Elixir và Unicode, Phần 2: Làm việc với Unicode Strings
Intro
Đây là bài dịch tiếp theo trong series về Elixir và Unicode của tác giả Nathan Long, Các bạn có thể đọc phần 1 tại đây
Trong bài viết trước, tôi đã đưa ra những khái niệm cơ bản về việc hỗ trợ Unicode trong Elixir: mỗi string trong Elixir là một chuỗi các codepoint, được mã hoá UTF-8. Tôi đã giải thích Unicode là gì và chúng ta đi qua các bước của quá trình encode và thấy được chính xác từng bit được tạo thành như thế nào.
Ở bài viết này, điều quan trọng chúng ta cần biết đó là: UTF-8 biểu diễn codepoint bằng 3 loại byte. Nhữnh codepoint lớn hơn sẽ gồm 1 leading byte và theo sau đó là 1, 2, 3 continuation byte, và leading byte sẽ cho chúng ta biết còn bao nhiêu continuation byte đằng sau nữa. Những codepoint nhỏ hơn thì chỉ cần 1 solo byte thôi là đủ.
Mỗi kiểu byte sẽ có pattern khác nhau và bằng cách sử dụng pattern đó, Elixir có thể làm chính xác rất nhiều thứ mà các ngôn ngữ khác làm sai, ví dụ như việc đảo chuỗi. Chúng ta cùng xem thử nhé.
Đảo ngược một chuỗi UTF-8
Giả sử là chúng ta cần đảo chuỗi a™. Elixir sẽ biểu diễn chuỗi này ở dạng binary gồm có 4 bytes: a được biểu diễn bằng 1 solo byte, ™ được biểu diễn bằng 3 bytes (1 leading byte và 2 continuation bytes)
Để cho đơn giản, ta có thể biểu diễn bằng ảnh sau:

Bạn sẽ không muốn đảo ngược các byte như dưới đây, làm sai thứ tự của các byte trong ™:

Thay vào đó, bạn cần đổi như sau, giữ đúng thứ tự các byte:

Elixir làm đúng việc này, nhờ vào việc sử dụng UTF-8, Elixir có thể biết các byte nào nên đi cùng với nhau. Điều này cũng giúp Elixir có thể tính toán đúng chiều dài của chuỗi, lấy chuỗi con dựa vào index vì ta biết được là các byte nào sẽ đi với nhau, và biết được, ví dụ, 3 byte đầu tiên là biểu diễu của 1 kí tự hay là 3 kí tự.
OK, đây mới chỉ là 1 phần của vấn đề. Vẫn còn 1 lớp nữa mà chúng ta cần xem xét.
Grapheme Clusters
Chúng ta không chỉ có nhiều byte trong cùng 1 codepoint mà chúng ta có thể có nhiều codepoint trong cùng một grapheme. Một grapheme là thứ mà theo cảm quan là 1 kí tự mà ta nhìn thấy, ví dụ như "một ký tự với dấu trọng âm hay là chữ á này chẳng hạn. Nhưng kí tự đó, ở bên dưới có thể là kết hợp của 1 chữ a thông thường (plain letter) ghép chồng với dấu sắc (combining diacritical mark). Nghĩa là: hãy đặt chồng dấu này lên kí tự đằng trước. Mỗi chuỗi các codepoint biểu diễn duy nhất một grapheme khi đó được gọi là một grapheme cluster.
noel = "noe\u0308l" # => "noël"
String.codepoints(noel) # => ["n", "o", "e", "̈", "l"]
String.graphemes(noel) # => ["n", "o", "ë", "l"]
Chú ý là Elixir cho phép chúng ta truy vấn cả codepoint lẫn grapheme trong chuỗi đó.
Lúc này bạn có thể muốn hỏi: Nếu tôi có thêm 1 dấu thì liệu tôi có thể thêm 2 được không ? Tôi có thể thêm bao nhiêu dấu tất cả ???

Câu trả lời là bạn có thể thêm cả đống cũng không sao hết.

Có thể bạn đã nhìn thấy zalgo text, ở một số trang web thiết kế chưa tốt, khi mà text box bị overflowed bằng các đoạn text này, chủ nhân của các trang này đã nghĩ là họ đã bị hack =)). Bạn có thể thấy trên StackOverflow câu hỏi làm sao để ngăn chặn việc này và kèm theo là zalgo comment.
Thật không may là không có một cách đơn giản để ngăn cản mọi người thêm cái này vào trang của bạn. Zalgo text không phải là bug, đơn giản nó là một tính năng bị dùng sai mục đích.
Hãy nhớ là Unicode đang cố để bao phủ hết tất cả ngôn ngữ của loài người. Nó hỗ trợ viết từ trái qua phải, hoặc từ phải qua trái, hỗ trợ chấm câu đặc biệt của ngôn ngữ Java để dùng viết thư cho người nhiều tuổi hơn hoặc có vai vế cao hơn.
Thực tế thì đúng là có những ngôn ngữ yêu cầu nhiều dấu kết hợp trên cùng một kí tự, ví dụ như ngôn ngữ Ticuna của Peru dùng dấu để thể hiện các âm (tones).

Ý tôi là, bạn có thể loại bỏ tất cả dấu kết hợp và làm vỡ rất nhiều đoạn text Unicode. Hoặc loại bỏ tất cả các kí tự có nhiều hơn 1 dấu kết hợp, như vậy thì người Peru chắc chắn sẽ không vui. Hoặc bạn có thể giới hạn con số 5 và những người dùng từ Tibet, những người dùng 8 hoặc nhiều hơn số dấu kết hợp, sẽ nói bye bye với trang web của bạn.
Một giải pháp đơn giản hơn đó là tuyên bố rằng: "đoạn text này không được phép overflow container chứa nó".
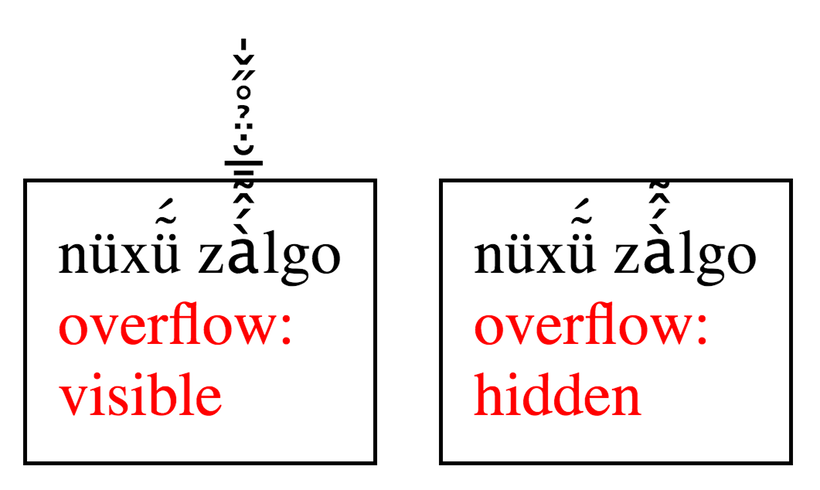
Anyway, sự thật là nhiều codepoint có thể biểu diễn một graphene như trên làm cho việc đảo chuỗi của chúng ta ở đầu bài sẽ không còn đúng nữa. Để có thể đảo chuỗi chính xác, ta cần nhóm các byte thành codepoint, rồi nhóm codepoint thành các grapheme rồi sau đó đảo chuỗi.
"noël" |> String.codepoints |> Enum.reverse # => "l̈eon"
"noël" |> String.graphemes |> Enum.reverse # => "lëon"
Dòng thứ 2, về cơ bản chính là những gì mà String.reverse trong Elixir làm, còn dòng thứ 1 là những gì mà các ngôn ngữ khác thường làm.
Tiện đây thì emoji cũng có thể được tạo ra bằng các sử dụng nhiều codepoint. Một ví dụ là đổi màu da:
👍🏿 👍🏾 👍🏽 👍🏼 👍🏻
Mỗi kí tự ở trên bao gồm 1 "thumb up" codepoint (👍) theo sau bởi một codepoint dùng để đổi màu da (ví dụ như 🏿). Kiểu này được hỗ trợ cho rất nhiều các code point khác liên quan đến con người.

Ngoài ra còn có kế hoạch kết hợp các emoji khác, ví dụ "cảnh sát + kí hiệu con gái = nữ cảnh sát", cũng là một ý tưởng hay ho.
Unicode cũng hỗ trợ vẽ gia đình bằng các kết hợp các emoji thành viên bằng các sử dụng kí tự "zero width joiner", theo suy nghĩ của tôi thì đúng là điên rồ. Không một kiểu font nào có thể hỗ trợ tất cả các kiểu cấu hình của 1 gia đình: với các màu da, tuổi tác, thành viên, con cái của từng thành viên rồi ghép lại. Tôi nghĩ việc này thích hợp biểu diễn bằng tag <img> hơn.
Túm lại, Chúng ta có thể có nhiều UTF-8 bytes biểu diễn một Unicode codepoint và nhiều codepoint biểu diễn một grapheme.
Gotchas
Và việc này dẫn đến nhiều gotcha (nhầm lẫn) cho các lập trình viên chúng ta.
Đầu tiên, để kiểm tra chiều dài của chuỗi, bạn cần phải quyết định xem bạn muốn gì. Có phải bạn muốn số grapheme, số codepoint, hay là số byte ???. String.length trong Elixir sẽ cho bạn số grapheme, thứ mà ta nhìn thấy string trông như vậy. Nếu bạn muốn byte_size hoặc số lượng codepoint, bạn cần phải rõ ràng về điều đó.
Mặc dù byte_size có độ phức tạp là , nhưng String.length sẽ cần phải duyệt string từ đầu đến cuối, nhóm các byte thành codepoint, nhóm codepoint thành grapheme, nên nó sẽ có độ phức tạp là .
Điểu khó khăn thứ hai, đó là so sánh chuỗi. Lí do là vì có nhiều hơn một cách để xây dựng lên 1 kí tự. Như ví dụ ở trên, kí tự "e" có dấu trọng âm trong noël có thể xây dựng bằng cách kết hợp kí tự e thông thường với combining diacritical mark. Tuy nhiên, ë cũng là một grapheme thông dụng nên Unicode cũng có sẵn codepoint cho nó.
Đối với con người, chúng ta không thể nhận ra được sự khác biệt giữa noël và noël nhưng nếu bạn so sánh hai chuỗi này bằng ==, nghĩa là kiểm tra giống nhau từng byte một, thì kết quả sẽ là không giống nhau. Chúng có các byte khác nhau nhưng cùng đưa ra một grapheme giống nhau. Theo định nghĩa của Unicode thì chúng là canonically equivalent (tương đồng theo tiêu chuẩn).
{two_codepoints, one_codepoint} = {"e\u0308", "\u00EB"} # => {"ë", "ë"}
two_codepoints == one_codepoint # => false
String.equivalent?(two_codepoints, one_codepoint) # => true
Cuối cùng, khi chuyển chữ hoa hoặc chữ thường cũng có thể rất khó, về cơ bản nó là 1 switch case, chạy qua từng grapheme: Nếu đó là A thi chuyển thành a, B chuyển thành b, ...
Elixir làm đúng trong hầu hết các trường hợp:
String.downcase("MAÑANA") == "mañana"
Nhưng, ngôn ngữ của con người thì vốn phức tạp. bạn nghĩ là bạn đã nắm được cơ bản cách chuyển chữ hoa-thường, để rồi nhận ra, trong tiếng Hi lạp, kí tự sigma ("Σ") khi đứng cuối từ sẽ là "ς" và là "σ" trong các trường hợp còn lại.
Đến cả Elixir cũng không quan tâm đến vấn đề này, nó chỉ chuyển hoa thường từng kí tự một, nên không thể biết được trước sau của chữ sigma là gì. Nếu đây thực sự là vấn đề mà bạn quan tâm, bạn có thể tự viết hàm GreekAware.downcase/1 để xử lý  .
.
Nhưng làm sao tôi có thể gõ các kí tự này ?
Giả sử bạn đang xem một bảng các kí tự Unicode và bạn thấy 1 thứ muốn đưa vào chuỗi trong Elixir (ví dụ như "🂡"). Bạn sẽ làm thế nào ?
Tất nhiên bạn có thể copy paste trực tiếp kí tự đó vào trong source code Elixir, nhưng điều này không đúng với tất cả các ngôn ngữ khác.
Có một cách khác là sử dụng giá trị của codepoint như ở dưới đây:
# hexadecimal codepoint value
"🂡" == "\u{1F0A1}"
# decimal codepoint value
"🂡" == <<127_137::utf8>>
Nếu bạn đã đọc bài trước của tôi thì bạn sẽ hiểu ::utf8 có nghĩa gì: nó sẽ encode số thành 1 hoặc nhiều UTF-8 byte trong binary, giống như chúng ta đã làm với ⏰.
The End !
All rights reserved
