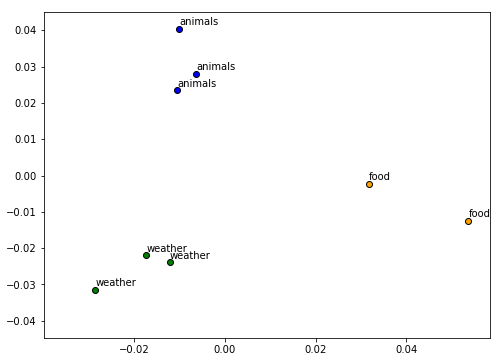
Bạn có thể dễ dàng nhận ra các văn bản trong cùng một cụm sẽ nằm gần nhau và cụm này sẽ cách xa cụm khác.
Mô hình GloVe
Mô hình GloVe là viết tắt của từ Global Vectơ, một mô hình học không giám sát có thể sử dụng để thu được dense vectơ cho các từ tương tự như Word2Vec. Tuy nhiên, mô hình này sử dụng kỹ thuật khác, việc huấn luyện được thực hiện trên một co-occurrence matrix và cho chúng ta một không gian vectơ với các sub-structures thể hiện ngữ cảnh. Thuật toán này được để xuất tại Stanford bởi Pennington et al. Các bạn hãy tham khảo bài báo gốc "GloVe: Global Vectors for Word Representation" của mô hình này để hiểu rõ nhất về tư tưởng và cách mà nó hoạt động.
Tư tưởng cơ bản của mô hình GloVe là đầu tiên ta cần xây dựng một ma trận co-occurence rất lớn bao gồm các cặp (word, context) sao cho mỗi phần tử của ma trận sẽ biểu diễn tần suất xuất hiện của một từ với ngữ cảnh (ngữ cảnh có thể là một từ hoặc chuỗi từ).
Áp dụng đặc trưng từ GloVe vào các bài toán Machine Learning
Bây giờ chúng ta hãy cùng sử dụng các đặc trưng thu được từ mô hình GloVe để áp dụng vào bài toán phân cụm văn bản. spacy là một framework rất phổ biến trong việc sử dụng GloVe embedding với các ngôn ngữ khác nhau. Các bạn cũng có thể sử dụng pre-trained thông qua gensim hoặc spacy. Ở đây chúng ta sẽ cài đặt spacy và sử dụng mô hình en_vectors_lg bao gồm word vectơ 300 chiều được train sẵn với GloVe
# Use the following command to install spaCy
> pip install -U spacy
OR
> conda install -c conda-forge spacy
# Download the following language model and store it in disk
https://github.com/explosion/spacy-models/releases/tag/en_vectors_web_lg-2.0.0
# Link the same to spacy
> python -m spacy link ./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg en_vecs
Linking successful
./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg --> ./Anaconda3/lib/site-packages/spacy/data/en_vecs
You can now load the model via spacy.load('en_vecs')
Tiếp theo hãy sử dụng spacy để load language model.
import spacy
nlp = spacy.load('en_vecs')
total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)
Total word vectors: 1070971
Điều này xác nhận rằng thư viện của chúng ta đã hoạt động bình thường. Bây giờ hãy sử dụng đoạn code dưới đây để lấy ra các GloVe embeddings cho mỗi từ trong tập dữ liệu thử nghiệm.
unique_words = list(set([word for sublist in [doc.split() for doc in norm_corpus] for word in sublist]))
word_glove_vectors = np.array([nlp(word).vector for word in unique_words])
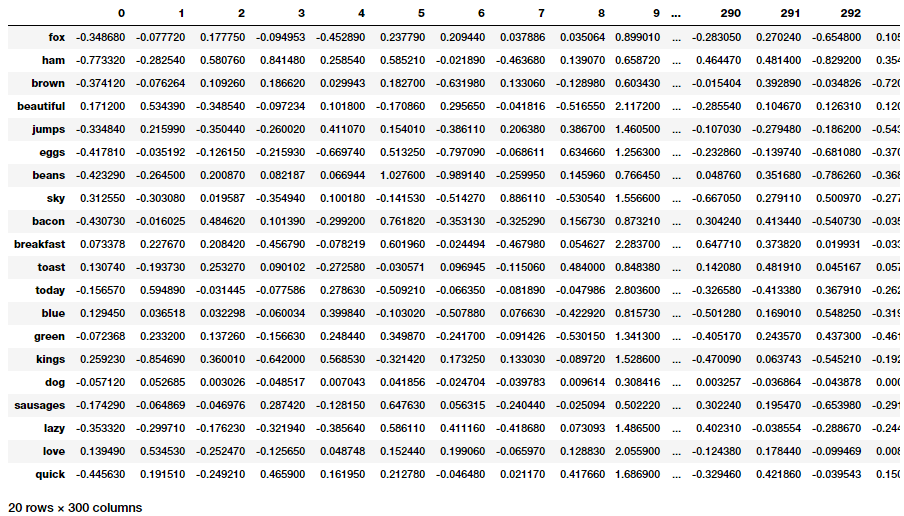
pd.DataFrame(word_glove_vectors, index=unique_words)
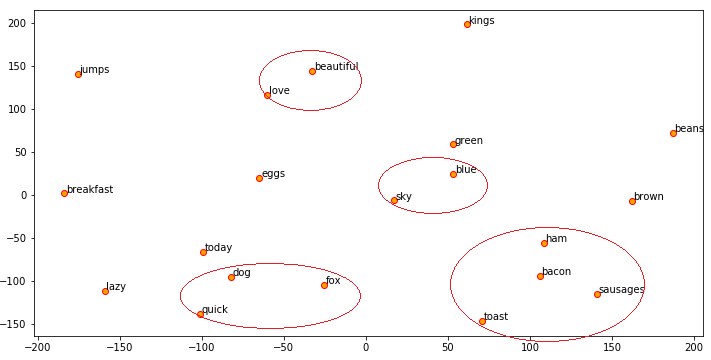
Và tiếp tục sử dụng t-SNE để mô hình hóa các embeddings gần nhau về mặt ngữ cảnh như những gì đã làm trước đó với Word2Vec.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_glove_vectors)
labels = unique_words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
Một điểm đặc biệt của spacy là nó sẽ cung cấp tự động cho bạn embeddings trung bình cho các từ trong một đoạn văn bản mà không cần viết các hàm xử lý như những gì đã làm với Word2Vec ở trên. Chúng ta sẽ tận dụng điều này để trích xuất đặc trưng từ các đoạn văn bản trong tập dữ liệu và sử dụng k-means để phân cụm các văn bản đó.
doc_glove_vectors = np.array([nlp(str(doc)).vector for doc in norm_corpus])
km = KMeans(n_clusters=3, random_state=0)
km.fit_transform(doc_glove_vectors)
cluster_labels = km.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)

Các bạn có thể thấy các cụm thu được từ việc sử dụng đặc trưng của GloVe là tương tự với các cụm thu được từ việc sử dụng Word2Vec. Tuy nhiên trong bài báo này đã khẳng định Glove hoạt động tốt hơn Word2Vec trong một số trường hợp được minh họa trong biểu đồ sau
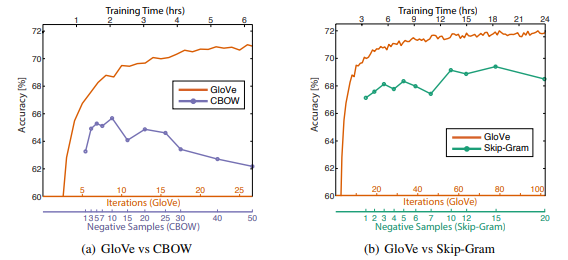
Các thí nghiệm trên được thực hiện bằng cách huấn luyện các vectơ 300 chiều trên bộ dữ liệu 6B token (Wikipedia 2014 + Gigaword 5) với cùng bộ từ vựng 400,000 từ và window_size = 10
Mô hình FastText
Mô hình FastText được giới thiệu lần đầu tiên bởi Facebook vào năm 2016 là một phần mở rộng và cải tiến của mô hình Word2Vec dựa trên bài báo "Enriching Word Vectors with Subword Information" của Mikolov et al. Nhìn chung FastText là một framework rất mạnh mẽ trong việc biểu diễn từ ngoài ra nó còn rất nhanh và chính xác trong việc phân loại các văn bản. FastText là framework mã nguồn mở được cung cấp bởi Facebook tại Github. Tại thời điểm của series này nó được công bố:
- SOTA hiện tại của English word vectors.
- Pre-trained hỗ trợ 157 ngôn ngữ từ Wikipedia và Crawl.
- Là mô hình để nhận diện ngôn ngữ và giải quyết các bài toán giám sát
Áp dụng đặc trưng từ FastText vào các bài toán Machine Learning
gensim là framework cung cấp cho chúng ta interfaces của FastText thông qua module gensim.models.fasttext. Bây giờ các bạn hãy áp dụng nó với tập dữ liệu Bible và cùng xem xét các center_word và các từ gần ngữ cảnh với nó.
from gensim.models.fasttext import FastText
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document) for document in norm_bible]
# Set values for various parameters
feature_size = 100 # Word vector dimensionality
window_context = 50 # Context window size
min_word_count = 5 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
# sg decides whether to use the skip-gram model (1) or CBOW (0)
ft_model = FastText(tokenized_corpus, size=feature_size, window=window_context,
min_count=min_word_count,sample=sample, sg=1, iter=50)
# view similar words based on gensim's FastText model
similar_words = {search_term: [item[0] for item in ft_model.wv.most_similar([search_term], topn=5)]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words

Wow! có rất nhiều điểm tương đồng với kết quả thu được từ mô hình Word2Vec. Các bạn có nhận ra sự tương đồng thú vị nào không?
Tiếp theo hãy sử dụng PCA để giảm chiều của các word embeddings và biểu diễn chúng trên biểu đồ 2-D.
from sklearn.decomposition import PCA
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = ft_model.wv[words]
pca = PCA(n_components=2)
np.set_printoptions(suppress=True)
P = pca.fit_transform(wvs)
labels = words
plt.figure(figsize=(18, 10))
plt.scatter(P[:, 0], P[:, 1], c='lightgreen', edgecolors='g')
for label, x, y in zip(labels, P[:, 0], P[:, 1]):
plt.annotate(label, xy=(x+0.06, y+0.03), xytext=(0, 0), textcoords='offset points')
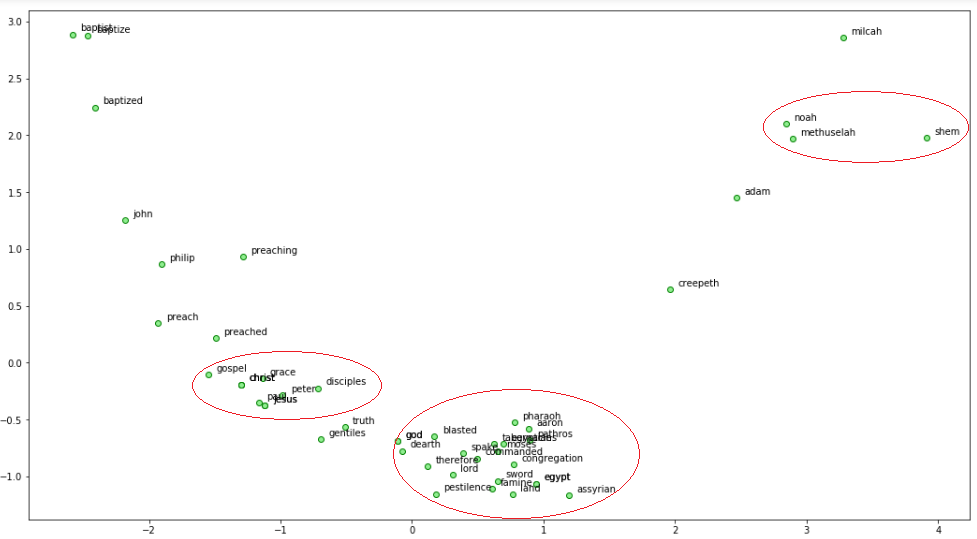
Để truy cập bất kỳ word embeddings nào bạn chỉ cần làm như sau
ft_model.wv['jesus']
array([-0.23493268, 0.14237943, 0.35635167, 0.34680951,
0.09342121,..., -0.15021783, -0.08518736, -0.28278247,
-0.19060139], dtype=float32)
Khi có được các embeddings này các bạn có thể làm một số việc rất thú vị như xem xét độ tương đồng giữa 2 embeddings khác nhau
print(ft_model.wv.similarity(w1='god', w2='satan'))
print(ft_model.wv.similarity(w1='god', w2='jesus'))
Output
------
0.333260876685
0.698824900473
Và chúng ta có thể thấy cặp "god" có sự tương đồng với "jesus" hơn so với "satan" dựa trên những gì trong bộ dữ liệu Bible. Rất thực tế!
Từ các word embeddings thậm chí chúng ta có thể tìm ra được các từ trái nghĩa với một từ như sau:
st1 = "god jesus satan john"
print('Odd one out for [',st1, ']:',
ft_model.wv.doesnt_match(st1.split()))
st2 = "john peter james judas"
print('Odd one out for [',st2, ']:',
ft_model.wv.doesnt_match(st2.split()))
Output
------
Odd one out for [ god jesus satan john ]: satan
Odd one out for [ john peter james judas ]: judas
Kết quả rất thú vị phải không!
Kết luận
Như vậy đây đã là phần cuối cùng của series về các kỹ thuật Feature Engineering, cảm ơn các bạn đã theo dõi và ủng hộ series này của mình. Đặc biệt, xin gửi lời cảm ơn đến tác giả Dipanjan (DJ) Sarkar và cộng sự đã đem đến cho chúng ta một series thật sự hay! Hẹn gặp lại các bạn trong các series tiếp theo ^^
Tài liệu tham khảo
All rights reserved
