Chương 5. Consumers: Unlocking Data - Kafka In Action Series
🔑 5.1 Consumer trong Kafka System
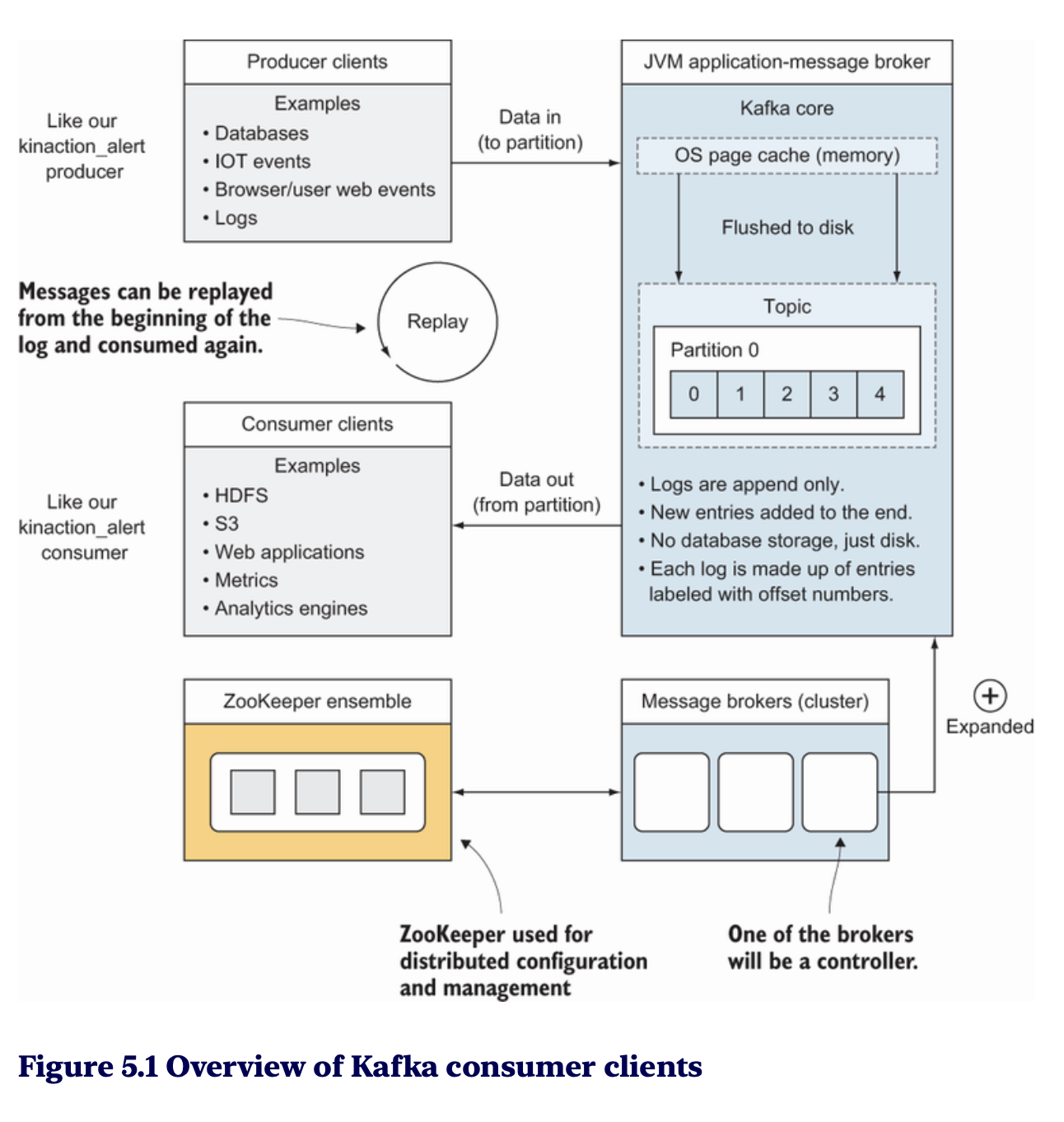
🔍 Consumer làm gì?
Trong Kafka, client (consumer) đóng vai trò quan trọng bằng cách:
- Đọc dữ liệu từ các topic: Lấy thông điệp từ log phân tán của Kafka.
- Cung cấp dữ liệu cho ứng dụng: Như bảng điều khiển (metrics dashboards) hoặc các công cụ phân tích.
- Lưu trữ dữ liệu vào hệ thống khác: Đảm bảo truy cập lâu dài hoặc xử lý thêm.
⏱ Kiểm soát tốc độ tiêu thụ
Consumer trong Kafka có lợi thế đặc biệt: kiểm soát tốc độ tiêu thụ dữ liệu. Điều này cho phép:
- Consumer quyết định lượng dữ liệu cần lấy và thời điểm lấy dữ liệu.
- Ứng dụng được thiết kế để xử lý tải thay đổi một cách hiệu quả, tránh bị quá tải.
5.1.1. Consumer Options:
- Sử dụng các deserializer phù hợp cho khóa và giá trị (ví dụ:
StringDeserializerhoặcLongDeserializer). - Đảm bảo các cấu hình như
bootstrap.servers,group.id, và các tham số timeout (heartbeat.interval.ms).
- Xử Lý Dữ Liệu Từ Topic:
- Poll dữ liệu từ topic
kinaction_promos. - Áp dụng công thức xử lý giá trị từ các sự kiện với magic number (ví dụ: nhân 1.543).
- Poll dữ liệu từ topic
📋 Bảng Cấu Hình Consumer (Bảng 5.1)
| Key | Mục Đích |
|---|---|
| bootstrap.servers | Một hoặc nhiều Kafka broker để kết nối khi khởi động client. |
| value.deserializer | Cần thiết để giải mã (deserialization) giá trị từ topic. |
| key.deserializer | Cần thiết để giải mã (deserialization) khóa từ topic. |
| group.id | Tên được sử dụng để tham gia một consumer group. |
| client.id | ID để xác định một người dùng (chương 10 sẽ sử dụng). |
| heartbeat.interval.ms | Khoảng thời gian giữa các lần consumer gửi tín hiệu (ping) đến group coordinator. |
🖥️ Code: Listing 5.1 - Consumer xử lý khuyến mãi
public class KinactionStopConsumer implements Runnable {
private final KafkaConsumer<String, String> consumer;
private final AtomicBoolean stopping =
new AtomicBoolean(false);
...
public KinactionStopConsumer(KafkaConsumer<String, String> consumer) {
this.consumer = consumer;
}
public void run() {
try {
consumer.subscribe(List.of("kinaction_promos"));
while (!stopping.get()) { ❶
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofMillis(250));
...
}
} catch (WakeupException e) { ❷
if (!stopping.get()) throw e;
} finally {
consumer.close(); ❸
}
}
public void shutdown() { ❹
stopping.set(true);
consumer.wakeup();
}
}
❶ The variable stopping determines whether to continue processing.
❷ The client shutdown hook triggers WakeupException.
❸ Stops the client and informs the broker of the shutdown
❹ Calls shutdown from a different thread to stop the client properly
5.1.2 Hiểu rõ về Offset trong Kafka
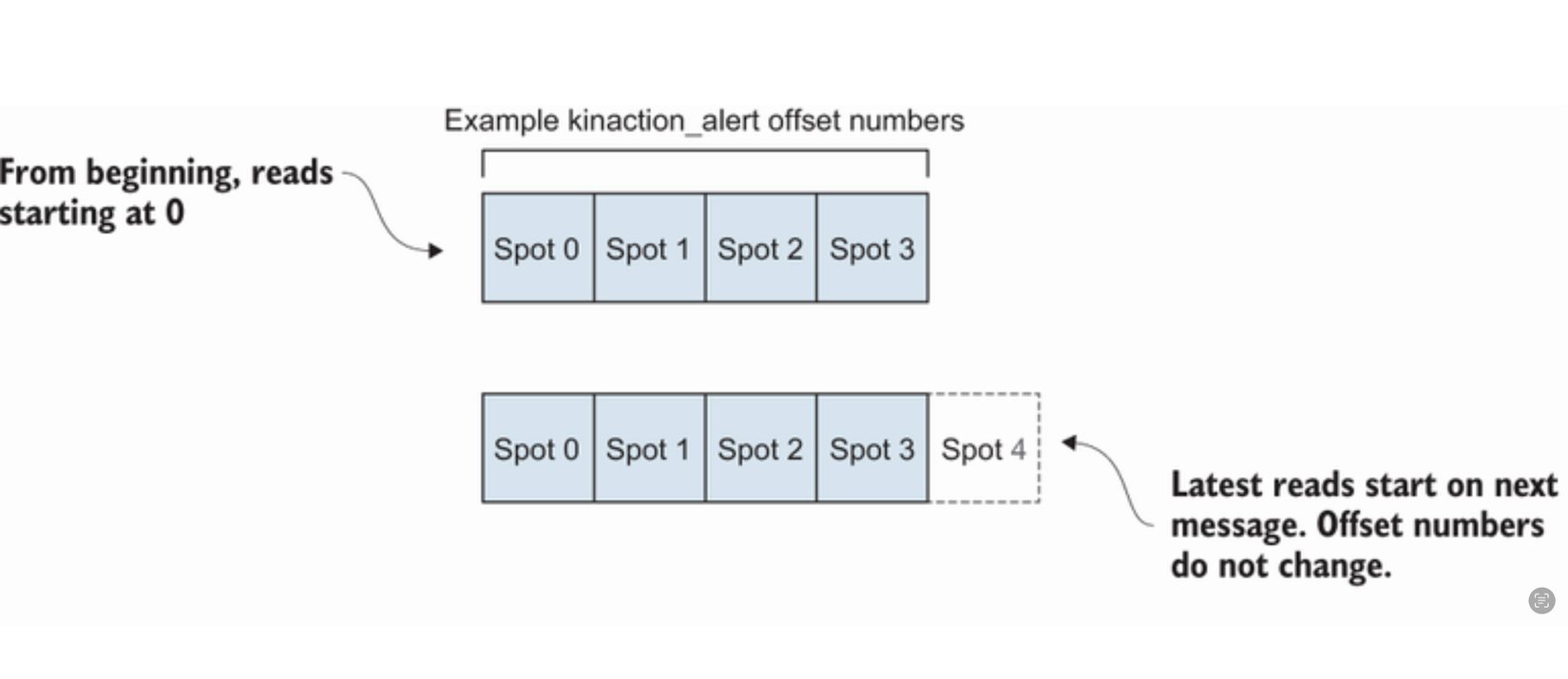
🔢 Offset và cách hoạt động
- Offset là chỉ mục xác định vị trí thông điệp trong log.
- Offset luôn tăng dần và không tái sử dụng.
- Mỗi partition có chuỗi offset riêng, giảm nguy cơ vượt giới hạn kiểu dữ liệu.
📌 auto.offset.reset và cách cấu hình
- Mặc định:
auto.offset.reset = latest. Chỉ nhận các thông điệp mới sau khi consumer khởi động. - Chế độ đọc từ đầu: Dùng flag
--from-beginningđể thiết lậpauto.offset.reset = earliest, cho phép đọc toàn bộ dữ liệu, kể cả thông điệp cũ.
🖼 Phân bổ partition và leader
-
Mỗi topic được chia thành nhiều partition, mỗi partition có một leader replica.
-
Consumer chỉ đọc từ leader replica của partition.
-
-
Hình 5.3 minh họa:
- Partition 1, 2, 3 có leader trên các broker khác nhau.
- Các bản sao (replica) được lưu trữ trên các broker phụ nhưng không được consumer đọc trực tiếp.
🌍 Ảnh hưởng của số lượng partition
- Nhiều partition tăng khả năng xử lý song song nhưng đi kèm chi phí:
- Tăng độ trễ khi đồng bộ giữa các broker.
- Tốn tài nguyên bộ nhớ nếu consumer phải xử lý nhiều partition.
- Khuyến nghị: Lựa chọn số lượng partition phù hợp với luồng dữ liệu và yêu cầu ứng dụng.
📊 Phân bổ consumer và partition
- Số lượng consumer không nên vượt quá số partition.
- Hình 5.4 minh họa: Với 4 consumer và 3 partition, consumer dư thừa sẽ ở trạng thái chờ mà không xử lý dữ liệu.
📚 Khả năng tương thích với Apache ZooKeeper
- Kafka hiện không sử dụng ZooKeeper cho consumer.
- Trước đây, ZooKeeper được dùng để lưu trữ offset, nhưng hiện nay Kafka client đã loại bỏ phụ thuộc này.
5.2 How consumers interact
Consumer Group là một nhóm gồm một hoặc nhiều consumer làm việc cùng nhau để đọc dữ liệu từ một topic trong Kafka Cùng group Các consumer phối hợp làm việc như một hệ thống duy nhất Khác group Các group làm việc độc lập, phù hợp với các logic xử lý khác nhau
Các đặc điểm chính của Consumer Groups:
Phối hợp (Coordination): Các consumer trong cùng một nhóm phối hợp để đảm bảo mỗi partition của topic chỉ được xử lý bởi một consumer duy nhất trong nhóm. Chia sẻ Offset: Các consumer trong cùng một nhóm chia sẻ thông tin offset (vị trí đọc dữ liệu cuối cùng) để đảm bảo không có dữ liệu bị đọc lặp lại hoặc bỏ sót.
Ví dụ: Giả sử bạn có một topic tên là hr-data với 3 partitions:
Topic: hr-data
Partition 0: [message1, message2, message3]
Partition 1: [message4, message5]
Partition 2: [message6, message7, message8]
Nếu bạn có 3 consumer trong cùng một nhóm, mỗi consumer sẽ được Kafka phân công đọc một partition. Nếu bạn thêm hoặc bớt consumer trong nhóm, Kafka sẽ tự động phân phối lại các partition để đảm bảo mỗi partition vẫn được xử lý (rebalancing)
5.3 Tracking
Ở các hệ thống khác, VD như RabbitMQ, nó sẽ xoá record ngay sau khi consumer ack message. Tuy nhiên đối với Kafka, những record này sẽ được lưu lại
Sự khác biệt quan trọng giữa Kafka với các hệ thống khác, ở việc cách consumer có được message. Kafka consumer sẽ poll dữ liệu từ Kafka về, trong khi đó các hệ thống khác lại thực hiện việc push message tới consumer cần tiêu thụ. Quan sát hình 5.5 phía dưới mô tả vấn đề khi push message tới consumer
Vấn đề 1: Do message bị xoá sau khi ack, nên chỉ có thể tiếp tục consume từ message 3 (Có 1 vấn đề Leo vẫn thắc mắc, mình sẽ để ngỏ ở đây, tại sao RabbitMQ không thực hiện việc lưu trữ lại message giống như Kafka làm??? mình sẽ research và bổ sung dưới comment sau :>>)
Vấn đề 2: Nếu có nhiều consumer cần tiêu thụ cùng 1 message, message đó sẽ bị duplicate trong nhiều queue khác nhau
2 vấn đề trên đều được Kafka giải quyết, nó sẽ chủ động chìa message và consumer nào cần sẽ tự chủ động đi poll dữ liệu về.
“it is important that the offsets and partitions are specific to a certain consumer group”
5.3.1 Group coordinator
Group coordinator làm việc với các consumer client để giữ thông tin về vị trí mà một nhóm cụ thể đã đọc trong topic
Hình 5.7 minh họa một scenario mà các partition giống nhau tồn tại trên ba broker khác nhau cho hai consumer group khác nhau, là kinaction_teamoffka0 và kinaction_teamsetka1. Các consumer trong mỗi group sẽ nhận một bản sao dữ liệu riêng từ các partition trên mỗi broker. Chúng không làm việc cùng nhau trừ khi thuộc cùng một group
1 quy tắc cần lưu ý là chỉ 1 consumer của 1 group có thể đọc 1 partition tại 1 thời điểm (mặc dù 1 partition có thể được đọc bởi nhiều consumer)
Hình 5.8 nhấn mạnh consumer 1 có thể đọc từ 2 partition leader, trong khi consumer 2 chỉ có thể đọc từ partition leader còn lại. Mỗi partition chỉ được gán cho một consumer duy nhất trong cùng một consumer group. Điều này được cho là để tránh việc nhầm lẫn trong quản lý offset và phân phối dữ liệu
“ heartbeat.interval.ms, which determines the amount of pings to the group coordinator from consumers ” Nếu heartbeat ngừng, điều này sẽ loại bỏ consumer khỏi group và kích hoạt cơ chế repartitioning.
5.3.2 Partition assignment strategy (Chiến lược assign partition)
- Range: dùng alphabetical order (phần dư sẽ dồn qua consumer đầu tiên)
- RoundRobin: Phân phối tuần tự
- Sticky và CooperativeSticky: Mình sẽ k tìm hiểu ở đây
5.4 Marking our place
Listing 5.4: Waiting on a Commit
consumer.commitSync(); // ❶
# // Any code here will wait on line before
❶ commitSync waits for a success or fail.
public static void commitOffset(long offset,
int partition,
String topic,
KafkaConsumer<String, String> consumer) {
OffsetAndMetadata offsetMeta = new OffsetAndMetadata(++offset, "");
Map<TopicPartition, OffsetAndMetadata> kaOffsetMap = new HashMap<>();
kaOffsetMap.put(new TopicPartition(topic, partition), offsetMeta);
consumer.commitAsync(kaOffsetMap, (map, e) -> { // ❶
if (e != null) {
for (TopicPartition key : map.keySet()) {
log.info("kinaction_error: offset {}", map.get(key).offset());
}
} else {
for (TopicPartition key : map.keySet()) {
log.info("kinaction_info: offset {}", map.get(key).offset());
}
}
});
}
❶ A lambda that creates an OffsetCommitCallback instance”
5.5 Compacted topic
“Kafka compacts the partition log in a background process, and records with the same key might be removed except for the last one”
Nếu requirement không quan trọng lịch sử của dữ liệu, chỉ quan tâm trạng thái mới nhất thì đây sẽ là feature bạn cần quan tâm.
Điều khiến các consumer dễ gặp lỗi nhất khi đọc từ một compacted topic là chúng vẫn có thể nhận được nhiều bản ghi cho cùng một key. Làm sao điều này có thể xảy ra? Vì quá trình compaction được thực hiện trên các tệp log lưu trữ trên đĩa, nên compaction có thể không nhìn thấy tất cả các thông điệp đang nằm trong bộ nhớ khi thực hiện compact.
Trong trường hợp có nhiều value cho 1 key thì client sẽ xử lý, lấy cái mới nhất là oke con dê =))
5.6 Coding time
Listing 5.6 Earliest offset
Properties kaProperties = new Properties();
kaProperties.put("group.id", UUID.randomUUID().toString()); ❶
kaProperties.put("auto.offset.reset", "earliest"); ❷
❶ Creates a group ID for which Kafka does not have a stored offset
❷ Uses the earliest offset retained in our logs
Listing 5.7: Latest Offset Configuration
Properties kaProperties = new Properties();
kaProperties.put("group.id",
UUID.randomUUID().toString()); // ❶
kaProperties.put("auto.offset.reset", "latest"); // ❷
❶ Creates a group ID for which Kafka does not have a stored offset
❷ Uses the latest record offset
Listing 5.8: Seeking to an Offset by Timestamps
...
Map<TopicPartition, OffsetAndTimestamp> kaOffsetMap =
consumer.offsetsForTimes(timeStampMapper); // ❶
...
// We need to use the map we get
consumer.seek(partitionOne,
kaOffsetMap.get(partitionOne).offset()); // ❷
❶ Finds the first offset greater or equal to that timeStampMapper
❷ Seeks to the first offset provided in kaOffsetMap
Listing 5.9: Audit Consumer Logic
// Disable auto commit
kaProperties.put("enable.auto.commit", "false"); // ❶
try (KafkaConsumer<String, String> consumer =
new KafkaConsumer<>(kaProperties)) {
// Subscribe to the topic
consumer.subscribe(List.of("kinaction_audit"));
while (keepConsuming) {
// Poll records from Kafka
var records = consumer.poll(Duration.ofMillis(250));
for (ConsumerRecord<String, String> record : records) {
// Audit record process logic
// ...
// Create OffsetAndMetadata for the next offset
OffsetAndMetadata offsetMeta =
new OffsetAndMetadata(++record.offset(), ""); // ❷
// Create map to store offsets for topic and partition
Map<TopicPartition, OffsetAndMetadata> kaOffsetMap =
new HashMap<>();
kaOffsetMap.put(
new TopicPartition("kinaction_audit", record.partition()),
offsetMeta); // ❸
// Commit offsets synchronously
consumer.commitSync(kaOffsetMap); // ❹
}
}
}
❶ Sets autocommit to false
❷ Adding a record to the current offset determines the next offset to read.
❸ Allows for a topic and partition key to be related to a specific offset
❹ Commits the offsets
Listing 5.10: Alert Trending Consumer
// Enable auto-commit
kaProperties.put("enable.auto.commit", "true"); // ❶
// Configure key deserializer
kaProperties.put("key.deserializer",
AlertKeySerde.class.getName()); // ❷
// Configure value deserializer
kaProperties.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
// Create KafkaConsumer instance
KafkaConsumer<Alert, String> consumer =
new KafkaConsumer<Alert, String>(kaProperties);
// Subscribe to the topic
consumer.subscribe(List.of("kinaction_alerttrend"));
while (true) {
// Poll for records
ConsumerRecords<Alert, String> records =
consumer.poll(Duration.ofMillis(250));
for (ConsumerRecord<Alert, String> record : records) {
// Process each alert record
// ...
}
}
❶ Uses autocommit as lost messages are not an issue
❷ AlertKeySerde key deserializer
5.11 Alert consumer
kaProperties.put("enable.auto.commit", "false");
KafkaConsumer<Alert, String> consumer =
new KafkaConsumer<Alert, String>(kaProperties);
TopicPartition partitionZero =
new TopicPartition("kinaction_alert", 0); ❶
consumer.assign(List.of(partitionZero)); ❷
while (true) {
ConsumerRecords<Alert, String> records =
consumer.poll(Duration.ofMillis(250));
for (ConsumerRecord<Alert, String> record : records) {
// ...
commitOffset(record.offset(),
record.partition(), topicName, consumer); ❸
}
}
...
public static void commitOffset(long offset,int part, String topic,
KafkaConsumer<Alert, String> consumer) {
OffsetAndMetadata offsetMeta = new OffsetAndMetadata(++offset, "");
Map<TopicPartition, OffsetAndMetadata> kaOffsetMap =
new HashMap<TopicPartition, OffsetAndMetadata>();
kaOffsetMap.put(new TopicPartition(topic, part), offsetMeta);
OffsetCommitCallback callback = new OffsetCommitCallback() {
...
};
consumer.commitAsync(kaOffsetMap, callback); ❹
}
❶ Uses TopicPartition for critical messages
❷ Consumer assigns itself the partition rather than subscribing to the topic
❸ Commits each record asynchronously
❹ The asynchronous commit uses the kaOffsetMap and callback arguments.
All rights reserved
