Deploy ứng dụng Machine learning lên Web server. Phần 4: Dự báo giá coin với LSTM - Keras - Python
Bài đăng này đã không được cập nhật trong 7 năm
LSTM là gì?
LSTM (Long Short Term Memory networks) là một cải tiến của mạng RNN có khả năng học phụ thuộc xa. LSTM được Hochreiter & Schmidhuber giới thiệu lần đầu tiên vào năm 1997 sau đó được nhiều cải tiến và được ứng dụng trong rất nhiều lĩnh vực như: Robot control, Time series prediction, Speech recognition, Time series anomaly detection, ...
LSTM được thiết kế để giải quyết vấn đề phụ thuộc xa. Việc nhớ thông tin trong là thuộc tính mặc định của mạng, chứ ta không cần phải luyện. Tức là ngay mạng LSTM có thể ghi nhớ được mà không cần bất kì can thiệp nào.
Sự khác biệt của LSTM và RNN thuần đó là LSTM có "tầng cổng quên" (forget gate layer).
Đầu vào của cổng quên này là và cho ra một giá trị trong khoảng (0 quên hết, 1 là nhớ hết, ngoài ra là nhớ 1 phần) thông qua hàm sigmoid. Một Cell LSTM gồm có 3 cổng tương ứng với 3 tầng đó là tầng cổng quên (forget gate layer), tầng cổng vào (input gate layer) và tầng tham chiếu (output gate layer).
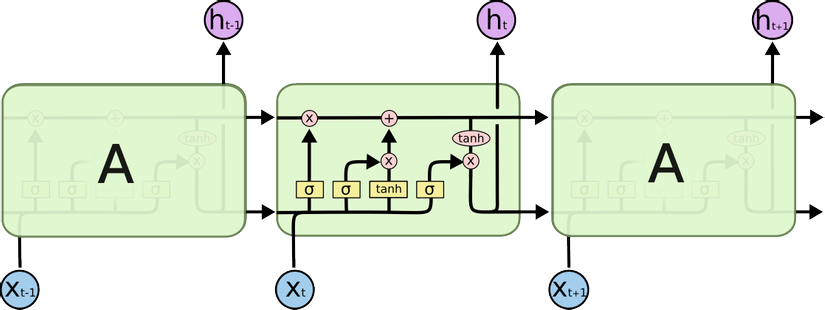
Vậy bộ nhớ dài hạn có tác dụng gì trong dự báo giá Coin?
Để giải thích vấn đề này mình xin nêu ra 1 ví dụ ngắn sau:
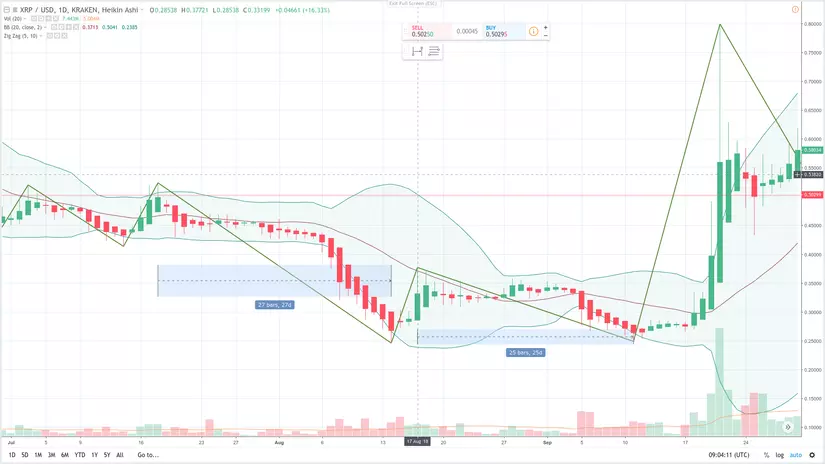
Bằng cách đo Date Range trên Tradingview mình có thể đoán được ngày nào nên mua XRP và ngày nào nên bán (cỡ khoảng 25-27 ngày).
Đối với RNN thuần để đoán được khả năng này khá là khó do nhớ được khá ít. Còn đối với LSTM thì rất may là nó nhớ sẵn rồi nên mình không cần phải can thiệp vào (chém gió vậy thôi chứ để đoán ra được cái này nó là cả 1 câu chuyện dài  ).
).
Oke vậy là tạm qua phần giới thiệu cơ bản về lí thuyết nếu muốn cụ thể hơn thì các bạn vui lòng tham khảo ở phần tài liệu tham khảo nhé
Code LSTM bằng Python với thư viện Keras
Thật may là ta không phải code chay từ đầu để xây dựng mô hình LSTM vì có thư viên sẵn mà chiến với Keras được base trên TensorFlow,Theano, CNTK.
Code full tham khảo tại đây: https://github.com/hung96ad/predict_price_cryptocurrencies
Install Libraries
Ở đây mình chạy trực tiếp luôn không chạy qua máy ảo Vitualenv hay Docker nhé vì sau cho chạy dự báo mỗi giờ 1 lần:
pip3 install --upgrade tensorflow
pip3 install h5py
pip3 install keras
pip3 install matplotlib
pip3 install pandas
pip3 install sklearn
Get data train
Lưu ý là bạn phải crawl data từ bài hướng dẫn trước lưu vào database rồi nhé: Crawl dữ liệu từ sàn Binance.com
Lấy dữ liệu để train và validate như sau:
SELECT c.`close`,
c.high,
c.low,
c.`open`,
c.volume,
c.quoteAssetVolume,
c.numberOfTrader,
c.takerBuyBaseAssetVolume,
c.takerBuyQuoteAssetVolume,
c.`ignore`
FROM candlestick_data AS c
WHERE c.idCoin = 173
Ví dụ trên mình lấy idCoin = 173 tức là cặp ADAETH bạn muốn train dữ liệu coin nào thì lấy id tương ứng nhé. Sau mình sẽ dự báo toàn bộ Market ETH.
Validate dữ liệu thì mình lấy 2 ngày do trade ngắn hạn nên mình cho chạy dự báo mỗi giờ vì vậy mà dữ liệu để validate mình lấy vậy thôi .
n_time_predicts = 2 * 24
Convert Time series to Supervised Learning
Việc convert từ bài toán chuỗi thời gian thành bài toán học có giám sát được thực hiện với tư tưởng như sau:
- Bắt đầu từ khung giờ thứ đến khung giờ
- Input: là những giá trị cần đưa vào của của khung giờ
- Output: là giá trị cần dự đoán của khung giờ tiếp theo ở đây mình lấy là giá "close"
Ví dụ với dữ liệu như sau:
| open | high | low | close | volume | quoteAssetVolume | numberOfTrader | takerBuyBaseAssetVolume | takerBuyQuoteAssetVolume | ignore |
|---|---|---|---|---|---|---|---|---|---|
| 0.0304000000 | 0.0306000000 | 0.0298550000 | 0.0304370000 | 1560.9700000000 | 47.4380609300 | 78 | 1227.1100000000 | 37.3092471400 | 57146.3825541400 |
| 0.0305260000 | 0.0307860000 | 0.0295340000 | 0.0301300000 | 578.1300000000 | 17.4638475100 | 195 | 314.9800000000 | 9.5420328900 | 54835.6917909400 |
| 0.0299520000 | 0.0302000000 | 0.0292500000 | 0.0298500000 | 563.5500000000 | 16.7206037600 | 225 | 176.9500000000 | 5.2605256600 | 54957.7561959400 |
| 0.0300330000 | 0.0306820000 | 0.0296000000 | 0.0300320000 | 790.9300000000 | 23.8081811100 | 221 | 322.3500000000 | 9.7097861000 | 54957.7561959400 |
| 0.0300860000 | 0.0305000000 | 0.0297560000 | 0.0299660000 | 643.7500000000 | 19.4555166800 | 222 | 280.4600000000 | 8.4800854000 | 51842.1161959400 |
Sẽ được chuyển thành dạng sau:
| open(t) | high(t) | low(t) | close(t) | volume(t) | quoteAssetVolume(t) | numberOfTrader(t) | takerBuyBaseAssetVolume(t) | takerBuyQuoteAssetVolume(t) | ignore(t) | close(t+1) |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0304000000 | 0.0306000000 | 0.0298550000 | 0.0304370000 | 1560.9700000000 | 47.4380609300 | 78 | 1227.1100000000 | 37.3092471400 | 57146.3825541400 | 0.0301300000 |
| 0.0305260000 | 0.0307860000 | 0.0295340000 | 0.0301300000 | 578.1300000000 | 17.4638475100 | 195 | 314.9800000000 | 9.5420328900 | 54835.6917909400 | 0.0298500000 |
| 0.0299520000 | 0.0302000000 | 0.0292500000 | 0.0298500000 | 563.5500000000 | 16.7206037600 | 225 | 176.9500000000 | 5.2605256600 | 54957.7561959400 | 0.0300320000 |
| 0.0300330000 | 0.0306820000 | 0.0296000000 | 0.0300320000 | 790.9300000000 | 23.8081811100 | 221 | 322.3500000000 | 9.7097861000 | 54957.7561959400 | 0.0299660000 |
| 0.0300860000 | 0.0305000000 | 0.0297560000 | 0.0299660000 | 643.7500000000 | 19.4555166800 | 222 | 280.4600000000 | 8.4800854000 | 51842.1161959400 | Nan |
Nan là giá trị mình cần dự báo
Code
def series_to_supervised(self, data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
for i in range(0, n_out):
cols.append(df.shift(i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
for i in range(n_in, 0, -1):
cols.append(df.shift(-i))
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
agg = concat(cols, axis=1)
agg.columns = names
if dropnan:
agg.dropna(inplace=True)
agg = agg.fillna(0)
return agg
# Chuẩn hóa dữ liệu đưa về đoạn [0,1]
def normalize_data(self, dataset, dropnan=True):
values = dataset.values
values = values.astype('float32')
scaled = self.scaler.fit_transform(values)
reframed = self.series_to_supervised(scaled, self.n_hours, 1, dropnan)
values = reframed.values
return values
Build model
Ở đây mình dùng 2 layers LSTM cấu hình sau:
units = 64
n_time_predicts = 2 * 24
epochs = 50
batch_size = 128
verbose = 0
min_delta = 1e-15
patience = 30 # với 30 vòng lặp mà loss giản không đáng kể thì dừng (1e-15 yên tâm là nó sẽ chạy hết 50 epochs :D)
monitor = 'val_loss'
Code
def build_model(self, units, train_X, loss='mse', optimizer='adam'):
model = Sequential()
model.add(LSTM(units,input_shape=(train_X.shape[1], train_X.shape[2]), return_sequences=True))
model.add(LSTM(units))
model.add(Dense(1))
model.compile(loss=loss, optimizer=optimizer)
return model
Fit model
def fit_model(self, model, train_X, train_y, test_X, test_y, symbol, config):
epochs, batch_size, verbose, min_delta, patience, monitor = config
model.fit(train_X, train_y, epochs=epochs, batch_size=batch_size, verbose=verbose, shuffle=False, validation_data=(test_X, test_y),
callbacks = [EarlyStopping(monitor=monitor, min_delta=min_delta, patience=patience)])
return model
Đợi 1 lát chắc tầm 1-2 phút.
Predict
Sau khi chạy hàm predict dữ liệu đầu ra là 1 array với khoảng giá trị (-1;1) cần phải được inverse_transform về dạng dữ liệu chuẩn ban đầu:
def make_predict(self, model, test_X, n_features = 1):
yhat = model.predict(test_X)
test_X = test_X.reshape((test_X.shape[0], self.n_hours*n_features))
inv_yhat = self.invert_scaling(yhat, test_X, n_features)
return inv_yhat
def invert_scaling(self, test_y, test_X_reshape, n_features):
inv_y = concatenate((test_y, test_X_reshape[:, -(n_features - 1):]), axis=1)
inv_y = self.scaler.inverse_transform(inv_y)
inv_y = inv_y[:,0]
return inv_y
Ta được kết quả như sau:
RMSE = 1.99825E-6
MAX_ERROR = 5.91337E-6 # sai số lớn nhất
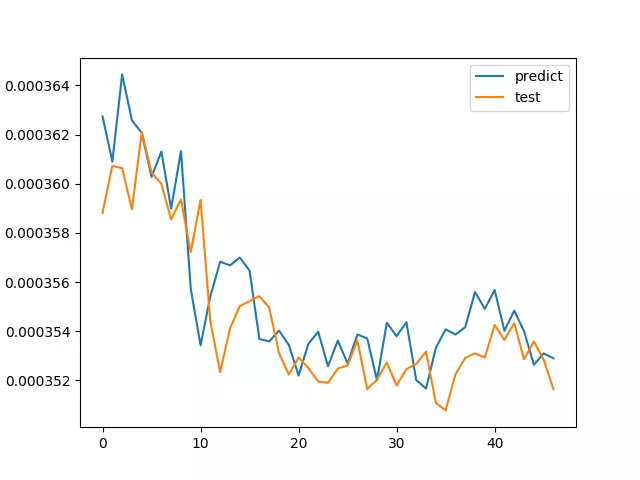
Oke nhìn dự đoán trông có vẻ khả là đúng. Đường Predict đi trước Test 1 nhịp để bắt sóng 
Ngoài ra để dự báo về sau thì mình cần lưu lại model và weight:
def save_model(self, model, symbol):
model.save_weights("weights/weight_%s.h5"%symbol)
model_json = model.to_json()
with open("models/model_%s.json"%symbol, "w") as json_file:
json_file.write(model_json)
Train model với nhiều cặp coin
Mình cho vòng lặp for để chạy hết dữ liệu các đồng thôi.
Chắc có lẽ do mình code tồi nên trong vòng for thì bộ nhớ không được giải phóng dẫn đến tình trạng tràn bộ nhớ không dự báo được nhiều @@.
Để giải quyết vấn đề bộ nhớ mình đã tìm được 1 giải pháp đó là dùng chính Python để gọi lại Python. Sau mỗi lần chạy với 1 cặp coin lưu model, weight lại và gọi lại sử dụng thư viện subprocess và argparse để chạy
# run.py
from subprocess import Popen, PIPE, STDOUT
from connectDB import ConnectDB
import time
if __name__ == '__main__':
start_time_main = time.time()
DB = ConnectDB()
list_coin = DB.get_list_coin_info("ETH")
for coin in list_coin:
print(coin)
start_time = time.time()
p = Popen('python3 train.py -id %s -symbol %s'%(coin[1], coin[0]), shell=True,
stdout=PIPE, stderr=STDOUT)
retval = p.wait()
print("Time train: %f" %(time.time() - start_time))
time.sleep(1)
print("Total time train: %f" %(time.time() - start_time_main))
# train.py
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Predict coin price.")
parser.add_argument('-id',type=int,help="-id id coin")
parser.add_argument('-symbol',type=str,help="-symbol symbol coin")
args = parser.parse_args()
coin = [args.symbol, args.id]
units = 64
n_hours = 1
n_time_predicts = 2 * 24
epochs = 50
batch_size = 128
verbose = 0
min_delta = 1e-15
patience = 30
monitor = 'val_loss'
config_train = (epochs, batch_size, verbose, min_delta, patience, monitor)
trainModel = trainModel(coin , n_hours, n_time_predicts, config_train, units)
trainModel.train_model()
Dự báo với nhiều cặp coin
Mấu chốt của việc dự báo với nhiều cặp coin để mình lựa chọn đồng nào tốt nhất với hi vọng profit sẽ max . Vì vậy cần lưu vào CSDL để dùng sau này. Ngoài ra còn cần giao diện để người dùng xem và có tin tưởng sử dụng hay không.
Do vậy cần thiết kế CSDL để lưu đống dữ liệu dự báo và show cho người dùng. Sau đây là query create table mà mình sử dụng
DROP TABLE IF EXISTS `historical_train`;
CREATE TABLE `historical_train` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`id_coin` smallint(6) DEFAULT NULL,
`time_create` int(11) DEFAULT NULL,
`price_test` text,
`price_predict` text,
`RMSE` float DEFAULT NULL,
`max_error` float DEFAULT NULL,
`openTime_last` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `time_create` (`time_create`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `historical_price_predictions`;
CREATE TABLE `historical_price_predictions` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`id_coin` smallint(6) DEFAULT NULL,
`time_create` int(11) DEFAULT NULL,
`price_predict` text,
`price_actual` text,
`price_preidct_last` float DEFAULT NULL,
`price_predict_previous` float DEFAULT NULL,
`price_actual_last` float DEFAULT NULL,
`price_actual_previous` float DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `time_create` (`time_create`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Để lưu dữ liệu vào cần convert array thành string:
def save_to_db(self, inv_yhat, inv_y, id_coin):
time_create = int(time.time())
price_predict = array2string(inv_yhat, separator=',')
price_actual = array2string(inv_y, separator=',')
price_preidct_last = inv_yhat[-1]
price_predict_previous = inv_yhat[-2]
price_actual_last = inv_y[-1]
price_actual_previous = inv_y[-2]
self.db.insert_history_prediction(id_coin, time_create, price_actual, price_predict,
price_preidct_last, price_predict_previous, price_actual_last, price_actual_previous)
Insert vào DB:
def insert_history_prediction(self, id_coin, time_create, price_actual, price_predict,
price_preidct_last, price_predict_previous, price_actual_last, price_actual_previous):
cnx = config_db()
cursor = cnx.cursor()
query_string = "INSERT INTO historical_price_predictions(id_coin, time_create, price_actual, price_predict, \
price_preidct_last, price_predict_previous, price_actual_last, price_actual_previous)\
VALUES (%s,%s,'%s','%s',%s,%s,%s,%s)"%(id_coin, time_create, price_actual, price_predict,
price_preidct_last, price_predict_previous, price_actual_last, price_actual_previous)
try:
cursor.execute(query_string)
cnx.commit()
except mysql.Error as err:
print(query_string)
cnx.rollback()
print("Something went wrong: {}".format(err))
cursor.close()
cnx.close()
del cursor
del cnx
return None
Demo
Sản phẩm demo tại: http://tradersupport.club
Admin: http://tradersupport.club/admin
Lời kết
Trên đây là ví dụ khá là cơ bản để dự báo giá coin trên sàn Binance. Từ những hiểu biết cơ bản của bản thân mong rằng qua đó các bạn có thể tự xây dựng cho riêng mình 1 mô hình dự báo khác phù hợp với nhu cầu cá nhân của bản thân.
Tuy nhiên đến đây để sử dụng vẫn chưa đủ cần có giao diện trực quan cho người dùng sử dụng mà mình sẽ giới thiệu ở phần tiếp theo.
Code mình mới viết nên khá là xấu. Nếu có vấn đề gì mong các bạn tích cực comment góp ý để code clean hơn. Mình xin cảm ơn!
Lời cảm ơn!
Xin gửi lời cảm ơn đến thầy Nguyễn Danh Tú giảng dạy môn CSDL nâng cao, Lập trình hướng đối tượng, thầy Lê Chí Ngọc giảng dạy môn Hệ hỗ trợ quyết định của viện Toán ứng dụng và Tin học tại trường Đại học Bách Khoa Hà Nội và các bạn trong lớp như Phan Huy Hoàng, Nguyễn Thanh Bình, Nguyễn Văn Long giúp đỡ mình rất nhiều trong việc học về Machine Learning, cùng với đó là thời gian thực tập trên Tổ hợp giáo dục Topica trong phòng vận hành TOX đã giúp mình biết được nhiều kiến thức để triển khai một ứng dụng lên web, cách đánh index CSDL sao cho hợp lí.
Mình tìm hiểu về Machine leaning mới được tầm khoảng hơn 3 tháng do vậy theo quan điểm cá nhân của mình thì để học và code được 1 ứng dụng về ML trên Python không phải là 1 chuyện khó vấn đề chỉ là bạn có thực sự đam mê và muốn tìm hiểu về nó hay không thôi. Mình cũng xin mạn phép chia sẻ 1 số cách của bản thân để tạo được 1 ứng dụng về ML nho nhỏ:
Bước 0: (bước khó nhất) Xác định xem mình định làm về bài toán nào (mình mất khoảng 1 tháng để xác định được)
Bước 1: Hỏi Google là bài toán này đã có những thuật toán nào để giải hay chưa?
Bước 2: Copy/past Code chẳng cần hiểu cái gì cả cứ copy/past xem nó chạy được code không đã rồi tính.
- Nếu chạy được thì oke ngon quá.
- Nếu không chạy được thì đặt câu hỏi là tại sao nó không chạy được? Copy lỗi và past lên hỏi Google xem là tại sao? Nếu vẫn không ra thì hỏi những người đã từng làm về vấn đề này xem họ có biết hay không. Mình khá là may mắn vì được học cùng với Bình và Hoàng )
Bước 3: Đặt câu hỏi tại sao ở đây họ lại làm vậy? Tại sao nó chạy được?
Bước 4: Tìm hiểu lí thuyết về thuật toán để xem mình có thể cải thiện những gì hay không?
Bước 5: Tìm hiểu về những vấn đê dâu ria khác như làm thế nào để deploy lên web sử dụng chẳng hạn.
Ngoài ra nếu thấy hay hãy để lại 1 start, 1 share nhé!
Thanks you verry much!
Tài liệu tham khảo
- Code tham khảo: https://github.com/hung96ad/predict_price_cryptocurrencies
- LONG SHORT-TERM MEMORY - Hochreiter & Schmidhuber (1997): https://www.bioinf.jku.at/publications/older/2604.pdf
- Understanding LSTM Networks: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- The Unreasonable Effectiveness of Recurrent Neural Networks: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- LSTM là gì? - dominhhai: https://dominhhai.github.io/vi/2017/10/what-is-lstm/
- LSTM - Keras: https://keras.io/layers/recurrent/#lstm
- Multivariate Time Series Forecasting with LSTMs in Keras: https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
All rights reserved
