
Data generator với Keras
Bài đăng này đã không được cập nhật trong 6 năm
Ở bài viết này mình sẽ viết về cách tạo Data Generator với Keras như thế nào. (nhạt quá =)) )
Mình sẽ viết gì ở bài này?
- Tại sao lại là Data Generator
- Thực Hành
- Kết Luận
- Reference
Tại sao lại là Data Generator
Trên thực tế không phải ai cũng có đủ tiền mua máy khủng và dữ liệu mình cần train chiếm nhiều Ram hơn dung lượng RAM thực tế mà máy chúng ta đang có. Vấn đề ở đây là khi chúng ta có một tập dữ liệu lớn và RAM không đủ để load vào cùng một lúc rồi sau đó chia tập train và test sau đó train model. Để giải quyết vấn đề này chúng ta cần chia nhỏ tập dữ liệu thành từng thư mục nhỏ sau đó load dữ liệu từng phần trong quá trình train model. Chúng ta có thể lựa chọn ăn mì bằng cách sử dụng ImageDatagenerator có sẵn của Keras. Hay chúng ta có thể tự chế biến món ăn theo cách mình mong muốn bằng cách custom Data Generator.
Ở bài viết này mình sẽ hướng dẫn bằng cách thực hành với tập Mnist.
Thực hành
Để custom Data Generator Keras có cung cấp cho chúng ta lớp Sequence (Sequence class) và cho phép chúng ta tạo các lớp có thể kế thừa từ nó.
Đầu tiên cần load tập dataset mnist.
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras.utils import Sequence, to_categorical
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Dense, Flatten, MaxPooling2D, Dropout
#load data mnist
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
Tập Mnist của chúng ta bao gồm 60000 ảnh cho tập train và 10000 ảnh cho tập test. Mỗi ảnh có kích thước là 28x28. Voi mỗi ảnh có type là float32 thì dung lượng mỗi ảnh khoảng 4 byte. chúng ta sẽ cần 4 * (28*28) *70000 + (70000 * 10) ~ 220Mb RAM đó là theo tính toán nhưng trên thực tế có thể chúng ta sẽ mất nhiều hơn. Vì vậy việc lựa chọn Data Generator là hợp lý.
Data Generator
Hàm khởi tạo init()
def __init__(self,
img_paths,
labels,
batch_size=32,
dim=(224, 224),
n_channels=3,
n_classes=4,
shuffle=True):
self.dim = dim
self.batch_size = batch_size
self.labels = labels
self.img_paths = img_paths
self.n_channels = n_channels
self.n_classes = n_classes
self.shuffle = shuffle
self.img_indexes = np.arange(len(self.img_paths))
self.on_epoch_end()
img_paths: list toàn bộ ảnh
labels: nhãn của toàn bộ ảnh
batch_size: kích thước của 1 batch
img_indexes: index của các class
input_dim: (width, height) đầu vào của ảnh
n_channels: số lượng channels của ảnh
n_classes: số lượng các class
shuffle: có shuffle dữ liệu sau mỗi epoch hay không
on_epoch_end()
Mỗi khi end hoặc start một epoch hàm này sẽ quyết định có shuffle dữ liệu hay không
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.img_paths))
if self.shuffle == True:
np.random.shuffle(self.indexes)
len()
def __len__(self):
'Denotes the number of batches per epoch'
return int(np.floor(len(self.img_indexes) / self.batch_size))
Trả về số lượng batch trên 1 epoch. Hàm len() là một built in function trong python. Chúng ta set giá trị thành:
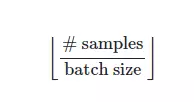
Chính là số step trên một epoch chúng ta sẽ nhìn thấy khi train model.
get_item()
def __getitem__(self, index):
'Generate one batch of data'
# tạo ra index cho từng batch
indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size]
#lấy list IDs trong 1 batch
list_IDs_temps = [self.img_indexes[k] for k in indexes]
# Generate data
X, y = self.__data_generation(list_IDs_temps)
return X, y
Hàm này sẽ tạo từng batch cho data theo thứ tự được truyền vào.
__data_generation()
def __data_generation(self, list_IDs_temps):
X = np.empty((self.batch_size, *self.dim))
y = []
for i, ID in enumerate(list_IDs_temps):
X[i,] = self.img_paths[ID]
X = (X/255).astype('float32')
y.append(self.labels[ID])
X = X[:,:,:, np.newaxis]
return X, keras.utils.to_categorical(y, num_classes=10)
__data_generation() sẽ được gọi trực tiếp từ hàm get_item() để thực hiện các nhiệm vụ chính như đọc ảnh, xử lý dữ liệu và trả về dữ liệu theo ý mình mong muốn trước khi đưa vào train model.
DataGenerator class
Sau khi hiểu và định nghĩa được các hàm ở trên chúng ta sẽ được đoạn code hoàn chỉnh dưới đây.
class DataGenerator(Sequence):
def __init__(self,
img_paths,
labels,
batch_size=32,
dim=(224, 224),
n_channels=3,
n_classes=4,
shuffle=True):
self.dim = dim
self.batch_size = batch_size
self.labels = labels
self.img_paths = img_paths
self.n_channels = n_channels
self.n_classes = n_classes
self.shuffle = shuffle
self.img_indexes = np.arange(len(self.img_paths))
self.on_epoch_end()
def __len__(self):
'Denotes the number of batches per epoch'
return int(np.floor(len(self.img_indexes) / self.batch_size))
def __getitem__(self, index):
'Generate one batch of data'
# Generate indexes of the batch
indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size]
# Find list of IDs
list_IDs_temps = [self.img_indexes[k] for k in indexes]
# Generate data
X, y = self.__data_generation(list_IDs_temps)
return X, y
def on_epoch_end(self):
'Updates indexes after each epoch'
self.indexes = np.arange(len(self.img_paths))
if self.shuffle == True:
np.random.shuffle(self.indexes)
def __data_generation(self, list_IDs_temps):
X = np.empty((self.batch_size, *self.dim))
y = []
for i, ID in enumerate(list_IDs_temps):
X[i,] = self.img_paths[ID]
X = (X/255).astype('float32')
y.append(self.labels[ID])
X = X[:,:,:, np.newaxis]
return X, keras.utils.to_categorical(y, num_classes=10)
Khởi tạo data và Training model
Ở đây mình chỉ dùng mô hình phân loại đơn giản dưới đây: Khởi tạo model
n_classes = 10
input_shape = (28, 28)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(28, 28 , 1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(n_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy'])
Khởi tạo dữ liệu train_generator và val_generator
train_generator = DataGenerator(x_train, y_train, batch_size = 32, dim = input_shape,
n_classes=10, shuffle=True)
val_generator = DataGenerator(x_test, y_test, batch_size=32, dim = input_shape,
n_classes= n_classes, shuffle=True)
Tiếp theo là train model.
model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=val_generator,
validation_steps=len(val_generator))
Kết Luận
Cảm ơn mọi người đã đọc bài viết của mình, nếu có gì chưa đúng mong nhận được sự góp ý từ mọi người!
Reference
https://stanford.edu/~shervine/blog/keras-how-to-generate-data-on-the-fly
All rights reserved
