
[Paper Explain] IAG: Induction-Augmented Generation Framework for Answering Reasoning
Bài đăng này đã không được cập nhật trong 2 năm
Cũng khá lâu rồi thì mình mới viết Viblo, một phần vì lười và cũng một phần vì có quá nhiều thứ cần cập nhật, đặc biệt là LLM khi cứ vài tuần lại có thêm một thứ mới để đọc. Nhưng lười mãi thì cũng không tốt, bài viết này sẽ giới thiệu về bài báo mình đang đọc có tên gọi "IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions". Mọi người có thể đọc nội dung chi tiết của bài viết này ở phần dưới đây nhé.
Tổng quan
Ờ thì nếu dạo quanh Github, đặc biệt là từ khi ta có thể dễ dàng sử dụng mô hình LLM của OpenAI/Azure thông qua việc gọi API, hàng tỉ repo chatbot xuất hiện với các tên rất thuyết phục như "Your assistant", "Your GenAI Second Brain",... Nhìn chung, các repo này đều triển khai chatbot dưới hình thức Retrieval Augmented Generation (RAG) để giải quyết vấn đề mô hình tạo ra thông tin không có thật bằng cách cung cấp thêm thông tin đã được tìm kiếm trước đó, và từ đó cải thiện kết quả đầu ra của các mô hình ngôn ngữ trong các nhiệm vụ đòi hỏi nhiều kiến thức.
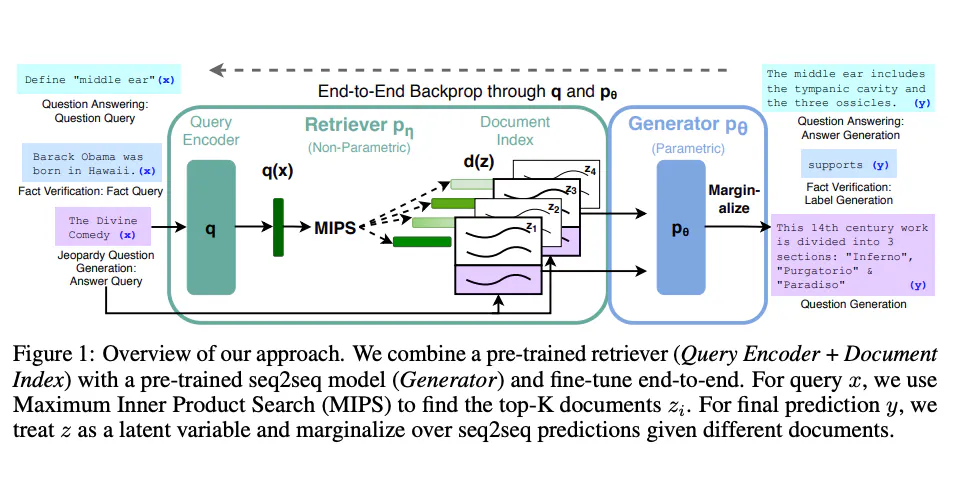
Tuy nhiên, việc chỉ áp dụng Retrieval để đảm bảo tính đúng đắn của thông tin có thể không đem lại kết quả tốt cho các câu hỏi lập luận ngầm. Cơ sở dữ liệu chung thường có độ phủ hạn chế và có thể chứa nhiều thông tin nhiễu. Để nâng cao hiệu suất của chatbot, các pháp sư từ Huawei đã giới thiệu Induction-Augmented Generation (IAG) sử dụng kiến thức quy nạp cùng với việc truy xuất các tài liệu để lập luận ngầm. Thông tin chi tiết về bài báo này được trình bày dưới đây:
Link: https://arxiv.org/abs/2311.18397
Các đóng góp chính
Trước đây, tôi dịch toàn bộ bài báo, nhưng sau khi suy nghĩ lại, có lẽ không ai sẽ đọc nữa. Vì vậy, tôi sẽ ghi lại các ý chính như sau:
Induction-Augmented Generation (IAG)
Cách cài đặt
Nhìn chung Induction-Augmented Generation (IAG) vẫn dùng Retriever để tìm hiếm thông tin từ cơ sở tri thức chung, tuy nhiên ta có thể dễ dàng nhận thấy từ trong hình trên là, quá trình xử lý có thêm một nhánh Inductor. Inductor lấy câu hỏi làm đầu vào và đưa ra các phát biểu kiến thức dưới dạng suy luận quy nạp. Những thông tin này, cùng với các tài liệu được truy xuất, được sử dụng làm bằng chứng hỗ trợ để đưa vào generator.
Vậy điểm khác biệt là gì? Phương pháp prompt mà nhóm tác giả nghiên cứu lấy ý tưởng từ lý luận quy nạp, một phương pháp tư duy logic rút ra kết luận chung từ quan sát cụ thể. Lý luận quy nạp sử dụng phép loại suy và khái quát hóa để kết nối các đối tượng tương tự và suy ra thông tin mới về một đối tượng dựa trên những gì đã biết. Khái quát hóa là việc khai thác thông tin danh mục để khái quát hóa từ cái đã biết đến cái chưa biết.
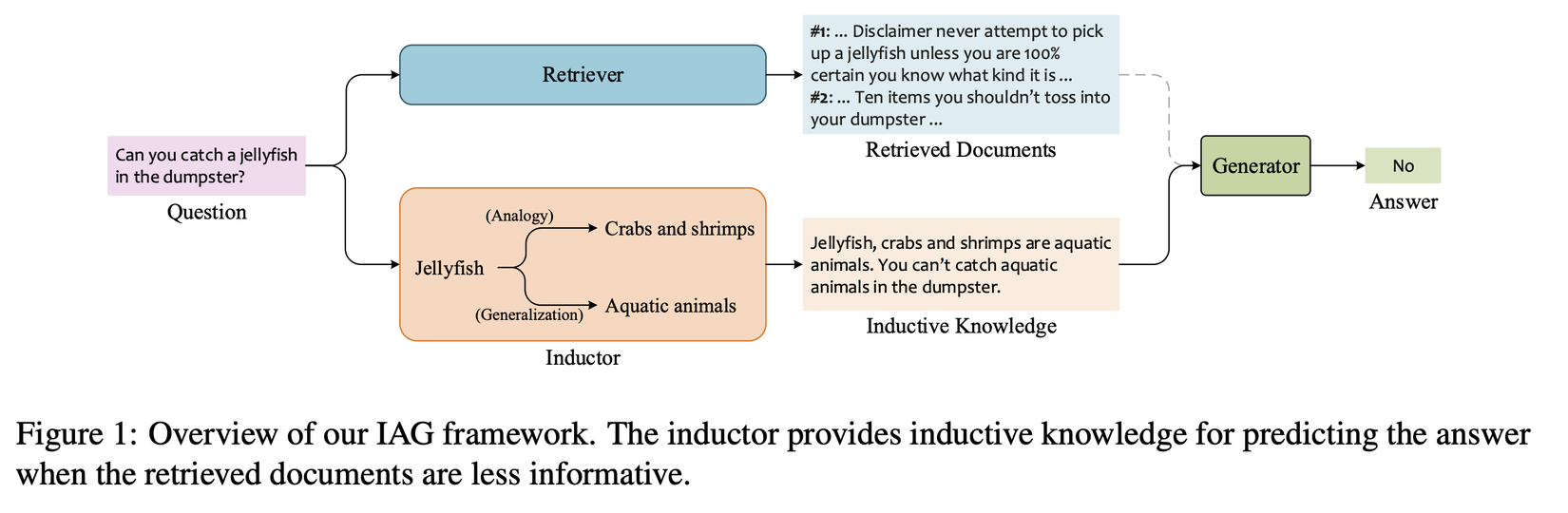
Như được thể hiện ở hình trên, bằng cách suy luận tương tự, người ta có thể phỏng đoán rằng sứa, giống như cua và tôm, hiếm khi được tìm thấy trong thùng rác vì những loài động vật này có đặc điểm cư trú tương tự nhau. Bằng cách khái quát hóa, việc sứa là động vật sống dưới nước có thể ủng hộ giả thuyết rằng chúng sống ở dưới nước thay vì ở thùng rác.
Dựa trên các chức năng nhận thức ở trên, nhóm tác giả đề xuất một phương pháp prompt hướng dẫn LLM tạo ra các tuyên bố kiến thức được thể hiện qua các câu hỏi bằng cách xây dựng một lộ trình suy luận gồm hai bước, được đưa ra chính thức như sau:
Question: A statement about target.
Knowledge: Target, analog#1, analog#2 are hypernym. An assertion about hypernym.
Trong đó hypernyms là thượng vị từ, là từ có nghĩa bao hàm những từ khác có nghĩa hẹp hơn, và khi đó ta sẽ có được các prompt trông như sau:
Question: It is safe to keep wolves as pets.
Knowledge: Wolves, tigers and lions are wild animals. Wild animals are generally dangerous.
###
Question: Bacon is healthy diet food.
Knowledge: Bacon, chips and cakes are junk food. Junk food is not healthy.
###
Question: Pens are more expensive than cars.
Knowledge: Pens, erasers and paper are stationery. Stationery is cheaper than cars.
###
Question: People make furniture out of oak.
Knowledge: Oak, pine and beech are Wood. Wood can be used to make furniture.
###
Question: Fridges are often used in the wild.
Knowledge: Fridges, ovens and TVs are appliances. Appliances are used in houses.
###
Question: {User Question}
Knowledge:
Vậy chi tiết cách cài đặt của IAG sẽ như thế nào? Dựa vào nội dung của mục 3.3 trong paper, ta có thể hình dung được cách cài đặt cùng GPT với các điểm chính như sau:
- Sử dụng GPT-3 để sinh các inductive knowledge cho mỗi câu hỏi
- Thay vì bỏ phiếu rõ ràng cho nhiều kết quả như Chain of Thought, IAG-GPT cho phép generator suy luận một cách ngụ ý dựa trên tập hợp tất cả các knowledge statement đã được chọn mẫu. Cụ thể, đối với mỗi câu hỏi, ta lấy mẫu M knowledge statement từ GPT-3 và gắn chúng vào N tài liệu đã được truy xuất, dẫn đến một bộ sưu tập gồm M + N bằng chứng.
- Generator, trong cả quá trình huấn luyện và suy luận, nhận tất cả M + N bằng chứng làm đầu vào theo phương pháp fusion-in-decoder. Việc cung cấp nhiều tuyên bố kiến thức đã được chọn mẫu cho generator mang lại hai lợi ích:
- Trong quá trình huấn luyện, generator học cách dự đoán câu trả lời chính xác dựa trên một tập hợp đa dạng các knowledge statement, làm cho nó mạnh mẽ đối với thông tin nhiễu có mặt trong thông tin được cung cấp.
- Trong suy luận, việc cung cấp một bộ sưu tập đa dạng hơn của thông tin tìm kiếm được tránh vấn đề local optimality trong quá trình greedy decoding và có cơ hội tốt hơn để cho ra knowledge statement tốt nhất để prompt cho generator
Kết quả thử nghiệm
Để kiểm tra độ hiệu quả, nhóm tác giả đã đánh giá IAG trên hai bộ kiểm tra trả lời câu hỏi mở, bao gồm CSQA2.0 và StrategyQA. Cả hai bộ đều là tác vụ phân loại nhị phân. Sau đó, với IAG-GPT, quá trình đưa ra câu trả lời sẽ được thực hiện theo 3 phần như sau:
- Retriever:
- Đối với StrategyQA, retriever được thực hiện bằng thuật toán BM25 thưa thớt, sau đó là một single-stream reranker.
- Đối với CSQA2.0, nhóm tác giả đưa câu hỏi vào Google Search và sử dụng 5 đoạn trích đầu tiên của kết quả trả về làm dữ liệu truy xuất.
- Inductor: Dịch vụ GPT-3 (textdavinci-003) được sử dụng để triển khai.
- Generator: Sử dụng T5-11B làm backbone để tạo generator.
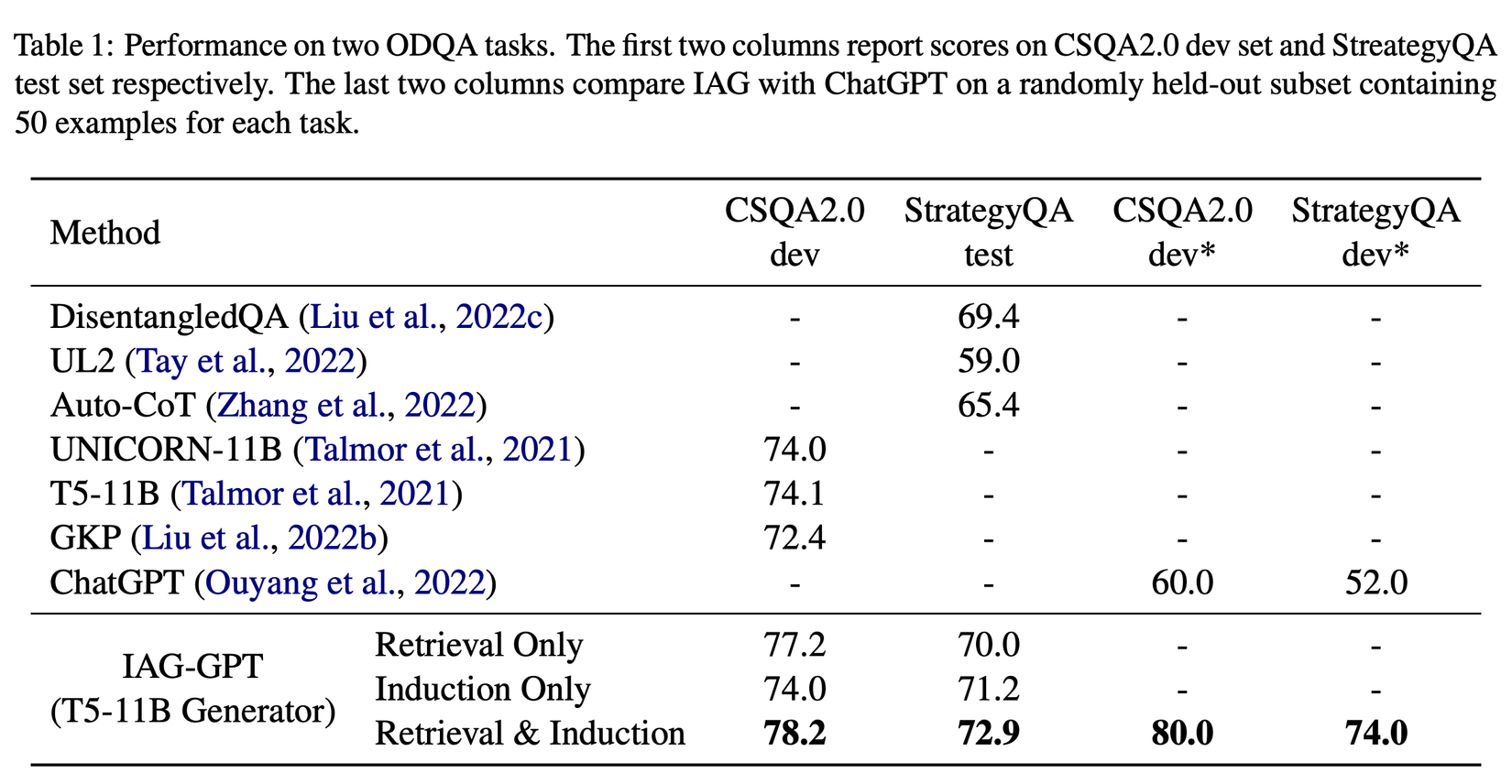
Dựa trên bảng kết quả trên, ta có thể thấy sự cải thiện đáng kể của IAG so với SOTA (74.1 → 78.2 cho CSQA2.0 và 69.4 → 72.9 cho StrategyQA). Kết quả chi tiết có thể được tìm hiểu thêm trong paper, tuy nhiên hiện tại source code để tái tạo chưa được công khai, nên tạm thời chúng chỉ có giá trị tham khảo :v
Phương pháp huấn luyện IAG-Student
Để loại bỏ sự phụ thuộc vào GPT-3 trong quá trình suy luận, nhóm tác giả thay thế GPT-3 bằng một mô hình student inductor được huấn luyện qua hai bước như sau:
Áp dụng Distillation
TLDR: Warm up mô hình thông qua phương pháp distillation, tức là các câu khẳng định tri thức thu thập từ GPT-3 được sử dụng như là nhãn giả để huấn luyện inductor với hàm loss seq2seq
Về cách cài đặt chi tiết:
Để theo dõi nội dung phần sau tốt hơn, chúng ta cần thống nhất các ký hiệu được nhóm tác giả sử dụng như sau:
- : knowledge statements được sample bằng cách sử dụng GPT-3
- : bộ top-M document được ranked từ retriever
Cách huấn luyện:
-
Thay vì huấn luyện trực tiếp generator bằng tất cả các knowledge statements được tạo ra bởi GPT3, nhóm tác giả cho rằng chúng ta cần xác định độ tin cậy của từng statement trước khi sử dụng chúng trong quá trình huấn luyện inductor, và có hai điểm chính được mô tả trong paper như sau:
- Giá trị có thể được sử dụng để định lượng hoá độ tin cậy có thể là xác suất generator đưa ra câu trả lời chính xác khi được statement sử dụng làm bằng chứng hỗ trợ cho generator.
- Cách tính toán:
- Adapt mô hình generator cho bộ dữ liệu cụ thể của task vụ bằng cách fine-tuning một vài bước thông qua việc sử dụng các document được tìm kiếm bởi retriever
- Đưa từng statements làm bằng chứng hỗ trợ bổ sung cùng với M document đã được thu thập vào generator và tính xác suất của câu trả lời được đưa ra là đúng bằng công thức trong đó là parameters của generator.
- Xác định các giá trị độ tin cậy từ 1 đến N bằng cách chuẩn hóa phân phối xác suất trên từ 1 đến N như bằng công thức và ,trong đó, và là giá trị trung bình và độ lệch chuẩn của phân phối
-
Sau khi đã thu được độ tin cậy của các statements, họ train inductor với chúng và sử dụng một trong hai distillation strategies thông qua việc sử dụng hai distillation loss khách nhau:
- : chỉ cho phép statements có độ tin tưởng cao nhất đóng góp vào giá trị hàm loss
- : cho phép tất cả statements được đóng góp vào giá trị hàm loss, tuy nhiên các giá trị này sẽ được đánh trọng số
- Again vì chưa có code nên mình không rõ nó được implement kiểu gì
Thuật toán TAILBACK
TLDR: Thuật toán TAILBACK tính toán prediction loss của generator dựa trên các knowledge statements được tạo bởi inductor và cập nhật các parameters của inductor thông qua phương pháp gradient descending. Để thực hiện điều này, một thuật toán differentiable beam search được triển khai cho inductor, cho phép các gradient được truyền qua các điểm số beam.
Như được đề cập trong paper, thuật toán TAILBACK được cài đặt thông qua việc sử dụng một differentiable beam search cho inductor và khi đó beam scores có thể được back-propagated. Cụ thể hơn thì, thuật toán vi phân khác với cách triển khai mặc định ở chỗ nó bảo toàn các đồ thị tính toán để lấy beam scores thay vì chuyển đổi chúng thành các đại lượng vô hướng bất khả vi trong quá trình tính toán. Do đó, gradients được truyền qua inductor thông qua beam scores.
![image.png]()
Chi tiết cách cài đặt của thuật toán TAILBACK được thể hiện qua mã giả ở trên, đoạn này mình sẽ dịch sau chứ giờ hơi lười :v
Kết quả thực nghiệm

Để chứng minh tính hiệu quả thì nhóm tác giả cũng thử nghiệm trên 2 tập data ở thí nghiệm trên, tuy nhiên quá trình đưa ra câu trả lời sẽ được thực hiện bằng cách sử dụng 3 phần như sau:
- Retriever: Tương tự như thí nghiệm trên
- Inductor: Dùng T5-Large làm backbone của mô hình inductor
- Generator: Sử dụng T5-Large làm backbone để tạo generator.
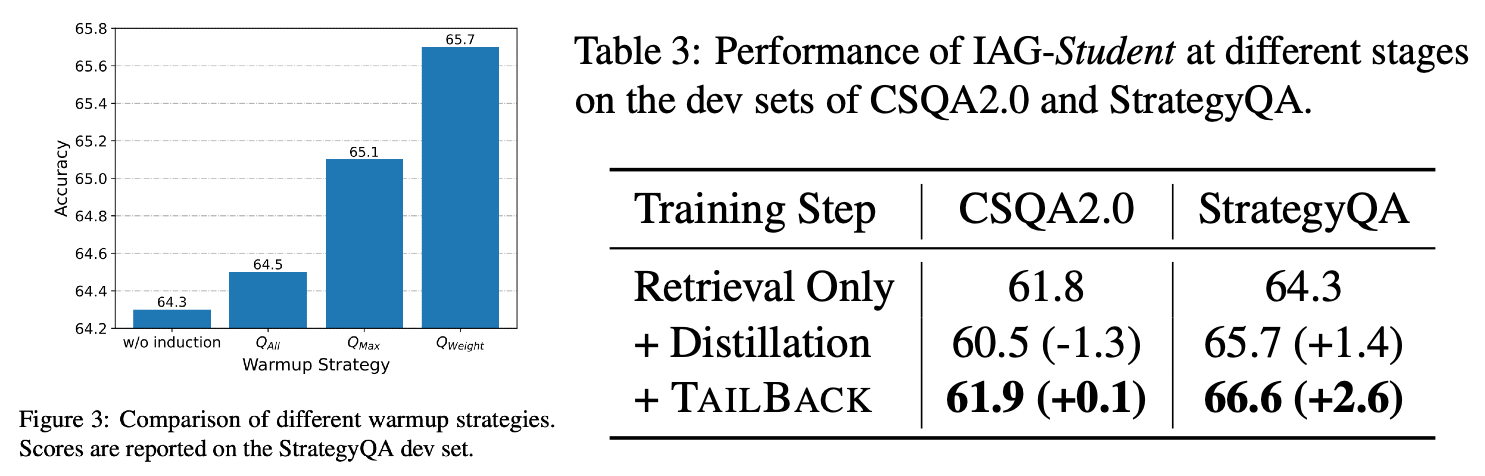
Dựa trên số liệu được báo cáo trong paper, chúng ta có thể thấy rằng mặc dù số lượng tham số của Generator giảm khá đáng kể (từ 11 tỉ về còn 770 triệu) nhưng mô hình Generator vẫn duy trì được độ chính xác khác ấn tượng. Điều này cho thấy rằng mô hình Generator đã được tối ưu hóa một cách hiệu quả để đạt được hiệu suất tốt hơn với số lượng tham số ít hơn.
Tổng kết
Bài viết này giới thiệu về IAG - Induction-Augmented Generation Framework for Answering Reasoning Questions", bao gồm các thử nghiệm của nhóm tác giả với GPT để nâng cao độ chính xác trên tác vụ QA, thuật toán TAILBACK nhằm huấn luyện các mô hình nhỏ có hiệu năng tương đương trong các tác vụ cụ thể. Trong quá trình theo dõi, các bạn có thể thấy rằng việc sử dụng inductor để sinh ra các knowledge statements khá giống như cách chúng ta thường sử dụng để tìm kiếm thông tin - nghĩ trước khi làm. Bởi vậy nên, mình nghĩ rằng việc cài đặt các hệ thống RAG dựa trên các phương pháp tìm kiếm, trao đổi thông tin của con người sẽ phần nào cải thiện được độ chính xác của chúng, nhất là khi các LLM được kỳ vọng rằng sẽ có được khả năng suy luận tốt như con người.
Bên cạnh đó và cũng không hề kém thú vị hơn là, nhóm tác giả đã cho ta thấy việc áp dụng Distillation và các thuật toán huấn luyện thích hợp có thể giúp ta thu được các mô hình nhỏ hơn đáng kể mà không ảnh hưởng quá đáng kể đến độ chính xác. Phát hiện này cho chúng ta một phương án mới khi giải quyết các bài toán liên quan đến các mô hình ngôn ngữ sử dụng cho một/một vài domain cụ thể khi ta có thể (1) giảm thiểu chi phí hosting khi sử dụng mô hình có lượng tham số nhỏ hơn, (2) hạn chế được việc phụ thuộc vào dịch vụ thứ 3 như GPT, nhất là khi nó có một vài issue như phiên bản GPT 3.5-06-13 mới và nó có hiệu suất kém hơn đáng kể ở các ngôn ngữ khác và (3) mô hình nhỏ hơn có thể giúp ta tiếp cận với phương pháp triển khai khác, chẳng hạn như triển khai trên thiết bị di động hoặc egde device
Nhìn chung thì mặc dù có ý tưởng và kết quả thu được khá ấn tượng, code thí nghiệm đi kèm vẫn chưa được công bố, vậy nên mình cũng không rõ paper này có phải là paper mõm hay không  )) Bài viết đến đây là hết, cảm ơn mọi người đã dành thời gian đọc.
)) Bài viết đến đây là hết, cảm ơn mọi người đã dành thời gian đọc.
All rights reserved
