Cùng đi học Machine Learning - Phần 2 - Machine Learning Algorithms
Bài đăng này đã không được cập nhật trong 4 năm
Mở đầu
Chào tất cả mọi người, chúng ta lại gặp nhau trong bài phần tiếp theo của seri "Cùng đi học Machine Learning". Ở phần trước, sau khi chúng ta đã "cưỡi ngựa xem hoa" về khái niệm Machine Learning thì chắc các bạn cũng đã tìm đọc vài bài viết, sách... về ML. Và chắc hẳn các bạn cũng dễ nhận ra là cuốn sách nào sau chương giới thiệu thì các chương tiếp theo sẽ là những thuật toán (algorithms), mà mỗi cuốn thì đề cập đến vài loại khác nhau, và khi tổng hợp lại chúng ta có khoảng 40 thuật toán như thế này 😱

Rất may mắn là chúng ta không cần phải học hết toàn bộ cái đống này mới có thể nghiên cứu ML, nhưng chúng ta vẫn nên biết chúng tồn tại ngoài kia, biết đâu 1 ngày nào đó sẽ cần tới. Còn trong nội dung bài viết ngày hôm nay chúng ta sẽ chỉ đề cập tới 1 số thuật toán phổ biến mà thôi.
Có hai cách phổ biến phân nhóm các thuật toán Machine learning:
- Một là dựa trên phương thức học (learning style).
- Hai là dựa trên sự tương tự giữa chức năng (function) của mỗi thuật toán.
Phân nhóm dựa trên phương thức học
Theo phương thức học, các thuật toán Machine Learning thường được chia làm 4 nhóm:
- Supervised learning (Học có giám sát)
- Unsupervised learning (Học không giám sát)
- Semi-supervised lerning (Học bán giám sát)
- Reinforcement learning (Học Củng Cố)
Trong một số tài liệu không đề cập đến Semi-supervised learning hoặc Reinforcement learning trong cách phân nhóm này.
Supervised learning
Trước khi định nghĩa Supervise learning chúng ta sẽ cùng xem xét ví dụ sau. Giả sử chúng ta muốn dự đoán giá nhà ở, và chúng ta có một tập dữ liệu về giá cả theo diện tích được biểu diễn như biểu đồ dưới đây:
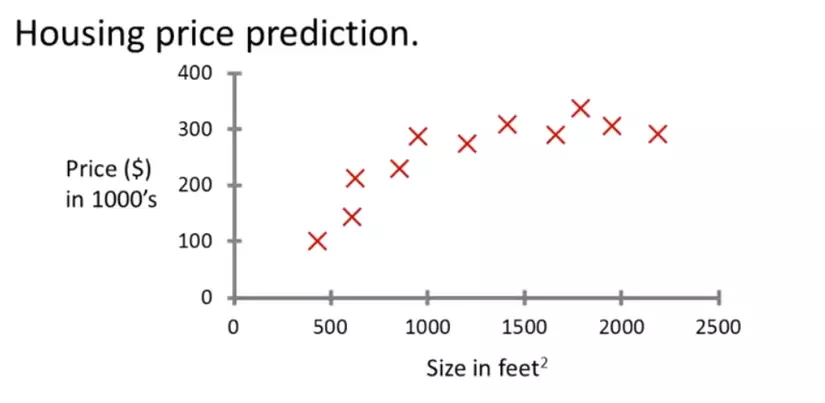 Với biểu đồ trên, làm sao chúng ta có thể dự đoán được giá của 1 ngôi nhà có diện tích 750 feet2 ? Dựa vào các dữ liệu đã thu thập được chúng ta có thể vẽ một đồ thị biểu diễn mối quan hệ giữa giá nhà - diện tích.
Với biểu đồ trên, làm sao chúng ta có thể dự đoán được giá của 1 ngôi nhà có diện tích 750 feet2 ? Dựa vào các dữ liệu đã thu thập được chúng ta có thể vẽ một đồ thị biểu diễn mối quan hệ giữa giá nhà - diện tích.
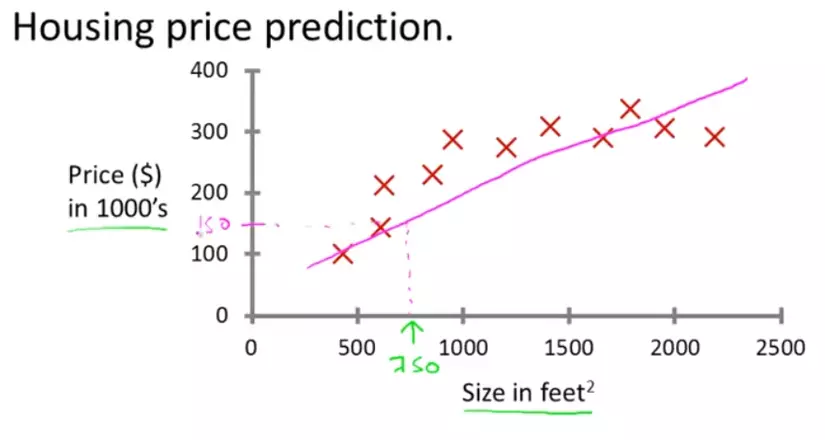 Trong trường hợp này, giả sử đồ thị đó là 1 đường thẳng dạng y = ax + b chẳng hạn, từ đó ta có thể thấy giá của ngôi nhà có thể rơi vào khoảng $150000.
Trong trường hợp này, giả sử đồ thị đó là 1 đường thẳng dạng y = ax + b chẳng hạn, từ đó ta có thể thấy giá của ngôi nhà có thể rơi vào khoảng $150000.
Trong ví dụ trên, bằng việc biết chính xác giá của một số ngôi nhà dựa trên diện tích, chúng ta đã tìm ra được hàm quan hệ y = ax + b, công việc này chính là Supervised Learning. Trong Supervised Learning chúng ta có 1 tập các giá trị input (x) và tập các giá trị output (y) tương ứng với x, bằng các thuật toán (algorithms) chúng ta tìm ra mối quan hệ y = f(x) và mục tiêu là tìm hàm f tốt nhất để khi có 1 giá trị x mới chúng ta có thể dự đoán được y.
Supervised learning là thuật toán dự đoán đầu ra (output) của một dữ liệu mới (new input) dựa trên các cặp (input, output) đã biết từ trước
Thuật toán này được gọi là Học tập có giám sát bởi vì quá trình của một thuật toán học từ tập dữ liệu huấn luyện có thể được coi là một giáo viên giám sát quá trình học tập. Chúng ta biết câu trả lời chính xác, thuật toán lặp đi lặp lại tạo ra những dự đoán về dữ liệu huấn luyện và được giáo viên đánh giá sửa chữa.
Thuật toán supervised learning còn được tiếp tục chia nhỏ ra thành hai loại:
- Regression (hồi quy): giá trị của output cần dự đoán là các giá trị thực và liên tục, ví dụ như giá tiền, cân nặng, số lượng... Ví dụ trên chính là 1 bài toán Regression.
- Classification (phân loại): giá trị của output cần dự đoán là các giá trị rời rạc, ví dụ như màu sắc, đúng/sai... Ví dụ về việc phân loại spam/non-spam email là 1 bài toán Classification.
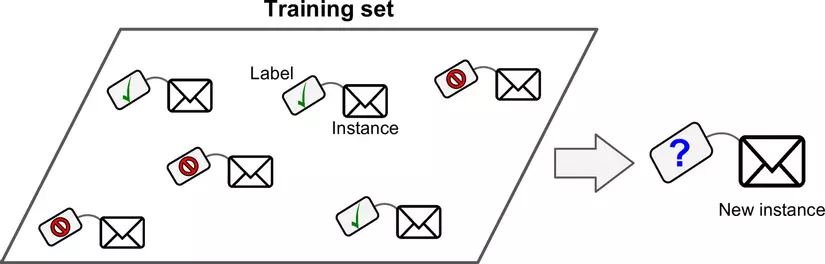
Một vài giải thuật phổ biến trong Supervised Learning:
- Regression: Linear Regression, Logistic Regression
- Classification: k-Nearest Neighbors
Unsupervised Learning
Ở các ví dụ của Supervised learning, chúng ta được cung cấp input đã có sẵn output chính xác hoặc đã được gắn nhãn (label). Tuy nhiên trong Unsupervised Learning, chúng ta được cung cấp những dữ liệu không có output cụ thể, cùng label hoặc hoàn toàn không có label.
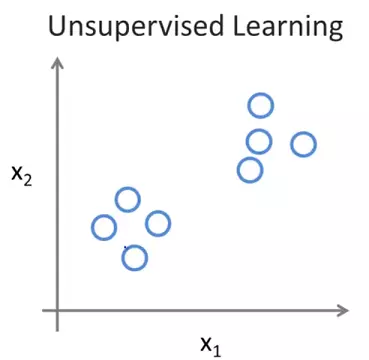 Đông thời mục tiêu của chúng ta cũng không phải đi tìm output chính xác nào đó, mà thay vào đó sẽ hướng tới việc tìm ra cấu trúc, sự liên hệ dữ liệu trong data set để thực hiện 1 công việc nào đó.
Đông thời mục tiêu của chúng ta cũng không phải đi tìm output chính xác nào đó, mà thay vào đó sẽ hướng tới việc tìm ra cấu trúc, sự liên hệ dữ liệu trong data set để thực hiện 1 công việc nào đó.
Thuật toán này được gọi là Học tập không giám sát bởi vì chúng ta chỉ biết dữ liệu đầu vào, không có output chính xác để đánh giá, giống như như khi học không có giáo viên chỉ dẫn.
Unsupervised Learning Algorithm cũng được chia thành hai loại:
- Clustering (phân nhóm): hướng đến việc phân nhóm, phân đoạn dữ liệu từ tập dữ liệu ban đầu. Ví dụ phân nhóm khách hàng theo độ tuổi, giới tính, hay đánh giá nhóm khách hàng tiềm năng dựa trên số liệu giao dịch...
- Association : hướng tới việc khám phá ra quy luật trong dataset. Ví dụ khách hàng mua mặt hàng A sẽ hay mua thêm mặt hàng B để xây dựng hệ thống recommend.
Một vài giải thuật phổ biến trong Unupervised Learning:
- Clustering: k-means
- Association: Apriori
Semi-Supervised Learning
Các bài toán khi chúng ta có một lượng lớn dữ liệu, nhưng chỉ một phần trong chúng được gán nhãn được gọi là Semi-Supervised Learning. Những bài toán thuộc nhóm này nằm giữa hai nhóm được nêu bên trên.
Một ví dụ điển hình của nhóm này là chỉ có một phần ảnh hoặc văn bản được gán nhãn (ví dụ bức ảnh về người, động vật hoặc các văn bản khoa học, chính trị) và phần lớn các bức ảnh/văn bản khác chưa được gán nhãn được thu thập từ internet. Thực tế cho thấy rất nhiều các bài toán Machine Learning thuộc vào nhóm này vì việc thu thập dữ liệu có nhãn tốn rất nhiều thời gian và có chi phí cao. Rất nhiều loại dữ liệu thậm chí cần phải có chuyên gia mới gán nhãn được (ảnh y học chẳng hạn). Ngược lại, dữ liệu chưa có nhãn có thể được thu thập với chi phí thấp từ internet.
Chúng ta có thể sử dụng unsupervised learning để khám phá và tìm hiểu cấu trúc trong các biến đầu vào.
Chúng ta cũng có thể sử dụng supervised learning để dự đoán cho dữ liệu không dán nhãn, sau đó đưa dữ liệu trở lại làm dữ liệu trainning cho supervised learning và sử dụng model sau khi đã được trainning để đưa ra dự đoán về dữ liệu mới.
Reinforcement Learning
Reinforcement learning là các bài toán giúp cho một hệ thống tự động xác định hành vi dựa trên hoàn cảnh để đạt được lợi ích cao nhất (maximizing the performance). Hiện tại, Reinforcement learning chủ yếu được áp dụng vào Lý Thuyết Trò Chơi (Game Theory), các thuật toán cần xác định nước đi tiếp theo để đạt được điểm số cao nhất.
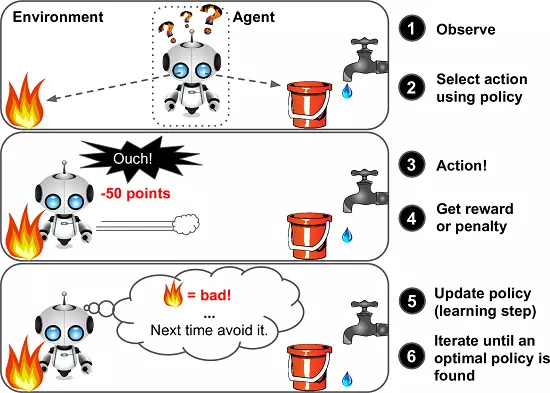
Một ví dụ nổi tiếng về Reinforcement Learning chính là AlphaGo.Về cơ bản, AlphaGo bao gồm các thuật toán thuộc cả Supervised learning và Reinforcement learning. Trong phần Supervised learning, dữ liệu từ các ván cờ do con người chơi với nhau được đưa vào để huấn luyện. Tuy nhiên, mục đích cuối cùng của AlphaGo không phải là chơi như con người mà phải thậm chí thắng cả con người. Vì vậy, sau khi học xong các ván cờ của con người, AlphaGo tự chơi với chính nó với hàng triệu ván chơi để tìm ra các nước đi mới tối ưu hơn. Thuật toán trong phần tự chơi này được xếp vào loại Reinforcement learning. (Xem thêm tại Google DeepMind’s AlphaGo: How it works).

Phân nhóm dựa trên sự tương tự giữa chức năng
Updating...
Nguồn
https://machinelearningmastery.com/supervised-and-unsupervised-machine-learning-algorithms/ https://machinelearningcoban.com/2016/12/27/categories/ https://www.coursera.org/learn/machine-learning http://www.allprogrammingtutorials.com/tutorials/introduction-to-machine-learning.php
All rights reserved
