
Cùng thiết lập Multi Node Cluster trong Hadoop 2.x nào!
Bài đăng này đã không được cập nhật trong 3 năm
Trong bài viết trước của mình, mình đã giới thiệu về Hadoop và các thành phần của Hadoop. Hadoop là một hệ sinh thái mã nguồn mở được sử dụng để lưu trữ và xử lý dữ liệu lớn. Nhân tiện một ngày đẹp trời được giao task setup multi node cluster để làm 1 số công việc trên công ty, mình viết luôn một bài coi như node lại quá trình cài đặt cũng như kiểm thử về multi node cluster trong Hadoop.
Việc triển khai multi node cluster trong Hadoop sẽ chứa hai hoặc nhiều DataNode trong môi trường Hadoop phân tán. Trong bài viết này, mình sẽ hướng dẫn các bạn cài đặt với 2 máy (1 master và 1 slave) và data node trên cả 2 máy sẽ đều chạy Triển thôi!!
Cài đặt Multi Node Cluster trong Hadoop
Những thứ cần chuẩn bị trên 2 máy
- Hadoop 2.7.3
- JAVA8
- SSH
Trước hết, do có một số lỗi vặt như đường dẫn tài khoản cty mình có '\' trong path, mà hadoop chỉ cho phép '/' vì vậy tốt nhất các bạn nên tạo riêng 1 user và cấp quyền sudo cho nó (trên tất cả các node cho an toàn), rồi cài đặt hadoop trên user đó.
- Tạo user
sudo adduser hadoop - Cấp quyền sudo
sudo usermod -aG sudo hadoop - Chuyển user
su hadoop
Bước 1: Check IP 2 máy
- Dùng lệnh
ifconfigđể kiểm tra IP 2 máy, ở đây mình có thông tin như sau- Master IP: 10.0.37.186
- Slave IP: 10.0.37.92
Bước 2: Vô hiệu hóa tường lửa
- Dùng lệnh
service iptables stopvàsudo chkconfig iptables offđể vô hiệu hóa tường lửa trên cả 2 máy - Hoặc bạn có thể dùng lệnh
sudo ufw disable
Bước 3: Thêm địa chỉ IP của master node và slave node vào file cấu hình
- Thêm cấu hình IP của 2 node vào file
/etc/hosts:sudo nano /etc/hosts

Bước 4: Restart sshd service
service sshd restart
Bước 5: Tạo SSH key trên Master Node
ssh-keygen -t rsa -P “”
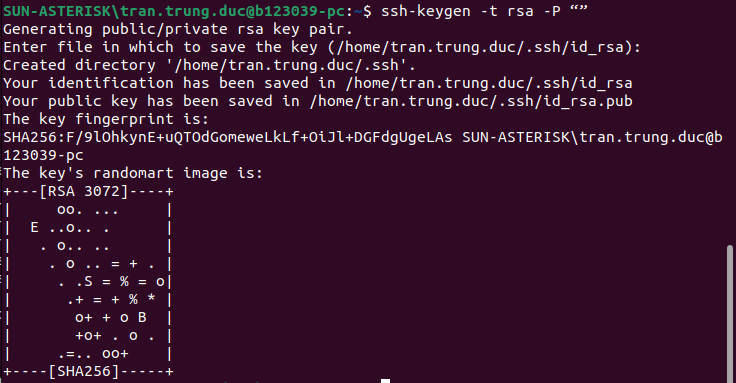
Bước 6: Sao chép SSH key vừa tạo để làm authorized key của Master Node
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Bước 7: Sao chép key ssh master node sang authorized key của slave node
ssh-copy-id -i $HOME/.ssh/id_rsa.pub user_slave_node@slave
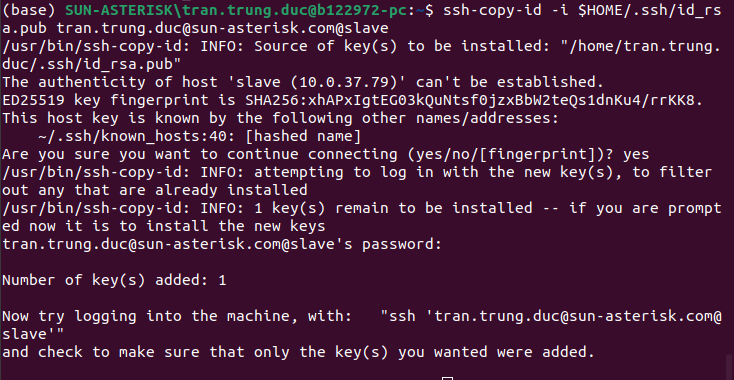
Bước 8: Cài JAVA trên tất cả các node
- Tải xuống Java8 package tại đây. Lưu trữ file này tại
/home - Giải nén package vừa tải
tar -xvf jdk-8u371-linux-x64.tar.gz
Bước 9: Cài Hadoop trên tất cả các node
- Download Hadoop Package tùy version tại đây
- Giải nén tập vừa tải
tar -xvf hadoop-2.7.3.tar.gz
Bước 10: Thêm Hadoop path và Java patth vào bash file trên tất cả các node
-
Mở file
.bashrcđể thêm các đường dẫn Hadoop và Javasudo nano .bashrc -
Thêm các nội dung sau
# Set hadoop environment variables export HADOOP_HOME=$HOME/hadoop-2.7.3 export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3 export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3 export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3 export YARN_HOME=$HOME/hadoop-2.7.3 export PATH=$PATH:$HOME/hadoop-2.7.3/bin # Set Java environment variables export JAVA_HOME=$HOME/jdk1.8.0_371 export PATH=$HOME/jdk1.8.0_371/bin:$PATH -
Thực thi các thay đổi
source .bashrc -
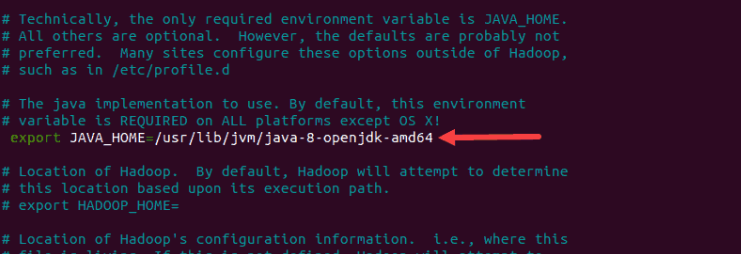
Export thêm Java path trong file
$HADOOP_HOME/etc/hadoop/hadoop_env.sh![image.png]()
-
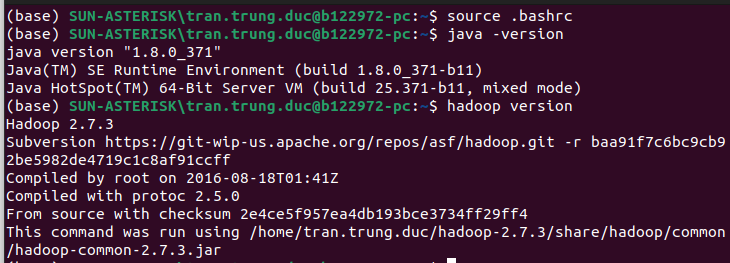
Kiểm tra lại xem đã cấu hình đúng đường dẫn hay chưa
![image.png]()
Bước 11: Disable IPv6
- Do một vài lý do, việc disable IPv6 trong Hadoop có thể cải thiện hiệu suất và ổn định cho hệ thống.
- Disable IPv6 trong
hadoop-env.shtrong folder$HADOOP_HOME/etc/hadoop/bằng cách sửa câu lệnhHADOOP_OPTS=-Djava.net.preferIPv4Stack=true - Để chắc chắn hơn, hãy kiểm tra xem Ubuntu của bạn có đang bật IPv6 không bằng lệnh sau
Nếu trả về 0 tức không bật IPv6, còn 1 thì chúng ta sẽ làm thêm 1 vài bước dưới đây để disable nócat /proc/sys/net/ipv6/conf/all/disable_ipv6
Thêm nội dung sausudo nano /etc/sysctl.conf
Reload lại config vừa thêm# IPv6 configuration net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1sudo sysctl -p
Bước 12: Cấu hình file masters và slaves
- Di chuyển tới thư mục
hadoop-2.7.3/etc/hadoopcd hadoop-2.7.3/etc/hadoop - Tại master node:
- Chỉnh sửa file
masters
sudo nano masters![image.png]()
- Chỉnh sửa file
slaves
sudo nano slaves![image.png]()
- Chỉnh sửa file
- Tại slave node:
- Chỉnh sửa file
masters
sudo nano masters![image.png]()
- Chỉnh sửa file
slaves
sudo nano slaves![image.png]()
- Chỉnh sửa file




Bước 13: Cấu hình file core-site.xml
-
Trên cả master node và slave node, cấu hình file
core-site.xmlnhư sausudo nano core-site.xml<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>![image.png]()
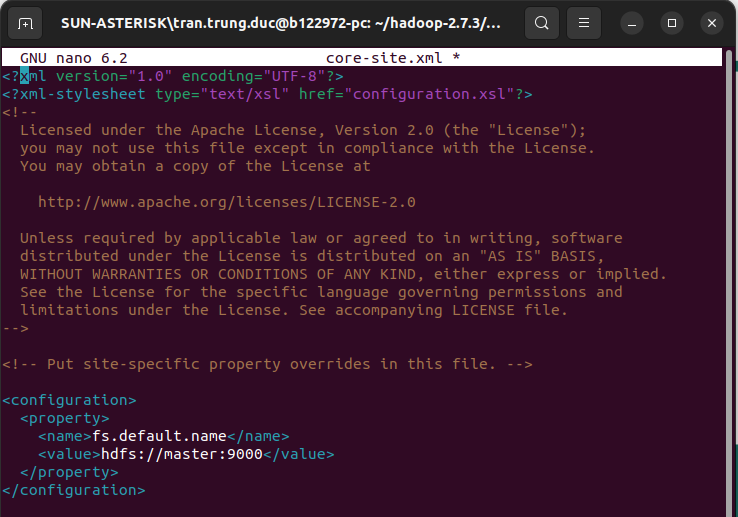
Bước 14: Cấu hình file hdfs-site.xml
-
Phần này là do mình đang thử nghiệm 2 máy nên sẽ để Secondary NameNode chính ở master node (Đúng chuẩn cần đặt Secondary NameNode ở 1 node riêng)
-
Trên master node
sudo nano hdfs-site.xml(lưu ý thay đổi --username-- cho phù hợp)<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>--IP_master_node--:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/--username--/hadoop-2.7.3/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/--username--/hadoop-2.7.3/datanode</value> </property> </configuration> -
Trên slave node
sudo nano hdfs-site.xml(lưu ý thay đổi --username-- cho phù hợp)<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.permissions.enabled</name> <value>true</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>--IP_master_node--:50090</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/--username--/hadoop-2.7.3/datanode</value> </property> </configuration>
Bước 15: Sao chép template của mapred-site.xml từ file mapred-site.xml.template
- Sao chép template thành 1 file riêng để cấu hình trên cả master node và slave node
cp mapred-site.xml.template mapred-site.xml - Cấu hình lại file
sudo nano mapred-site.xml<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Bước 16: Cấu hình file yarn-site.xml
- Trên cả master node và slave node, cấu hình file
yarn-site.xmlnhư sausudo nano yarn-site.xml<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Bước 17: Định dạng tên node trên master node
- Tại master node:
hdfs namenode -format
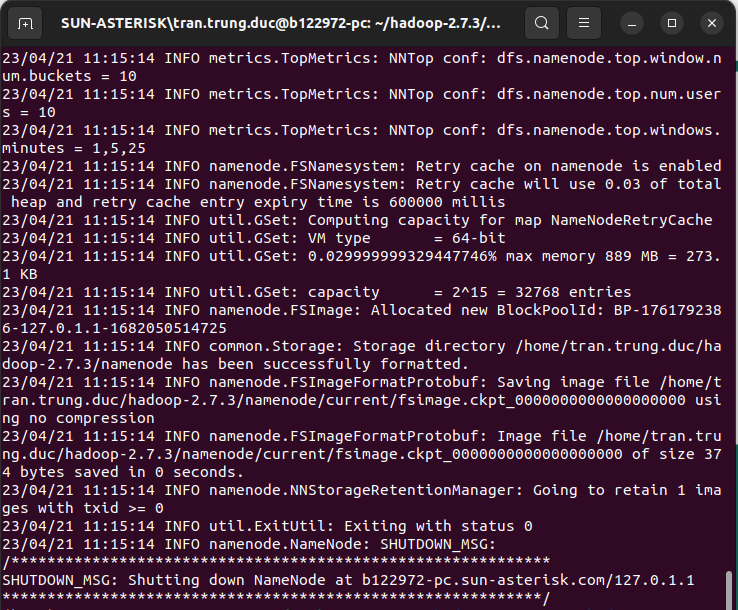
Bước 18: Khởi động các demons trên master node
- Tại master node:
cd $HADOOP_HOME
./sbin/start-all.sh
Kiểm tra các Nodes đã hoạt động hay chưa
- Sử dụng lệnh
jpsđể kiểm tra xem các node đã hoạt động hay chưa

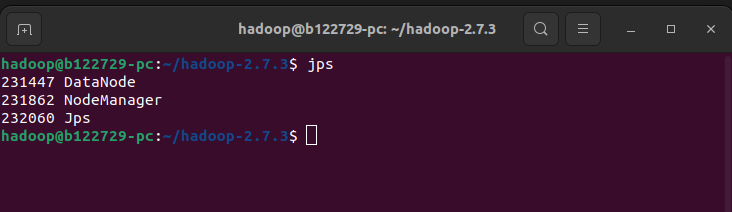
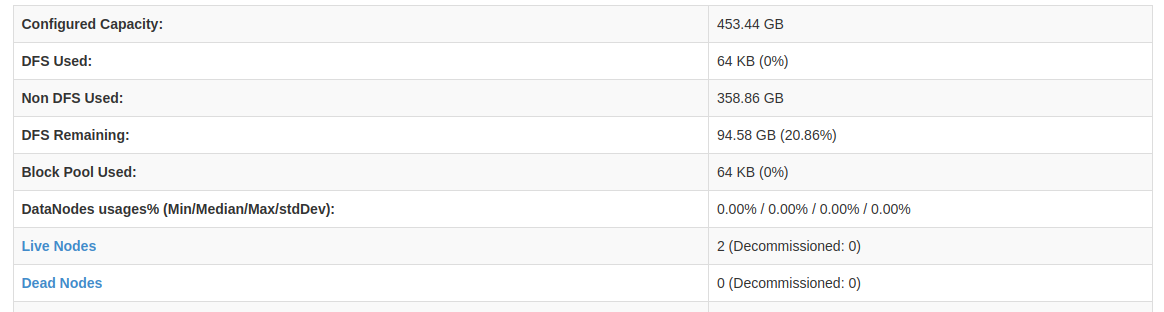
- Hoặc các bạn có thể check trên url http://master:50070/dfshealth.html và đảm bảo live node có giá trị 2
Một số lỗi mình gặp phải và cách khắc phục
- JAVA_HOME is not set: Thêm dòng sau
JAVA_HOME="/home/<<user_name>>/jdk1.8.0_371"vào file/etc/environmenttrên tất cả các nodes sau đó chạy lệnhsource /etc/environment

-
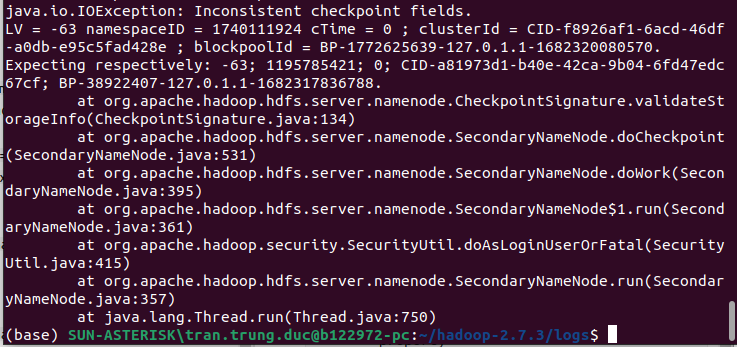
Check bằng
jpskhông thấy có node nào đang chạy: check logs trong$HADOOP_HOME/logsđể biết có lỗi ở đâu (datanode, namenode, hdfs hay yarn)![image.png]()
-
Ngoài ra nếu có lỗi nào, các bạn có thể comment bên dưới nhé ^^
Tài liệu tham khảo
All rights reserved
