Chương 3: Thiết kế và Ứng dụng Dự án Kafka - Kafka In Action Series
Chương này tập trung vào cách thiết kế và triển khai một dự án Kafka thực tế. Từ việc tiếp quản một kiến trúc dữ liệu cũ, thiết kế sự kiện cho các cảm biến, cho đến việc định dạng và lập kế hoạch cho dữ liệu. Đây là bước đi quan trọng để giúp bạn hiểu cách Kafka có thể được áp dụng vào những trường hợp thực tế.
3.1 Thiết kế một dự án Kafka
Tiếp quản kiến trúc dữ liệu hiện có
Khi tham gia vào một tổ chức với kiến trúc dữ liệu cũ, bạn sẽ gặp phải các thách thức như:
- Hệ thống xử lý dữ liệu không đồng bộ, chậm và kém hiệu quả.
- Khó mở rộng và thiếu khả năng xử lý real-time.
- Sự phụ thuộc chặt chẽ giữa các hệ thống hiện có (tightly coupled systems).
Kafka sẽ là lựa chọn lý tưởng để cải tiến kiến trúc hiện tại vì khả năng:
- Hỗ trợ xử lý event-driven (hướng sự kiện).
- Phân phối dữ liệu nhanh chóng và ổn định.
- Giảm sự phụ thuộc giữa các hệ thống.
Một thay đổi đầu tiên
Bước đầu tiên trong quá trình thiết kế Kafka:
- Tạo một topic Kafka: Tách biệt dòng dữ liệu hiện tại thành các event streams.
- Xây dựng producer và consumer: Kết nối các hệ thống nguồn và hệ thống đích.
- Xử lý vấn đề latency: Đảm bảo dữ liệu được phân phối thời gian thực.
Ví dụ: Trong hệ thống hóa đơn (invoices), Kafka giúp tách dữ liệu thanh toán và gửi thông báo trạng thái hóa đơn ngay lập tức.
Tính năng sẵn có của Kafka
- Replication: Đảm bảo dữ liệu không bị mất khi có lỗi hệ thống.
- Partitioning: Tăng khả năng mở rộng và song song hóa việc xử lý dữ liệu.
- Retention: Lưu trữ dữ liệu lâu dài để phát lại (replay) khi cần thiết.
Dữ liệu cho hóa đơn
Thiết kế dòng dữ liệu cho hệ thống hóa đơn:
- Topic "invoices": Chứa thông tin hóa đơn mới tạo.
- Topic "payments": Ghi nhận trạng thái thanh toán.
- Consumer: Xử lý trạng thái thanh toán và gửi cập nhật đến hệ thống khách hàng.
Kafka giúp đảm bảo tính toàn vẹn và đồng bộ giữa các thành phần hệ thống.
3.2 Thiết kế sự kiện cảm biến
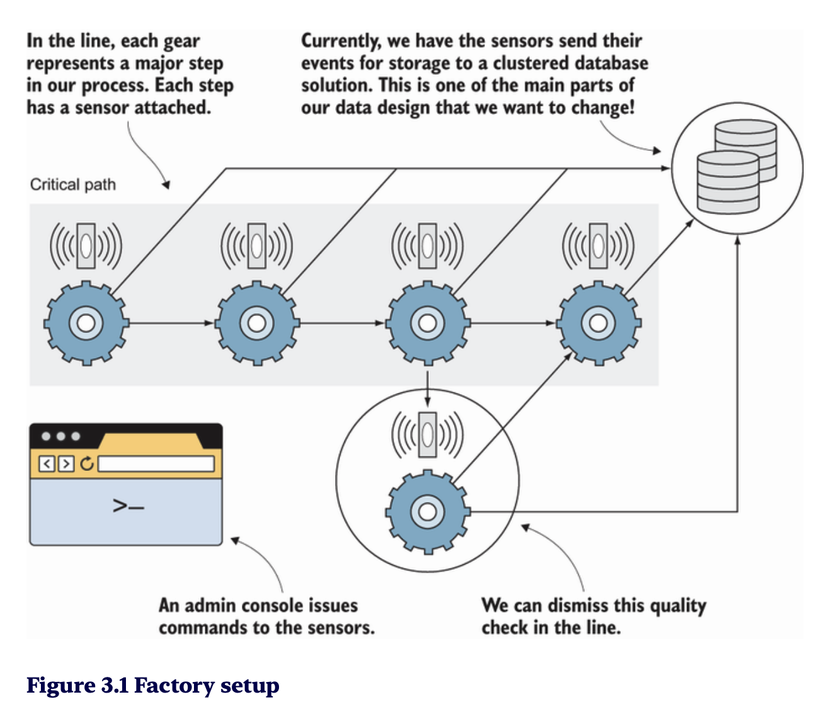
Các vấn đề hiện có
Hệ thống cũ gặp nhiều vấn đề khi xử lý sự kiện từ cảm biến:
- Dữ liệu cảm biến được gửi đến một hệ thống tập trung và dễ quá tải.
- Không có khả năng mở rộng và xử lý song song.
- Dữ liệu không được lưu trữ để phân tích sau này.
Tại sao Kafka là giải pháp phù hợp?
Kafka giải quyết vấn đề này bằng cách:
- Phân phối dữ liệu theo thời gian thực đến các topic Kafka.
- Lưu trữ dữ liệu trong các partitions và cho phép các consumer xử lý song song.
- Đảm bảo khả năng chịu lỗi và phục hồi nhờ cơ chế replication.
Các ý tưởng khởi đầu cho thiết kế
- Topic "sensor-events": Ghi lại tất cả dữ liệu sự kiện từ cảm biến.
- Phân loại dữ liệu: Chia dữ liệu thành các partitions dựa trên loại cảm biến hoặc khu vực địa lý.
- Lựa chọn retention: Xác định thời gian lưu trữ dữ liệu cho phân tích sau này.
Yêu cầu về dữ liệu người dùng
Các yêu cầu từ hệ thống người dùng:
- Dữ liệu cần được truyền nhanh chóng và đáng tin cậy.
- Có khả năng lưu trữ và phát lại dữ liệu để kiểm tra lịch sử.
- Tích hợp dễ dàng với hệ thống analytics (ví dụ: Elasticsearch, Spark).
Kế hoạch tổng thể áp dụng Kafka
- Xây dựng topic và phân vùng dữ liệu.
- Tạo producer để ghi dữ liệu cảm biến vào topic Kafka.
- Tạo consumer để đọc và xử lý dữ liệu theo thời gian thực.
- Kết nối với hệ thống phân tích để báo cáo và giám sát.
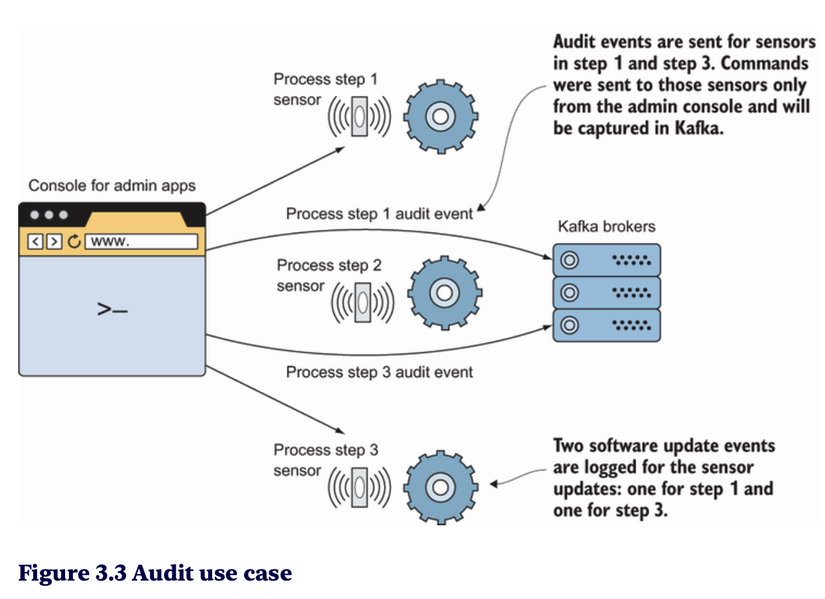
Xem xét bản thiết kế
- Kafka cluster: Đảm bảo có đủ brokers và partition để mở rộng hệ thống.
- Replication factor: Đặt cấu hình hợp lý để bảo vệ dữ liệu.
- Consumer group: Thiết kế các consumer xử lý dữ liệu song song mà không bị trùng lặp.
3.3 Định dạng dữ liệu của bạn
Lập kế hoạch cho dữ liệu
- Xác định cấu trúc dữ liệu: Sử dụng các định dạng như JSON, Avro hoặc Protobuf.
- Schema Registry: Giúp quản lý và kiểm soát các phiên bản schema dữ liệu.
- Thống nhất định dạng: Đảm bảo tất cả producers và consumers sử dụng định dạng dữ liệu giống nhau.
Cài đặt các phụ thuộc
- Kafka client libraries: Cài đặt thư viện Kafka cho ngôn ngữ bạn sử dụng (Java, Python, Go...).
- Schema Registry: Triển khai công cụ Schema Registry để quản lý định dạng dữ liệu.
- Kafka Connect: Kết nối Kafka với các nguồn dữ liệu khác như cơ sở dữ liệu hoặc hệ thống lưu trữ.
References
- Apache Kafka Documentation
- Confluent Schema Registry
- Các khóa học Kafka trên Udemy và Coursera.
Lời kết
Trong chương này, chúng ta đã tìm hiểu cách thiết kế và triển khai một dự án Kafka. Từ việc tiếp quản hệ thống cũ đến thiết kế các sự kiện cảm biến và định dạng dữ liệu, Kafka đã chứng minh khả năng mạnh mẽ trong việc xử lý dữ liệu thời gian thực và phân tán.
Chương tiếp theo sẽ tiếp tục đi sâu vào cách triển khai các thành phần Kafka trong thực tế và tối ưu hóa hệ thống của bạn!
All rights reserved
