AI Agent của bạn nghe có vẻ thông minh. Nhưng điều đó không có nghĩa là nó an toàn.
Một team tài chính gần đây đã xây dựng một AI agent để hỗ trợ quy trình chốt sổ cuối tháng. Nó kéo dữ liệu từ ERP, phân loại các ngoại lệ, và viết bình luận. Nhìn bề ngoài, mọi thứ đều ổn. Nhưng khi team bắt đầu test nghiêm túc, họ phát hiện ra điều đáng lo: agent thỉnh thoảng sử dụng bằng chứng không liên quan, trích dẫn chính sách đã lỗi thời, và trong một số trường hợp, thực thi các hành động lẽ ra phải có sự phê duyệt rõ ràng.
Đây không phải là câu chuyện cá biệt. Các công ty đang nhận ra rằng việc test một AI agent khác biệt hoàn toàn so với test một ứng dụng tiêu chuẩn hay một chatbot đơn giản. Chỉ kiểm tra xem câu trả lời cuối cùng có nghe hợp lý hay không, rồi chuyển sang pilot, là một cách làm thiếu an toàn đến mức nguy hiểm. Các agent doanh nghiệp không chỉ trả lời câu hỏi. Chúng truy xuất ngữ cảnh, chọn công cụ, gọi API, tuân theo hoặc vi phạm chính sách, yêu cầu hoặc bỏ qua phê duyệt, và cuối cùng là tác động đến kết quả kinh doanh.
Câu hỏi thực sự là: làm thế nào để bạn chứng minh rằng một agent hoạt động đúng đắn, an toàn, nhất quán, và phù hợp với business của bạn? Nếu không có một quy trình đánh giá có kỷ luật, bạn có nguy cơ bị đánh lừa bởi một agent có ngôn ngữ trôi chảy nhưng lại yếu kém trong phán đoán vận hành.
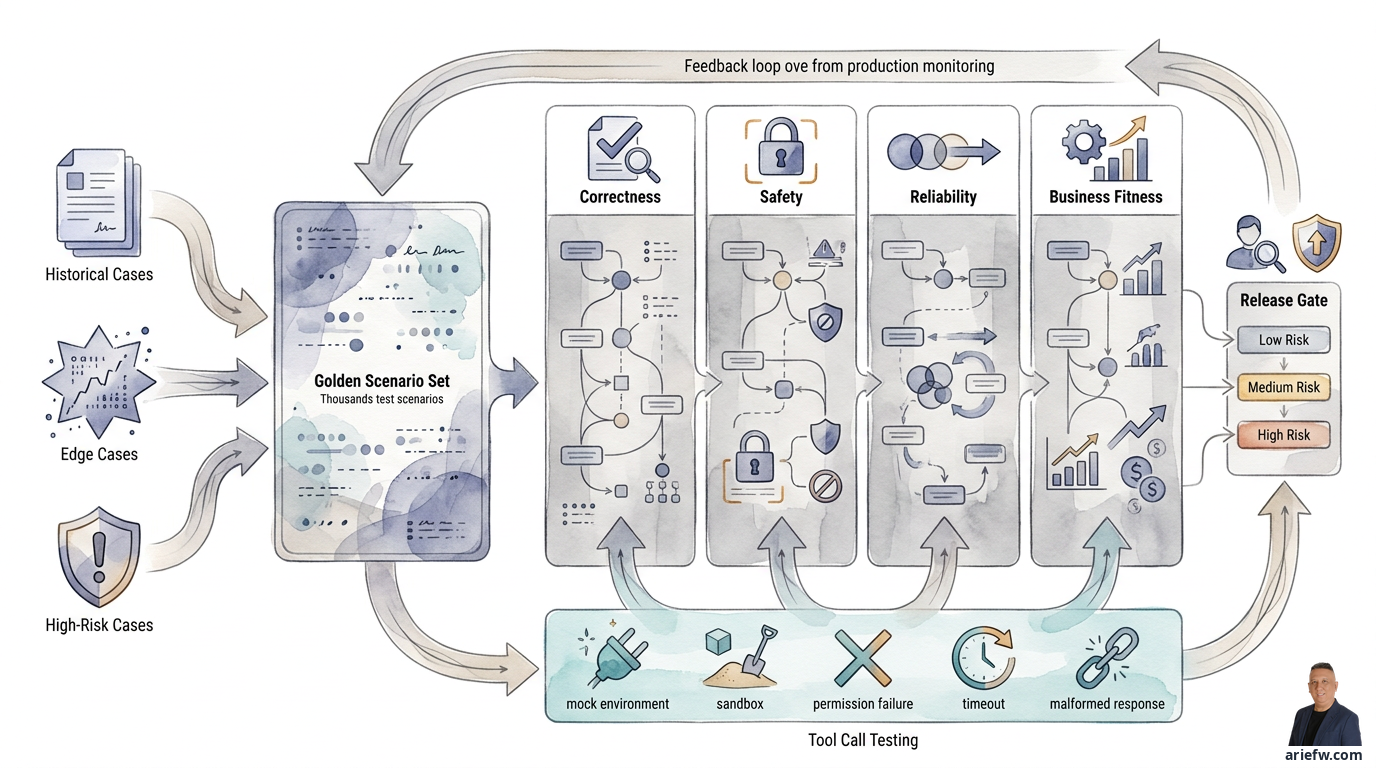 Kiến trúc đánh giá ánh xạ đầu vào từ các trường hợp lịch sử, biên và rủi ro cao thông qua các kiểm tra về tính đúng đắn, an toàn, độ tin cậy và sự phù hợp kinh doanh, kết hợp với kiểm thử lời gọi công cụ và các cổng release theo cấp độ.
Kiến trúc đánh giá ánh xạ đầu vào từ các trường hợp lịch sử, biên và rủi ro cao thông qua các kiểm tra về tính đúng đắn, an toàn, độ tin cậy và sự phù hợp kinh doanh, kết hợp với kiểm thử lời gọi công cụ và các cổng release theo cấp độ.
Tại sao Testing Truyền thống Không Đủ
Hãy xem xét ba tình huống doanh nghiệp phổ biến. Một agent mua sắm nhận được yêu cầu, tra cứu chính sách danh mục, kiểm tra trạng thái nhà cung cấp, và soạn thảo một đề nghị mua hàng. Một agent chốt sổ tài chính thu thập bằng chứng, phân loại ngoại lệ, và chuẩn bị bình luận. Một agent IT vận hành nhận được một sự cố, chạy chẩn đoán, và mở một ticket hoặc kích hoạt một runbook.
Trong mọi trường hợp, thứ cần được test không chỉ là câu kết luận cuối cùng. Điều quan trọng hơn nhiều là: ngữ cảnh nào đã được truy xuất, công cụ nào đã được chọn, trình tự các bước có đúng không, agent dừng lại ở đâu, và kết quả cuối cùng có tuân thủ các quy tắc kinh doanh hay không?
Đây là cái bẫy phổ biến nhất: một agent có thể tạo ra một phản hồi cực kỳ thuyết phục nhưng vẫn sai. Nó có thể sử dụng bằng chứng không liên quan, trích dẫn chính sách lỗi thời, gọi sai công cụ, thực thi hành động mà không được ủy quyền, hoặc xử lý một trường hợp lẽ ra phải được chuyển lên cấp trên. Trong vận hành khách hàng, một agent có thể hứa hoàn tiền vì khách hàng nói nghe có vẻ thuyết phục, mặc dù quyền lợi không hỗ trợ điều đó. Trong tài chính, một agent có thể tạo ra một bình luận chốt sổ bóng bẩy nhưng không được hỗ trợ bởi đủ bằng chứng. Trong IT, một agent có thể đề xuất một giải pháp kỹ thuật hợp lý nhưng lại vi phạm chính sách quản lý thay đổi.
Bởi vì hai lần chạy với đầu vào tương tự có thể tạo ra các đường dẫn hơi khác nhau, việc test agent không thể dựa vào so khớp văn bản chính xác. Bạn cần test hành vi mong đợi, ranh giới hành động, chất lượng quyết định, và độ robust với sự biến thiên đầu vào. Việc đánh giá phải chuyển từ test đầu ra sang test hành vi và kết quả.
Xây dựng Bộ Kịch bản Vàng, Không phải Case Demo
Nền tảng của một quy trình đánh giá tốt là một bộ kịch bản vàng: một tập hợp các tình huống đại diện được sử dụng lặp đi lặp lại để test agent trước mỗi bản release và sau mỗi thay đổi. Đây không phải là một danh sách các câu hỏi demo. Nó phải phản ánh thực tế vận hành.
Ba nguồn quan trọng nhất:
- Các trường hợp lịch sử: các ví dụ thực tế từ quá khứ—các ngoại lệ hóa đơn phổ biến, các ticket khách hàng định kỳ, các sự cố IT điển hình, các yêu cầu mua sắm tiêu chuẩn. Những thứ này cung cấp cho bạn một đường cơ sở dựa trên các mẫu hình công việc thực tế, chứ không phải giả định của team dự án.
- Các trường hợp biên: các tình huống hiếm gặp nhưng quan trọng—dữ liệu không đầy đủ, tài liệu mâu thuẫn, đầu vào mơ hồ, sự kết hợp các điều kiện mà agent có khả năng thất bại. Đây thường là nơi các agent hỏng trong production.
- Các trường hợp rủi ro cao: các tình huống liên quan đến dữ liệu nhạy cảm, giao dịch vượt ngưỡng, hướng dẫn cố tình vượt qua chính sách, hoặc các trường hợp cần bị từ chối hoặc chuyển lên cấp trên. Trong các lĩnh vực được quản lý chặt chẽ, những thứ này quan trọng hơn việc test chất lượng ngôn ngữ.
Mỗi kịch bản cần có một hành vi mong đợi rõ ràng. Đối với các hệ thống agent, kỳ vọng đó phải phong phú hơn một câu trả lời đơn thuần. Ở mức tối thiểu, hãy xác định liệu agent có nên: đưa ra một câu trả lời cụ thể, gọi một công cụ cụ thể, tránh gọi một công cụ, yêu cầu phê duyệt, chuyển cho con người, từ chối yêu cầu, hay dừng lại vì dữ liệu không đủ.
Một bộ kịch bản vàng phải sống và phát triển. Cập nhật nó khi quy trình làm việc thay đổi, chính sách được cập nhật, công cụ mới được thêm vào, nguồn dữ liệu thay đổi, hoặc các dạng lỗi mới xuất hiện trong production. Nếu bộ kịch bản vàng không thay đổi, các bài kiểm tra hồi quy sẽ mang lại sự tự tin giả tạo.
Bốn Chiều của Đánh giá
Để giữ cho việc đánh giá rõ ràng, hãy tách biệt bốn chiều.
Tính đúng đắn đo lường xem các sự kiện được sử dụng có chính xác không, chính sách được áp dụng có hiện hành không, công cụ được chọn có phù hợp không, và hành động cuối cùng có tuân theo quy tắc quy trình không. Điều này thường cần được đánh giá ở nhiều cấp độ: chất lượng câu trả lời, chất lượng suy luận, độ chính xác khi sử dụng công cụ, và kết quả cuối cùng.
An toàn đo lường xem agent có tránh được rò rỉ dữ liệu, các hành động trái phép, tấn công prompt injection, và các hành vi có khả năng gây hại hay không. Một agent nhân sự không được tiết lộ dữ liệu của nhân viên khác. Một agent mua sắm không được tạo ra các lối tắt cho các nhà cung cấp chưa được thẩm định. Một agent IT không được thực thi các thay đổi production ngoài chính sách. Kiểm tra an toàn phải bao gồm các kịch bản được cố tình thiết kế để đẩy agent vượt quá ranh giới của nó.
Độ tin cậy đo lường xem agent có cho kết quả hợp lý nhất quán trên các đầu vào tương tự không, có hoạt động chính xác với nhiễu không, và có bị sụp đổ khi các công cụ chậm, dữ liệu một phần, hoặc định dạng đầu vào thay đổi nhẹ không. Production hiếm khi cung cấp đầu vào sạch sẽ như demo.
Sự phù hợp kinh doanh đánh giá xem agent có phù hợp với mô hình vận hành thực tế của bạn không. Một agent có thể đúng về mặt kỹ thuật, an toàn về mặt chính sách, và hợp lý nhất quán, nhưng vẫn không phù hợp. Sự phù hợp kinh doanh đánh giá xem tỷ lệ chuyển lên cấp trên có hợp lý không, đầu ra có thực sự giúp ích cho người review không, thời gian chu kỳ có được cải thiện không, công việc làm lại có giảm không, và agent có hoạt động tốt với các SOP, hàng đợi phê duyệt và năng lực team của bạn không.
Kiểm thử Lời gọi Công cụ: Nơi Rủi ro Thực sự Nằm
Trong các hệ thống agent, lời gọi công cụ là nơi agent chạm vào thực tế doanh nghiệp. Việc kiểm thử phải đi xa hơn nhiều so với việc xác minh rằng các API có thể được gọi.
Mỗi công cụ quan trọng nên được kiểm thử trong nhiều điều kiện:
- Một môi trường mock để xác minh luồng cơ bản
- Một sandbox để kiểm tra tác động đầu cuối mà không chạm vào production
- Lỗi phân quyền để đảm bảo phản ứng an toàn khi quyền truy cập bị từ chối
- Timeout để xem liệu agent có thử lại, fallback, hay chuyển lên cấp trên một cách chính xác không
- Phản hồi sai định dạng để kiểm tra độ robust trước các phản hồi API không hoàn hảo
Nếu một API danh mục nhà cung cấp ERP bị lỗi, agent không được phép đoán trạng thái nhà cung cấp. Nó phải dừng lại hoặc chuyển lên cấp trên. Nếu dữ liệu quyền lợi khách hàng không đầy đủ, agent không được hứa bồi thường. Nếu một công cụ runbook trả về kết quả mơ hồ, agent nên tạm dừng hành động tiếp theo.
Nhiều agent trông rất tốt khi tất cả các công cụ hoạt động bình thường. Vấn đề xuất hiện khi một API chậm, dữ liệu một phần, phản hồi không khớp schema, hoặc công cụ chính sách từ chối một hành động. Hành vi mong đợi trong những điều kiện này phải rõ ràng: dừng lại, yêu cầu thêm dữ liệu, chuyển lên cấp trên, hoặc đưa ra câu trả lời hạn chế. Điều không bao giờ được xảy ra là agent bịa đặt, vượt qua một công cụ, hoặc cố gắng các đường dẫn thay thế trái phép.
Cổng Release: Không phải Agent Nào Cũng Cần Chung Một Tiêu Chuẩn
Sau khi đánh giá, bạn cần các cổng release chính thức. Mục tiêu không phải là làm chậm sự đổi mới mà là đảm bảo rằng các agent đi vào production phù hợp với mức độ rủi ro của chúng.
Một trợ lý kiến thức nội bộ rủi ro thấp không cần quy trình giống như một agent có thể thực hiện hoàn tiền, ghi sổ nhật ký, hoặc chạy các biện pháp khắc phục IT. Trong thực tế, các cổng có thể được phân biệt:
- Trợ lý rủi ro thấp: tính đúng đắn cơ bản, an toàn tối thiểu, khả năng quan sát cơ bản, chủ sở hữu rõ ràng.
- Agent quy trình rủi ro trung bình: tỷ lệ vượt qua kịch bản vàng nghiêm ngặt hơn, kiểm thử lời gọi công cụ, review con người chính thức, kế hoạch rollback, giám sát chất lượng sau khi live.
- Agent thực thi rủi ro cao: phạm vi kịch bản rộng hơn, kiểm thử an toàn và đối kháng, phê duyệt từ bộ phận rủi ro/bảo mật/tuân thủ, sẵn sàng quy trình phê duyệt, khả năng quan sát đầy đủ, kế hoạch rollback và ứng phó sự cố, triển khai giới hạn trước khi mở rộng quy mô.
Trước khi đưa vào production, tối thiểu phải đảm bảo rằng các kịch bản chính và các trường hợp rủi ro cao đã được kiểm thử, tỷ lệ vượt qua đáp ứng các ngưỡng đã thỏa thuận cho cấp độ rủi ro, các dạng lỗi chính đã được biết đến với các biện pháp giảm thiểu, khả năng quan sát và ghi log kiểm toán đã sẵn sàng, chủ sở hữu kinh doanh và kỹ thuật đã rõ ràng, một công tắc kill hoặc rollback tồn tại, và các bộ phận rủi ro liên quan đã phê duyệt nếu cần.
Cổng không nên hỏi "mô hình có tốt không?" mà là "hệ thống này có an toàn và có thể vận hành được không?"
Áp dụng vào Hệ thống Thực tế
Nếu bạn đang xây dựng một agent ngay hôm nay, hãy bắt đầu bằng cách kiểm toán cách
All rights reserved
