
Bạn đã biết cách sinh mã duy nhất cho hệ thống phân tán chưa???
Bài đăng này đã không được cập nhật trong 2 năm
Trong lĩnh vực các hệ thống phân tán quy mô lớn, một thành phần quan trọng thường ẩn phía sau là Bộ Sinh Mã Định Danh Duy Nhất (ví dụ như sinh mã primary key cho table trong database). Những mã định danh này đóng vai trò then chốt trong việc đảm bảo tính toàn vẹn, nhất quán và khả năng mở rộng của các ứng dụng hiện đại. Trong bài viết này, chúng ta sẽ khám phá vào thế giới của nó, tìm hiểu tầm quan trọng, các loại khác nhau, ưu và nhược điểm của chúng.
Suy nghĩ đầu tiên của bạn là ta có thể sử dụng một khóa chính với thuộc tính tự động tăng (auto_increment) trong một cơ sở dữ liệu truyền thống. Tuy nhiên, thuộc tính auto_increment không phù hợp trong môi trường phân tán bởi vì một máy chủ cơ sở dữ liệu đơn lẻ không đủ lớn và việc tạo ra các ID duy nhất trên nhiều cơ sở dữ liệu với độ trễ tối thiểu là một thách thức vô cùng lớn.
Đây là một ví dụ về IDs duy nhất:

Bạn cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha. Và chúng mình có động lực ra những bài viết thú vị hơn nữa 😄😄😄
Cùng Sydexa khám phá công nghệ vô cùng quan trọng này nha!!! 😄😄
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Bước 1 - Hiểu rõ vấn đề và xác định phạm vi bài toán
Trong bất kỳ cuộc phỏng vấn thiết kế hệ thống nào, bước đầu tiên và quan trọng nhất là đặt những câu hỏi để làm rõ vấn đề. Dưới đây là một ví dụ về tương tác giữa ứng viên và người phỏng vấn, mô tả cách tiếp cận vấn đề:
Ứng viên: Đặc điểm của các ID duy nhất lEà gì?
Người phỏng vấn: ID phải là duy nhất và có thể sắp xếp được.
Ứng viên: Mỗi khi có bản ghi mới, ID có tăng lên 1 không?
Người phỏng vấn: ID tăng theo thời gian nhưng không nhất thiết chỉ tăng lên 1. ID được tạo vào buổi tối sẽ lớn hơn những ID được tạo vào buổi sáng cùng ngày.
Ứng viên: ID có phải chỉ bao gồm giá trị số không?
Người phỏng vấn: Đúng vậy.
Ứng viên: Yêu cầu về độ dài ID là bao nhiêu?
Người phỏng vấn: ID phải vừa với 64-bit.
Ứng viên: Quy mô của hệ thống là gì?
Người phỏng vấn: Hệ thống phải có khả năng tạo ra 10,000 ID mỗi giây.
Trên đây là một số câu hỏi mẫu bạn có thể hỏi người phỏng vấn của mình. Việc hiểu rõ các yêu cầu và làm rõ những điểm mơ hồ là rất quan trọng. Đối với câu hỏi phỏng vấn này, các yêu cầu có thể được liệt kê như sau:
- ID phải là duy nhất.
- ID chỉ là các giá trị số.
- ID phải phù hợp với 64-bit.
- ID được sắp xếp theo ngày.
- Có khả năng tạo ra hơn 10,000 ID duy nhất mỗi giây.
Bước 2 - Các thiết kế tổng quan
Có nhiều phương pháp có thể được sử dụng để tạo ID duy nhất trong các hệ thống phân tán. Các phương án mà chúng ta xem xét bao gồm:
- Multi-master replication
- UUID
- Ticket server
- Twitter snowflake
Ta xem xét từng phương án, cách thức hoạt động và ưu nhược điểm của chúng.
Multi-master replication
Được minh họa như hình dưới đây:
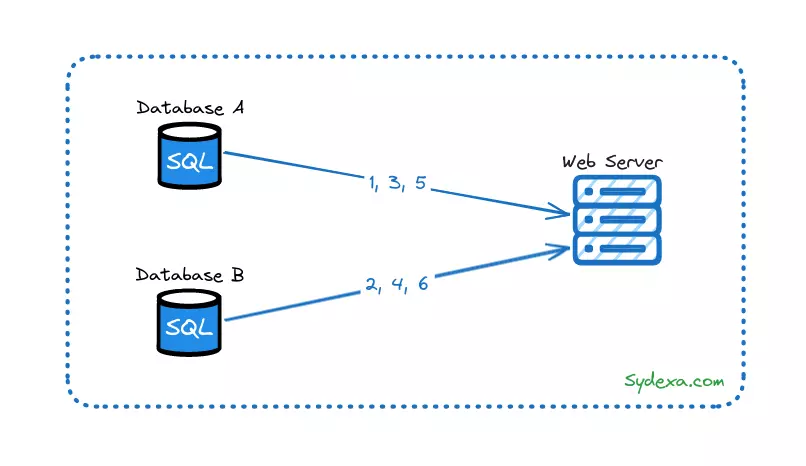
Phương pháp này sử dụng tính năng tự động tăng (auto_increment) của cơ sở dữ liệu. Thay vì tăng ID tiếp theo lên 1, nó được tăng lên k, trong đó k là số máy chủ cơ sở dữ liệu đang sử dụng. Như trong hình minh họa, sử dụng 2 máy chủ cơ sở dữ liệu cho nên k = 2, ID tiếp theo được tạo ra bằng ID trước đó trên cùng một máy chủ cộng thêm 2. Với k = 3 cũng tương tự như vậy:
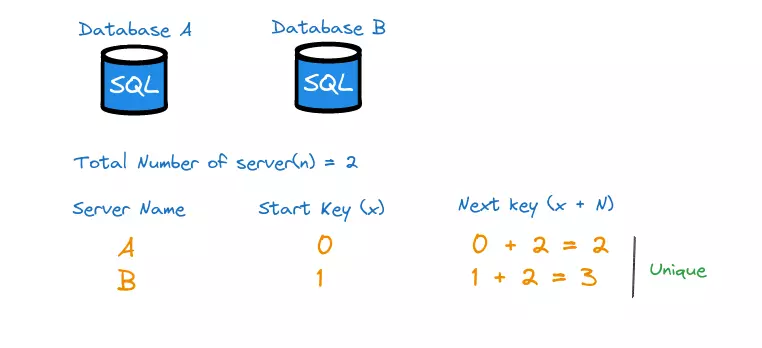
Cách này có những ưu và nhược điểm như sau:
✅ Ưu điểm
- Dễ dàng triển khai
- Mỗi máy chủ độc lập với nhau
- Tối ưu chi phí
❌ Nhược điểm
- Nếu ta tăng hoặc giảm số lượng máy chủ thì ta sẽ phải cập nhật lại bộ đếm trên tất cả các máy chủ 😢
- ID không tăng theo thời gian trên nhiều máy chủ: Giả sử máy chủ A tạo ID tại thời điểm 1 và máy chủ B tạo ID tại thời điểm 2. Dù thời điểm 2 sau thời điểm 1 nhưng không có gì đảm bảo rằng ID tạo ra tại thời điểm 2 sẽ lớn hơn ID tạo ra tại thời điểm 1, vì mỗi máy chủ tạo ID một cách độc lập.
Universally Unique Identifier (UUID)
Khi nói về việc tạo ID duy nhất, UUIDs hay Universal Unique Identifiers thường được nhắc đến.
Một UUID được tạo thành từ 32 ký tự hệ cơ số 16 (hex). Mỗi ký tự là 4 bit. Vì vậy, tổng cộng là 128 bit. Có 5 phần được phân chia bởi dấu gạch ngang. Tổng cộng ta có 32 ký tự hex + 4 dấu gạch ngang = 36 ký tự
6e965784–98ef-4ebf-b477–8bd14164aaa4
5fd6c336-48c4-4510-bfe5-f7928a83a3e2
0333be18-5ecc-4d7e-98d4-80cc362e4ade
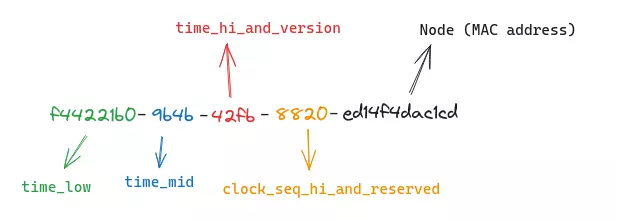
"Làm thế nào để UUID đảm bảo được tính ngẫu nhiên và duy nhất?"
Bí mật nằm ở khả năng va chạm cực thấp của nó.
“Tưởng tượng bạn tạo ra 1 tỷ UUID mỗi giây trong suốt 86 năm và chỉ khi đó bạn mới có 50% cơ hội nhận được một id trùng khớp”
Trong thiết kế này, mỗi máy chủ web đều chứa một bộ sinh ID, và mỗi máy chủ web sẽ tự chịu trách nhiệm sinh ID mà không cần phối hợp với các máy chủ khác.
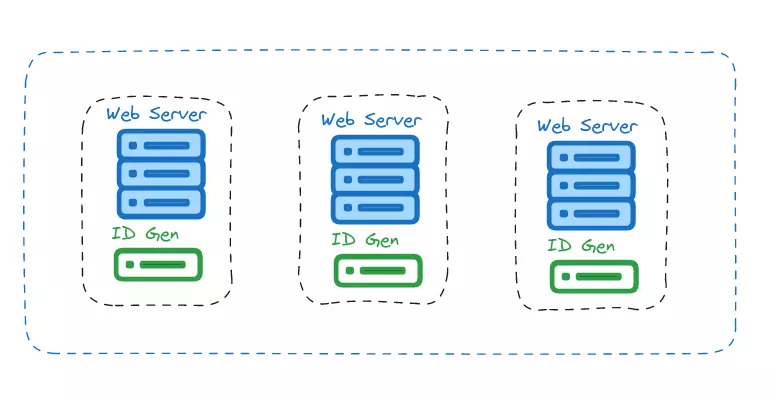
✅ Ưu điểm:
- Việc tạo UUID rất đơn giản. Không cần phối hợp giữa các máy chủ nên sẽ không có vấn đề trong việc đồng bộ hóa.
- Hệ thống dễ dàng mở rộng vì mỗi máy chủ web tự chịu trách nhiệm sinh ID mà nó sử dụng. Bộ sinh ID có thể dễ dàng mở rộng cùng với máy chủ web.
❌ Nhược điểm:
- ID dài 128 bit, nhưng yêu cầu ban đầu của chúng ta là 64 bit.
- ID không tăng theo thời gian.
- ID có thể không phải là số.
Ticket Server
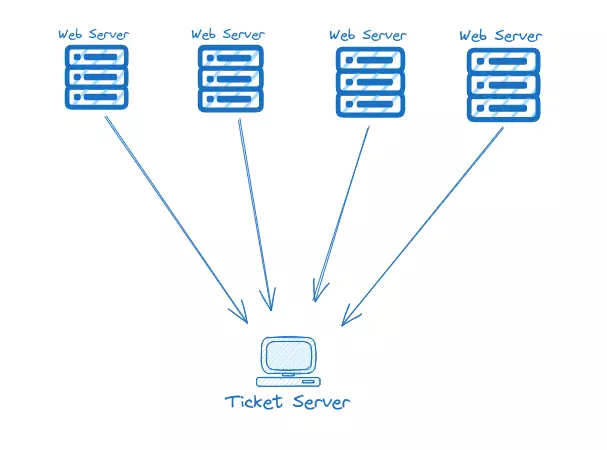
Bằng cách sử dụng bảng SQL và tính năng tự tạo ID tăng dần cho khoá chính. Những ID này là tuần tự nên chúng có thể sắp xếp một cách tự nhiên. Hơn nữa, chúng ta cũng có thể giới hạn kích thước ID thành 32 hoặc 64 bit.
Tuy nhiên, phương pháp này có nhược điểm sau:
- Vì chỉ có một cơ sở dữ liệu duy nhất nên đây trở thành điểm lỗi duy nhất (single point of failure) (Nếu vì một lý do nào đó cơ sở dữ liệu không khả dụng, hệ thống của ta có thể bị ngừng hoạt động).
Để làm cho thiết kế này có thể mở rộng, chúng ta có thể chia bảng SQL của mình thành nhiều máy chủ cơ sở dữ liệu. Ví dụ, chúng ta có thể tạo hai ticket servers (Với hai backend SQL khác nhau) để đạt được tính có sẵn cao và để khắc phục cho điểm lỗi duy nhất.
Tuy nhiên, nhược điểm của giải pháp này là chúng ta có thể nhận được hai id giống nhau từ hai ticket servers. Một cách để xử lý việc này là đảm bảo rằng cả hai máy chủ tạo ra các loại id khác nhau (chẵn và lẻ)

Một hạn chế của phương pháp mở rộng trên là chúng ta mất khả năng sắp xếp của id. Ví dụ, nếu một id của TicketServer1 là 101 và một id khác của TicketServer2 là 202, chúng ta không thể chắc chắn id nào được tạo ra trước (Vì TicketServer2 202 có thể đã được tạo ra trước 101 trên TicketServer1 nhưng so sánh số cho chúng ta biết ngược lại)
Nói cách khác, việc sử dụng một cơ sở dữ liệu duy nhất tạo ra điểm lỗi duy nhất. Việc sử dụng nhiều cơ sở dữ liệu, không thể đảm bảo rằng chúng có thể sắp xếp theo thời gian, đồng thời có thách thức trong việc đồng bộ hóa dữ liệu.
Snowflake from Twitter
Các phương pháp đã nêu trên cho chúng ta một số ý tưởng về cách các hệ thống tạo ID khác nhau hoạt động. Tuy nhiên, không có phương pháp nào đáp ứng được yêu cầu ban đầu của chúng ta. Do đó, chúng ta cần một phương pháp khác. Hệ thống tạo ID duy nhất của Twitter có tên là “snowflake” có thể đáp ứng yêu cầu của chúng ta.
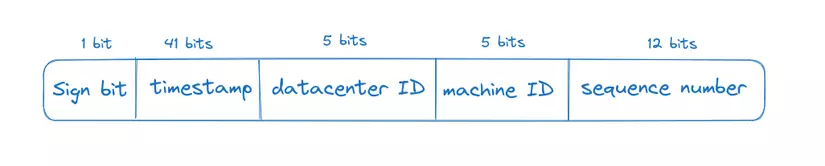
Thay vì tạo một ID trực tiếp, chúng ta chia ID thành các phần khác nhau. Hình trên cho thấy cấu trúc của một ID 64 bit.
Mỗi phần được giải thích bên dưới đây.
- Sign bit: 1 bit. Nó sẽ luôn là 0. Nó có thể được sử dụng để phân biệt giữa các số có dấu và không dấu.
- Timestamp: 41 bit. Mặc định epoch của Twitter snowflake là 1288834974657, tương đương với 01:42:54 UTC, ngày 04 tháng 11 năm 2010.
- Datacenter ID: 5 bit, cho ta 2^5 = 32 trung tâm dữ liệu.
- Machine ID: 5 bit, cho ta 2^5 = 32 máy trên mỗi trung tâm dữ liệu.
- Sequence number: 12 bit. Đối với mỗi ID được tạo, số thứ tự tăng lên 1. Số này được đặt lại về 0 sau mỗi millisecond.
Bước 3 - Thiết kế sâu hơn.
Trong thiết kế tổng quan, ta đã thảo luận về các lựa chọn khác nhau để thiết kế một bộ tạo ID duy nhất trong các hệ thống phân tán. Chúng ta quyết định sử dụng một phương pháp dựa trên bộ tạo ID Snowflake của Twitter. Cùng tìm hiểu sâu hơn về thiết kế. Ta xem lại hình bên dưới đây.
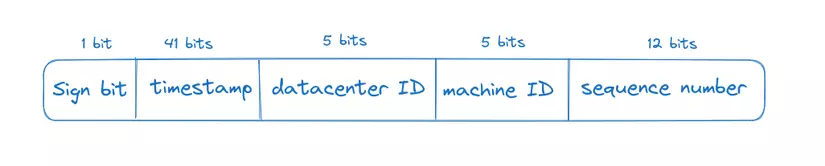
ID của trung tâm dữ liệu và ID máy được chọn vào giai đoạn khởi động hệ , nói chung sẽ được cố định một khi hệ thống đang hoạt động. Bất kỳ thay đổi nào trong Datacenter ID và Machine ID đều yêu cầu xem xét cẩn thận vì một sự thay đổi tình cờ trong những giá trị này có thể dẫn đến xung đột ID. Timestamp và Sequence number được tạo ra có yêu cầu tạo ID mới.
Timestamp
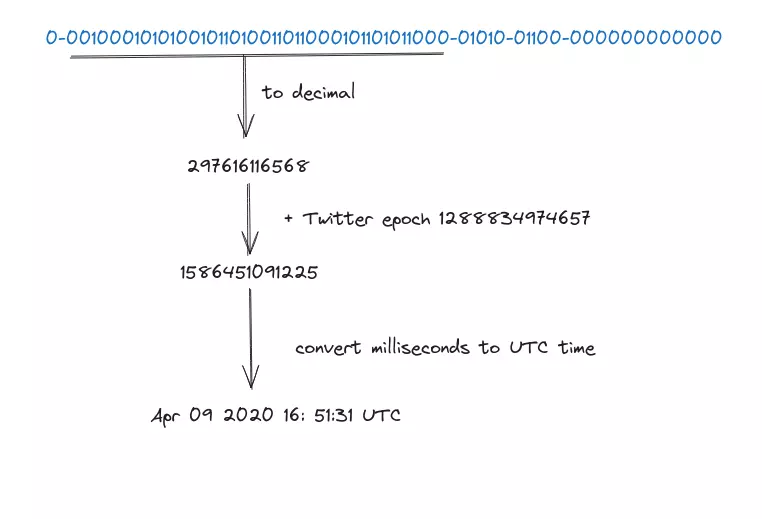
41 bit đầu tiên từ trái sang sau bit 0 tạo nên Timestamp. Khi Timestamp tăng theo thời gian, ID có thể được sắp xếp theo thời gian. Hình này cho thấy một ví dụ về cách biểu diễn nhị phân được chuyển đổi sang UTC. Ta cũng có thể chuyển đổi UTC trở lại biểu diễn nhị phân bằng cách sử dụng một phương pháp tương tự.
Sequence number
Sequence number là 12 bit, cho chúng ta 2^12 = 4096 tổ hợp. Như vậy, một máy có thể hỗ trợ tối đa 4096 ID mới mỗi mili giây.
Bước 4 - Kết luận
Ta đã thảo luận về các phương pháp khác nhau để thiết kế một trình tạo ID duy nhất. Ta chọn snowflake vì nó hỗ trợ tất cả các trường hợp sử dụng và có thể mở rộng trong một môi trường phân tán.
Nếu còn thời gian ở cuối cuộc phỏng vấn, có thể thảo luận một số điểm:
- Về đồng bộ hóa đồng hồ: Trong thiết kế của chúng ta, ta giả định rằng các máy chủ tạo ID có cùng một đồng hồ. Giả định này có thể không đúng khi một máy chủ đang chạy trên nhiều lõi.
- Về điều chỉnh độ dài của các phần: Chẳng hạn dùng ít bit hơn cho sequence number và phần timestamp nhiều bit hơn thì sẽ hiệu quả cho các ứng dụng có tính toán song song thấp.
- Về khả năng đáp ứng liên tục cao: Vì trình tạo ID là một hệ thống quan trọng, nó phải có khả năng hoạt động liên tục cao.
Và đó là một chuyến thám công nghệ giúp sinh mã định danh cho những hệ thống lớn. Sydexa hẹn các bạn ở một bài viết thú vị nữa nha 😍😍😍😍
Nếu thấy bài viết này hay thì cho chúng mình xin 1 upvote và comment để chúng mình nhận giải của viblo nha 😄😄😄
Lời nhắn
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
All rights reserved
