Elixir và Unicode, Phần 1: Unicode và UTF-8 là gì ?
Bài đăng này đã không được cập nhật trong 4 năm
Intro
Đây là bài dịch đầu tiên trong series về Elixir và Unicode của tác giả Nathan Long, Các bạn có thể đọc phần 2 tại đây
Bài gốc: Part 1 | Part 2
Đây là một series rất chi tiết và dễ hiểu, mình có chỉnh sửa và bổ sung 1 chút, hi vọng đem đến cho mọi người 1 cái nhìn rõ ràng nhất về Unicode và UTF-8, thứ chúng ta gặp rất nhiều nhưng chưa chắc đã biết rõ 
Bài viết này là bài viết được đúc rút ra từ bài nói "String Theory" mà tôi là đồng diễn giả với James Edward Gray II tại hội thảo Elixir & Phoenix Conf năm 2016.
Có thể bạn đã từng nghe nó rằng Elixir hỗ trợ Unicode cực kì tốt. Điều này tạo nên một ngôn ngữ tuyệt vời cho mục đích tính toán song song, phân tán, những app chống lỗi hiệu quả, và có thể là giúp chúng ta gửi những emo like this 💩
Đặc biệt hơn nữa, Elixir còn vượt qua 1 cách hoàn hảo những bài test được khuyến cáo tại The String Type is Broken.
Bài viết này có nói rằng phần lớn các ngôn ngữ đều tạch ở một số bài kiểm tra, và thành tích tệ hại thuộc về C#, C++, Java, JavaScript, Perl (tác giả không nói cụ thể là version nào). Tuy nhiên, ở đây tôi sẽ so sánh những ngôn ngữ mà tôi hay sử dụng nhất: Elixir (version 1.3.2), Ruby (version 2.4.0-preview1) và JavaScript (run in v8 engine version 4.6.85.31).
Dưới đây là kết quả: (trong này có sử dụng một số thuật ngữ codepoints và normalized, tôi sẽ giải thích 2 thuật ngữ này sau)

(Shame on other languages  )
)
OK, Vậy làm thế nào mà Elixir có thể hỗ trợ Unicode tốt đến như vậy ?? Dù bạn hỏi (hay là giả vờ hỏi) thế nào nữa thì trước hết hãy cùng tìm hiểu ý tưởng (concept) tạo nên Unicode. Let's go ~
Unicode là gì ?
Unicode thì thực sự là bá đạo nhưng không may, ấn tượng đầu tiên của tôi về Unicode là những kí tự ô vuông kiểu như thế này:

Source: Zazzle
Trước khi nói về Unicode, hãy nói về ASCII, thứ mà những người nói tiếng Anh như tôi khi nhắc đến sẽ nghĩ ngay đến những đoạn văn bản thông thường. Nếu chạy lệnh man ascii trên máy của bạn, bạn sẽ nhận được kết quả tương tự như thế này.

Về cơ bản, ASCII đơn giản là một cách ánh xạ (mapping) từ kí tự sang số. Đây là sự đồng ý giữa các lập trình viên rằng chữ a hoa, A, có thể được biểu diễn bằng số 65 và tương tự cho các kí tự khác (Tại sao lại là 65 ??? có lí do riêng cho việc này đấy  ). Số được gán cho một kí tự sẽ được gọi là codepoint của kí tự đó.
). Số được gán cho một kí tự sẽ được gọi là codepoint của kí tự đó.
Để encode ASCII - lưu nó dưới dạng mà chúng ta có thể lưu trữ hoặc truyền đi được - rất đơn giản. Bạn chỉ cần chuyển codepoint sang cơ số 2 và thêm vào phía trái (pad) các số 0 để cho đủ 8-bit (tương đương 1 byte). Đối với Elixir chúng ta sẽ làm như sau:
base_2 = fn (i) ->
Integer.to_string(i, 2)
end
# A ? gives us the codepoint
?a == 97
?a |> base_2.() |> String.pad_leading(8, ["0"]) == "01100001"
Bởi vì chỉ có 128 kí tự ASCII nên dữ liệu thực sự không bao giờ dài hơn 7 bit, nên khi chúng ta encode a sẽ có 1 số 0 thừa ở đầu như sau.

Tạm thời chúng ta vẫn ổn với cách encode này, nhưng chúng ta muốn viết nhiều hơn những kí tự thông thường. Chúng ta muốn viết:
- Những kí tự đi kèm với trọng âm
á é í ó ú ü ñ ź đẹp trai
- Chữ Hi Lạp
λ φ θ Ω
- Kí hiệu toán học
∫f(x)dx ∞ △ABC ~ △DEF
- Chữ tượng hình Trung Quốc
夜露死苦
- Vẽ tranh chắc cũng không chết ai đâu nhỉ
𠜎 = 🐓 + 🗡 (Chữ Hàn này có nghĩa là "thiến gà")
- Ta còn muốn viết emoji nữa: cười, khóc, hôn, lật mặt, hám tiền,...
😆 😭 😘 🙃 🤑
Với Unicode, ta có thể viết tất cả các kí tự của tất cả các ngôn ngữ của con người (trên lý thuyết là vậy)
Thực tế thì, Unicode được tạo ra như một chuẩn mực nhưng nó cũng là một quá trình liên quan đến chính trị, và có ai đó nói rằng, ngôn ngữ của họ không được đối xử công bằng như các ngôn ngữ khác. Ví dụ, trong bài viết I Can Text You A Pile of Poo, But I Can’t Write My Name (Tạm dịch: tôi có thể nhắn cho bạn cả 1 đống sh!t nhưng lại không thể viết tên mình 1 cách hẳn hoi) tác giả Aditya Mukerjee có giải thích rằng, ngôn ngữ Bengal (một ngôn ngữ ở vùng Nam Á) có hơn 200 triệu người bản xứ sử dụng, nhiều hơn cả tiếng Nga nhưng không phải lúc nào cũng có thể gõ 1 cách hẳn hoi trên máy tính.
Tương tự, những người viết tiếng Trung, Hàn, Nhật cũng bị bảo như sau: Này, các bạn sẽ sử dụng chung "Han unification", như vậy chúng ta sẽ tiết kiệm thêm được vài chỗ trống  "
"

Source: The Sorry State of Japanese on the Internet
Hoặc ít nhất là đấy là cách mà họ giải thích các kí tự trên. Có một bài viết trên trang chủ của Unicode giải thích về ngôn ngữ học, tính lịch sử cũng như các lí do kĩ thuật. Bài này cũng có nhắc đến:
Quá trình này được nhận thức rất rõ bởi tiêu chuẩn quốc gia của các nước tham gia, Nhật Bản, Trung Quốc, Hàn Quốc và các nước khác, tất cả đều cùng nhau tham gia vào phần lớn công việc bao gồm tối thiểu hoá những mã hoá mà tất cả các thành viên khác của uỷ ban đều đống ý rằng chúng là của cùng một kí tự.
Đối với tôi, một người không viết bất cứ ngôn ngữ nào được nói ở trên, tôi chẳng thể đánh giá được. Nhưng nếu mà lấy việc tiết kiệm chỗ trống làm lí do kĩ thuật thì có vẻ lạ khi mà Unicode có cả bảng mã cho bài tú lơ khơ ???
 Hay là cả kí tự giả kim thuật...
Hay là cả kí tự giả kim thuật...
và kí hiệu âm nhạc của Hi Lạp cổ đại...
 à và cả Linear B, thứ mà chả ai dùng đã cả nghìn năm rồi (wtf).
à và cả Linear B, thứ mà chả ai dùng đã cả nghìn năm rồi (wtf).
Nhưng đối với mục đích của bài viết này, cái quan trọng mà tôi muốn nói đến là Unicode trên lý thuyết có thể hỗ trợ bất cứ thứ gì chúng ta muốn gõ ở bất kì ngôn ngữ nào
Ở lõi của mình, Unicode giống như ASCII: 1 danh sách các kí tự mà chúng ta muốn gõ vào máy tính. Mỗi kí tự sẽ tương ứng với một số (numberic codepoint), cho dù nó là chữ a hoa, A, chữ lambda thường, hoặc là "người đàn ông lơ lửng trong bộ vest".
A = 65
λ = 923
🕴= 128,372 # <- best emoji ever
Unicode nói: "Ok, kí tự này tồn tại, chúng tôi đã gắn cho nó một tên chính thức và một codepoint, đây là nó ở dạng chữ thường và dạng chữ hoa (nếu có), và đây (có thể) là ảnh của nó. Này những nhà thiết kế font chữ, nó hiển thị thế nào chỉ phụ thuộc vào cách bạn vẽ nó thôi đấy."
Giống như ASCII, các Unicode string (hãy tưởng tượng nó là một chuỗi "codepoint 121, codepoint 111...") cần phải được encode thành 0 và 1 trước khi ta có thể lưu trữ và truyền chúng đi. Nhưng không giống như ASCII, Unicode có nhiền hơn 1 triệu codepoint, nên ta không thể nhét vừa tất cả vào 1 byte được. Và không giống như ASCII, chúng ta KHÔNG CÓ 1 CÁCH DUY NHẤT để encode chúng.
Vậy ta có thể làm gì ? 1 ý tưởng đó là cứ 3 byte tương ứng với 1 kí tự. Nếu thế thì sẽ rất dễ cho việc duyệt string vì codepoint thứ 3 sẽ luôn bắt đầu ở byte số 7. Tuy nhiên, về mặt không gian lưu trữ và băng thông thì cách làm này không hiệu quả.
Thay vì vậy, giải pháp phổ biến nhất đó là cách mã hoá UTF-8
UTF-8
UTF-8 đưa ra cho chúng ta 4 mẫu (template) để lựa chọn: mẫu 1 byte, mẫu 2 byte, mẫu 3 byte, mẫu 4 byte
 Đối với mỗi template sẽ có những phần header giống nhau (đánh dấu bằng màu đỏ trong hình trên) và những vị trí mà ta có thể điền dữ liệu codepoint vào (đánh dấu bằng "x" ở phần trên).
Đối với mỗi template sẽ có những phần header giống nhau (đánh dấu bằng màu đỏ trong hình trên) và những vị trí mà ta có thể điền dữ liệu codepoint vào (đánh dấu bằng "x" ở phần trên).
Template 4 byte cho phép ta lưu trữ 21 bit, tương đương với 2,097,151 giá trị khác nhau, quá dư đủ so với 128,000 codepoint hiện tại. Nên là, tương lai nếu có thêm nhiều Unicode codepoint nữa thì UTF-8 cũng dễ dàng mã hoá được.
Để sử dụng các template này, đầu tiên bạn cần biểu diễn codepoint đó dưới dạng các bit.
Ví dụ, ⏰ có codepoint là 9200 (trong iex bạn có thể dùng ? để thấy giá trị này)
?⏰ # => 9200
Chuyển số đó sang hệ cơ số 2:
base_2.(?⏰) == "10001111110000"
Tổng cộng là 14 bit, không đủ nếu chúng ta dùng template 2 byte, nhưng với 3 byte thì ok. Chúng ta sẽ chèn chúng vào các vị trí lưu codepoint, từ phải sang trái và pad phần trống bằng số 0 như hình dưới:
 Cơ mà đây có phải là điều mà Elixir thực sự làm không ? Trong
Cơ mà đây có phải là điều mà Elixir thực sự làm không ? Trong iex, ta có thể dùng hàm IEx.Helpers.i/1 để kiểm tra 1 string có chứa ⏰ như sau:
i "⏰"
....
Raw representation
<<226, 143, 176>>
Ta có thể thấy string này được biểu diễn như 1 chuỗi nhị phân gồm 3 byte. Trong Elixir, "bitstring" là bất cứ cái gì nằm giữa << và >> là một chuỗi liên tiếp các bit trong bộ nhớ. Nếu chuỗi đó có số bit chia hết cho 8, ta gọi chúng là "binary" - chuỗi các byte. Và nếu các byte đó là UTF-8 hợp lệ thì nó sẽ được gọi là "string".
Ba số ở trên là biểu diễn thập phân của 3 byte của "binary", ta có thể chuyển chúng sang cơ số 2 như sau:
[226, 143, 176] |> Enum.map(base_2)
# => ["11100010", "10001111", "10110000"]
Yeah, đúng y chang những gì ta làm ở phía trên. hehe
Ba kiểu byte của UTF-8
UTF-8 đẹp trai (cool) vì chỉ cần nhìn vào những byte đó, bạn có thể nhận ra ngay nó thuộc loại nào, dựa vào nó bắt đầu bằng gì. Có những "solo" byte (byte chứa toàn bộ một code point, bắt đầu bằng 0), "leading" byte (byte đầu tiên trong 1 vài codepoint) bắt đầu bằng 11 (có thể là có cả những số 1 khác ở sau đó) và "continuation" byte (những byte thêm của codepoint), bắt đầu bằng 10. Leading bytes cho bạn biết sắp tới có bao nhiêu continuation byte: nếu bắt đầu là 110 thì codepoint sẽ có 2 byte, nếu bắt đầu là 1110, sẽ có 3 byte trong codepoint, vân vân và mây mây...
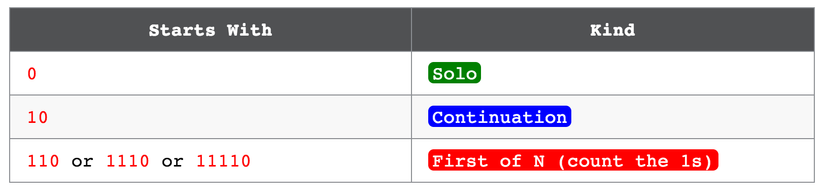 Dưới đây là ví dụ cho các template của UTF-8:
Dưới đây là ví dụ cho các template của UTF-8:

Chữ cái a được mã hoá bằng 1 solo byte - 1 byte duy nhất bắt đầu bằng 0. Kí tự "khoai lang nướng" có leading byte bắt đầu bằng 4 số 1, nghĩa là nó dài 4 byte và sau đây sẽ còn 3 continuation byte nữa bắt đầu bằng 10.
Thêm nữa, mã hoá của 'a' ở UTF-8 giống hệt như ASCII. Thực tế thì bất cứ đoạn text ASCII nào cũng có thể coi là UTF-8, nghĩa là nếu bạn có một đoạn text ASCII rồi, bạn có thể đơn giản tuyên bố: "OK, giờ nó là UTF-8 rồi nhé" và bắt đầu thêm các kí tự Unicode vào.
Việc các loại byte bắt đầu một cách khác nhau cho phép ta có thể đọc UTF-8 từ giữa file hoặc stream dữ liệu, và nếu bạn có rơi vào giữa 1 kí tự thì bạn cũng biết làm thế nào để bỏ qua cho đến leading byte hoặc solo byte tiếp theo.
Đây cũng là cơ sở để bạn có thể thực hiện các thao táo như đảo ngược chuỗi mà không lo làm vỡ chữ, đo chiều dài string, lấy substring bằng index. Trong bài tiếp theo, chúng ta sẽ xem Elixir làm những việc này như thế nào. Chúng ta cũng sẽ học được lí do tại sao mà “noël” lại không giống “noël” , làm sao để viết comment làm vỡ layout của 1 website, hay tại sao mà đến cả Elixir cũng không thể chuyển những kí tự “ΦΒΣ” từ chữ hoa thành chữ thường.
Bonus: giải thích bằng Python
>>> "á"
'\xc3\xa1'
>>> "á".decode("utf-8")
u'\xe1'
>>> bin(0xc3)
'0b11000011'
>>> bin(0xa1)
'0b10100001'
>>> bin(225)
'0b11100001'
Chúng ta thử lại với Python. Kí tự 'á' có codepoint là 225 (http://www.fileformat.info/info/unicode/char/e1/index.htm) (decode sang utf-8 sẽ có giá trị hex là 0xe1). 225 chuyển sang bit là: 11100001, 8 bit, ta chia thành 11 và 100001 (tách số bit tương ứng với số lượng chứa được trong các byte của template từ phải sang trái, trường hợp này ta sử dụng template 2 byte: 110xxxxx 10xxxxxx). Cuối cùng ta được:
110xxxxx + 11 = 11000011 = 0xc3
10xxxxxx + 100001 = 10100001 = 0xa1
Đúng như những gì ta mong đợi
ElixirConf 2016 - String Theory by Nathan Long & James Edward Gray II
All rights reserved
