
Bạn đã biết gì về prompt engineering? (P2) - Retrieval Augmented Generation - cứu cánh cho sự "ảo tưởng" của các LLM
Bài đăng này đã không được cập nhật trong 2 năm
Gần đây, sự phát triển của các mô hình ngôn ngữ lớn đã mở đường cho những tiến bộ vượt bậc trong lĩnh vực xử lý ngôn ngữ tự nhiên cũng như đẩy mạnh việc ứng dụng AI tạo sinh vào cuộc sống. Tuy nhiên, những mô hình mạnh mẽ này cũng đi kèm với một số thách thức cần phải giải quyết. Một trong những vấn đề lớn là hiện tượng "hallucination" - ảo giác, tức việc LLM tạo ra các thông tin không chính xác, không đúng sự thật hoặc không được hỗ trợ bởi dữ liệu có sẵn. Hiện tượng này rất nguy hiểm bởi nó có thể dẫn đến việc cung cấp các thông tin sai lệch gây hậu quả nghiêm trọng và làm giảm độ tin cậy của các hệ thống dựa trên AI. Trong bài viết này, chúng ta sẽ tìm hiểu về Retrieval Augmented Generation (RAG), một kỹ thuật cực kỳ hữu ích và đang được sử dụng rộng rãi, giúp giải quyết vấn đề trên.
1. Một số vấn đề thường gặp khi ứng dụng LLM
- LLM bị outdated: Ví dụ như dữ liệu đào tạo của ChatGPT bị đóng băng ở thời điểm tháng 9/2021. Nếu bạn hỏi ChatGPT về một sự kiện gì đó vào tháng trước, tình hình thời tiết, chính sách mới, vv. thì nó sẽ không những không cung cấp được thông tin chính xác cho bạn mà còn có thể sẽ "ảo tưởng" ra một câu trả lời nghe có vẻ rất thuyết phục.
- Domain-specific knowledge: LLM được đào tạo cho các nhiệm vụ tổng quát (generalized tasks), nghĩa là nó sẽ không biết dữ liệu riêng tư của bạn, công ty bạn, cũng như thiếu các kiến thức ngành chuyên sâu hoặc thông tin về một đối tượng rất cụ thể nào đó (ví dụ sản phẩm mới ABC của một công ty XYZ)
- LLM hoạt động như một hộp đen: Chúng ta không thể biết được LLM đã sử dụng những nguồn thông tin nào để đưa ra được câu trả lời
 Chúng ta có thể giải quyết được một phần nào vấn đề hallucination bằng prompt engineering. Tuy nhiên để LLM có thể trả lời các câu hỏi yêu cầu những thông tin mới, thông tin chuyên ngành thì chúng ta cần đến một công cụ mạnh mẽ hơn.
Chúng ta có thể giải quyết được một phần nào vấn đề hallucination bằng prompt engineering. Tuy nhiên để LLM có thể trả lời các câu hỏi yêu cầu những thông tin mới, thông tin chuyên ngành thì chúng ta cần đến một công cụ mạnh mẽ hơn.
2. Retrieval Augmented Generation là gì
Retrieval Augmented Generation (RAG) là một phương pháp được giới thiệu bởi các nhà nghiên cứu của Meta AI để giải quyết các task yêu cầu nhiều kiến thức (knowledge-intensive). RAG là kết hợp của thành phần truy xuất thông tin (Retrieval) với mô hình tạo sinh văn bản (Generation).
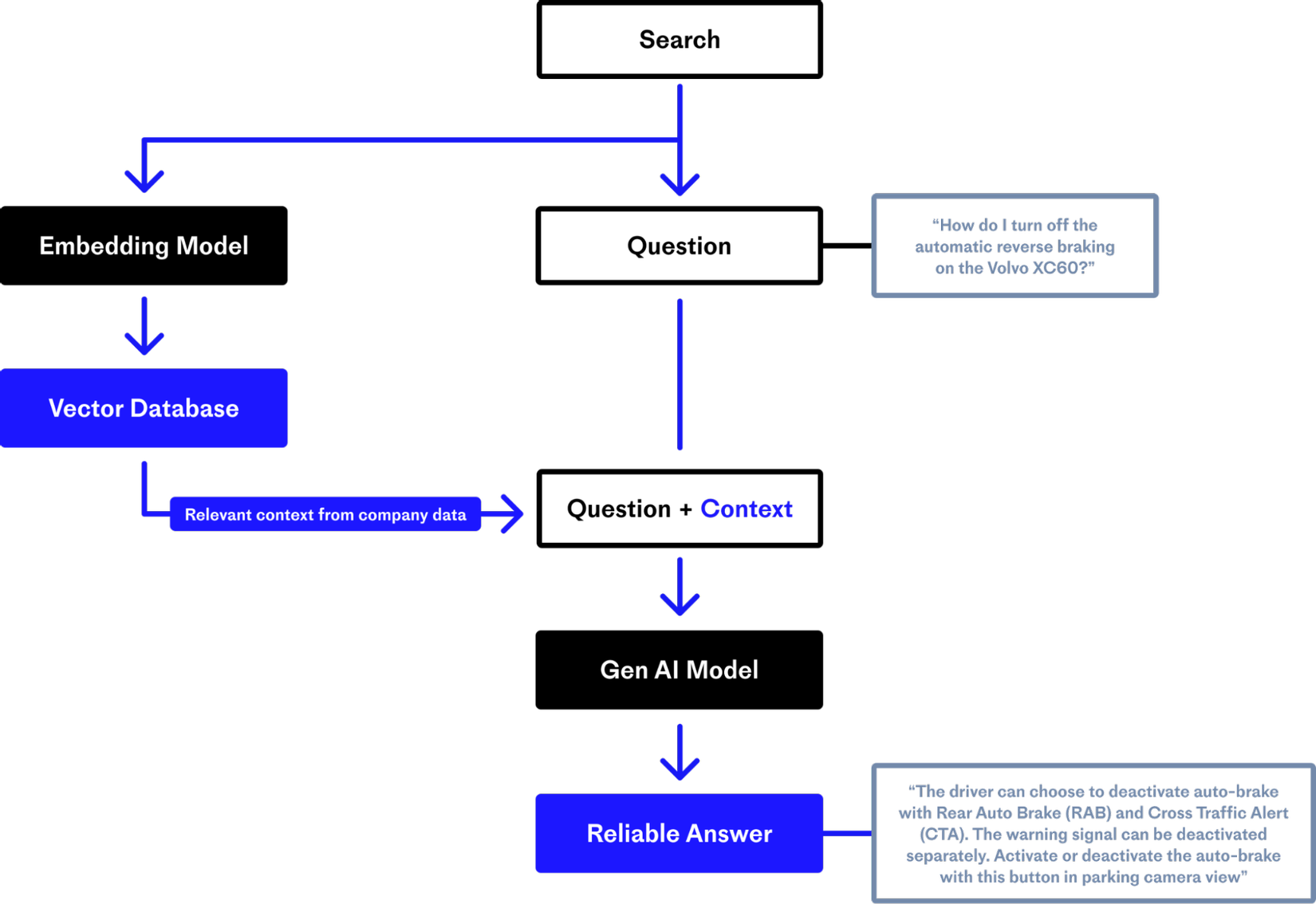
- Các tài liệu, kiến thức từ một nguồn (ví dụ: Wikipedia, Google drive, vv.) được embed bằng Embedding model và index vào Vector Database để phục vụ cho truy vấn.
- RAG lấy input đầu vào và dùng nó để truy xuất ra một tập hợp các tài liệu có liên quan.
- Sau đó, các tài liệu được thêm vào prompt dưới dạng in-context learning và được đưa vào generation model để tạo ra phản hồi.
- Một prompt ví dụ:
"""Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
{context}
Question: {question}
Helpful Answer:"""
3. Tác dụng của RAG:
- Có khả năng đáp ứng với các bài toán mà nguồn thông tin/ kiến thức có sự phát triển, biến đổi qua thời gian.
- Chúng ta không cần phải tốn chi phí đào tạo hay fine tune lại LLM mà vẫn có thể sử dụng nguồn thông tin mới nhất để tạo ra những kết quả chính xác, đáng tin cậy.
- Cho phép các LLM cung cấp nguồn, giống như cách các paper nghiên cứu trích dẫn tài liệu tham khảo. Hãy tưởng tượng một ứng dụng phục vụ ngành pháp lý bằng cách giúp các luật sư chuẩn bị tranh luận. RAG cho phép ứng dụng cung cấp các trích dẫn về tiền lệ pháp lý, luật pháp địa phương và bằng chứng mà nó sử dụng khi đưa ra các đề xuất của mình.
- RAG giúp hoạt động bên trong của các ứng dụng AI tạo sinh dễ kiểm tra (audit) và hiểu hơn. Nó cho phép người dùng cuối truy cập thẳng vào cùng một tài liệu nguồn mà LLM đã sử dụng khi tạo câu trả lời.
Kết luận
Trong bài viết này, chúng ta đã khám phá khái niệm Retrieval Augmented Generation (RAG) và ứng dụng của nó trong việc giảm thiểu các vấn đề ảo giác trong các mô hình ngôn ngữ lớn. RAG thể hiện sự hợp nhất của hai thành phần cơ bản: truy xuất và tạo sinh. Nó tận dụng độ chính xác của việc truy xuất thông tin để lấy dữ liệu liên quan từ cơ sở kiến thức rộng lớn và kết hợp nó với khả năng sáng tạo của các mô hình ngôn ngữ lớn để tạo ra các phản hồi chính xác về mặt thực tế và mạch lạc theo ngữ cảnh.
Với việc liên tục cải tiến và áp dụng RAG cũng như các kỹ thuật tương tự, chúng ta sẽ ngày càng tiến gần hơn đến một tương lai nơi các mô hình ngôn ngữ trở thành những công cụ không những mạnh mẽ mà còn đáng tin cậy trong hành trình tìm kiếm kiến thức, thông tin và giao tiếp có ý nghĩa.
Reference
All rights reserved
