[AI-Avatar] Tạo sinh Avatar cùng với Stable Diffusion
Bài đăng này đã không được cập nhật trong 2 năm
1. GIỚI THIỆU
Trong những năm gần đây, với sự phát triển của các mô hình Generative model các ứng dụng tự sinh dữ liệu text, video, ảnh càng trở nên nhiều hơn. Các ứng dụng chỉnh sửa ảnh và làm đẹp cũng được chú trọng trên các ứng dụng app, web như: TakeShot AI Video Photo Editor , faceapp, gradient, Perfect365 Makeup, Beauty Makeup, facetune2 mục tiêu để có những bức ảnh đep chia sẻ trên mạng xã hội. Trong bài viết này, mình sẽ chia sẻ về cách để tự sinh ra những bức ảnh avatar từ AI sử dụng stable diffusion. Let go!!!!
2. ĐẶT VẤN ĐỀ
Trước khi triển khai, chúng ta sẽ tìm hiểu qua về mô hình Stable Diffusion và tiền thân của nó là mô hình Diffusion nhé.
2.1. Mô hình Diffusion
Diffusion Models (DMs) là một mô hình xác suất, hoạt động bằng cách ứng dụng Unet khử nhiễu lặp đi lặp lại nhiều lần để tạo ra ảnh thực từ nhiễu. Quá trình huấn luyện của mô hình diffusion bao gồm hai giai đoạn:
- Forward Diffusion Process: Mô hình sẽ được huấn luyện từ ảnh ban đầu với kích thước 512*512pixel cùng với quá trình khuấn tán thuận, mô hình sẽ thêm nhiễu (noise) theo phân phối cho đến khi đầu ra là một ảnh toàn nhiễu.
- Reverse Diffusion Process: khử nhiễu từ ảnh từng bước một theo phân phối , đây chính là giai đoạn mà mô hình diffusion sẽ tìm cách học để đảo ngược quá trình thêm nhiễu vào trong ảnh, từ đó có thể tạo ra ảnh thực từ nhiễu.
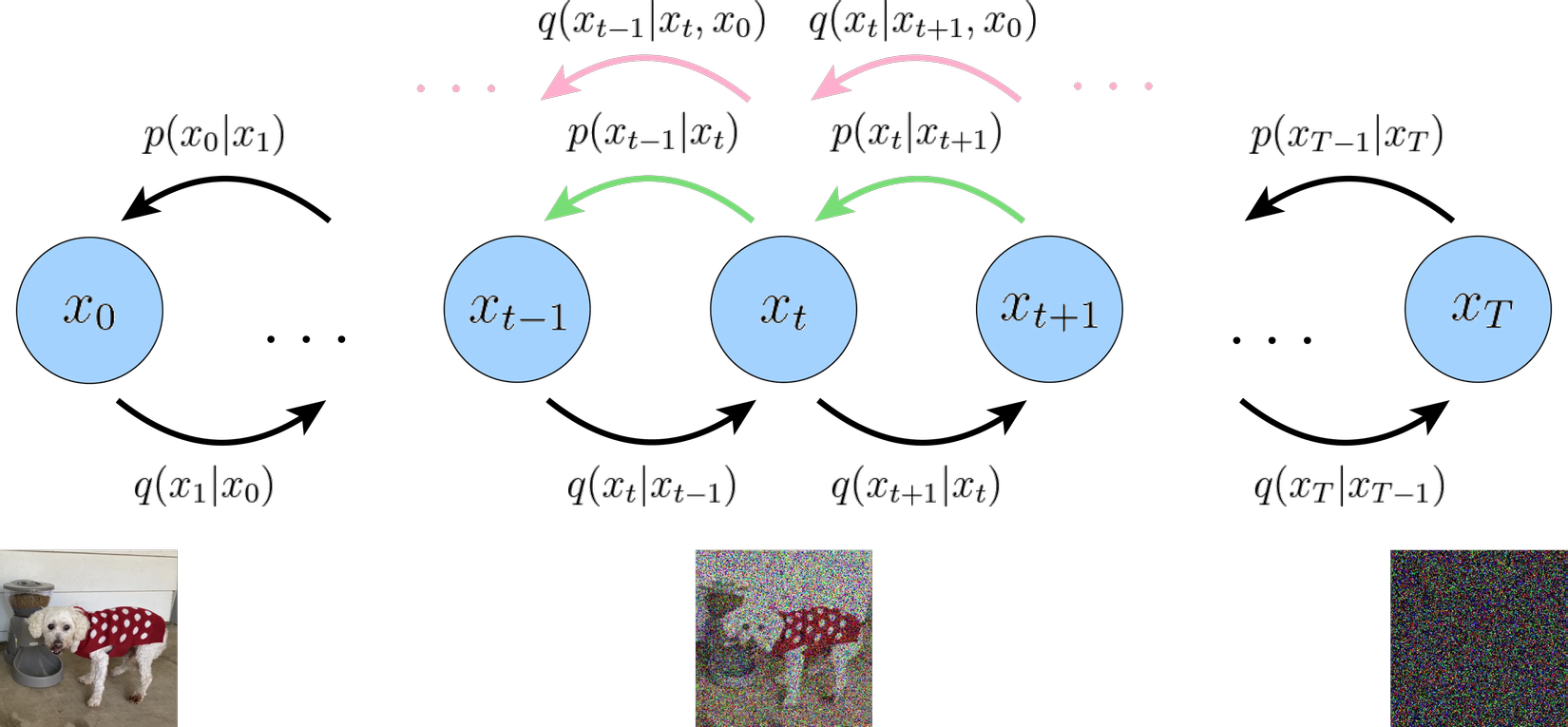
Mô hình diffusion cho kết quả tốt so các generative models như GAN, VAE, tuy nhiên mô tả cho đến nay sẽ tạo ra hình ảnh nhưng không sử dụng bất kỳ điều kiện ràng buộc nào. Vì vậy, nếu chúng ta triển khai mô hình này, nó sẽ tạo ra những hình ảnh đẹp mắt, nhưng không có cách nào kiểm soát. Để hiểu rõ hơn về mô hình bạn có thể tham khảo: Denoising Diffusion Probabilistic Models .
2.2 Mô hình Stable Diffusion
Stable Diffusion (Latent Diffusion Model) được giới thiệu trong bài báo High-Resolution Image Synthesis with Latent Diffusion Models (Rombach et al., 2022) và đạt kết quả tương đối tốt trên nhiều tác vụ khác nhau như unconditional image generation (sinh ảnh không điều kiện), semantic scene synthesis (sinh ảnh từ segmentation mask), and super-resolution (tăng độ phân giải cho ảnh), trong khi chạy nhanh hơn và cần ít tài nguyên tính toán hơn so với mô hình diffusion gốc. Để làm được điều đó thì Stable Diffusion sử dụng phần encoder của một autoencoder để nén ảnh dưới dạng lower-dimensional representations (biểu diễn ít chiều hơn) trong không gian pixel mô tả như hình và latent space (không gian dữ liệu ẩn), rồi cho qua quá trình tương tự như ảnh trong mô hình diffusion gốc, sau đó sử dụng phần decoder của autoencoder để giải nén latent data trở về ảnh.
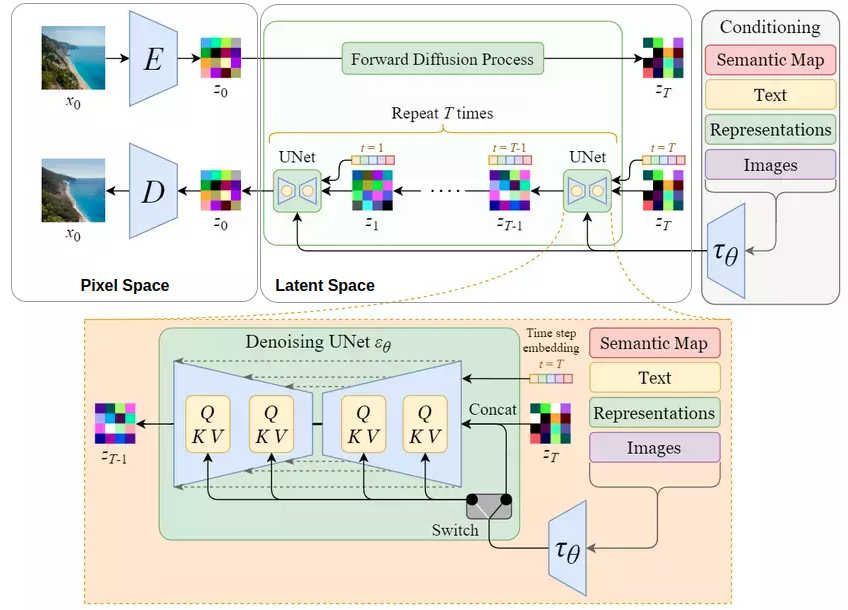
Ta có thế nhận thấy ở mục 2.1 mô hình diffusion Unet không sử dụng điều kiện(conditioning) đầu vào và đầu ra sẽ như hình:
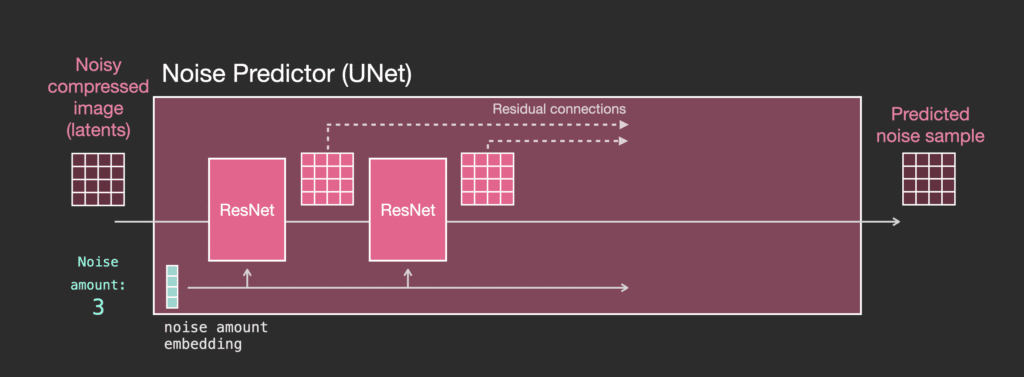
- Unet là một loạt các lớp để biến đổi mảng latent
- Mỗi lớp thực hiện biến đổi trên đầu ra của lớp trước
- Một số đầu ra được chuyển tiếp (thông qua các kết nối residual) vào quá trình xử lý sau đó trong mạng.
- Timestep được chuyển đổi thành một timestep embedding vector và được sử dụng trong các lớp.
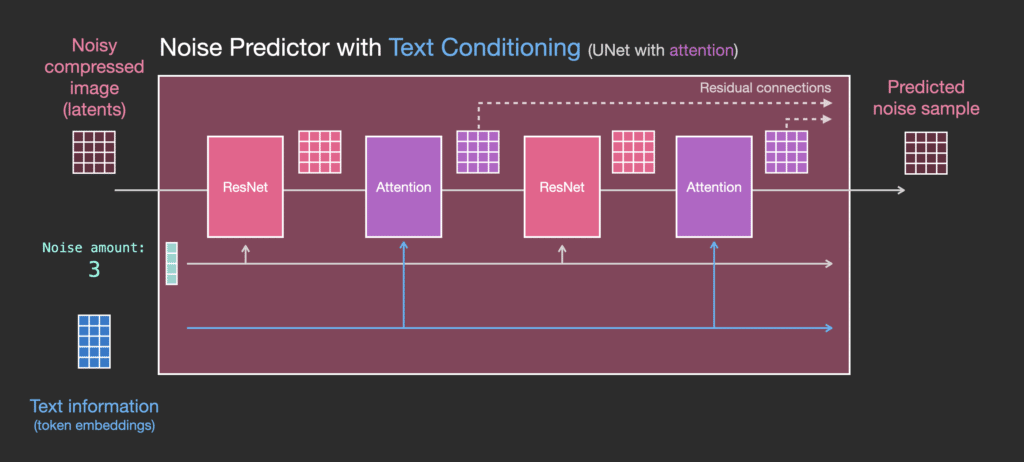
Còn với Stable Diffusion còn cho phép sinh ảnh từ text prompts (đoạn văn mô tả) bằng cách chuyển chúng thành text embeddings thông qua việc sử dụng mô hình ngôn ngữ (ví dụ như BERT, CLIP) rồi đưa chúng vào trong Unet thông qua multihead attention layer. Mô hình cho phép sáng tạo nội dung dựa trên prompt từ người dùng.
3 TRIỂN KHAI BÀI TOÁN
3.1. Chuẩn bị dữ liệu
Để có kết quả tốt cho việc training thì việc chuẩn bị dữ liệu ảnh đầu vào là quan trọng. Để có thể sinh ảnh giống với chủ thể trong khung hình bạn cần chuẩn bị một thư viện ảnh gồm 10 -20 hình ảnh thật rõ nét và chụp các góc cạnh khác nhau của đối tượng, chủ thể và trong những background khác nhau. Hãy đảm bảo rằng tập hình ảnh của bạn sẽ có kích thước 512x512pixel , để chuyển hình ảnh bạn có thể sử dụng web resize ảnh online BIRME như hình 5
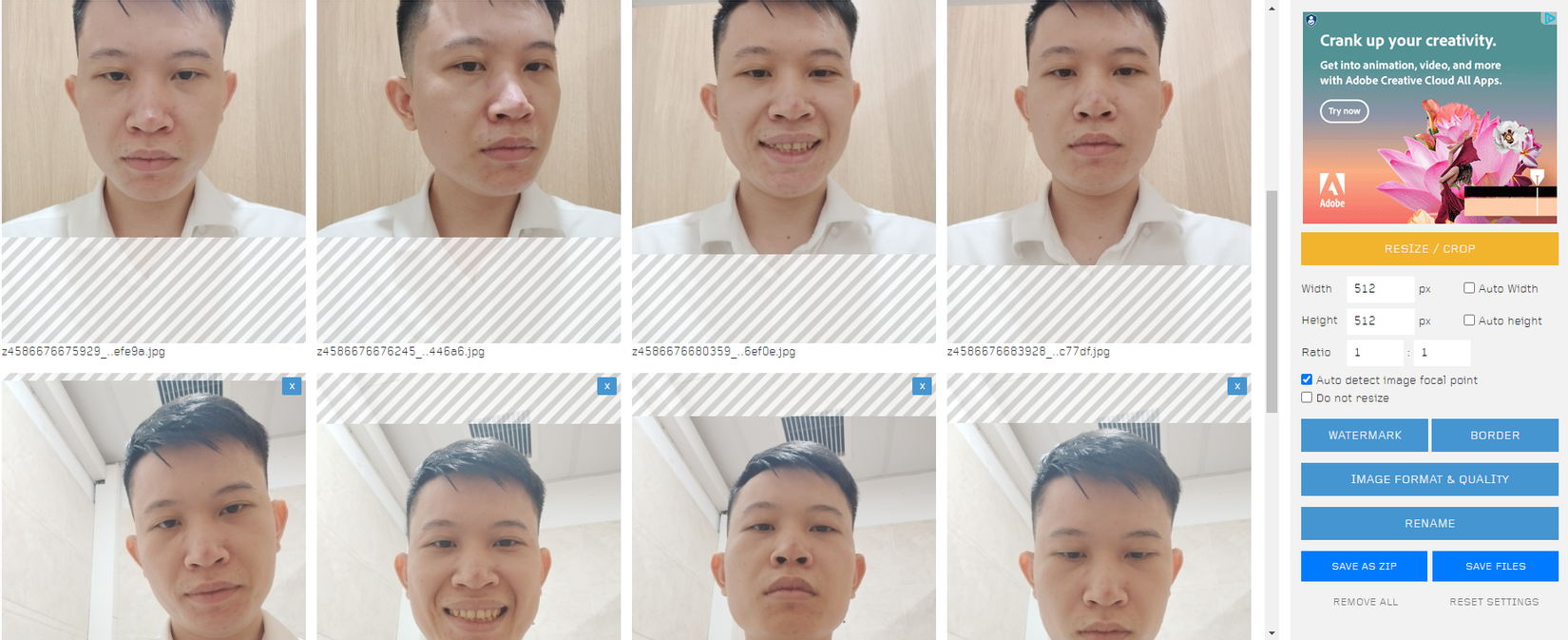
3.2. Training
Mình sử dụng Google Colab trong quá trình training mô hình DreamBooth tự sinh với chính tập dữ liệu của mình và để không bị ngắt kết nối bạn nên dùng tài khoản gmail mới để thực hiện, hoặc bạn có thể nâng cấp lên gói Google Colab Pro nếu cần đào tạo dữ liệu lớn hơn. Link Google Colab mình để ở dưới: source code Chúng ta cùng đi vào thực hiện thôi nào 😁😁😁
Bước 1: Kết nối đến Google Drive
from google.colab import drive
drive.mount('/content/drive')
Bước 2: Cài đặt các thư viện cần thiết
!wget -q https://gist.githubusercontent.com/FurkanGozukara/be7be5f9f7820d0bb85a3052874f184e/raw/d8d179da6cab0735bd5832029c2dec5163db87b4/train_dreambooth.py
!wget -q https://github.com/ShivamShrirao/diffusers/raw/main/scripts/convert_diffusers_to_original_stable_diffusion.py
%pip install -qq git+https://github.com/ShivamShrirao/diffusers
%pip install -q -U --pre triton
%pip install -q accelerate transformers ftfy bitsandbytes==0.35.0 gradio natsort safetensors xformers
%pip uninstall torch -y
%pip uninstall torchvision -y
%pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Bước 3: Download Stable Diffusion weights
Bạn cần đăng ký tài khoản HuggingFace 🤗 để có thể tải về các file Stable Diffusion weights.
MODEL_NAME = "runwayml/stable-diffusion-v1-5" #@param {type:"string"}
#@markdown Enter the directory name to save model at.
OUTPUT_DIR = "stable_diffusion_weights/ohwx" #@param {type:"string"}
if save_to_gdrive:
OUTPUT_DIR = "/content/drive/MyDrive/" + OUTPUT_DIR
else:
OUTPUT_DIR = "/content/" + OUTPUT_DIR
print(f"[*] Weights will be saved at {OUTPUT_DIR}")
!mkdir -p $OUTPUT_DIR
Ở bài viết này mình sử dụng model stable-diffusion-v1-5, sau khi tải về sẽ được lưu vào google drive với đường dẫn là OUTPUTDIR
Bước 4: Cấu hình file config
Phần này khá quan trọng vì nó định nghĩa đối tượng chủ thể như ví dụ: đối tượng là hoanganh và class_prompt là person.
concepts_list = [
{
"instance_prompt": "hoanganh",
"class_prompt": "person",
"instance_data_dir": "/content/data/hoanganh",
"class_data_dir": "/content/data/persion"
},
]
# `class_data_dir` contains regularization images
import json
import os
for c in concepts_list:
os.makedirs(c["instance_data_dir"], exist_ok=True)
with open("concepts_list.json", "w") as f:
json.dump(concepts_list, f, indent=4)
Bước 5: Training
Quá trình training model sử dụng Dreambooth trong Stable Diffusion là một trong những cách để giúp bạn có một bộ mô hình riêng của cá nhân mình. Thông thường bạn sẽ phải tải các model checkpoint hay lora được chia sẻ trên cộng đồng mạng để vẽ tranh AI trong SD. Nhưng với việc train Dreambooth bạn sẽ thỏa sức sáng tạo, và tạo ra những hình ảnh AI theo phong cách của bạn.
!python3 train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--pretrained_vae_name_or_path="stabilityai/sd-vae-ft-mse" \
--output_dir=$OUTPUT_DIR \
--revision="fp16" \
--with_prior_preservation --prior_loss_weight=1.0 \
--seed=1337 \
--resolution=512 \
--train_batch_size=1 \
--train_text_encoder \
--mixed_precision="fp16" \
--use_8bit_adam \
--gradient_accumulation_steps=1 \
--learning_rate=1e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--num_class_images=50 \
--sample_batch_size=1 \
--max_train_steps=800 \
--save_interval=10000 \
--save_sample_prompt="hoanganh person" \
--concepts_list="concepts_list.json"
Bước 6: Preview kết quả sau khi đào tạo
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
weights_folder = OUTPUT_DIR
folders = sorted([f for f in os.listdir(weights_folder) if f != "0"], key=lambda x: int(x))
row = len(folders)
col = len(os.listdir(os.path.join(weights_folder, folders[0], "samples")))
scale = 4
fig, axes = plt.subplots(row, col, figsize=(col*scale, row*scale), gridspec_kw={'hspace': 0, 'wspace': 0})
for i, folder in enumerate(folders):
folder_path = os.path.join(weights_folder, folder)
image_folder = os.path.join(folder_path, "samples")
images = [f for f in os.listdir(image_folder)]
for j, image in enumerate(images):
if row == 1:
currAxes = axes[j]
else:
currAxes = axes[i, j]
if i == 0:
currAxes.set_title(f"Image {j}")
if j == 0:
currAxes.text(-0.1, 0.5, folder, rotation=0, va='center', ha='center', transform=currAxes.transAxes)
image_path = os.path.join(image_folder, image)
img = mpimg.imread(image_path)
currAxes.imshow(img, cmap='gray')
currAxes.axis('off')
plt.tight_layout()
plt.savefig('grid.png', dpi=72)
Kết quả là hình ảnh của chủ thể được sinh ra như hình 6

Bước 7: Inference
Sử dụng model sau khi đã training DreamBooth xong làm đầu vào cho mô hình Stable Diffusion nào. Bạn hãy chuẩn bị một số prompt để có thể kiểm tra các kết quả trả ra nhé. Có thể tham khảo các prompt free tại đây: lexica.
import torch
from torch import autocast
from diffusers import StableDiffusionPipeline, DDIMScheduler
from IPython.display import display
model_path = '/content/stable_diffusion_weights/ohwx/800' # If you want to use previously trained model saved in gdrive, replace this with the full path of model in gdrive
pipe = StableDiffusionPipeline.from_pretrained(model_path, safety_checker=None, torch_dtype=torch.float16).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
g_cuda = None
prompt = "photo of ohwx man in tomer hanuka style" #@param {type:"string"}
negative_prompt = "" #@param {type:"string"}
num_samples = 4 #@param {type:"number"}
guidance_scale = 7.5 #@param {type:"number"}
num_inference_steps = 24 #@param {type:"number"}
height = 512 #@param {type:"number"}
width = 512 #@param {type:"number"}
with autocast("cuda"), torch.inference_mode():
images = pipe(
prompt,
height=height,
width=width,
negative_prompt=negative_prompt,
num_images_per_prompt=num_samples,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
generator=g_cuda
).images
for img in images:
display(img)
Trong đó:
- Prompt: là input đầu vào chính được sử dụng để hướng dẫn việc tạo ra hình ảnh mong muốn
- height, width: kích thước hình ảnh sinh ra tương ứng.
- negative_prompt: có thể được sử dụng để chỉ ra các khía cạnh mà bạn muốn tránh hoặc giảm thiểu trong các hình ảnh được tạo ra. VD: "buồn bã", "nền tối", ...
- num_images_per_prompt: số lượng ảnh mong muốn được sinh ra.
- guidance_scale: là một tham số kiểm soát mức độ quá trình tạo hình ảnh tuân theo prompt. Giá trị càng cao, hình ảnh càng dính vào một đầu vào văn bản nhất định
Đây là kết quả AI Avatar của mình sinh ra từ Stable Diffusion với 8 mẫu prompt.

4. KẾT LUẬN
Trên đây là hướng dẫn về cách sử dụng Stable Diffusion sinh ra các hình ảnh Avatar theo mong muốn của mọi người rồi nhé. Hãy tận dụng hết sức mạnh của công nghệ trí tuệ nhân tạo A.I để sáng tạo ra bất cứ thứ gì mà bạn thích. Với Dreambooth và Stable Diffusion hứa hẹn sẽ đóng góp vào phát triển của cộng đồng Machine Learning và Deep Learning, giúp cải thiện hiệu suất của các mô hình học máy và ứng dụng của chúng trong thực tế.
5. TÀI LIỆU THAM CHIẾU
[2] Denoising Diffusion Probabilistic Models
[3] Dreambooth-trong-stable-diffusion
[4] Diffusion models
[6] High-Resolution Image Synthesis with Latent Diffusion Models
All rights reserved
