
Bạn đã biết gì về prompt engineering? (P3) - Cải thiện Retrieval Augmented Generation (RAG) với query transformation
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài trước mình đã giới thiệu sơ qua về RAG - Retrieval Augmented Generation - một phương pháp hữu hiệu giải quyết vấn đề hallucination cho các bài toán dùng LLM để truy xuất và cung cấp thông tin.
RAG giúp nâng cao kiến thức của mô hình ngôn ngữ bằng thông tin từ các nguồn bên ngoài đáng tin cậy như Wikipedia, các tài liệu về một vấn đề cụ thể. Vì vậy bước quan trọng nhất đối với RAG là đảm bảo rằng quá trình truy xuất sẽ tìm thấy đúng đoạn thông tin để đưa vào mô hình. Nhất là khi hiện tại chúng ta phải đổi mặt với các vấn đề như:
- Không thể đưa toàn bộ các tài liệu vào trong mô hình do hạn chế về context length, chi phí, độ trễ, vv.
- Hiện tượng "lost in the middle": tức là khi mô hình gặp khó khăn trong việc sử dụng thông tin nằm ở phần giữa trong một đoạn input dài
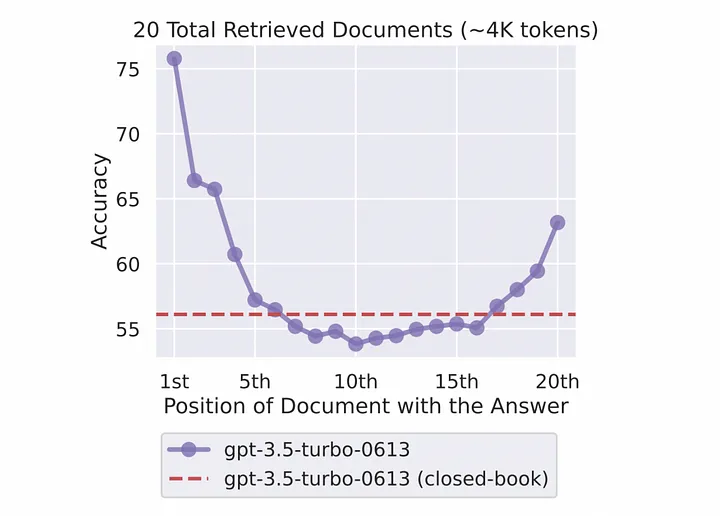
Có nhiều kỹ thuật để cải thiện độ chính xác của RAG. Trong bài viết này mình sẽ đề cập và giới thiệu về các phương pháp query transformation (biến đổi truy vấn).
Ý tưởng của query transformation là: trong nhiều trường hợp, truy vấn (câu hỏi) của người dùng có thể không thể hiện sự tương đồng với các tài liệu liên quan trong cơ sở dữ liệu (ví dụ người dùng sử dụng các cách diễn đạt, từ ngữ khác với trong tài liệu). Trong những trường hợp này, chúng ta có thể biến đổi truy vấn để tăng mức độ liên quan của truy vấn đó với các tài liệu trước khi truy xuất thông tin liên quan và đưa vào mô hình ngôn ngữ.
1. Rewrite-Retrieve-Read
Trong các trường hợp thực tế, không phải lúc nào câu hỏi của người dùng cũng được viết một cách tối ưu cho việc tìm kiếm và truy xuất thông tin. Ví dụ có những người dùng chỉ nhập một từ khóa duy nhất, có những người lại nhập một câu hỏi dài dòng rằng thì là mà, vv.. Cách tiếp cận này sử dụng LLM để viết lại truy vấn của người dùng, thay vì trực tiếp sử dụng nguyên văn câu gốc, sau đó tiến hành truy xuất thông tin bằng RAG.
Bài báo gốc cũng đề xuất một pipeline với phần rewriter có thể train được, bạn có thể xem thêm tại đây.
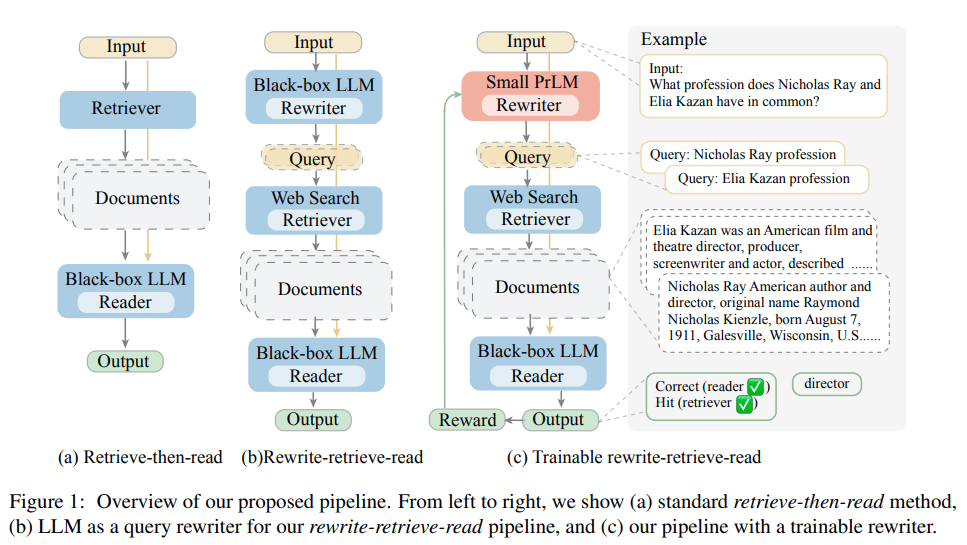
Implement sử dụng Langchain: link
2. Multi Query Retrieval
Kỹ thuật Multi Query Retrieval sử dụng cách tiếp cận chia để trị (divide-and-conquer) để xử lý các câu hỏi phức tạp. Đầu tiên mô hình ngôn ngữ sẽ phân tích câu hỏi truy vấn và chia chúng thành các câu hỏi phụ đơn giản hơn. Mỗi câu hỏi phụ nhắm đến các tài liệu liên quan khác nhau có thể cung cấp một phần câu trả lời chính xác. Sau đó, hệ thống sẽ thu thập các câu trả lời phụ và tổng hợp tất cả các kết quả từng phần thành đáp án cuối cùng.
Implement sử dụng LlamaIndex: link
Một chiến lược khác là sử dụng LLM để tạo ra nhiều truy vấn tìm kiếm dựa vào một câu hỏi đầu vào. Sau đó, các truy vấn có thể được thực hiện song song và các kết quả được truy xuất sẽ được kết hợp với nhau để input vào generation model. Một truy vấn có thể không nắm bắt được toàn bộ phạm vi những gì người dùng quan tâm hoặc có thể quá hẹp để mang lại kết quả toàn diện. Vì vậy việc tạo nhiều truy vấn từ các góc độ khác nhau cũng có thể phát huy tác dụng.
Implement sử dụng Langchain: link
3. RAG-Fusion
Đây cũng là một kỹ thuật phổ biến gần đây xây dựng trên nền của Multi Query Retrieval. Nó bao gồm các bước sau:
- Query Generation: tạo nhiều truy vấn từ truy vấn ban đầu của người dùng bằng LLM
- Vector Search: tiến hành tìm kiếm bằng vector trên mỗi truy vấn được tạo để truy xuất các tài liệu có liên quan từ một tập có sẵn
- Reciprocal Rank Fusion: áp dụng thuật toán Reciprocal Rank Fusion để xếp hạng lại các tài liệu dựa trên mức độ liên quan của chúng trên nhiều truy vấn
- Output Generation: tạo ra kết quả cuối cùng dựa trên danh sách tài liệu đã được xếp hạng lại ở bước trên
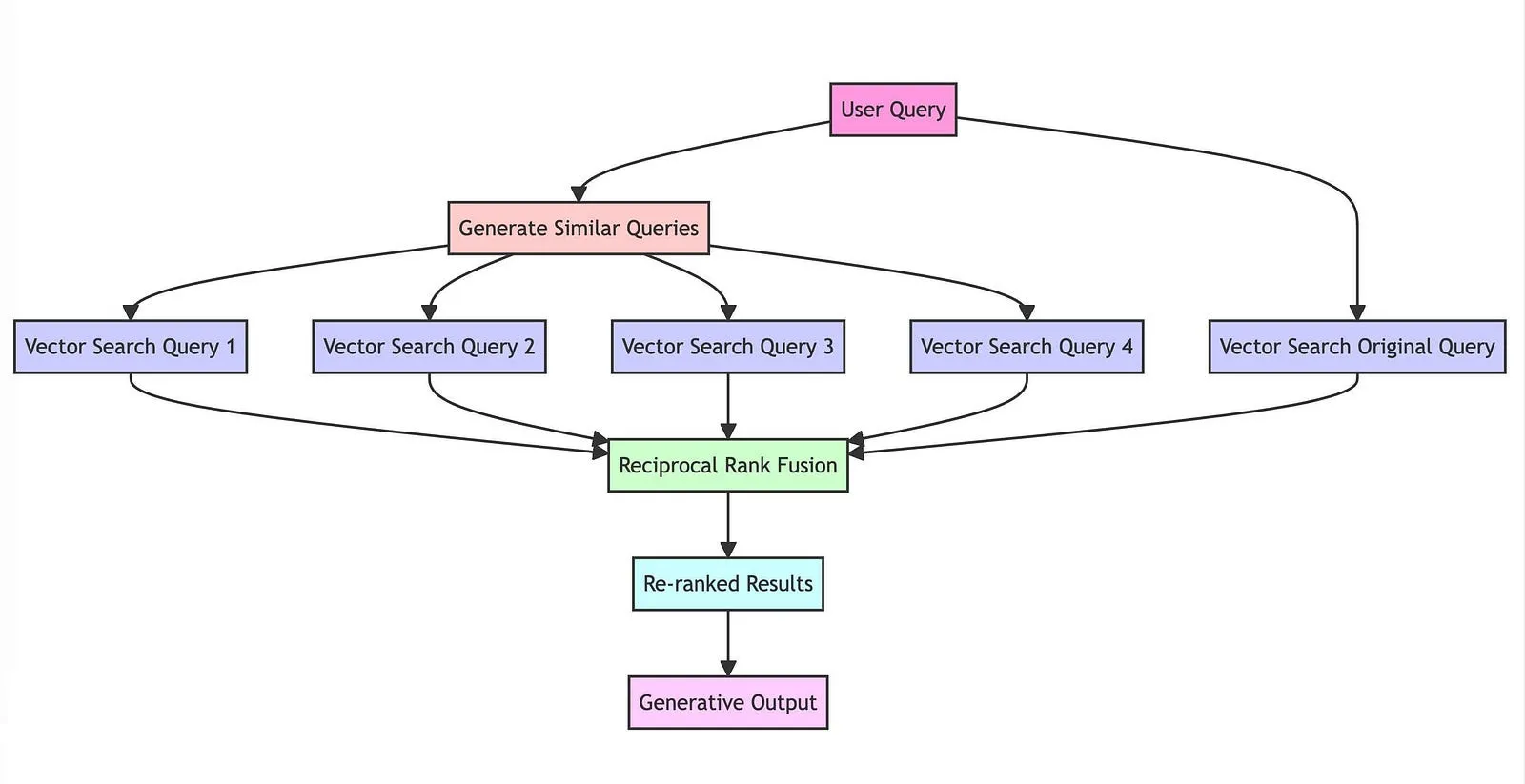
Github repo: link
4. HyDE
Hypothetical Document Embeddings (HyDE) là một kỹ thuật sử dụng embedding để truy xuất các tài liệu liên quan mà không cần training data thực tế. Đầu tiên, ta sẽ sử dụng LLM tạo ra một câu trả lời giả định để trả lời cho câu truy vấn. Câu trả lời này có thể có các thông tin không thực sự đúng (hallucination) nhưng chúng ta kỳ vọng nó sẽ bao gồm các pattern có liên quan đến truy vấn của người dùng và cả câu trả lời chính xác.
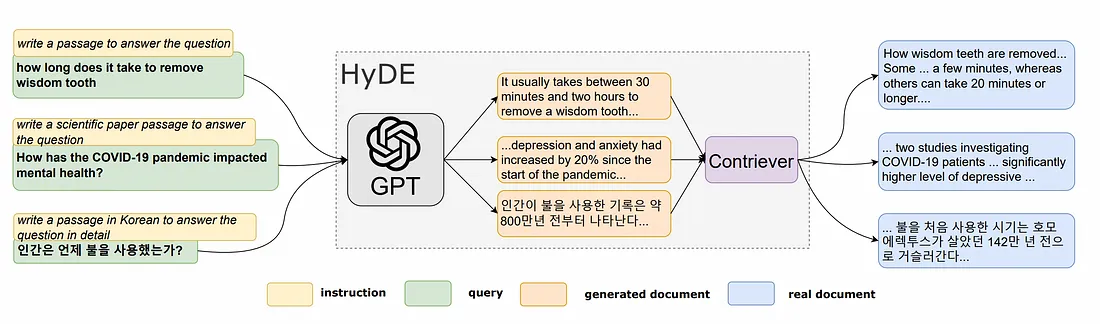
Bước tiếp theo, cả câu truy vấn và câu trả lời giả định sẽ được chuyển thành embedding vector. Hệ thống sẽ truy xuất trong DB các đoạn thông tin gần nhất với embedding này để đưa ra câu trả lời.
Implement sử dụng LlamaIndex: link
5. Multi-Step Query Transformation
Biến đổi truy vấn nhiều bước (Multi-Step Query Transformation) dựa trên phương pháp tự hỏi, trong đó mô hình ngôn ngữ sẽ tự đưa ra và trả lời các câu hỏi thêm (follow-up questions) trước khi trả lời câu hỏi ban đầu. Cách này giúp mô hình kết hợp các dữ kiện và thông tin riêng biệt mà nó học được từ trước.
Theo tác giả bài báo gốc, LLM thường không kết hợp được hai mẩu thông tin với nhau. Ví dụ: một mô hình có thể biết Fact A và Fact B nhưng không thể suy ra được hàm ý khi kết hợp 2 thông tin này. Phương pháp tự hỏi nhằm khắc phục hạn chế này.
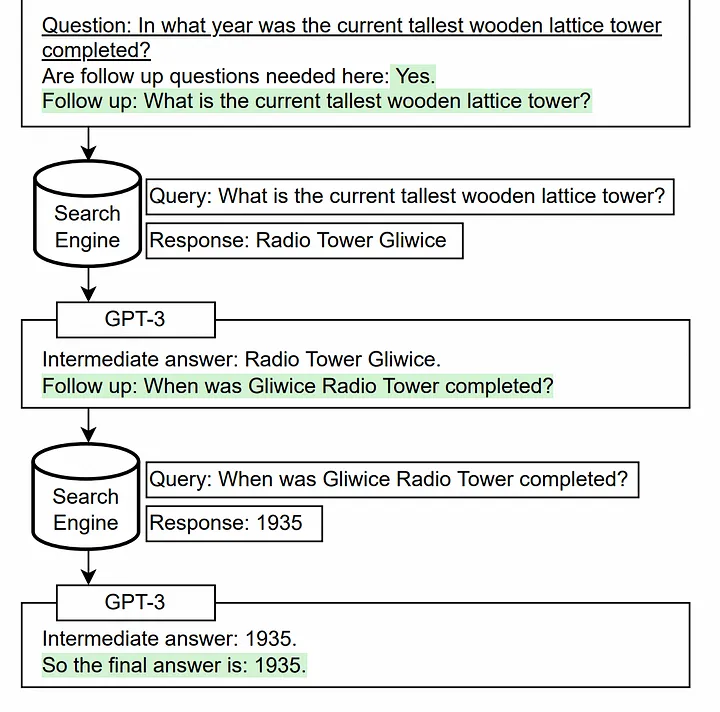
Implement sử dụng LlamaIndex: link
Kết luận
Trong bài này mình đã giới thiệu các phương pháp biến đổi truy vấn (query transformation) nhằm cải thiện kết quả của Retrieval Augmented Generation. Hy vọng có thể giúp các bạn có một số cách tiếp cận hữu ích cho bài toán của mình. Hẹn gặp các bạn trong các bài viết sau!
Reference
All rights reserved
