Cùng mình xây dựng một kiến trúc phần mềm
Bài đăng này đã không được cập nhật trong 2 năm
Chúc anh em năm mới an khang thịnh vượng, chúc cộng đồng Viblo Community ngày càng lớn mạnh hơn nữa!
Tổng quan
Ý tưởng
TL;DR: triển khai hệ thống tổng hợp tin tức tiếng Việt từ nhiều nguồn và cho phép người dùng tìm kiếm những tin tức đó.
Ý tưởng ban đầu là sẽ xây dựng một hệ thống tổng hơp và tin tức từ nhiều nguồn báo tiếng Việt khác nhau. Bộ Thông tin và Truyền Thông vào năm 2015, ở nước ta có hơn 207 trang thông tin điện tử tổng hợp của các cơ quan báo chí. Vì thế việc triển khai được hệ thống tìm kiếm tin tức cụ thể trong phạm vi hẹp của tin tức từ nhiều nguồn báo khác nhau cũng là 1 ý tưởng thú vị.
Hơn thế nữa, những bài báo này còn là nguồn dữ liệu tốt có thể từ đó ngoại suy ra các thống kê thú vị về một nguồn báo, một tờ báo nào đó.
Hình 1: Một số trang báo điện tử trong nước. Nguồn: Wikipedia
Ước lượng
Sau khi chạy thử một số thống kê ban đầu thì với 6 chủ đề (Tin tức, Kinh doanh, Giải trí, Thể thao, Công nghệ và Du lịch) từ 3 nguồn báo (VnExpress, Tuổi Trẻ, Người Lao Động) ta sẽ cần crawl mới khoảng 160-230 bài viết. Ta tạm chia đơn giản với 6 chủ đề cơ bản, mỗi nguồn báo sẽ có 55-75 bài viết mới mỗi ngày.
Sau khi thực hiện crawl, hệ thống sẽ match những bài viết tương tự nhau trong cùng chủ đề sử dụng mô hình Máy học Doc2Vec. Sau vài quá trình chạy thử ban đầu, với mỗi chủ đề, hệ thống sẽ cần từ 60-90s để hoàn thành việc matching.
Tiêu chí
TL;DR: Kết quả tìm kiếm cần phải trả về nhanh, liên quan cao. Hệ thống cần có khả năng mở rộng và khả dụng cao
Trước khi đến với kiến trúc, ta cần đặt ra một số tiêu chí mục tiêu xoay quanh việc nâng cao trải nghiệm tìm kiếm tin tức của người dùng và cùng với nâng cao tính hiệu quả của nhóm phát triển trong việc xây dựng hệ thống:
-
Nhanh: người dùng sẽ gõ từ khoá và kết quả tìm kiếm phải trả về đủ nhanh. Thế nào là đủ nhanh? Ta có thể tham khảo biểu đồ bên dưới được trích từ redisconf 2018. Lí tưởng nhất là rơi vào khoảng 50-500ms.
![Hình 2: Đánh giá thời gian phản hồi của việc tìm kiếm. Nguồn: redisconf 2018]()
Hình 2: Đánh giá thời gian phản hồi của việc tìm kiếm. Nguồn: redisconf 2018 -
Độ liên quan: kết quả trả về cần thể hiện độ liên quan với từ khoá và có thể định lượng được.
-
Có khả năng sắp xếp: kết quả tìm kiếm cần có thể được sắp xếp theo một hoặc nhiều thứ tự xác định.
-
Khả năng mở rộng: hệ thống cần đảm bảo hoạt động ổn định khi lưu lượng truy cập tăng đột biến.
-
Tính khả dụng cao (highly availability): cần đảm bảo việc sử dụng của người dùng vẫn hoạt động bình thường ngay cả hệ thống đang thực hiện các tác vụ nặng hoặc một phần của hệ thống dừng hoạt động.

Ngoài ra, ta cần cân nhắc một số tiêu chí khác như Tính mềm dẻo (Flexibility), Tính dễ bảo trì (Maintainability) để dễ dàng thêm bớt các tính năng mới cũng như bảo trì các tính năng hiện tại của hệ thống. Tuy nhiên, trong giai đoạn đầu phát triển kiến trúc, ta sẽ tập trung giải quyết các tiêu chí quan trọng đã đề cập trước hơn.
Kiến trúc ban đầu
TL;DR: Kiến trúc ban đầu gồm 2 phần chính: Crawler Service - thực hiện tác vụ crawl và lưu các bài viết, Articles Service - xử lí các yêu cầu tìm kiếm từ người dùng.
Ta triển khai hệ thống gồm 2 thành phần chính:
- Crawler Service: thành phần này sẽ chịu trách nhiệm chính trong việc “crawl” thu thập dữ liệu từ các nguồn báo khác nhau và lưu lại trong cơ sở dữ liệu.
- Articles Service: thành phần này sẽ chịu trách nhiệm giao tiếp, xử lí các yêu cầu tìm kiếm từ người dùng.
- Vì các bài viết được lưu độc lập cũng như ít cần ràng buộc dữ liệu và query phức tạp. Cơ sở dữ liệu NoSQL sẽ là lựa chọn ưu tiên, cụ thể là Firestore.
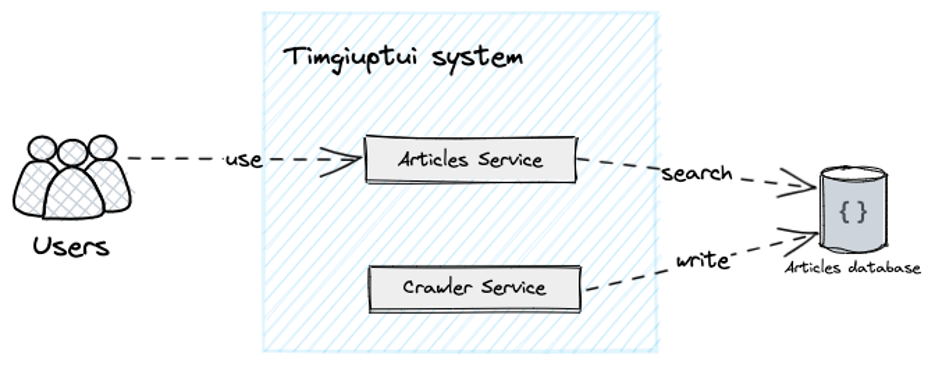
Hình 3: Kiến trúc ban đầu.
Crawler Service
Vào những thời điểm xác định trong ngày, Crawler Service sẽ tiến hành thu thập các bài viết từ các nguồn báo thông qua RSS links.

Hình 4: Lưu nguồn báo.
Sau khi đã crawl toàn bộ bài viết, ta sẽ tiến hành match các bài viết tương tự lại với nhau sử dụng mô hình Doc2Vec. Với mỗi chủ đề, hệ thống lần lượt tạo 1 mô hình Doc2Vec. Từ mô hình đã tạo, hệ thống duyệt qua từng bài viết, mỗi bài viết mô hình sẽ infer ra cho ta 1 vector rồi trả về 10 bài viết tương tự cao nhất với bài viết đang xét cùng với “tỉ lệ liên quan”. Để đảm bảo kết quả thực sự đúng, ta xét ngưỡng là 85% (0.85) và loại bỏ các bài dưới ngưỡng khỏi kết quả.

Hình 5: Match bài viết tương tự nhau.
Cuối cùng ta sẽ lưu bài viết vào dưới dạng 1 document trong cơ sở dữ liệu với cấu trúc cơ bản như sau:

Hình 6: Cấu trúc cơ bản bài viết.
Thêm một điều lưu ý, cấu trúc HTML bài viết của từng trang tin tức sẽ có khả năng thay đổi liên tục, Crawler Service sẽ cần phải liên tục được cập nhật để có thể crawl được và crawl chính xác nội dung của bài viết.
Articles Service
Ngoài việc đọc thông tin cụ thể của 1 bài viết thông qua id. Chức năng chính của service này là tìm kiếm. Nếu chỉ đơn thuần dữ liệu dưới database, ta rất khó triển khai các tính năng tìm kiếm cho service này.
Một hướng tiếp cận đơn giản là ta có thể bắt chước câu query LIKE (như trong sql database) thông qua một số triển khai không chính thống (?). Bởi vì hướng tiếp cận này sẽ chậm hơn các câu query truyền thống từ 6-8 lần. Về lâu dài, đây sẽ không phải là hướng tiếp cận phù hợp để đảm bảo yếu tố nhanh, cụ thể là đáp ứng thời gian phản hồi nằm trong khoảng 50-500ms như đã đặt ra ở phần tiêu chí.
Vấn đề và giải pháp
Từ kiến trúc ban đầu, ta sẽ nhận thấy một số vấn đề có thể giải quyết để thoả mãn tiêu chi đặt ra. Các phần ngay sau đây sẽ lần lượt đi qua các vấn đề và giải pháp của nó.
Build time của Crawler Service
1. Đặt vấn đề
Crawler Service sẽ có thực hiện 2 phần chính:
- Crawl: phần này sẽ được cập nhật tương đối nhiều để có thể crawl thêm nguồn báo mới hoặc chỉnh sửa lại các spider cũ cho phù hợp khi nguồn báo thay đổi cấu trúc bài báo của họ. Nhưng bù lại tương đối nhanh và nhẹ để build.
- Handle: phần này sẽ chạy sau quá trình crawl, có nhiệm vụ xử lí, match các bài viết tương tự nhau rồi sau đó lưu vào cơ sở dữ liệu. Tuy phần này sẽ không cần phải cập nhật nhiều, nhưng sẽ cần sử dụng một số thư viện NLP nặng (underthesea, gensim, nltk), cũng như preload trước một số dữ liệu (stopwords, model configs) nên làm tăng build time khá nhiều.
Từ đó, tổng cộng build time của Crawler Service vào khoảng 24 phút. Con số này có vẻ vẫn chấp nhận được.
Tuy nhiên với việc cần phải cập nhật liên tục để phục vụ việc crawl trong giai đoạn đầu, con số này sẽ tăng nhanh chóng. Ta nhẩm ước lượng sẽ build lại 4-5 lần/ngày để cập nhật cho quá trình crawl và khỏang 1-2 lần/ngày cho quá trình handle. Tổng cộng Crawler Service thì sẽ tốn 125-150 phút buid time trong 1 ngày.
Với những thay đổi cho crawl, ta mong đợi nó cần phải nhanh chóng được triển khai để áp dụng vào lần crawl kế tiếp. Cũng như việc crawl sẽ không phải sử dụng bất kì thư viện, tài nguyên quá nặng nào có thể làm tăng build time.
2. Hướng giải quyết
Do quá trình handle không cần thiết phải cập nhật liên tục mà lại tăng build time lên rất nhiều. Ta có thể giải quyết bằng cách tách handle ra khỏi Crawler Service.
Ta sẽ có tách thành 2 services:
- Crawler Service: chỉ chịu trách nhiệm việc crawl bài viết, sau đó sẽ gửi những bài viết này cho Handler Service xử lí.
- Handler Service: nhận các bài viết từ Crawler Service, sau đó xử lí và lưu chúng vào cơ sở dữ liệu.
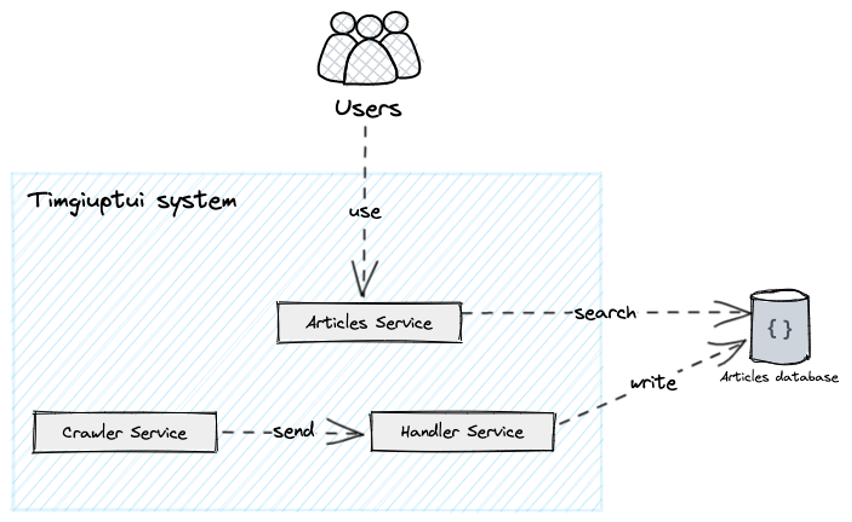
Hình 7: Giải quyết vấn đề build time của Crawler Service.
Với việc tách ra riêng ta còn có thể tối ưu hoá Crawler Service hơn nữa bằng cách sử dụng 1 image docker gọn nhẹ, phù hợp với yêu cầu hơn thay vì 1 docker image đầy đủ để phục vụ cho cả quá trình handle.
3. Kết quả
Build time của Crawler Service chỉ còn vào khoảng 2,5 phút.

Hình 8: Build time của Crawler sau khi tách quá trình “handle” ra thành Handler Service.
Tương tự build time của Handler Service là vào khoảng 15-20 phút. Ta chọn mốc trung bình 18 phút và lập bảng so sánh tương đối như sau:
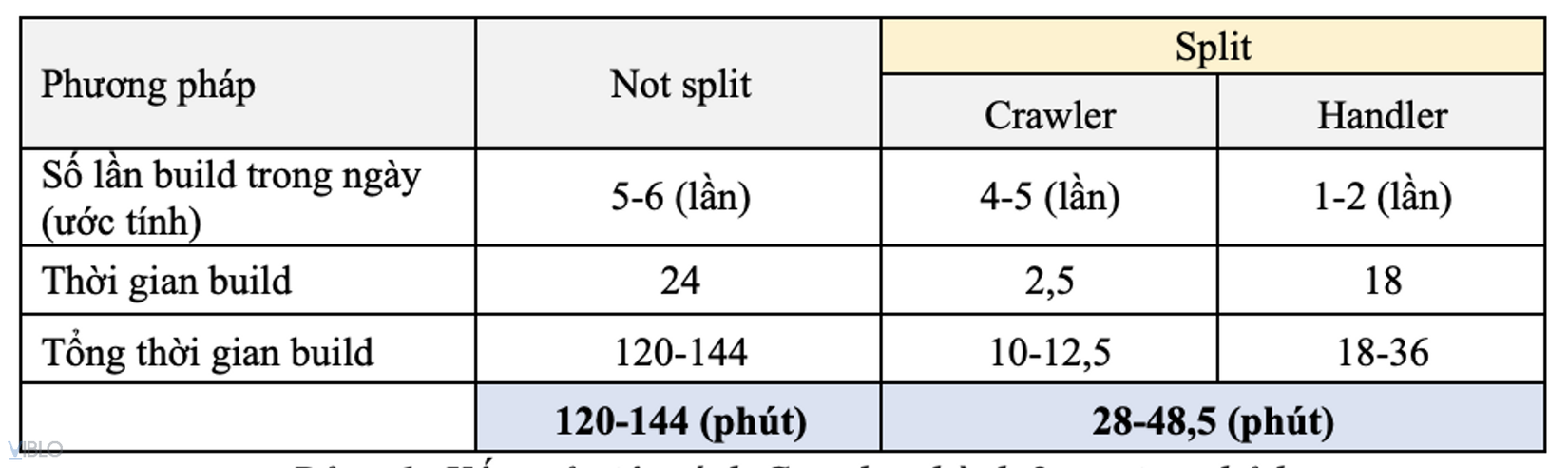
Hình 9: Kết quả việc tách Crawler thành 2 service nhỏ hơn.
Từ bảng trên, trong trường hợp tốt nhất tổng build time giảm đi 4 lần và ít nhất là 3 lần. Hơn nữa, việc tách ra còn tăng tốc thời gian phát triển Crawler Service do không còn bị block bởi build time dài.
Tối ưu tìm kiếm
1. Đặt vấn đề
Tìm kiếm là chức năng chính của phần mềm chúng ta. Cần phải mang lại trải nghiệm tìm kiếm nhanh chóng và tuyệt vời cho người dùng. Chúng ta sẽ cần phải triển khai:
- Auto-complete đối với trang home: người dùng gõ và hệ thống sẽ tự động gợi ý các tiêu đề bài viết ngay bên dưới thành tìm kiếm.
- Full-text search đối với trang search: người dùng sẽ gõ và hệ thống sẽ tự động trả về các bài viết mà trong tiêu đề hoặc mô tả của bài viết có chứa từ khoá hoặc từ gần giống từ khoá.
Trong cả 2 triển khai, chúng ta cần đảm bảo thời gian phản hồi nằm trong 50-500ms.
Đầu tiên chúng ta sẽ thử query trực tiếp vào database:
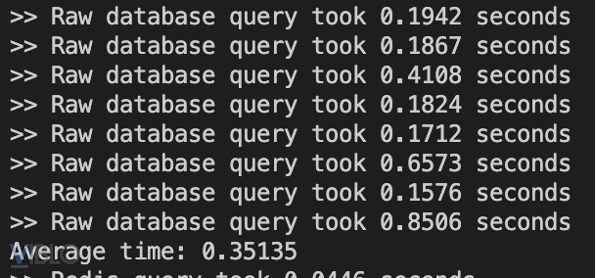
Hình 10: Thời gian xử lí khi trực tiếp query database.
Ở cách tiếp cận này ta sẽ thấy một số vấn đề như sau:
- Thời gian xử lí trung bình chưa thật sự tốt vì khi kết hợp vào API, thời gian phản hồi khả năng cao sẽ >500ms
- Thời gian xử lí không ổn định, dao động lớn (từ 0,17- 0,85s)
- Hầu hết NoSQL database tính phí operations-based
2. Hướng giải quyết
Chúng ta có thể sử dụng Redis, cụ thể là Redis Search để giải quyết vấn đề này.
Với bài toán auto-complete, chúng ta có thể sử dụng câu lệnh FT.SUGGEST. Chúng ta sẽ thêm Redis vào kiến trúc hiện tại: khi Handler Service thêm bài viết vào cơ sở dữ liệu thì đồng thời thêm tiêu đề bài viết đó thành 1 suggestion vào Redis. Ở phía bên dưới, Redis sử dụng cấu trúc Trie nên thời gian truy xuất là O(1) rất nhanh và giữ được độ ổn định.
Nhưng FT.SUGGEST chỉ hỗ trợ prefix, như thế có nghĩa mình sẽ không tìm kiếm được khi từ khoá nằm ờ cuối câu. Chúng ta có thể giải quyết bằng full-text search.
Để triển khai full-text search, chúng ta thực hiện 2 bước:
- Tạo index cho các trường sẽ áp dụng full-text search. Ở đây chúng ta sẽ tìm kiếm trên cả tiêu đề (title) và mô tả (description) của bài viết, đồng thời cần khả năng lọc theo chủ đề (topics), nguồn báo (souces) và có thể sắp xếp theo ngày đăng (date). Chúng ta cũng sẽ ưu tiên các kết quả mà từ khoá nằm ở tiêu đề (title) hơn là các kết quả từ khoá chỉ nằm ở mô tả (desciption).

Hình 11: Cấu trúc index ‘articles’.
- Với mỗi bài viết, chúng ta sẽ thêm một record vào Redis và tự động đánh index dựa trên cấu trúc index đã được định nghĩa ở bước 1.
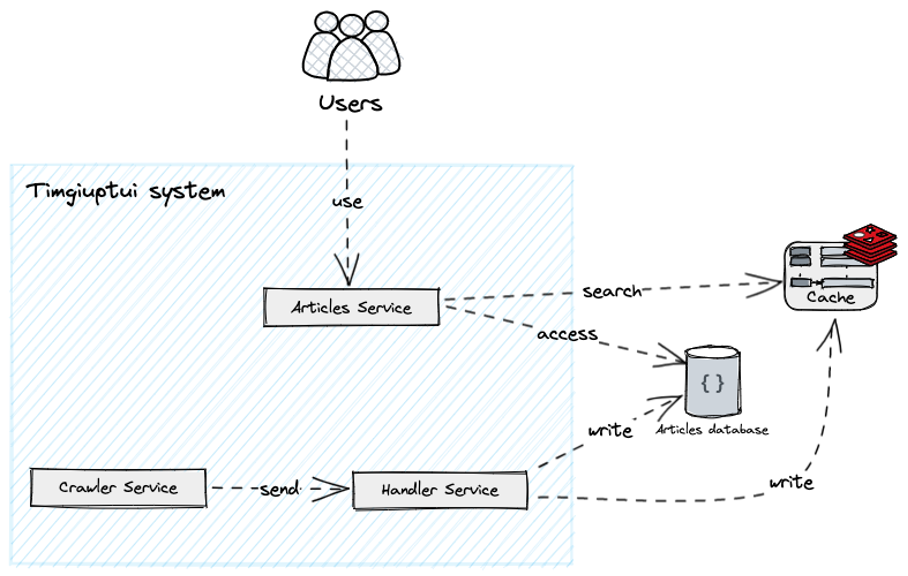
Hình 12: Kiến trúc sau khi thêm Redis.
3. Kết quả
Chúng ta triển khai chạy thử và có kết quả như sau khi sử dụng Redis Search:
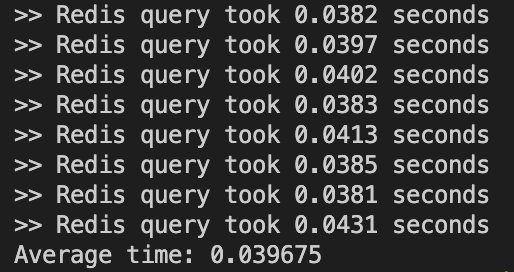
Hình 13: Thời gian xử lí query khi sử dụng Redis.
Về thời gian xử lí, kết quả cho thấy thời gian xử lí nhanh hơn 8-9 lần.
Về độ ổn định, kết quả với 10 lần query liên tiếp nhau đều cho ta thời gian xử lí ổn định ở quanh khoảng 40ms.
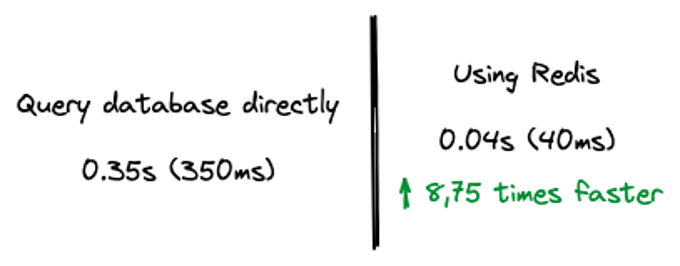
Hình 14: So sánh thời gian phản hồi giữa truy xuất database trực tiếp và việc sử dụng Redis.
Giao tiếp giữa các services
1. Đặt vấn đề
Hiện tại, các service trong hệ thống đang giao tiếp trực tiếp với nhau. Tuy nhiên điều này có một số bất lợi như sau:
- Không có cơ chế retry: hoặc việc tự triển khai cơ chế này trên từng service là tương đối phức tạp
- Dễ có sự giao tiếp chồng chéo giữa các service
- Rất khó quản lí và bảo trì khi hệ thống ngày càng mở rộng
- Khi trực tiếp giao tiếp, chúng ta cần phải thủ công thiết lập hệ thống để xác thực giữa những service với nhau.
2. Hướng giải quyết
Với việc giao tiếp giữa các server là event-based (Event-driven Architecture). Chúng ta sẽ triển khai một Event Broker (trong hệ thống sẽ tạm gọi là Event Handler), nó như là cầu nối trung gian cho việc giao tiếp giữa những server nội bộ của hệ thống.
Chúng ta sẽ có kiến trúc mới như sau:
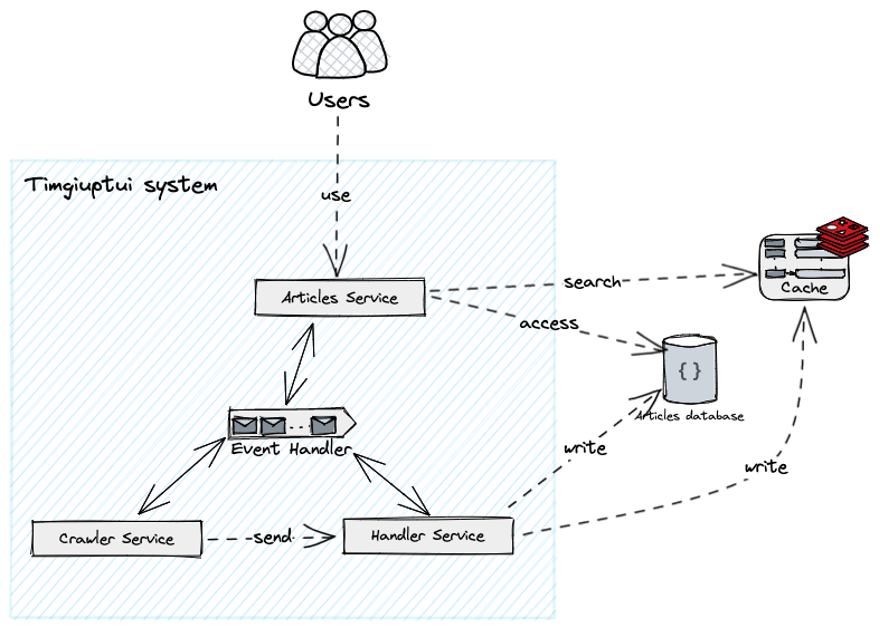
Hình 15: Thêm Event Broker (Handler) vào hệ thống.
3. Kết quả
Sau khi triển khai vào hệ thống, Event Broker giúp hệ thống:
- Có thêm cơ chế retry và “có thể kiểm soát được”
- Giảm sự giao tiếp chồng chéo, dễ quản lí và theo dõi cách event trong hệ thống
- Không cần thiết lập cơ chế xác thực ở từng service mà sẽ tập trung nằm ở Event Broker
Hình 16: Thiết lập Event Broker.
Kết luận
Kiến trúc hoàn chỉnh
Kiến trúc cuối cùng của toàn bộ hệ thống:
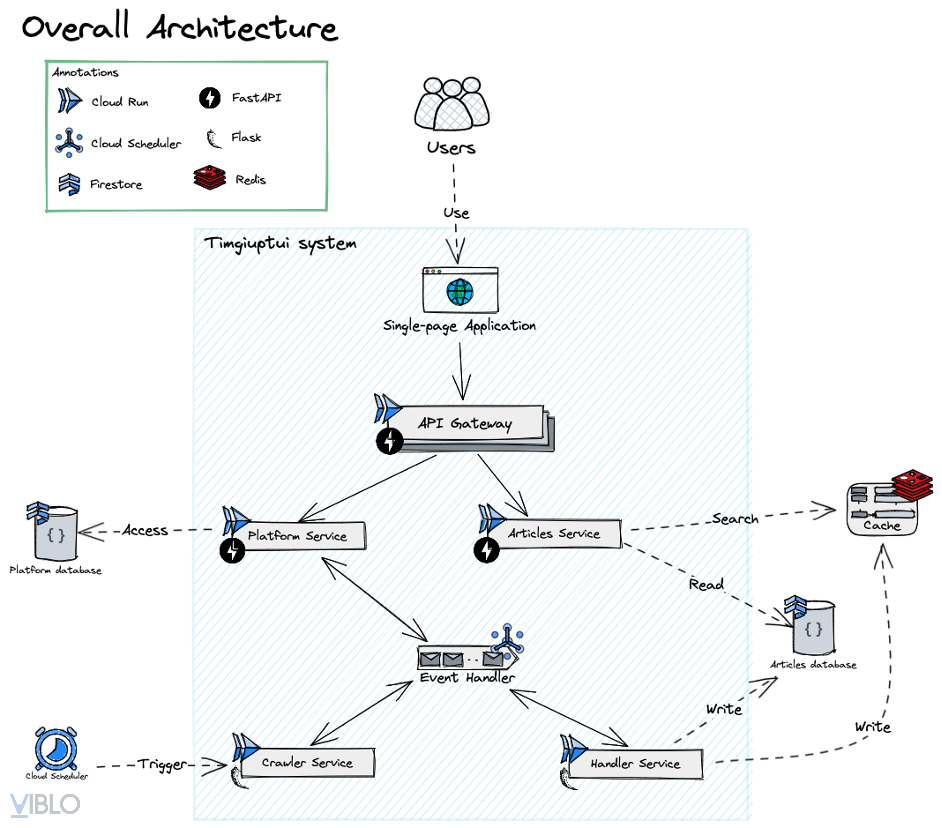
Hình 17: Kiến trúc hoàn chỉnh.
Các server sẽ được deploy lên Cloud Run. Event Broker (Event Handler) sẽ sử dụng Cloud Pub/Sub.
Các service nội bộ sẽ sử dụng framework Flask, các server public sẽ sử dụng framework FastAPI.
Ngoài ra, hệ thống sẽ sử dụng Cloud Scheduler cho tác vụ đặt lịch chạy Crawler Service. Thêm vào đó là Platform Service sẽ được tách riêng ra để quản lí các config của hệ thống (nguồn crawl, các chủ đề, các nguồn báo, thời gian crawl…). Cùng với đó là 1 API Gateway đơn giản để chuẩn hoá và tập trung hoá cách client sẽ giao tiếp với hệ thống.
Cuối cùng, một luồng crawl sẽ lần lượt chạy như sau:
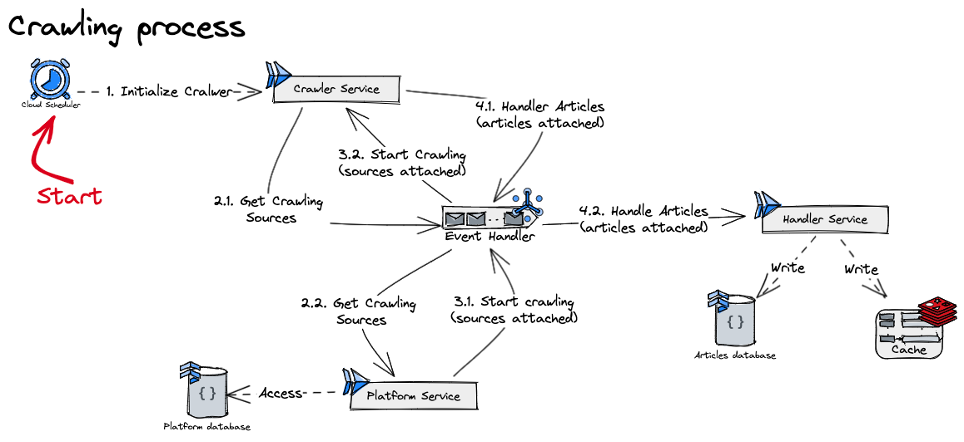
Hình 18: Quá trình crawl.
Nhận xét
Ưu điểm
- Thời gian tìm kiếm phản hồi rất nhanh (<200ms), có thể xếp hạng và đánh giá được kết quả trả về.
- Kiến trúc đáp ứng được khả năng mở rộng (scalability), tính khả dụng (availability) và tính mềm dẻo (flexibility).
- Mỗi service đều khá nhỏ và có 1 chức năng cụ thể, tương đối dễ bảo trì.
Nhược điểm
- Tuy mỗi service đều nhỏ, đơn giản nhưng tổng thể độ phức tạp của toàn bộ kiến trúc sẽ tăng lên.
- Các bài viết không được cập nhật real-time, sẽ có khoảng thời gian chậm trễ giữa các lần Scheduler hoạt động (tối đa khoảng 6 tiếng trễ).
Hướng phát triển
- Mở rộng hỗ trợ nhiều chủ đề, nhiều nguồn báo hơn.
- Triển khai thống kê trên lượng dữ liệu khá mà hệ thống thu thập được.
- Triển khai việc theo dõi, chuẩn đoán hệ thống để giảm thiểu tối đa sự cố.
Demo
Web demo: timgiuptui.com
API demo: api.timgiuptui.com/docs
Source code: Github
Tài liệu tham khảo
[1] Chris Richardson. (2023) What is microservices? Đường dẫn: https://microservices.io/.
[2 Bass, L., Clements, P. and Kazman, R. (2013). Software Architecture in Practice. Upper Saddle River (N.J.): Addison-Wesley.
[3] Google. (2023) Microservices Architecture on Google App Engine. Đường dẫn: https://cloud.google.com/appengine/docs/legacy/standard/python/microservices-on-app-engine.
[4] Google.(2022) Cloud Computing Services | Google Cloud. Đường dẫn: https://cloud.google.com/.
[5] Redis. (2022) Documentation | Redis. Đường dẫn: https://redis.io/docs/.
[6] Youtube. (n.d.). Amazing User Experiences with Redis and RediSearch. Đường dẫn: https://www.youtube.com/watch?v=B_BVmJ90X8Q.
[7] redis-py.readthedocs.io. (n.d.). redis-py dev documentation. Đường dẫn: https://redis-py.readthedocs.io/en/stable/.
)
All rights reserved
