
Cơ bản về fastai - Thư viện bậc cao cho Pytorch (P1)
Bài đăng này đã không được cập nhật trong 3 năm
Intro
Hello mọi người, một mùa Mayfest nữa lại tới nên mình quay lại viết bài và chủ đề của bài viết ngày hôm nay là về thư viện fastai.
Nếu như trong Tensorflow có Keras thì Pytorch cũng có một số thư viện bậc cao để việc phát triển mô hình học sâu nhanh chóng và thuận tiện hơn như Lightning, Ignite và fastai. Fastai được thiết kế xung quanh 2 mục tiêu chính: Dễ tiếp cận và có thể nhanh chóng phát triển mô hình cho các bài toán deep learning như classification, segmentation... thông qua API bậc cao cung cấp sẵn 1 số kỹ thuật SOTA của các bài toán. Bên cạnh đó, fastai cũng cung cấp các thành phần bậc thấp giúp các nhà nghiên cứu xây dựng và thử nghiệm những ý tưởng mới. Một số tính năng của fastai:
- Một thư viện computer vision được optimize để chạy trên GPU
- Refactor lại optimizer của Pytorch giúp người dùng có thể phát triển optimizer mới chỉ bằng vài dòng code
- Class Learner (gần giống Model trong Keras) làm wrapper cho mô hình và dataloader, quá trình train mô hình của Pytorch giờ được thay thế bằng 1 lệnh
.fit()giống Keras (rất phù hợp với những người lười viết training loop ^^) - Hệ thống callback cực mạnh cho Learner người dùng can thiệp vào mọi chỗ trong training loop như data, mô hình, optimizer, ...
Trong phần 1 này mình sẽ nói về 1 số chức năng cơ bản khá là "mì ăn liền" của fastai, một số khái niệm nâng cao hơn sẽ được đề cập trong phần sau nhé.
Cài đặt
Do là thư viện dựa trên pytorch nên khi cài fastai các bạn cần cài pytorch trước đó. Repo github của fastai được cập nhật khá thường xuyên nên gần như lúc nào cũng support pytorch version mới nhất. Tại thời điểm viết bài là fastai version 2.7.12 và pytorch 2.0.
Các bạn có thể cài đặt bằng câu lệnh pip quen thuộc:
pip install fastai
hoặc sử dụng conda:
conda install -c fastchan fastai
Nếu bạn code theo bằng google colab thì không cần làm gì cả vì colab đã cài sẵn rồi!
Train mô hình với fastai
Ở phần này, mình sẽ hướng dẫn các bạn dùng fastai để train mô hình cho 1 số bài toán kinh điển trong deep learning.
Image classification
Đầu tiên ta cần import fastai và các thư viện cần thiết:
from fastai.vision.all import *
Dòng code trên sẽ import toàn bộ những thứ cần thiết để làm computer vision trong fastai cũng như 1 số thư viện khác như numpy, pandas, matplotlib và torch.
Trong phần này, mình sẽ dùng bộ dữ liệu MNIST về chữ số viết tay (0 đến 9). Bộ dữ liệu gồm 60000 ảnh để train và 10000 ảnh để test mô hình. Để tải dữ liệu, các bạn chạy đoạn code dưới đây
path = untar_data(URLs.MNIST)
Ở trên, ta dùng hàm untar_data đầu vào là 1 url để tải xuống, giải nén bộ MNIST và trả về đường dẫn của dữ liệu vừa giải nén. Mọi người có thể kiểm tra class URLs hoặc vào đây để xem những dataset nào có sẵn trong fastai.
Để check trong thư mục dataset có gì, ta dùng
# tương đương os.path.listdir()
print(path.ls())
và thu được kết quả sau
[Path('/root/.fastai/data/mnist_png/testing'),Path('/root/.fastai/data/mnist_png/training')]
Trong mỗi thư mục training và testing là các thư mục con từ 0 đến 9 tương ứng với 10 class và trong mỗi thư mục là ảnh tương ứng với class đó.

Đến đây, nếu dùng Pytorch thường thì mọi người sẽ bắt đầu viết Dataset như thế này
class MNISTDataset(torch.utils.data.Dataset):
def __init__(self, ):
pass
def __getitem__(self, idx):
pass
sau đó tạo Dataloader trông khá là cồng kềnh. Còn trong fastai, để tạo nhanh chóng ta chỉ cần dùng:
dls = ImageDataLoaders.from_folder(path=path,
train='training',
valid='testing',
shuffle=True)
Do data của chúng ta được tổ chức theo kiểu label của ảnh là thư mục cha của nó nên ở đây ta dùng factory method from_folder của ImageDataLoaders để tạo load data. Giải thích 1 các tham số:
path: đường dẫn tới datatrain: tên thư mục chứa data trainvalid: tên thư mục chứa data validationshuffle: có shuffle data khi train không
Nếu data của bạn sắp xếp kiểu khác thì có thể tham khảo các factory method khác ở đây.
Đoạn code trên sẽ trả về 1 object Dataloaders. Nhìn vào thì mọi người có thể đoán ra object này để làm gì. Dataloaders là số nhiều của Dataloader, cụ thể hơn là 1 Dataloader cho tập train và 1 cho tập validation. Dataloader trong fastai gần như giống hệt trong Pytorch nhưng có thể một vài tiện ích như hỗ trợ visualize dữ liệu:
dls.train.show_batch()

Tiếp đến là training mô hình. Để train mô hình trong fastai, ta cần khởi tạo class Learner bằng cách truyền vào kiến trúc mô hình và dataloaders. Với các bài toán kinh điển như phân lớp, các bạn có thể tạo Learner bằng hàm vision_learner:
learner = vision_learner(dls,
arch=resnet18,
metrics=accuracy,
pretrained=True)
Các tham số
- Dataloaders
- Kiến trúc mạng, ở trên mình dùng resnet18 trong torchvision
- Metrics sử dụng
- Có dùng pretrain không? Nếu có thì load weight từ imagenet. Khi sử dùng mô hình pretrain, fastai sẽ tự thêm các 1 số lớp Linear ở cuối phần mô hình sao cho phù hợp
Ta có thể sử dụng learner.summary() để kiểm tra mô hình
Callback
Nếu các bạn để ý thì trong summary có đoạn Loss function: FlattenedLoss of CrossEntropyLoss() trong khi ta chưa set loss function ở chỗ nào cả. Nếu ta không truyền loss function vào Learner, thì fastai sẽ tự set loss function phù hợp dựa vào dataloader. Khá tiện đúng không nào!
Và cuối cùng để train mô hình ta chỉ cần gọi
learner.fit(3)
Dòng code trên sẽ train mô hình trong 3 epoch, và ta sẽ thu được kết quả dưới đây:
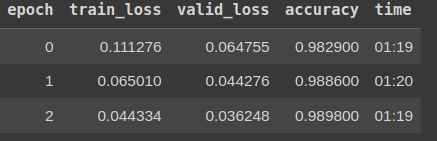
Toàn bộ code để train mô hình chỉ bao gồm 8 dòng code dưới đây
from fastai.vision.all import *
path = untar_data(URLs.MNIST)
dls = ImageDataLoaders.from_folder(path=path,
train='training',
valid='testing',
shuffle=True)
learner = vision_learner(dls, resnet18, metrics=accuracy)
learner.fit(3)
Sau khi train, ta có thể dùng learner.show_results() để visualize kết quả

Segmentation
Trong phần này mình sẽ dùng bộ dữ liệu Camvid về ảnh chụp từ camera trên ô tô. Về code thì không có thay đổi gì nhiều so với classification
path = untar_data(URLs.CAMVID)
codes = np.loadtxt(path/'codes.txt', dtype=str)
dls = SegmentationDataLoaders.from_label_func(
path, fnames = get_image_files(path/"images"),
label_func = lambda o: path/'labels'/f'{o.stem}_P{o.suffix}',
codes = codes
)
learner = unet_learner(dls, resnet18)
learner.fit(2)
Điểm khác biệt ở đây là thay vì dùng ImageDataLoaders, ta sử dụng SegmentationDataLoaders và factory method from_label_func
fnames: một list đường dẫn ảnh được trả về từ hàmget_image_filestrong fastailabel_func: một function nhận đầu vào là đường dẫn ảnh và trả về đường dẫn tới mask tương ứngcodes: mapping giữa class và số
[Animal', 'Archway', 'Bicyclist', 'Bridge', 'Building', 'Car',
'CartLuggagePram', 'Child', 'Column_Pole', 'Fence', 'LaneMkgsDriv',
'LaneMkgsNonDriv', 'Misc_Text', 'MotorcycleScooter', 'OtherMoving',
'ParkingBlock', 'Pedestrian', 'Road', 'RoadShoulder', 'Sidewalk',
'SignSymbol', 'Sky', 'SUVPickupTruck', 'TrafficCone',
'TrafficLight', 'Train', 'Tree', 'Truck_Bus', 'Tunnel',
'VegetationMisc', 'Void', 'Wall']
Vì do mạng CNN thông thường không sử dụng được cho task segmentation nên ta chuyển qua sử dụng unet_learner với backbone resnet18.
Và tương tự như lúc nãy, ta có thể visualize kết quả bằng learner.show_results

Text classification
Phần này mình sẽ sử dụng bộ data IMDB cho sentiment analysis. \
Như thường lệ, ta tải data xuống bằng untar_data
path = untar_data(URLs.IMDB)
Bộ IMDB cũng được tổ chức giống bộ MNIST với 2 class pos và neg trong các subfolder tương ứng
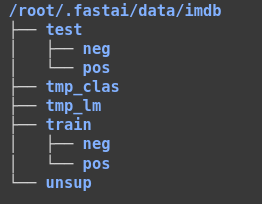
Do cấu trúc gần giống nên mọi người có đoán được ta sẽ load data như thế nào không nhỉ.
dls = TextDataLoaders.from_folder(path, train='train', valid='test')
Visualize bằng show_batch
 Để tạo Learner cho text classification ta chỉ cần dùng hàm
Để tạo Learner cho text classification ta chỉ cần dùng hàm text_classifier_learner và truyền vào dataloader và kiến trúc RNN, ở đây ta sử dụng AWD_LSTM
learner = text_classifier_learner(dls, AWD_LSTM, metrics=accuracy)
learner.fit(2)
Kết luận
Ở trên mình đã giới thiệu về một số tính năng cơ bản "mì ăn liền" của thư viện fastai. Về cơ bản thì với những gì đã giới thiệu ở trên thì thư viện này vẫn khá là tù nên ở phần sau mình sẽ hướng dẫn cách custom các thành phần của thư viện này. Mong các bạn tiếp tục ủng hộ. Cám ơn mọi người đã đọc bài viết.
Reference
All rights reserved
