Chiến lược bày hàng thông minh – bí mật từ dữ liệu mua sắm

🛒 Vì sao trứng thường nằm cạnh bột mì và sữa?
Đi siêu thị, bạn có để ý thấy trứng thường được đặt gần bột mì và sữa không?
Thoạt nghe thì tưởng chỉ là sự ngẫu nhiên trong cách sắp xếp, nhưng thực tế phía sau đó là cả một “nghệ thuật sắp kệ” dựa trên dữ liệu mua sắm của hàng triệu khách hàng.
Khi nhiều người mua trứng cũng thường xuyên mua kèm bột mì và sữa, siêu thị sẽ tận dụng thông tin này để:
- Bày sản phẩm cạnh nhau cho khách dễ tìm
- Khéo léo khuyến khích khách hàng mua thêm vài món liên quan
Trong bài viết này, chúng ta sẽ cùng khám phá:
- Một chút lý thuyết đằng sau thuật toán Apriori (Market Basket Analysis)
- Ví dụ tính toán nhỏ xíu để bạn dễ hình dung
- Ứng dụng thực tế: từ siêu thị đến các sàn thương mại điện tử như Shopee, Lazada, Amazon
Cuối cùng, bạn sẽ thấy rằng: đằng sau mỗi chuyến đi siêu thị là cả một thế giới thuật toán đang vận hành.
Ý tưởng phía sau việc sắp xếp kệ hàng
Khi bạn đi siêu thị, việc thấy trứng nằm cạnh bột mì và sữa không chỉ là sự tình cờ.
Thực tế, các siêu thị (và cả các trang thương mại điện tử) đều dựa trên một khái niệm quen thuộc trong phân tích dữ liệu: giỏ hàng (market basket).
🛒 Giỏ hàng chính là danh sách những sản phẩm mà một khách hàng mua trong một lần.
Ví dụ:
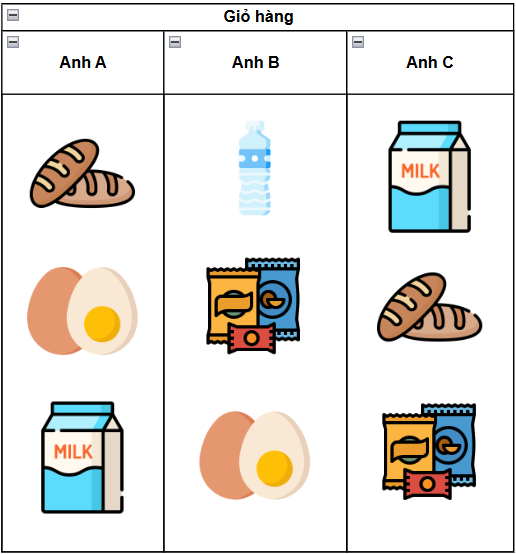
Nếu bạn có hàng nghìn giỏ hàng như vậy, sẽ thấy xuất hiện những mẫu lặp lại:
- Người mua trứng thường mua kèm sữa và bánh mì
- Người mua nước thường mua kèm snack
Khi phát hiện ra các “cặp đôi ăn ý” này, siêu thị có thể:
- Sắp xếp sản phẩm cạnh nhau để khách dễ tìm
- Đẩy doanh thu bằng cách khuyến khích khách mua thêm (ví dụ: đã có trứng, thêm sữa là đủ làm bánh rồi)
- Thiết kế khuyến mãi combo: mua 2 sản phẩm sẽ giảm giá sản phẩm thứ 3
Nói cách khác, việc sắp kệ hàng không còn là ngẫu nhiên, mà là một chiến lược dựa trên dữ liệu.
Thuật toán Apriori là gì?
Để tìm ra mối quan hệ giữa các sản phẩm trong giỏ hàng, người ta dùng một công cụ quen thuộc trong Machine Learning cổ điển: thuật toán Apriori.
🤔 Nghe tên thì có vẻ “to tát”, nhưng thực chất ý tưởng rất đơn giản:
- Nếu một tập sản phẩm nhỏ (ví dụ: {trứng, sữa}) thường xuyên xuất hiện,
- thì một tập lớn hơn chứa nó (ví dụ: {trứng, sữa, bột mì}) cũng có khả năng cao xuất hiện.
Thuật toán Apriori dựa trên 3 khái niệm quan trọng Support, confidence, and lift:
-
Support (độ hỗ trợ)
![image.png]()
- Tần suất xuất hiện của một sản phẩm (hoặc một nhóm sản phẩm) trong toàn bộ giỏ hàng.
- Ví dụ: nếu có 100 giỏ hàng, 20 giỏ có {trứng, sữa} → support = 20%.
-
Confidence (độ tin cậy)
![image.png]()
- Xác suất mua thêm sản phẩm B khi đã mua sản phẩm A.
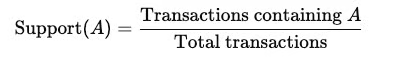

Ví dụ: trong 20 giỏ có trứng, 15 giỏ cũng có sữa → confidence(Trứng → Sữa) = 15/20 = 75%.
-
Lift (hệ số nâng đỡ)
![image.png]()
- Đo độ “bất ngờ” của mối quan hệ.
- Nếu lift > 1 → có mối quan hệ thật sự (không chỉ tình cờ).
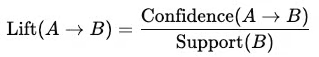
Ví dụ: nếu khách mua trứng thường xuyên đặc biệt mua thêm sữa, lift sẽ > 1.
Thuật toán hoạt động chi tiết như thế nào ?
Hãy tưởng tượng bạn là quản lý siêu thị và có trong tay hàng ngàn giỏ hàng (mỗi giỏ là danh sách sản phẩm mà khách mua). Bạn muốn biết: Nếu khách đã mua trứng, thì họ còn thường mua gì thêm?
Thuật toán Apriori sẽ làm việc đó theo 4 bước:
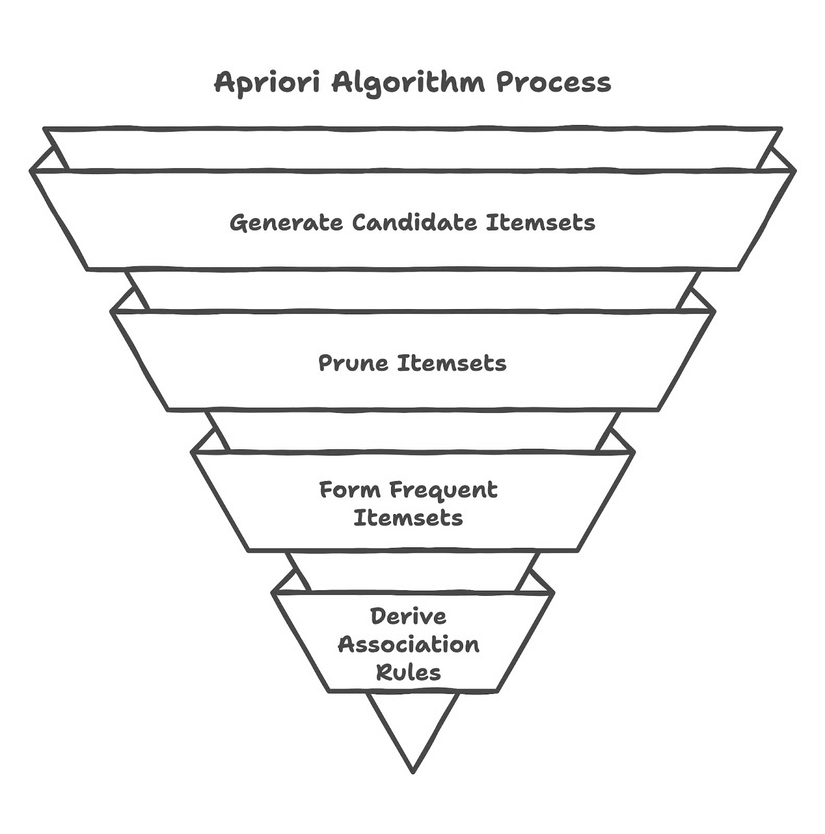
Thuật toán Apriori (Nguồn DataCamp)
1. Đếm từng món lẻ (Generating candidate itemsets) Bước đầu tiên, ta chỉ đếm xem mỗi sản phẩm xuất hiện bao nhiêu lần trong tất cả các giỏ hàng.
Ví dụ:
- Trứng: có mặt trong 60/100 giỏ hàng → 60%
- Sữa: có mặt trong 40/100 giỏ hàng → 40%
👉 Lúc này ta biết món nào phổ biến nhất.
2. Lọc món ít gặp (Pruning)
- Ta đặt ra một ngưỡng tối thiểu (gọi là min_support), ví dụ: chỉ quan tâm sản phẩm có mặt trong ít nhất 30% giỏ hàng.
- Những món “ít ai mua” (như hạt dẻ rang muối) sẽ bị bỏ qua.
- Giữ lại các món phổ biến: trứng, sữa, bột mì...
3. Tìm các cặp/bộ hay đi chung (Generating frequent itemsets)
- Sau khi biết món lẻ nào phổ biến, ta thử kết hợp chúng thành cặp:
- Trứng + Sữa
- Trứng + Bột mì
- Sữa + Bột mì
- Rồi tiếp tục đếm: cặp nào xuất hiện nhiều lần trong giỏ hàng → giữ lại.
- Có thể mở rộng thành bộ 3, bộ 4… đến khi không còn “tổ hợp phổ biến” nữa.
👉 Đây là lúc ta tìm ra “combo vàng”: Trứng + Sữa + Bột mì.
4. Rút ra quy luật (Deriving association rules)
- Giờ thì ta biến những “combo” thành luật gợi ý.
Ví dụ:
- Nếu khách đã mua Trứng → 75% khả năng họ cũng mua Sữa.
- Nếu khách mua Trứng và Bột mì → 60% khả năng họ cũng mua Sữa.
👉 Những luật này giúp siêu thị biết nên đặt món nào cạnh món nào, hoặc gợi ý mua thêm trên app mua sắm.
Ứng dụng thuật toán với Python
Trong phần này, chúng ta sẽ trực tiếp áp dụng thuật toán Apriori bằng thư viện mlxtend để tìm ra các tập mục phổ biến và luật kết hợp từ dữ liệu giao dịch.
1. Chuẩn bị môi trường và dữ liệu
Cài đặt thư viện cần thiết (pandas, mlxtend)
pip install pandas mlxtend
Giới thiệu 2 dạng dữ liệu đầu vào:
- Dữ liệu đã được xử lý sẵn (one-hot) = (0,1) = (true,false)
- Dữ liệu thô (list các giao dịch) => Cần chuyển sang one-hot
Ví dụ minh hoạ dữ liệu one-hot:
| Milk | Bread | Butter | Beer | Diaper |
|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 | 0 |
Mỗi dòng là một giao dịch, mỗi cột là sản phẩm — 1 nghĩa là có xuất hiện trong giỏ hàng.
2. Các bước thực hiện
Sau khi dữ liệu đã ở dạng one-hot, ta có thể áp dụng thuật toán Apriori để tìm ra các tập mục phổ biến (frequent itemsets) và sinh ra các luật kết hợp. Dưới đây là quy trình 4 bước cơ bản mà mình đã triển khai trong notebook (link đính kèm ở cuối bài):
Bước 1: Đếm tần suất từng món (1-itemsets)
frequent_items = item_support[item_support >= min_support_threshold].sort_values(ascending=False)
Bước 2: Tạo và lọc tập mục thường gặp (Frequent Itemsets) Dùng apriori để lấy mọi frequent itemset với min_support
frequent_itemsets = apriori(df, min_support=min_support_threshold, use_colnames=True)
Bước 3: Tìm luật kết hợp (Association Rules)
Sử dụng metric confidence hoặc lift để lọc
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=min_confidence_threshold)
Notebook tham khảo
Bạn có thể xem toàn bộ code và thử chạy trực tiếp tại notebook mình đã làm ở đây Nếu thấy sai sót hoặc có góp ý, rất mong bạn phản hồi — cảm ơn bạn nhiều 💬
Kết luận
Các ví dụ trên là những minh họa cơ bản nhất cho cách thuật toán Apriori được áp dụng trong thực tế — giúp chúng ta phát hiện những mối quan hệ ẩn giữa các sản phẩm và hiểu hành vi mua sắm của khách hàng rõ hơn.
Tuy nhiên, Apriori cũng có một số hạn chế:
- Khi áp dụng trên dữ liệu có hàng trăm ngàn bản ghi (record), quá trình tính toán sẽ rất chậm.
- Cần chọn ngưỡng hỗ trợ (support) và độ tin cậy (confidence) hợp lý, nếu không kết quả có thể quá ít hoặc quá nhiều.
- Thuật toán này không tối ưu cho dữ liệu lớn (big data), nên trong thực tế người ta thường dùng các cải tiến như FP-Growth.
Nếu bạn thích thú với chủ đề này, hãy để lại like hoặc bình luận để mình có động lực nghiên cứu sâu hơn nhé.
👋
Chào bạn,
Mình là Nam — người luôn thích tìm tòi, học hỏi và chia sẻ những công nghệ thú vị trong cuộc sống.
Hy vọng bài viết này giúp bạn hiểu rõ hơn về Apriori và cách áp dụng nó vào thực tế.
👉 Hẹn gặp bạn ở bài viết tiếp theo!
All rights reserved
