Elasticsearch và quá trình phân tích dữ liệu
Bài đăng này đã không được cập nhật trong 6 năm
1. Elasticsearch
Như chúng ta đã biết thì Elasticsearch là một open-source search engine rất nổi tiếng hỗ trợ cho việc tìm kiếm cho hệ thống của bạn. Được xây dựng trên apache lucene (một thư viện mã nguồn mở để xây dựng các search engine), Elasticsearch hoạt động độc lập như một server đồng thời giao tiếp thông qua RESTful do vậy, bất kể hệ thống bạn viết bằng ngôn ngữ gì Elasticsearch đều có thể sử dụng được.
2. Sử dụng Elasticsearch
Elasicsearch có khả năng mở rộng rất mạnh mẽ, bạn có thể cài đặt để nó lưu dữ liệu dưới dạng phân tán thành nhiều server và khi có một server down thì Elasictsearch có thể tự động khôi phục dữ liệu của server đó, xem thêm các khái niệm về cluster, node, shards... , chính vì thế bạn có thể sử dụng Elasticsearch như một database. Tuy nhiên Elasticsearch chỉ mạnh mẽ ở việc truy suất và tìm kiếm dữ liệu, còn việc thêm mới / sửa / xóa dữ liệu thì kém xa các database khác như Mysql, Postgres nên khuyến khích chỉ sử dụng Elasticsearch để lưu trữ các dữ liệu cần search và kết hợp với một database khác để lưu trữ dữ liệu.
Về nguyên tắc sử dụng thì hệ thống của bạn sẽ gửi các dữ liệu cần search lên server Elasicsearch thông qua http request, các dữ liệu này sẽ được lưu dưới dạng các documents, đồng thời dữ liệu sẽ được đánh index giống các database khác để tăng tốc độ tìm kiếm, nhưng khác với các database khác, Elasticsearch , sử dụng một cấu trúc được gọi là inverted index - khác với Btree của Mysql, dữ liệu sẽ được tách ra thành các token và được lưu lại,
3. Analysis là gì?
Analysis là một quá trình được tự động thực hiện để phân tích dữ liệu trước khi lưu vào inverted index trong Elasticsearch sử dụng các analyzer. Ví dụ khi phân tích một đoạn text, quá trính này sẽ thực hiện các bước sau:
- Character filtering—Chuyển đổi các ký tự sử dụng character filter
- Breaking text into tokens—Tách đoạn text thành tập hợp các token
- Token filtering—Biến đổi các token sử dụng token filter
- Token indexing—Và cuối cùng là lưu các token đó vào inverted index
Trước khi đi vào chi tiết của từng bước, hình dưới đây sẽ mô tả tổng quan quá trình phân tích của đoạn text có nội dung "share your experience with NoSql & big data technologies" sử dụng một analyser gồm một chararacter filter, một tokenizer, và 3 token filters
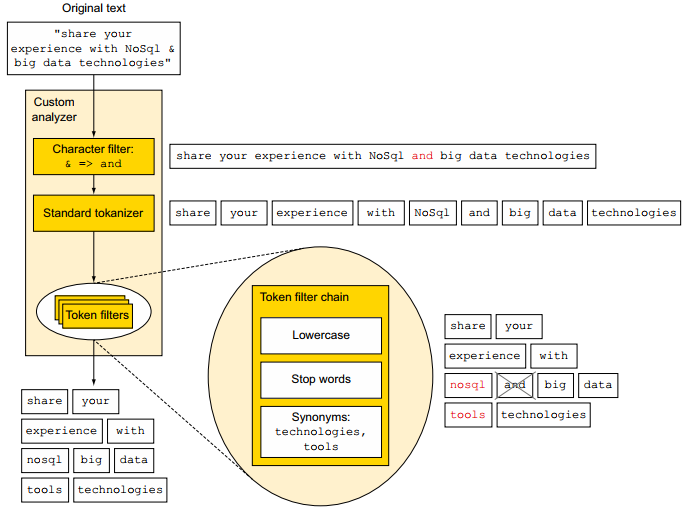
3.1 Character filtering
Đây là bước đầu tiên của quá trình analysis, ở bước này, các ký tự sẽ được chuyển đổi thành dữ liệu cho phù hợp với yêu cầu search của bạn sử dụng các Character filters , quá trình nãy sẽ giúp bạn xử lý cho các trường hợp như muốn loại bỏ các thẻ/ký tự của HTML trong đoạn text, chuyển các ký tự thành từ có nghĩa như “I love u 2” thành “I love you too”. Ở ví dụ trên charater filter đã chuyển đổi ký tự "&" thành từ "and", vì vậy khi bạn tìm kiếm với từ khóa "and" thì dữ liệu chứa ký tự "&" sẽ được liệt kê ra, một điều khó có thể thực hiện khi search với các câu lệnh sql 
3.2 Breaking into tokens
Sau khi đoạn text đã được xử lý chuyển đổi các ký tự xong, nó sẽ được phân tách thành các tokens độc lập sử dụng các tokenizers. Elasitcsearch cung cấp rất nhiều tokenizers để phục vụ cho yêu cầu bài toán của bạn, ví dụ như whitespace tokenizer sẽ tách đoạn text thành các tokens dựa váo các khoảng trắng whitespace: "artic region" sẽ output ra 2 token artic, region, hoặc letter tokenizer sẽ tách đoạn text thành các token dựa vào whitespace và các ký tự đặc biệt: "sun-asterisk company" sẽ có output là 3 tokens sun, asterisk, company
3.3 Token filtering
Sau khi đoạn text được tách và cho ra output là các tokens, các tokens này sau đó sẽ được đưa vào một hoặc nhiều các Token filters, tại đây các tokens sẽ được xóa bợt, thêm hoặc chỉnh sửa tùy vào loại token filter. Các token này sẽ hữu ích trong trường hợp bạn muốn chuyển các token về dạng lowercase và ngược lại, hoặc có thể thêm token mới "tools" như ở ví dụ trên. Một analyzer có thể có không hoặc nhiều token filters
3.4 Token indexing
Sau khi các token đã đi qua 0 hoặc nhiều token filters chúng đã được gửi tới Lucene để được lập đánh index. Một analyzer sẽ bao gồm không hoặc nhiều character filters, một tokenizer, và không hoặc nhiều token filters
Tùy thuộc vào loại query bạn sử dụng, analyzer này cũng có thể được áp dụng cho tìm kiếm văn bản trước khi search được thực hiện. Đặc biệt, các query chứa các truy vấn match và match_phrase thực hiện analysis trước khi thực hiện tìm kiếm, để xử lý dữ liệu trước, nhờ vậy thì kết quả tìm kiếm trả về sẽ chính xác hơn và việc tìm kiếm cũng nhanh hơn.
4. Lời kết
Trên đây là phần tổng hợp về Elasticsearch và quá trình phân tích dữ liệu của Elasticsearch khi dữ liệu được đánh index , vì mới tìm hiểu nên bài viết có phần sơ sài mong các bạn góp ý, mình sẽ tiếp tục nghiên cứu đi sâu vào phần này ở các bài viết sau. Cám ơn các bạn đã quan tâm ^_^
Nguồn tham khảo:
- https://www.elastic.co/guide/index.html
- Ebook "Elasticsearch in action" Part 1 - Chapter 5: https://github.com/BlackThursdays/https-github.com-TechBookHunter-Free-Elasticsearch-Books/blob/master/book/Elasticsearch in Action.pdf
All rights reserved
