Data visualization trong Machine Learning - Phần 4
Bài đăng này đã không được cập nhật trong 7 năm
Chào mọi người, trong phần cuối của series này mình sẽ giới thiệu với mọi người một số dạng biểu đồ sử dụng trong quá trình trích chọn đặc trưng (features selection), biểu đồ dùng trong bài toán regression...
Biểu diễn kết quả trích chọn đặc trưng (features selection):
Note 1: Nhắc lại một chút về quá trình trích chọn đặc trưng:
- Trong thực tế một mẫu dữ liệu thường bao gồm rất nhiều các đặc trưng (features) khác nhau, tuy nhiên không phải tất cả các features này đều đem lại kết quả tốt cho thuật toán dự đoán. Vì vậy quá trình trích chọn đặc trưng là quá trình lựa chọn ra các features tốt cho thuật toán dự đoán sẽ sử dụng.
- Các thuật toán features selection có thể sử dụng phương pháp ranking để lựa chọn features bằng cách dựa vào mối tương quan giữa các thuộc tính để lọc ra được các thuộc tính độc lập với nhau. Một số phương pháp nâng cao khác sẽ tìm tập con features bằng cách thử và sai, xây dựng và ước lượng mô hình một cách tự động thông qua từng tập con features tìm được.
1. Recursive Feature Elimination:
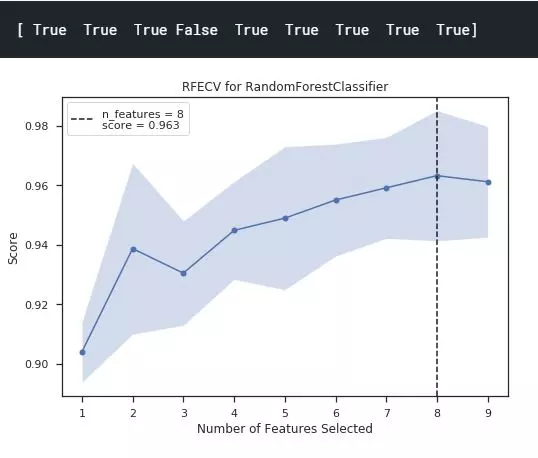
Ý nghĩa: Biểu diễn kết quả của quá trình thử và sai các tập con features để đưa ra số lượng features và các features tối ưu cho thuật toán dự đoán. Như biểu đồ trên ta có thể thấy rằng với mô hình dự đoán là RandomForestClassifier thì số lượng feature tối ưu sẽ là 8 với accuracy trung bình là 0.963
Tham số:
- cv (type: int, cross-validation): Xác định phương pháp xác thực chéo.
- model (type: estimator): Mô hình dự đoán được sử dụng.
- scoring (type: string): phương pháp đánh giá mô hình dự đoán theo scikit-learn
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from yellowbrick.features import RFECV
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(5)
oz = RFECV(model=RandomForestClassifier(), cv=cv, scoring='accuracy')
oz.fit(X=X_train, y=y_train)
print(oz.support_)
oz.poof()
Biểu diễn kết bài toán Regression:
Note 1: Nhắc lại về bài toán Regression (hồi quy):
- Nếu label không được chia thành các nhóm mà là một giá trị thực cụ thể. Ví dụ: một căn nhà rộng x m2, có y phòng ngủ, cách trung tâm thành phố z km sẽ có giá bao nhiêu? Thì bài toán đi tìm khoảng giá trị như vậy được gọi là bài toán Regression.
- Như vậy Regression cũng là một thuật toán Supervised Learning (Học có giám sát). Nghĩa là là thuật toán dự đoán đầu ra (outcome) của một dữ liệu mới (new input) dựa trên các cặp (input, outcome) đã biết từ trước.
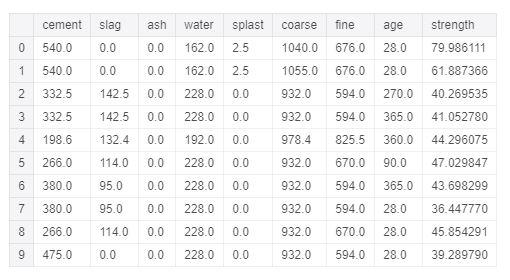
Note 2: Do có sự khác nhau về yêu cầu của label tương ứng với mỗi thuật toán Classification hay Regression nên để ví dụ cho các biểu đồ của bài toán Regression mình cần chuẩn bị lại tập dữ liệu như dưới đây. Đây là tập dữ liệu cho biết độ nét của bê tông với các đặc trưng là thành phần cấu thành lên khối bê tông đó như xi măng, nước, chất phụ gia...
from sklearn.model_selection import train_test_split from yellowbrick.datasets import load_concrete data = load_concrete() # Load the regression data set data = pd.DataFrame(data) # Specify the features of interest and the target features = ['cement', 'slag', 'ash', 'water', 'splast', 'coarse', 'fine', 'age'] target = 'strength' X = data[features] y = data[target] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
1. Prediction Error Plot:
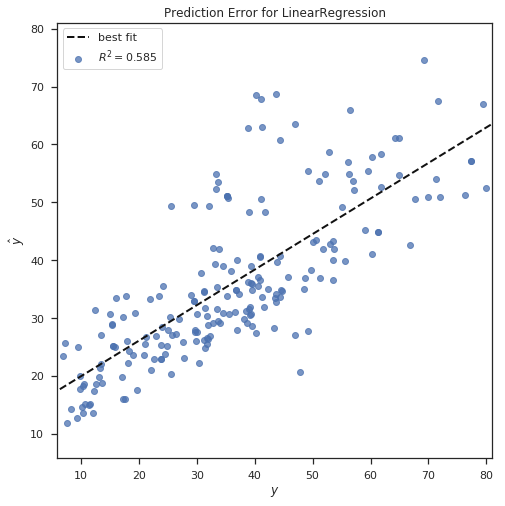
Ý nghĩa: Biểu đồ trên cho ta thấy được các điểm dữ liệu được dự đoán, đường best-fit và giá trị R-squared của mô hình dự đoán. Nếu các điểm dự đoán càng gần đường best-fit và giá trị R-squared càng lớn thì mô hình được chọn càng phù hợp với tập dữ liệu đầu vào.
Lưu ý:
- R-squared cho biết mô hình đó hợp với dữ liệu ở mức bao nhiêu %
- R-squared = 1 - RSS/TSS trong đó ESS là viết tắt của Residual Sum of Squares, tức là tổng các độ lệch bình phương của phần dư dự đoán. TSS là viết tắt của Total Sum of Squares, tức là tổng độ lệch bình phương của toàn bộ các giá trị dự đoán.
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from sklearn.linear_model import LinearRegression
from yellowbrick.regressor import PredictionError
model = LinearRegression() # Instantiate the linear model and visualizer
visualizer = PredictionError(model=model, identity=False)
visualizer.fit(X_train, y_train) # Fit the training data to the visualizer
visualizer.score(X_test, y_test) # Evaluate the model on the test data
visualizer.poof() # Draw/show/poof the data
2. Residuals Plot:
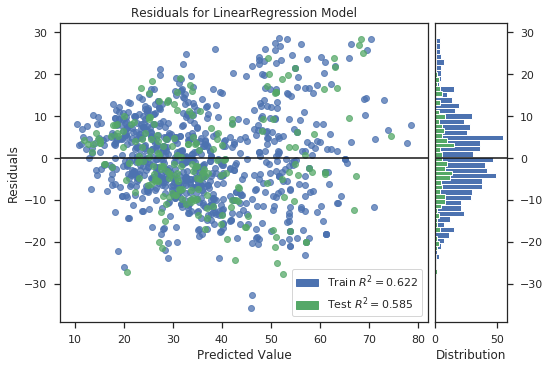
Ý nghĩa: Residuals Plot cho thấy sự khác biệt giữa phần dư trên trục tung và giá trị dự đoán ở trục hoành, cho phép bạn phát hiện các vùng giá trị có thể dễ bị lỗi nhiều hơn hoặc ít hơn.
Lưu ý:
- Residuals là giá trị thể hiện độ chênh lệch giữa giá trị dự đoán và giá trị thực tế. Trên biểu đồ, nếu các điểm residuals phân bố ngẫu nhiên về cả 2 phía của đường nằm ngang thì có thể thấy rằng một mô hình hồi quy tuyến tính là phù hợp và tập dữ liệu đầu vào, ngược lại nếu chúng ta cần một mô hình phi tuyến tính.
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from sklearn.linear_model import LinearRegression
from yellowbrick.regressor import ResidualsPlot
model = LinearRegression()
visualizer = ResidualsPlot(model=model)
visualizer.fit(X=X_train, y=y_train) # Fit the training data to the model
visualizer.score(X=X_test, y=y_test) # Evaluate the model on the test data
visualizer.poof()
Như vậy mình series Data visualization trong Machine Learning của mình đã kết thúc tại đây. Luôn có rất nhiều các thư viện, các cách khác nhau để mọi người có thể dễ dàng mô hình hóa tập dữ liệu của mình. Và những dạng biểu đồ mình giới thiệu trong series này là những dạng biểu đồ mà cá nhân mình cảm thấy mọi người có thể sẽ gặp khi giải quyết một bài toán Machine Learning. Hi vọng series này sẽ phần nào đó giúp ích cho mọi người 
All rights reserved
