
Các giải thuật tìm kiếm thường được sử dụng trong Natural Language Generation
Bài đăng này đã không được cập nhật trong 4 năm
Chào mọi người, trong bài viết này mình sẽ cùng mọi người tìm hiểu một số thuật toán tìm kiếm được sử dụng trong Natural Language Generation.
I. Tổng quan về Natural Language Generation
Natural Language Generation là gì?
Natural Language Generation(NLG) là việc sử dụng AI để tạo ra các câu chuyện viết hoặc nói từ một tập dữ liệu. NLG liên quan đến tương tác giữa người với máy và máy với người, bao gồm computational linguistics , natural language processing (NLP) and natural language understanding (NLU).
Natural Language Generation được sử dụng như thế nào?
- Tạo phản hồi của các chatbots(dialogue) và voice assistants như Alexa của Google và Siri của Apple
- Chuyển đổi các báo cáo tài chính và các loại dữ liệu kinh doanh khác thành nội dung dễ hiểu cho nhân viên và khách hàng
- Tự động hóa các phản hồi email, tin nhắn và trò chuyện của khách hàng tiềm năng
- Tổng hợp, tổng hợp các bản tin thời sự (Text summarization)
- Tạo mô tả sản phẩm cho các trang web thương mại điện tử và nhắn tin cho khách hàng
- Machine Translation
- Làm thơ
NLG trong Deep Learning
Trong Deep Learning hiện nay, NLG thường được biểu diễn bằng kiến trúc Encoder-Decoder. Encoder đọc văn bản đầu và trả về một vector đại diện cho văn bản đó, Decoder lấy vector đó rồi tạo ra một đoạn văn bản tương ứng.
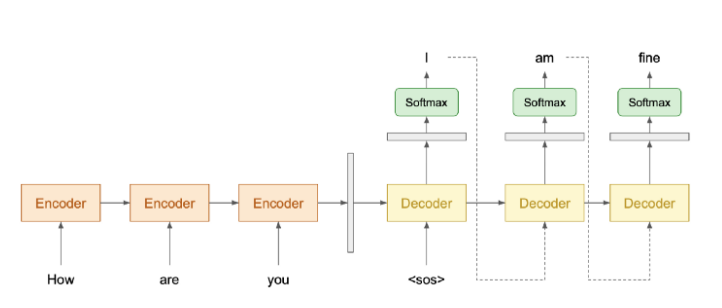
Các bạn có thể tham khảo thêm một số bài viết về NLG ở phần tài liệu tham khảo bên dưới.
II. Các giải thuật tìm kiếm trong NLG
VÌ sao cần các giải thuật tìm kiếm này?
Trong NLG khi chúng ta tạo ra các đoạn văn bản hay các câu, các giải thuật tìm kiếm giúp chúng ta tìm ra những câu hoặc đoạn văn hợp lý, giống ngôn ngữ con người và tránh những sự mơ hồ không đáng có khi sản sinh văn bản.
Tại mỗi bước thời gian trong quá trình decode, chúng ta lấy vector(chứa thông tin từ bước này sang bước khác) và tính toán xác suất khả năng xảy ra của mỗi từ bằng hàm softmax.
Greedy Decoding
Giải thuật này là đơn giản nhất. Tại mỗi bước thời gian nó chỉ cần chọn token có khả năng xảy ra cao nhất.
Mặc dù đơn giản là vậy và cảm tưởng có vẻ rất hợp lý nhưng trên thực tế nó lại tạo ra những đoạn văn bản không phải là tốt nhất có thể. Điều này do phân phối của dữ liệu gây ra khiến chúng ta mắc kẹt ở những kết quả chưa tốt.
Ví dụ greedy decoding tạo ra kết quả không tốt cho nhiệm vụ tóm tắt văn bản:

Beam Search
Do phân phối của dữ liệu nên Greedy Decoding không thể tìm ra được câu hợp lý nhất. Cách giải thích hợp lý hơn đó là do mỗi bước thời gian chúng ta cần tìm do đó chưa chắc tích các xác suất cao nhất ở mỗi bước thời gian là lớn nhất. Vậy nên để tìm kiếm xác suất lớn nhất ta phải xem xét toàn bộ xác suất của các token ở mỗi bước thời gian . Tìm kiếm đến cuối cùng có thể giải quyết vấn đề trước đó vì nó sẽ tìm kiếm toàn bộ không gian. Tuy nhiên, nó sẽ rất tốn kém về mặt tính toán. Giả sử có 10.000 từ vựng, để tạo ra một câu có độ dài 10 tokens, nó sẽ là (10.000) ¹⁰ - một con số quá lớn.
Beam search có thể đối phó với vấn đề này. Tại mỗi bước thời gian , nó tạo ra tất cả các token có thể có trong danh sách từ vựng, sau đó, nó sẽ chọn các k token có xác suất cao nhất . Xác suất của k token này sẽ là cơ sở để tính toán cho k token ở bước thời gian tiếp theo. Cuối cùng, ta có k đoạn văn bản được tạo ra. Không gian tìm kiếm chỉ là (10.000) * k.
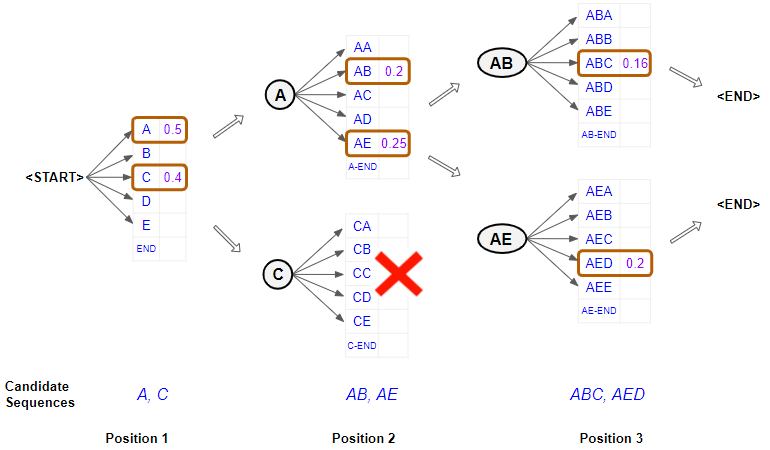
Hình ảnh minh họa Beam Search với k = 2
Beam search với k lớn sẽ có kết quả gần như là tìm kiếm trên toàn bộ không gian, và với k nhỏ(đặc biệt k = 1) sẽ cho ra kết quả giống hoặc gần giống với Greedy decoding.
Random sampling
Mặc dù beam search hiệu quả là vậy nhưng đôi khi trong 1 số nhiệm vụ nhất định ta lại thấy beam search khá tồi.
Hãy tưởng tượng khi khách hàng phản hồi tốt về sản phẩm của bạn, con bot của bạn chỉ biết nói "Cảm ơn"? ? Quá là nhàm chán. Random sampling sẽ giúp chúng ta thoát khỏi cảnh nhàm chán đó bằng câu khác như "Cảm ơn vì sự tin tưởng của quý khách dành cho chúng tôi".
? Quá là nhàm chán. Random sampling sẽ giúp chúng ta thoát khỏi cảnh nhàm chán đó bằng câu khác như "Cảm ơn vì sự tin tưởng của quý khách dành cho chúng tôi".
Giải thuật này khá đơn giản, ta chỉ cần chọn ngẫu nhiên một từ ở mỗi bước thời gian dưa vào phân phối xác suất của đầu ra hàm softmax. Với lấy mẫu ngẫu nhiên các token có xác suất 0.2 đôi khi lại không được chọn mà chọn token có xác suất 0.01. Nhưng đương nhiên là từ có xác suất 0.01 rất khó có khả năng xảy ra.
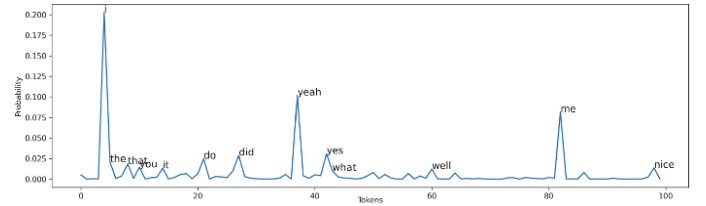
Random sampling với Temperature
Random sampling đôi khi tự nó có thể có khả năng tạo ra một từ rất ngẫu nhiên một cách tình cờ(như trình bày bên trên), không hợp lý chút nào. Temperature được sử dụng để tăng xác suất của các token có thể xảy ra trong khi giảm xác suất của token không hợp lý. Thông thường . Lưu ý khi việc sử dụng temperature không có ý nghĩa. Ta có hàm softmax mới như sau:
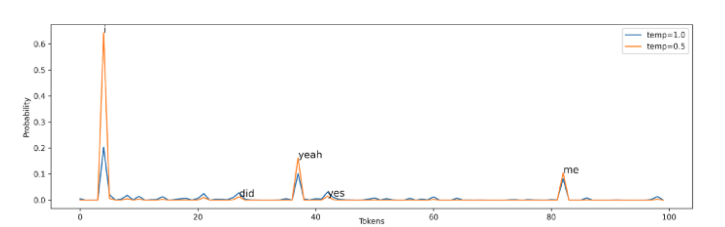
Trong hình trên, với = 0,5, các từ có thể xảy ra nhất như i , yeah , me , có nhiều cơ hội được tạo hơn. Đồng thời, điều này cũng làm giảm xác suất của những token ít có khả năng xảy ra hơn, mặc dù điều này chỉ làm giảm sự xảy ra của chúng.
Top-K Sampling
Random sampling hiệu quả nhưng đôi khi nó tạo ra những câu vô nghĩa, mặc dù đã sử dụng temperature nhưng việc tạo ra những câu không ai hiểu là chuyện vẫn có thể xảy ra. Để tránh điều này, Top-K Sampling được đề xuất. Trong Top-K sampling chỉ xem xét k token có xác suất cao nhất ở mỗi bước thời gian . GPT-2 đã áp dụng giải thuật này, đây là một trong những lý do giúp nó thành công trong việc tạo ra những câu chuyện.
Tùy từng tác vụ mà k được chọn là khác nhau, ví dụ như trong 1 số paper về Neural Machine Translation có đề xuất thì k = 10, nhưng với những nhiệm vụ tạo ra những bài thơ hay bài hát thì k có thể lớn hơn.
Ví dụ với k = 6:
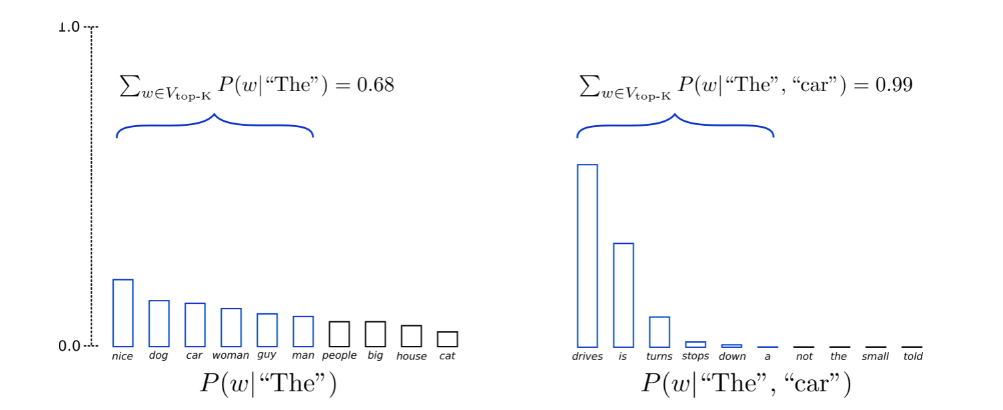
Như hình minh họa, top 6 tokens có xác suất cao nhất được xem xét và chọn ngẫu nhiên trong 6 tokens này.
Top-p(nucleus) sampling
Mặc dù được đánh giá rất cao và đã cho kết quả thực nghiệm tốt, nhưng gần đây các nhà nghiên cứu chỉ ra một số hạn chế của top-k sampling như là tổng xác suất của k token được chọn trên quá nhỏ dẫn đến thiếu đi một số lựa chọn thú vị, hoặc tổng xác suất của k token được chọn quá lớn khiến các từ không nên chọn vẫn tồn tại.
Thay vì xem xét xác suất của k token có nhiều khả năng nhất , trong Top-p sampling chọn các token có xác suất cao nhất sao cho tổng các xác suất này lớn hơn hoặc bằng p:
Bằng cách này, kích thước của tập hợp các token cần xem xét có thể tự động tăng và giảm theo phân phối xác suất của từng bước thời gian .
Ví dụ với p = 0.92:
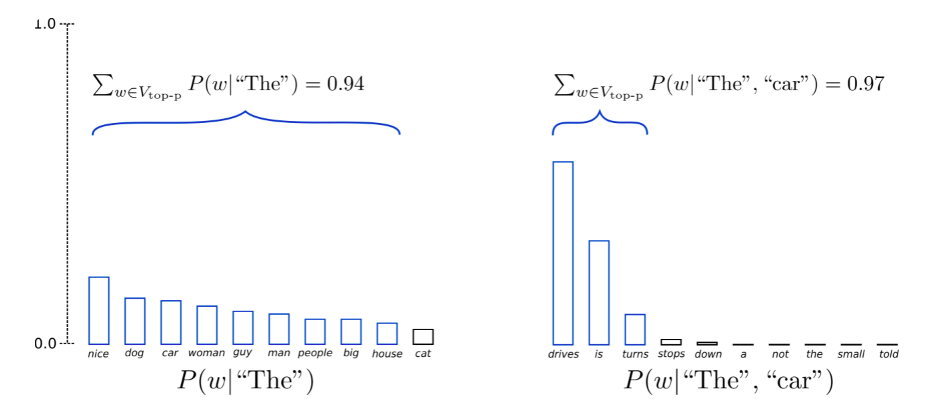
Như hình minh họa, top-p sampling sẽ chọn ra những token có xác suất cao nhất sao cho tổng xác suất
III. Tổng kết
- Như vậy mình đã cùng mọi người tìm hiểu sơ lược về các giải thuật tìm kiếm trong NLG.
- Không thể kết luận là giải thuật này tốt hơn giải thuật kia vì còn tùy từng nhiệm vụ như trong NMT thì thường là Beam search và Greedy decoding(top-k sampling cũng có thể được dùng nhưng phải trong những tập data rất lớn trên 10M câu), tạo ra các bài thơ thì thường là Random-sampling, Top-k sampling, v.v.
- Gần đây còn có một phương pháp mới đó là kết hợp cả top-k và top-p Sampling.
IV. Tài liệu tham khảo
- https://towardsdatascience.com/decoding-strategies-that-you-need-to-know-for-response-generation-ba95ee0faadc
- https://huggingface.co/blog/how-to-generate
- https://viblo.asia/p/cach-tao-ra-ngon-ngu-con-nguoi-tu-hu-vo-natural-language-generation-voi-language-model-GrLZD00JZk0
- https://searchenterpriseai.techtarget.com/definition/natural-language-generation-NLG
- https://www.youtube.com/watch?v=4uG1NMKNWCU - bài giảng về NLG trong khóa cs224n
All rights reserved
