
Autocomplete - Bài toán kinh điển trong các hệ thống tìm kiếm
Bài đăng này đã không được cập nhật trong 2 năm
Autocomplete là một tính năng quan trọng nếu dịch vụ của bạn hỗ trợ chức năng tìm kiếm. Nó không chỉ giúp người dùng nhanh chóng gõ ra từ khoá cần tìm kiếm mà còn gợi ý cho người dùng nên tìm kiếm cái gì.
Yêu cầu của bài toán này là lưu trữ, xử lý hàng tỷ xâu được nhập bởi hàng triệu người dùng dưới trạng Trie, sau đó với mỗi truy vấn của người dùng, đưa ra gợi ý những xâu bắt đầu bằng những gì người dùng đã nhập vào. Có thể có rất nhiều xâu khớp với xâu truy vấn của người dùng, chúng ta chỉ cần lấy ra 7 xâu có độ ưu tiên lớn nhất.
Cụ thể hơn:
- Độ trễ thấp: các gợi ý liên quan phải được hiển thị khi người dùng đang nhập.
- Tính khả dụng cao (highly available)
- Chấp nhận việc không có tính nhất quán cao (accept eventual consistency).
- Kết quả tìm kiếm phải được sắp xếp theo một độ ưu tiên nào đó.
- Các kết quả phải liên quan đến bất kỳ tiền tố nào mà người dùng đã nhập.
Với bài toán này chúng ta có nhiệm vụ chính:
- Thu thập và lưu trữ các từ khoá tìm kiếm của người dùng.
- Xây dựng hệ thống gợi ý dựa vào những từ mà người dùng sẽ nhập.
Trong chuổi bài viết này, chúng ta sẽ tập dung vào nhiệm vụ thứ hai trước.
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
Lời giải đơn giản
Cách tiếp cận sơ khai nhất là quét qua toàn bộ các xâu để tìm ra những xâu bắt đầu bằng từ cần tìm. Trong SQL, câu lệnh truy vẫn sẽ có dạng như sau:
SELECT suggestion
FROM autocomplete_table
WHERE suggestion LIKE 'iphone%'
ORDER BY weight
LIMIT 7;
Cách làm này vô cùng đơn giản, tuy nhiên hiệu suất rất thấp, đặc biệt là nếu có hàng triệu xâu cần được tìm kiếm.
Để tăng tốc kết quả tìm kiếm, chúng ta có thể sử dụng phương pháp tìm kiếm nhị phân (binary search). Bằng cách sắp xếp toàn bộ dữ liệu theo thứ tự từ điển, chúng ta có thể nhanh chóng xác định vị trí bắt đầu và vị trí kết thúc của những xâu bắt đầu bằng một chuỗi ký tự cho trước. Độ phức tạp của cách làm này là O(log(N))với N ở đây là số lượng xâu ở trong cơ sở dữ liệu.
Chúng ta cần sử dụng các cấu trúc dữ liệu hiệu quả hơn.
Trie
Một cấu trúc dữ liệu phù hợp để tìm kiếm xâu tiền tố đó là Trie. Đây là cấu trúc dữ liệu phổ biến giúp ta tìm được các xâu có tiền tố độ dài L với độ phức tạp thời gian là O(L). Ngoài ra, Trie cũng khá tối ưu về mặt bộ nhớ để lưu trữ toàn bộ dữ liệu cần được gợi ý bởi vì những xâu có chung tiền tố sẽ có chung một đường dẫn gốc trên cây.
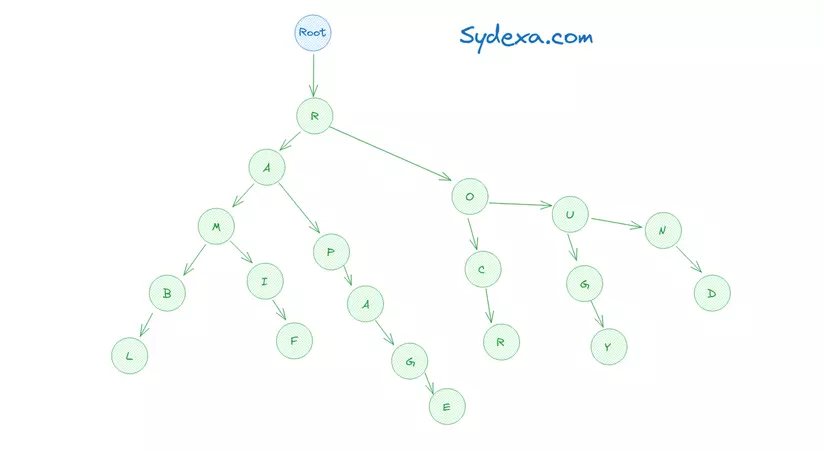
Suffix Tree
Đối với những xâu dài, từ nút gốc đến nút lá sẽ có rất nhiều nút trung gian ở giữa. Việc lưu trữ, xử lý một cây tìm kiếm như này sẽ rất tốn kém. Do vậy, để tối ưu, chúng ta có thể sử dụng suffix tree. Tương tự với Trie, thì cấu trúc dữ liệu này cũng giúp tìm kiếm các xâu với một đoạn mở đầu cho trước một cách nhanh chóng. Điểm khác là các nút chỉ có một nhánh nối nhau thì sẽ được ghép lại với nhau để tạo thành một nút duy nhất. Điều này giúp giảm độ phức tạp của cây, tìm kiếm nhanh hơn và không cần thăm quá nhiều nút trung gian. Hãy xem hình mình hoạ phía dưới:
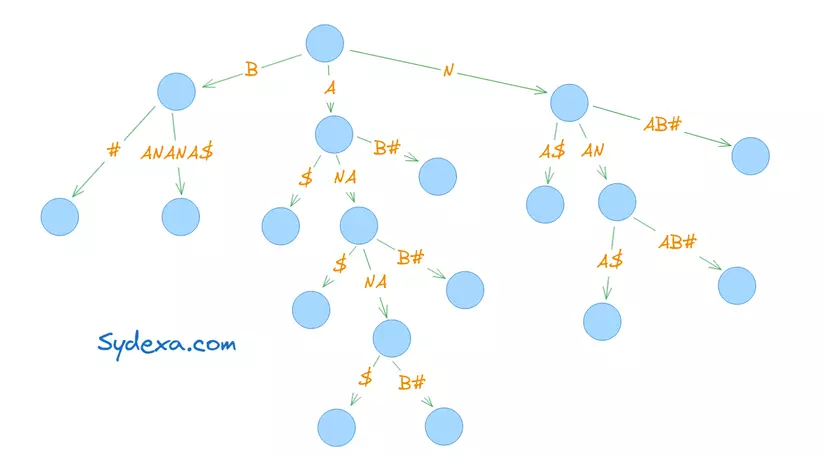
Thêm các trọng số vào Suffix Tree
Bây giờ để lấy ra danh sách các xâu để gợi ý cho người dùng, chúng ta cần duyệt hết phần đầu xâu mà người dùng đã nhập vào. Bước này có độ phức tạp là O(L) với L là độ dài xâu mà người dùng đã nhập.
Sau đó chúng ta cần tìm hết các xâu có tiền tố đã cho, bằng cách duyệt hết các xâu trong cây con hiện tại. Tuy nhiên số lượng xâu trong nhánh con hiện tại có thể rất lớn, chúng ta không nên đưa hết toàn bộ xâu này cho người dùng, chúng ta chỉ nên giới hạn khoảng 7 gợi ý. Đô phức tạp cho việc duyệt tìm hết xâu con trong nhanh hiện tại là O(N) với N là số xâu trong nhánh hiện tại.
Một số xâu có độ ưu tiên cao hơn, có khả năng cao là người dùng sẽ chọn cần được hiện lên đầu tiên. Để thực hiện yêu cầu này, chúng ta sẽ gán cho mỗi xâu một trọng số, và sắp xếp lại toàn bộ các xâu ở nhánh con này theo trọng số này. Xâu nào có trọng số lớn hơn sẽ ưu tiên gợi ý cho người dùng.
Làm sao để xác định được trọng số này? Tuỳ vào chiến lược của từng ứng dụng mà chúng ta có thể có cách đặt trọng số khác nhau. Chẳng hạn có thể dựa vào lịch sử tìm kiếm của người dùng, những câu truy vấn nào được tìm kiếm nhiều hơn sẽ có trọng số lớn hơn. Chúng ta cũng có thể ưu tiên những xâu được tìm kiếm nhiều gần đây để nhanh chóng bắt kịp xu hướng của người dùng vốn thay đổi rất nhanh theo thời gian.
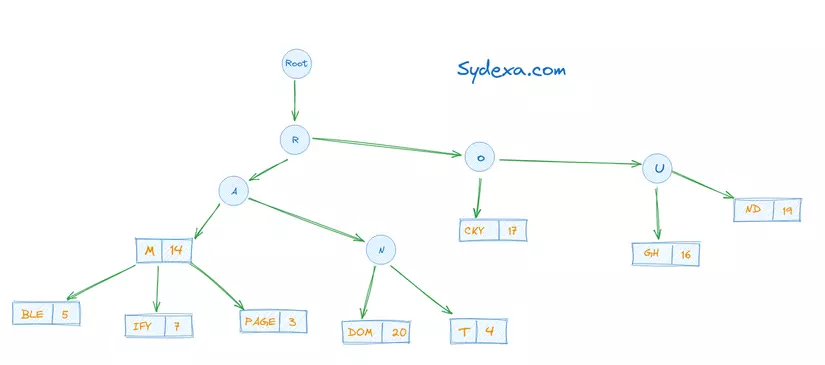
Việc sắp xếp lại các xâu theo trọng số sẽ có độ phực tạp là O(Nlog(N)) với N là số xâu cần sắp xếp.
Với hình minh hoạ trên, nếu người dùng nhập vào RAT, thì sẽ nhận về các phương án gợi ý, đã sắp xếp theo trọng số, lần lượt là: RATING (15), RATIONAL (12), RATAN (10)
Tính toán trước kết quả
Như vậy, độ phức tạp tính toán cho mỗi truy vấn tính đến hiện tại là O(L) + O(N) + O(Nlog(N)). Với số lượng truy vấn rất lớn thì với độ phức tạp này sẽ gây ra nhiều chậm trễ và trải nghiệp không tốt cho người dùng. Đặc biệt là khi cây con của một nhánh có rất nhiều phần tử, rất nhiều xâu có cùng tiền tố như thế.

Để cải thiện tốc độ, chúng ta có thể tính toán trước kết quả, của các nhánh cây có rất nhiều phần tử. Ta tiến hành lưu kết quả tìm kiếm trong một bẳng băm (hash table). Việc này sẽ gây tốn kém rất nhiều bộ nhớ. Tuy nhiên việc mở rộng bộ nhớ dù đắt đỏ nhưng hoàn toàn khả thi, nhưng mang đến trải nghiệm nhanh chóng cho người dùng.
Những vấn đề còn tồn đọng
Hiện tại chúng ta đã chọn được cấu trúc dữ liệu để lưu trữ các xâu cần được gợi ý. Thực hiện tính toán trước một số nhánh nặng để tăng tốc tốc độ tìm kiếm. Tuy nhiên, số lượng truy vấn vẫn còn rất lớn, chúng ta cần tìm giải pháp để:
- Chia một cây lớn thành nhiều cây nhỏ hơn để giảm tải truy vấn đến một máy chủ.
- Đảm bảo tính khả dụng của dịch vụ (high availability).
- Cách để lưu Suffix Tree vào cơ sở dữ liệu.
Chúng ta sẽ tìm hiểu kĩ hơn những vấn đề trên vào những phần sau với sydexa.com nha
Lời nhắn
Chúng mình có tạo Group cho các bạn cùng chia sẻ và học hỏi về thiết kế hệ thống nha 😄😄😄
Các bạn tham gia để gây dựng cộng đồng System Design Việt Nam thật lớn mạnh nhé 😍😍😍
Cộng Đồng System Design Việt Nam: https://www.facebook.com/groups/sydexa
Kênh TikTok: https://www.tiktok.com/@sydexa.com
All rights reserved
