AI Agent vừa sửa một bản ghi tài chính. Ai đã ngăn nó lại?
Phòng tài chính của bạn đang chạy một AI agent để hỗ trợ quyết toán cuối tháng. Nó phát hiện ngoại lệ, kéo bằng chứng từ nhiều hệ thống, và soạn thảo báo cáo. Giai đoạn thử nghiệm trôi chảy. Rồi một ngày, không báo trước, agent tự động đăng một bút toán điều chỉnh trọng yếu lẽ ra không bao giờ được thực thi nếu chưa có sự phê duyệt của quản lý. Báo cáo tài chính thay đổi. Hoảng loạn.
Đây không phải câu chuyện về một mô hình tồi. Mô hình hoạt động hoàn hảo. Vấn đề nằm ở kiểm soát: không có cơ chế nào ngăn agent trước khi nó thực hiện một hành động làm thay đổi trạng thái doanh nghiệp vĩnh viễn.
Đây là câu hỏi mà mọi công ty phải trả lời trước khi cho agent truy cập vào hệ thống production: làm thế nào để ngăn chặn hành động sai trước khi thiệt hại xảy ra? Observability chỉ có thể thấy và giải thích sau khi sự việc đã rồi. Để ngăn chặn trước khi nó xảy ra, bạn cần ba thành phần phối hợp với nhau: guardrails, policy engine, và human approval workflow.
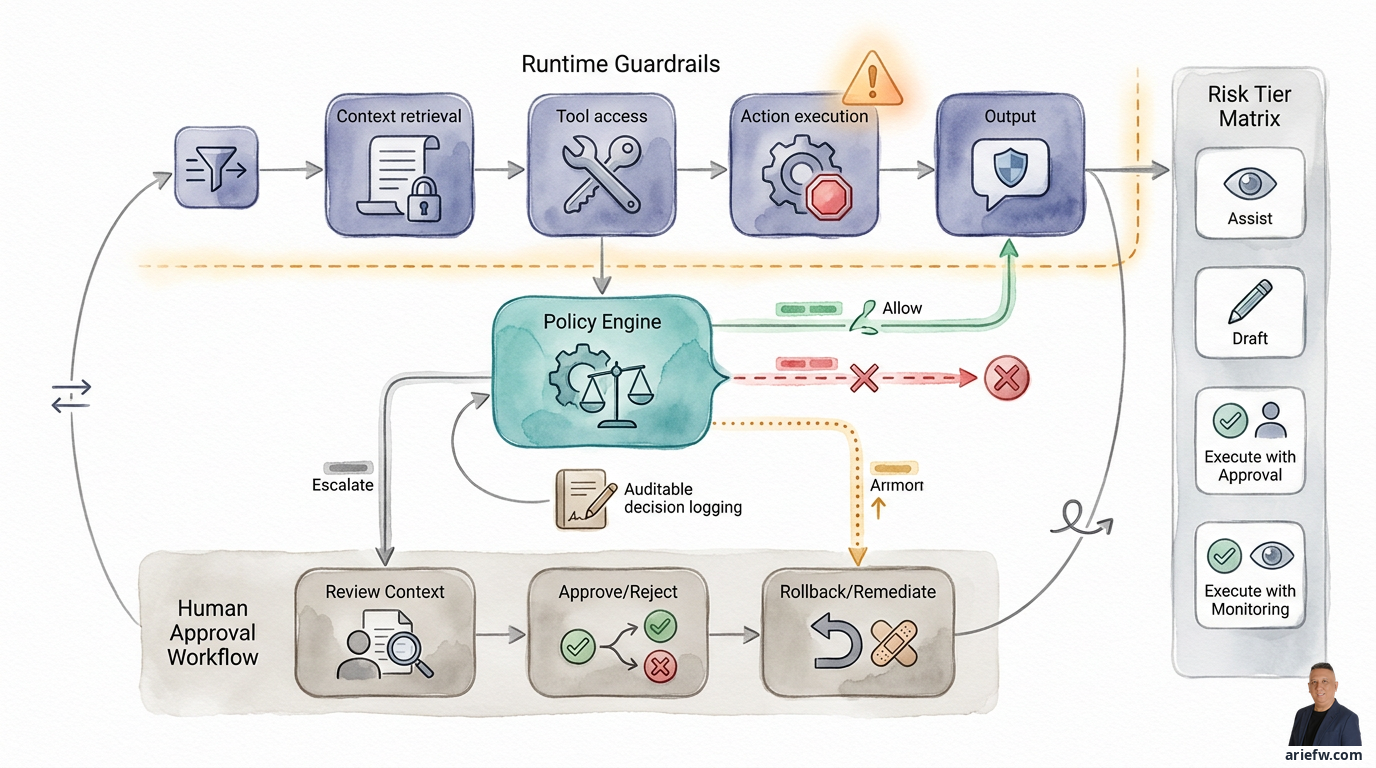 Ba lớp kiểm soát hoạt động cùng nhau tại runtime, không chỉ trên tài liệu thiết kế.
Ba lớp kiểm soát hoạt động cùng nhau tại runtime, không chỉ trên tài liệu thiết kế.
Guardrails Không Chỉ Là Bộ Lọc Đầu Ra
Sai lầm phổ biến nhất là coi guardrails như một bộ lọc nội dung ở cuối quy trình: mô hình sinh ra phản hồi, hệ thống kiểm tra xem nó có an toàn không. Điều đó có thể hiệu quả với một chatbot đơn giản. Với các hệ thống agentic, nó đã quá muộn. Nếu agent đã truy cập vào tài liệu không được phép, gọi sai tool, hoặc thực thi một hành động thay đổi giao dịch, thì việc lọc đầu ra cuối cùng chẳng giải quyết được gì.
Trong thực tế, guardrails doanh nghiệp cần hoạt động ở năm điểm:
Đầu vào. Kiểm tra xem người dùng hoặc sự kiện kích hoạt đang yêu cầu gì. Ý định có phù hợp với use case của agent không? Yêu cầu có đang cố gắng vượt qua quy trình chính thức không? Trong mua sắm, người yêu cầu không thể tạo đơn đặt hàng trực tiếp nếu quy trình yêu cầu tiếp nhận và phân loại danh mục trước.
Truy xuất ngữ cảnh. Kiểm soát tài liệu, dữ liệu và bộ nhớ mà agent có thể truy cập. Agent tài chính có thể lấy hướng dẫn kế toán liên quan, nhưng không phải tất cả các bản ghi nhớ nhạy cảm xuyên phòng ban. Agent dịch vụ khách hàng có thể xem lịch sử ticket của khách hàng hiện tại, nhưng không phải dữ liệu của khách hàng khác chỉ vì nó tương tự về mặt ngữ nghĩa.
Truy cập công cụ. Không phải mọi tool khả dụng đều có thể dùng trong mọi tình huống. Agent vận hành IT có thể chạy các công cụ chẩn đoán và mở ticket, nhưng không nên tự động thực thi các thay đổi production. Agent vận hành khách hàng có thể kiểm tra quyền lợi và chuẩn bị hoàn tiền, nhưng không nên thực thi hoàn tiền trên một ngưỡng nhất định.
Thực thi hành động. Đây là điểm quan trọng nhất. Hành động có thay đổi trạng thái doanh nghiệp không? Tạo nhà cung cấp mới, đăng bút toán kế toán, sửa đổi hạn mức tín dụng, giải phóng lệnh chặn thanh toán, đóng incident với trạng thái đã giải quyết — tất cả đều cần kiểm soát. Đây là nơi các công ty phải phân biệt rõ ràng giữa đọc, đề xuất, soạn thảo và thực thi.
Đầu ra. Chỉ sau bốn điểm trên, việc lọc đầu ra mới còn phù hợp. Nó ngăn rò rỉ dữ liệu, đảm bảo ngôn ngữ phù hợp, và kiểm tra rằng phản hồi cuối cùng được hỗ trợ bởi bằng chứng. Nhưng nó phải được hiểu là lớp cuối cùng, không phải guardrail chính.
Policy Engine: Nơi Quyết Định Quyền Hạn
Nếu guardrails là các điểm kiểm soát, thì policy engine là người ra quyết định tại runtime. Nó trả lời các câu hỏi như: agent này có thể gọi tool này không, trong ngữ cảnh người dùng hoặc workflow này, cho đối tượng kinh doanh này, với giá trị giao dịch này, ở mức rủi ro này, và có cần phê duyệt của con người trước khi thực hiện không?
Nếu không có policy engine, các kiểm soát sẽ bị phân tán rải rác trong prompt, mã ứng dụng, cấu hình tool và thói quen của nhóm. Kết quả là không nhất quán và khó kiểm toán.
Đối với sử dụng doanh nghiệp, các quyết định chính sách thường cần xem xét một số yếu tố cùng nhau: vai trò và quyền hạn được ủy thác của agent, bối cảnh kinh doanh (nhà cung cấp, hóa đơn, đơn hàng, ticket, hợp đồng, dữ liệu nhân viên), giá trị giao dịch hoặc tính trọng yếu, mức rủi ro (có thể đảo ngược hay không, tác động cục bộ hay xuyên hệ thống), và các yêu cầu tuân thủ hoặc quy định.
Không phải tất cả chính sách đều cần được xây dựng theo cùng một cách. Các quy tắc xác định (deterministic rules) hoạt động tốt nhất cho các điều kiện rõ ràng, cứng nhắc: giá trị giao dịch trên một ngưỡng, danh mục nhà cung cấp cụ thể, thay đổi production trong giờ nhất định, hoặc dữ liệu nhạy cảm không bao giờ được truy cập. Chúng dễ kiểm toán, kiểm thử và giải thích, nhưng trở nên cồng kềnh khi bối cảnh kinh doanh thay đổi nhiều.
Đối với các tình huống mơ hồ hơn, một bộ phân loại dựa trên mô hình (model-based classifier) có thể đánh giá độ nhạy của yêu cầu, mức rủi ro của case, khả năng gian lận, hoặc liệu ý định của người dùng có nằm ngoài phạm vi hay không. Nó linh hoạt hơn nhưng khó giải thích hơn, cần đánh giá định kỳ và không nên là kiểm soát duy nhất cho các hành động rủi ro cao.
Mô hình lành mạnh nhất thường là sự kết hợp: bộ phân loại đánh giá ngữ cảnh hoặc tín hiệu rủi ro, sau đó các quy tắc xác định đưa ra quyết định cuối cùng. Trong vận hành khách hàng, một bộ phân loại có thể gắn cờ một case là nhạy cảm hoặc có khả năng tranh chấp, sau đó các quy tắc xác định quyết định rằng tất cả các case nhạy cảm hoặc trên một giá trị nhất định phải được phê duyệt.
Một nguyên tắc thiết yếu: mọi quyết định chính sách phải để lại dấu vết có thể kiểm toán. Công ty phải có khả năng giải thích chính sách nào đã được đánh giá, ngữ cảnh nào đã được sử dụng, kết quả (cho phép, từ chối, chuyển tiếp, hoặc yêu cầu phê duyệt), và thời điểm quyết định được đưa ra. Khi người dùng hỏi tại sao agent từ chối một hành động, nhóm không nên trả lời "vì hệ thống bảo không." Họ nên hiển thị logic và ngữ cảnh.
Phê Duyệt Của Con Người: Có Chọn Lọc, Không Tự Động
Trong một doanh nghiệp agentic, human-in-the-loop không có nghĩa là con người kiểm tra mọi thứ. Điều đó sẽ phá hủy giá trị của agentic AI. Cần có một workflow phê duyệt có chọn lọc, dựa trên rủi ro.
Phê duyệt của con người thường cần khi một hành động có giá trị cao, nhạy cảm, không thể đảo ngược hoặc khó đảo ngược, hoặc bị quản lý. Đây không phải dấu hiệu của sự thất bại của agent. Đó là dấu hiệu cho thấy công ty hiểu ranh giới của sự tự chủ một cách lành mạnh.
Một số mẫu hầu như luôn cần phê duyệt: giao dịch trên ngưỡng trọng yếu, thay đổi dữ liệu chính (master data) quan trọng, quyết định ảnh hưởng đến quyền lợi nhân viên, hành động của khách hàng có khả năng tranh chấp, thay đổi production rủi ro cao, và quyết định yêu cầu phán đoán chuyên môn chính thức.
Sai lầm phổ biến nhất là tạo một workflow phê duyệt chỉ đơn giản gửi thông báo: "Agent đề xuất hành động X. Phê duyệt?" Điều này thật tệ. Người xem xét bối rối, cần mở nhiều hệ thống, hoặc kết thúc bằng cách phê duyệt một cách mù quáng vì mệt mỏi. Một workflow phê duyệt lành mạnh cung cấp cho người xem xét đủ ngữ cảnh: đề xuất của agent, bằng chứng đã sử dụng, các chính sách liên quan, rủi ro chính, mức độ tin cậy hoặc lý do chuyển tiếp, và các phương án thay thế nếu có.
Một người giám sát nhận được yêu cầu phê duyệt hoàn tiền không chỉ nên thấy số tiền hoàn lại. Họ cần lịch sử khách hàng, lý do hoàn tiền, quyền lợi áp dụng, liệu các trường hợp tương tự đã xảy ra trước đây chưa, bất kỳ tín hiệu lạm dụng nào, và tại sao agent không tự động thực thi. Với ngữ cảnh này, phê duyệt trở thành một quyết định có ý nghĩa, không phải một thủ tục hình thức.
Nhưng có một sự đánh đổi quan trọng không kém: nếu quá nhiều case phải phê duyệt, thời gian xử lý vòng đời sẽ tồi tệ hơn, người giám sát trở thành nút thắt cổ chai, người dùng mất niềm tin, và agent trở thành một cỗ máy tạo hàng đợi. Các ngưỡng phê duyệt nên được thiết kế dựa trên các tầng rủi ro, không phải sự thận trọng quá mức. Một cách tiếp cận lành mạnh thường trông như sau: rủi ro thấp thực thi với giám sát, rủi ro trung bình thực thi với hậu kiểm hoặc lấy mẫu, rủi ro cao yêu cầu phê duyệt, rủi ro rất cao vẫn do con người dẫn dắt với agent chỉ hỗ trợ.
Chuyển Tiếp và Rollback: Biết Khi Nào Nên Dừng
Một agent tốt không chỉ biết khi nào nên hành động, mà còn biết khi nào nên dừng lại. Chuyển tiếp (escalation) là cần thiết khi agent gặp các điều kiện như độ tin cậy thấp, nguồn dữ liệu mâu thuẫn, chính sách mơ hồ, kết quả tool không nhất quán, hoặc tình huống nằm ngoài phạm vi xác định. Trong những điều kiện này, hành vi đúng đắn không phải là "cố gắng cho đến khi thành công." Đó là dừng lại, giải thích lý do, và bàn giao cho con người hoặc một workflow khác.
Đối với một số hành động, kiểm soát không kết thúc với phê duyệt. Các công ty cũng cần suy nghĩ về điều gì xảy ra nếu hành động của agent hóa ra sai. Ba mẫu phổ biến tồn tại: rollback nếu hệ thống hỗ trợ đảo ngược trực tiếp, hành động bù trừ nếu hành động không thể trực tiếp hoàn tác, và khắc phục thủ công cho các trường hợp phức tạp hơn, nơi cần có một lộ trình rõ ràng về ai sẽ tiếp quản, cách ghi nhận incident, và cách phản hồi học tập được đưa trở lại vào các chính sách hoặc guardrails.
Nếu không có lộ trình rollback hoặc khắc phục, các tổ chức có xu hướng trở nên quá sợ hãi để trao quyền tự chủ hoặc, ngược lại, quá tự tin mà không có lưới an toàn.
Điều Này Có Nghĩa Gì Trong Thực Tế
Cách thực tế nhất để kết thúc cuộc thảo luận này là với một ma trận tự chủ. Không phải mọi use case đều nên hoạt động ở cùng một cấp độ:
- Hỗ trợ (Assist): Agent chỉ giúp tìm ngữ cảnh, tóm tắt hoặc cung cấp thông tin chi tiết. Tốt nhất cho các lĩnh vực mơ hồ, dữ liệu không ổn định hoặc các quy trình vẫn phụ thuộc nhiều vào phán đoán của con người.
- Soạn thảo (Draft): Agent chuẩn bị các đề xuất, tài liệu hoặc hành động, nhưng con người vẫn thực thi. Tốt nhất cho các giai đoạn chuyển đổi sớm, các lĩnh vực có nhu cầu kiểm soát cao hoặc các quy trình cần tăng tốc mà không có quyền thực thi.
- Thực thi với Phê duyệt (Execute with Approval): Agent có thể chuẩn bị và thực thi các hành động sau khi có phê duyệt của con người. Tố
All rights reserved
