Data visualization trong Machine Learning - Phần 3
Bài đăng này đã không được cập nhật trong 7 năm
Chào mọi người, trong phần trước của series này mình đã giới thiệu với mọi người một số dạng biểu đồ thường được sử dụng trong giai đoạn data preprocessing (tiền xử lý dữ liệu), các biểu đồ trong giai đoạn này cung cấp cho người dùng cái nhìn cơ bản về tập dữ liệu ta đang có như miền giá trị của các trường, sự phân bố của các categories, giá trị khuyết thiếu... Trong phần này mình sẽ tiếp tục giới thiệu với mọi người các biểu đồ liên quan đến sự phân phối của dữ liệu và một số dạng biểu đồ sử dụng trong việc mô hình hóa kết quả của bài toán phân lớp (classification).
Biểu diễn sự phân bố dữ liệu:
Note 1: Nhắc lại một chút về phân phối xác suất:
- Phân phối xác suất dùng để miêu tả mức độ (hay xác suất) xảy ra các khả năng có thể một đại lượng ngẫu nhiên, nhằm giúp người nghiên cứu dễ dàng nhận biết các khả năng nào hay xảy ra nhất và với giá trị là bao nhiêu. Có rất nhiều loại phân phối khác nhau, trong đó nổi tiếng và phổ biến nhất là phân phối chuẩn (hay còn lại là phân phối Gauss)
- Phân phối chuẩn là một trong các phân phối xác suất quan trọng nhất của toán thống kê, phản ánh giá trị và mức độ phân bố của các dữ liệu đang nghiên cứu. Phân phối chuẩn được đặc trưng bởi hai tham số là giá trị kỳ vọng µ (Muy) còn được hiểu là giá trị trung bình, và độ lệch tiêu chuẩn σ (Sigma). Trong khi giá trị µ là mức trung bình của tất cả các dữ liệu đang nghiên cứu thì σ phản ánh mức độ đồng đều của các dữ liệu này. Đồ thị của phân phối chuẩn có dạng hình chuông.
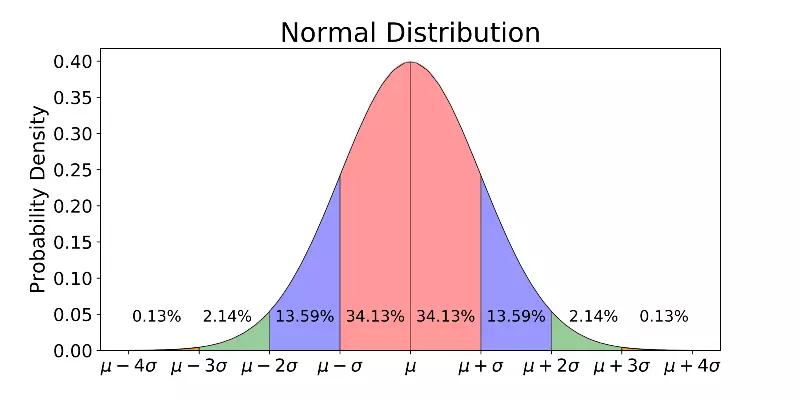
Note 2: Các thuật toán học máy thường đủ thông minh để xử lý với hầu hết các dạng phân phối của dữ liệu. Tuy nhiên nếu dữ liệu tuân theo phân phối chuẩn cũng sẽ có một số lợi thế như giúp thuật toán hội tụ đúng và nhanh hơn. Ngoài ra một số thuật toán base trên Gradient Descent khá nhạy cảm với dải giá trị của các features nên người ta cũng cần phải chuẩn hóa dữ liệu trước khi thực hiện việc tính toán
1. Phân phối đơn biến:
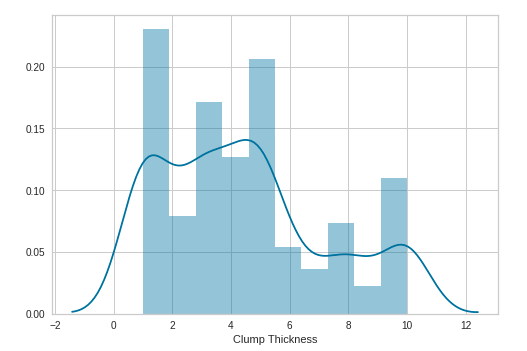
Ý nghĩa: Biểu diễn phân phối của một feature cụ thể, từ biểu đồ chúng ta có thể xem xét được dạng phân phối, miền giá trị, mức độ tập trung giá trị của feature đang xét.
Tham số:
- a (type: Series, 1d-array, list): Dữ liệu cần quan sát. Thường là một cột của tập dữ liệu đầu vào.
- kde (type: boolean): Nếu set là True đường ước lượng mật độ hạt nhân (kernel density estimate) sẽ được hiển thị, nếu là False sẽ được ẩn.
Code:
import seaborn as sns
sns.distplot(a=X['Clump Thickness'], kde=True)
2. Phân phối đôi biến (bivariate distributions):
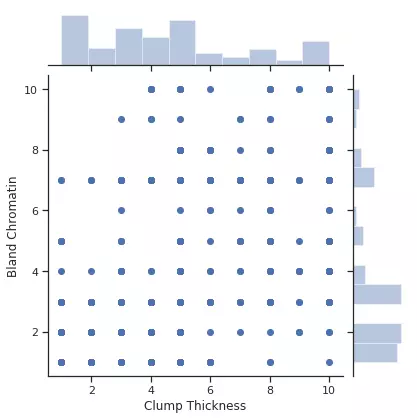
Ý nghĩa: Biểu diễn phân phối của một cặp feature cụ thể, từ biểu đồ chúng ta có thể xem xét được dạng xác suất xảy ra của label khi cùng xuất hiện cặp feature đang xét. Ngoài ra ta cũng có được biểu đồ phân phối của từng feature tương ứng ở trục x, y.
Tham số:
- x, y (type: String): Tên của feature cần biểu diễn.
- data (type: data frame): Tập dữ liệu cần biểu diễn
Code:
import seaborn as sns
sns.jointplot(x='Uniformity of Cell Size', y='Uniformity of Cell Shape', data=X)
3. Multiple pairwise bivariate distributions:
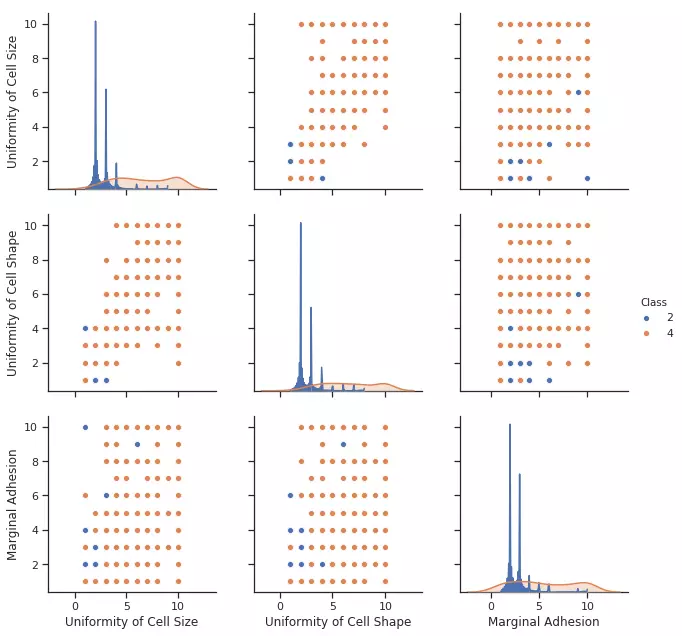
Ý nghĩa: Biểu diễn một ma trận mối quan hệ giữa từng cặp features trong tập dữ liệu đầu vào và mối quan hệ giữa cặp feature đang xét đó với target của mẫu đang xét. Ngoài ra ta cũng có được biểu đồi phân phối của từng feature tương ứng ở đường chéo của ma trận.
Tham số:
- hue (type: String): Tên của cột target.
- vars (type: String/String array): Tên của các cột cần biểu diễn
Code:
import seaborn as sns
sns.pairplot(df, hue='Class', vars=['Uniformity of Cell Size', 'Uniformity of Cell Shape', 'Marginal Adhesion'])
Biểu diễn kết quả của bài toán phân lớp:
Note 1: Nhắc lại một chút về True/False Positive/Negative:
- Cách đánh giá này thường được áp dụng cho các bài toán phân lớp có hai lớp dữ liệu. Cụ thể hơn, trong hai lớp dữ liệu này có một lớp được ưu tiên hơn lớp kia và cần được dự đoán chính xác. Ví dụ, trong bài toán xác định có bệnh ung thư hay không thì việc không bị sót (miss) quan trọng hơn là việc chẩn đoán nhầm âm tính thành dương tính. Trong những bài toán này, người ta thường định nghĩa lớp dữ liệu quan trọng hơn cần được xác định đúng là lớp Positive, lớp còn lại là lớp Negative. Như vậy ta có thể định nghĩa True Positive(TP), False Positive (FP), True Negative (TN), False Negative (FN) như sau:
- Với các bài toán có nhiều hơn hai lớp dữ liệu ta cũng có thể chọn ra một lớp được ưu tiên là Positive và tất cả các lớp còn lại là Negative để xác định TP, FP, TN, FN.

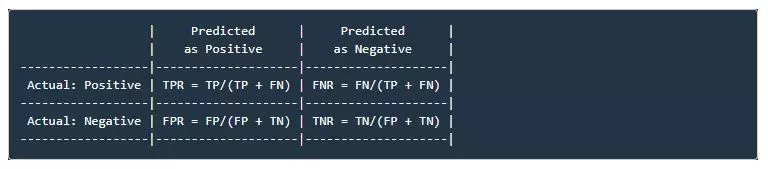
Note 2: TPR, FNR, FPR, TNR (R - Rate):
- Trên thực tế người ta thường quan tâm đến các chỉ số TPR, FNR, FPR, TNR, các giá trị trên được xác định bởi:
- False Positive Rate còn được gọi là False Alarm Rate (tỉ lệ báo động nhầm), False Negative Rate còn được gọi là Miss Detection Rate (tỉ lệ bỏ sót). Trong bài toán dự đoán bệnh ung thư đang xét, người ta sẽ ưu tiên thà báo nhầm còn hơn bỏ sót, tức là ta có thể chấp nhận False Alarm Rate cao để đạt được Miss Detection Rate thấp.
Note 3: Để phục vụ cho bài toán phân lớp chúng ta sẽ chia tập dữ liệu đầu vào thành hai phần train và test:
from sklearn.model_selection import train_test_split # Extract the numpy arrays from the data frame X = df[features].as_matrix() y = df.Class.as_matrix() # Create the train and test data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
1. Confusion Matrix:
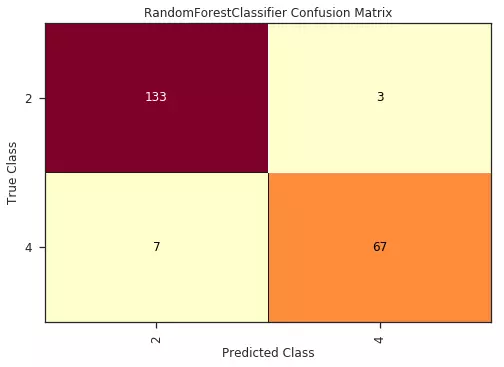
Ý nghĩa: Biểu diễn trực quan kết quả cụ thể mỗi loại được phân loại như thế nào, lớp nào được phân loại đúng nhiều nhất, và dữ liệu thuộc lớp nào thường bị phân loại nhầm vào lớp khác. Về cơ bản, confusion matrix thể hiện có bao nhiêu điểm dữ liệu được dự đoán vào một phân lớp, và bao nhiêu điểm dữ liệu thực tế thuộc một phân lớp.
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from yellowbrick.classifier import ConfusionMatrix
from yellowbrick.classifier import ClassPredictionError
cm = ConfusionMatrix(model=RandomForestClassifier())
cm.fit(X=X_train, y=y_train)
cm.score(X=X_test, y=y_test)
cm.poof()
2. Biểu đồ lỗi dự đoán (Class Prediction Error):
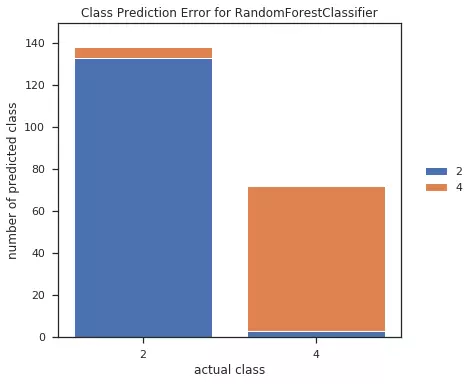
Ý nghĩa: Biểu diễn trực quan kết quả dự đoán của mô hình, số lượng mẫu bị dự đoán sai cho từng phân lớp. Ta có thể thay đổi các mô hình khác nhau để so sánh kết quả.
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassPredictionError
visualizer = ClassPredictionError(model=RandomForestClassifier())
visualizer.fit(X=X_train, y=y_train)
visualizer.score(X=X_test, y=y_test)
visualizer.poof()
3. Classification Repor:
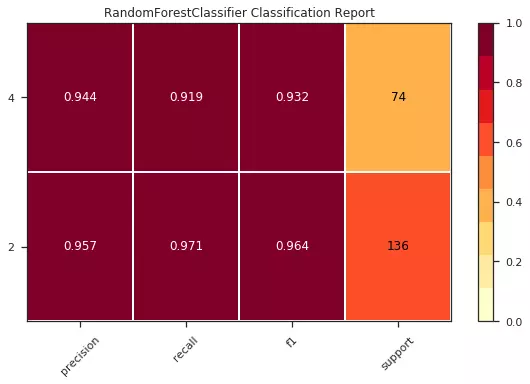
Ý nghĩa: Biểu diễn kết quả của mô hình dự đoán bao gồm các chỉ số precision, recall, F1 và support scores.
Lưu ý:
- Precision được định nghĩa là tỉ lệ số điểm true positive trong số những điểm được phân loại là positive (TP + FP).
- Recall được định nghĩa là tỉ lệ số điểm true positive trong số những điểm thực sự là positive (TP + FN).

- F1-Score: Đây được gọi là một trung bình điều hòa(harmonic mean) của các tiêu chí Precision và Recall. Nó có xu hướng lấy giá trị gần với giá trị nào nhỏ hơn giữa 2 giá trị Precision và Recall và đồng thời nó có giá trị lớn nếu cả 2 giá trị Precision và Recall đều lớn. Chính vì thế F1-Score thể hiện được một cách khách quan hơn performance của một mô hình học máy.
- Support scores: Số lượng mẫu đã được dự đoán
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- support (type: boolean): Nếu set là True thang màu tương ứng với kết quả sẽ được sử dụng, nếu là False sẽ không được sử dụng.
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassificationReport
visualizer = ClassificationReport(model=RandomForestClassifier(), support=True)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
4. Biểu đồ ROC/AUC:
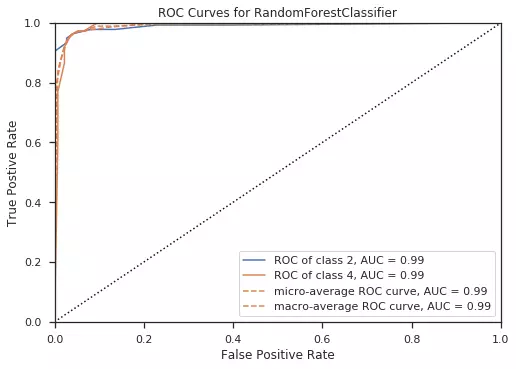
Ý nghĩa: Biểu diễn mối quan hệ giữa độ nhạy (sensitivity ) và tính đặc trưng của mô hình dự đoán (specificity). Nói cách khách là biểu diễn sự thay đổi của FNR, FPR phụ thuộc vào ngưỡng threshold được lựa chọn.
Lưu ý:
- Ứng với mỗi giá trị của threshold, ta sẽ thu được một cặp (FPR, TPR). Biểu diễn các điểm (FPR, TPR) trên đồ thị khi thay đổi threshold từ 0 tới 1 ta sẽ thu được một đường được gọi là Receiver Operating Characteristic curve hay ROC curve. (Chú ý rằng khoảng giá trị của threshold không nhất thiết từ 0 tới 1 trong các bài toán tổng quát. Khoảng giá trị này cần được đảm bảo có trường hợp TPR/FPR nhận giá trị lớn nhất hay nhỏ nhất mà nó có thể đạt được).
- AUC (Area Under the Curve): Diện tích của phần nằm bên dưới đường ROC. AUC luôn dương vào nhỏ hơn 1.
- AUC càng lớn thì mô hình dự đoán càng tốt.
Tham số:
- model (type: estimator): Mô hình dự đoán được sử dụng.
- classes (type: list): Danh sách các phân lớp của tập dữ liệu đầu vào
- X, y (type: ndarray/Series): Tập dữ liệu training và tập label.
Code:
from yellowbrick.classifier import ROCAUC
from sklearn.ensemble import RandomForestClassifier
visualizer = ROCAUC(model=RandomForestClassifier(), classes=classes)
visualizer.fit(X=X_train, y=y_train)
visualizer.score(X=X_test, y=y_test)
visualizer.poof()
Trên đây mình đã giới thiệu với các bạn các một số dạng biểu đồ sử dụng trong việc mô hình hóa phân phối của dữ liệu và một số dạng biểu đồ mô hình hóa kết quả của bài toán phân lớp. Trong phần tới, phần cuối cùng của series này mình sẽ tiếp tục giới thiệu với mọi người một số dạng biểu đồ dùng trong bài toán regression, các dạng biểu đồ sử dụng trong quá trình parameter tunning...
Tài liệu tham khảo:
https://machinelearningcoban.com/2017/08/31/evaluation/
https://viblo.asia/p/mot-vai-hieu-nham-khi-moi-hoc-machine-learning-4dbZNoDnlYM
All rights reserved
