Agent AI Của Bạn Cứ Quên Mãi: Context Layer Mới Là Vấn Đề Kiến Trúc Thực Sự
Phòng tài chính thử nghiệm một AI agent để hỗ trợ chốt sổ cuối kỳ. Agent có quyền truy cập dữ liệu, có vẻ đủ năng lực. Nhưng kết quả lại gây bất an: đôi khi nó trích dẫn một chính sách kế toán đã hết hạn từ quý trước, đôi khi nó trộn lẫn dữ liệu giữa các pháp nhân khác nhau, và đôi khi nó quên mất rằng nó đã phê duyệt một bước nào đó rồi. Đội ngũ bắt đầu tự hỏi—agent này đang giúp ích, hay đang tạo thêm việc?
Đây không phải vấn đề của model. Đây là vấn đề của context.
Nhiều đội ngũ cố gắng vá lỗi này bằng cách kéo dài prompt, thêm hướng dẫn phức tạp hơn, hoặc tăng cường truy xuất tài liệu một cách hung hăng. Kết quả là sự bất ổn. Agent trông thông minh vào một khoảnh khắc, nhưng ngay sau đó lại lấy nhầm tài liệu, quên quyết định trước đó, hoặc vi phạm ranh giới truy cập.
Đối với doanh nghiệp, context không phải là thứ có thể nghĩ tới sau. Nó là lớp vận hành quyết định liệu agent có thể đưa ra quyết định phù hợp, an toàn và có trách nhiệm hay không.
Quan Niệm Sai Lầm: Context Chỉ Là "Thêm Thông Tin"
Khi một agent làm việc trên một case đơn lẻ, nó hiếm khi chỉ phụ thuộc vào một nguồn dữ liệu. Nó cần kết hợp trạng thái giao dịch từ ERP, chính sách từ kho tri thức, mối quan hệ thực thể từ dữ liệu master, lịch sử quyết định từ các workflow trước đó, và ranh giới truy cập dựa trên danh tính người dùng. Bạn không thể đổ tất cả dữ liệu thô này vào một prompt và mong đợi sự rõ ràng.
Context layer là thứ biến dữ liệu thô và kiến thức thành context có thể sử dụng được cho việc ra quyết định. Nó làm bốn việc:
- Chọn lọc những gì thực sự liên quan đến tác vụ hiện tại.
- Diễn giải thông tin với ý nghĩa kinh doanh—phân biệt một chính sách đang có hiệu lực với một bản nháp cũ.
- Phân quyền truy cập để agent chỉ thấy những gì nó được phép.
- Đóng gói context dưới dạng agent có thể sử dụng hiệu quả.
Nếu thiếu bốn chức năng này, agent sẽ rơi vào hai khuôn mẫu tồi: hoặc chúng dựa vào những prompt phình to nhồi nhét mọi hướng dẫn có thể, hoặc chúng phụ thuộc vào việc truy xuất không kiểm soát trả về quá nhiều hoặc quá ít.
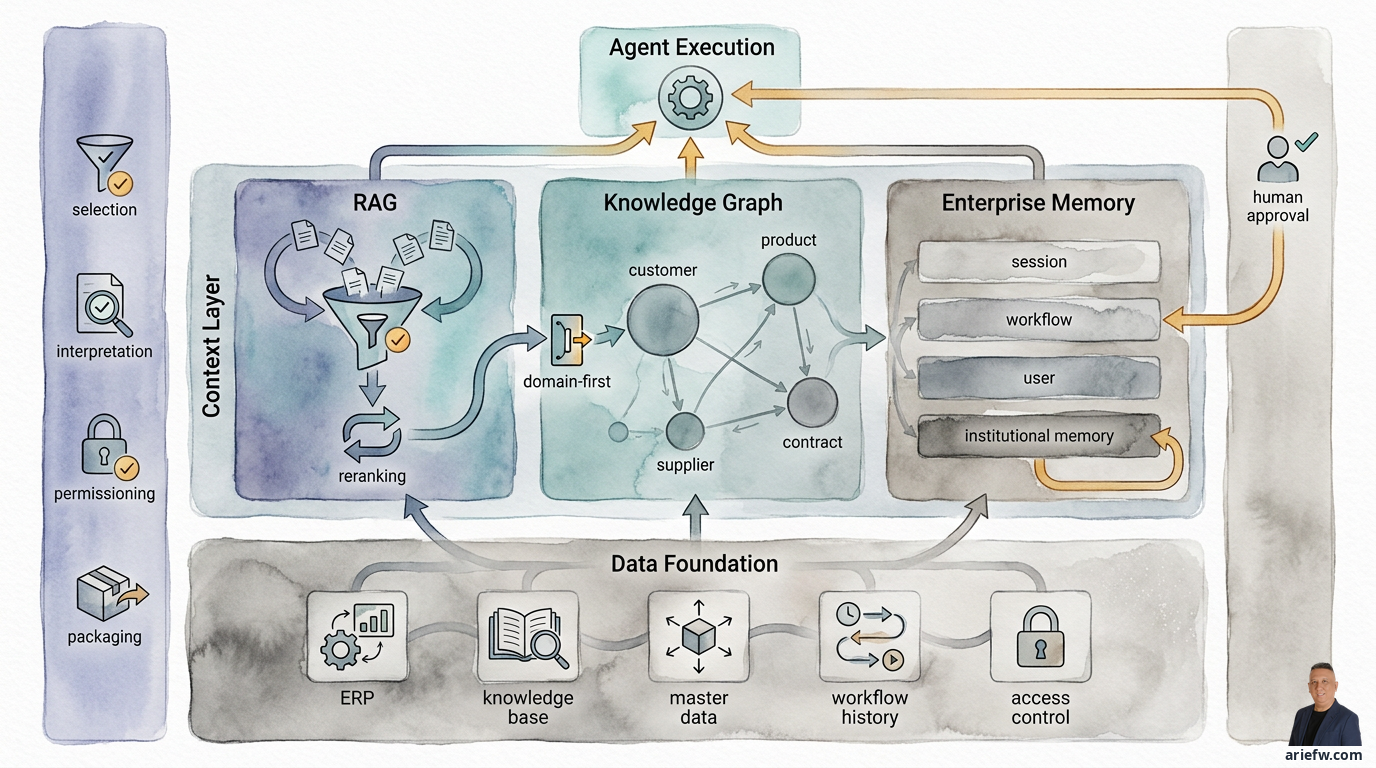 Context layer nằm giữa data foundation và agent execution, với bốn chức năng kiểm soát đảm bảo agent nhận được context phù hợp, an toàn và có thể sử dụng được.
Context layer nằm giữa data foundation và agent execution, với bốn chức năng kiểm soát đảm bảo agent nhận được context phù hợp, an toàn và có thể sử dụng được.
RAG: Truy Xuất Tôn Trọng Ranh Giới
Thành phần phổ biến nhất của context layer là retrieval-augmented generation (RAG). Nhiệm vụ của nó rất đơn giản: giúp agent tìm các tài liệu liên quan từ kho tri thức doanh nghiệp và sử dụng chúng để trả lời, suy luận, hoặc chuẩn bị một hành động.
Đối với nhiều use case, đây là một điểm khởi đầu hợp lý. Service desk đọc các bài báo tri thức. HR operations trả lời các câu hỏi chính sách. Procurement tham khảo SOP và hợp đồng. Legal ops so sánh các điều khoản.
Nhưng RAG tốt khó hơn nhiều so với việc dump tài liệu vào một vector database. Chất lượng của nó được quyết định bởi sáu yếu tố ở phía trước của quá trình tìm kiếm:
- Chất lượng nguồn. Nếu corpus của bạn pha trộn các chính sách chính thức, bản nháp cũ, email không chính thức và các file mồ côi, việc truy xuất sẽ tạo ra nhiễu. RAG chỉ tốt khi corpus của nó tốt.
- Chiến lược chunking. Tài liệu phải được chia thành các đơn vị có thể truy xuất được. Quá lớn, việc truy xuất sẽ mờ nhạt. Quá nhỏ, context bị đứt đoạn. Enterprise chunking nên tuân theo cấu trúc tài liệu kinh doanh, không phải số lượng ký tự.
- Metadata. Thường quan trọng hơn embeddings. Ngày hiệu lực, số phiên bản, khu vực, chức năng, mức độ bảo mật, trạng thái hoạt động và chủ sở hữu tài liệu đều làm cho việc truy xuất chính xác hơn nhiều.
- Chiến lược tìm kiếm. Chỉ tìm kiếm tương tự (similarity search) hiếm khi đủ. Kết hợp tìm kiếm ngữ nghĩa, bộ lọc từ khóa, bộ lọc metadata, và đôi khi mở rộng truy vấn dựa trên ngữ cảnh workflow.
- Reranking. Kết quả ban đầu cần được sắp xếp lại để các phần có liên quan và có thẩm quyền nhất xuất hiện trước—đặc biệt khi nhiều tài liệu có vẻ giống nhau nhưng có trạng thái kinh doanh khác nhau.
- Đánh giá câu trả lời. Đừng đánh giá RAG bằng việc câu trả lời "nghe có vẻ hay". Hãy kiểm tra xem agent có thực sự truy xuất đúng tài liệu, trích dẫn chính sách hiện hành, tránh pha trộn các nguồn xung đột và tạo ra câu trả lời thực sự hữu ích hay không.
Một trong những sai lầm nguy hiểm nhất: xây dựng RAG thông minh về mặt kỹ thuật nhưng mù quáng về mặt phân quyền. Một agent không nên truy xuất một tài liệu chỉ vì nó liên quan về mặt ngữ nghĩa. Nó cũng phải kiểm tra xem tài liệu đó có thể truy cập được đối với người dùng hoặc workflow mà nó đại diện hay không. Permission-aware RAG áp dụng kiểm soát truy cập trong khi truy xuất, không phải sau khi câu trả lời được hình thành.
Knowledge Graphs: Khi Mối Quan Hệ Quan Trọng Hơn Tài Liệu
Nếu RAG giúp agent tìm những gì đã được viết ra, thì knowledge graph giúp chúng hiểu cái gì được kết nối với cái gì. Một knowledge graph biểu diễn rõ ràng các thực thể kinh doanh và mối quan hệ của chúng: khách hàng, sản phẩm, nhà cung cấp, hợp đồng, tài sản, địa điểm, chính sách, rủi ro, nhân viên, case. Và các mối quan hệ giữa chúng: một khách hàng có hợp đồng, một nhà cung cấp cung cấp linh kiện cho một sản phẩm, một sản phẩm chịu sự điều chỉnh của một chính sách cụ thể.
Đối với enterprise agents, graph có giá trị vì nhiều quyết định vận hành không thể được đưa ra từ một tài liệu hoặc bảng duy nhất. Chúng phụ thuộc vào một mạng lưới các mối quan hệ.
Hãy xem xét một supply chain control tower. Khi một lô hàng bị chậm trễ, agent cần hiểu: lô hàng này được gắn với đơn hàng nào của khách hàng? Những sản phẩm nào có trong đơn hàng đó? Những nhà cung cấp nào cung cấp các sản phẩm đó? Khách hàng đó có SLA ưu tiên không? Những địa điểm nào bị ảnh hưởng? Có chính sách leo thang nào không? Tất cả điều này dễ dàng được mô hình hóa dưới dạng graph hơn là một chồng tài liệu.
Nhiều tổ chức tránh knowledge graph vì họ tưởng tượng ra một dự án khổng lồ, tốn kém, trên toàn doanh nghiệp. Điều đó là không cần thiết. Một cách tiếp cận thực tế hơn: bắt đầu với các graph dành riêng cho từng lĩnh vực cho các use case ưu tiên. Một graph cho mối quan hệ nhà cung cấp-hợp đồng-danh mục-chính sách trong procurement. Một graph cho mối quan hệ khách hàng-sản phẩm-ticket-SLA trong dịch vụ khách hàng. Một graph cho mối quan hệ thực thể-tài khoản-sổ nhật ký-kiểm soát trong quy trình chốt sổ tài chính.
Domain-first graphs mang lại ba lợi thế: thời gian đạt giá trị nhanh hơn, dễ dàng xác thực bởi chủ sở hữu doanh nghiệp và quản trị đơn giản hơn so với việc cố gắng lập bản đồ toàn bộ công ty cùng một lúc.
Enterprise Memory: Ghi Nhớ Mà Không Tạc Khắc Sai Lầm
Thành phần thứ ba là memory. Memory cho phép agent giữ lại context không có sẵn trong một prompt hoặc truy vấn duy nhất. Điều này quan trọng vì hầu hết công việc doanh nghiệp kéo dài nhiều bước, nhiều ngày và đôi khi nhiều đội ngũ.
Nhưng memory trong doanh nghiệp phải có kỷ luật. Không phải mọi thứ đều cần được ghi nhớ, và không phải tất cả các ký ức đều nên được đối xử như nhau.
Cần phân biệt bốn loại memory:
- Session memory: Context trong một cuộc trò chuyện hoặc tương tác đơn lẻ. Agent nhớ bạn đang thảo luận về hóa đơn #4023. Hữu ích cho sự mạch lạc, nhưng thường không cần lưu trữ dài hạn.
- Workflow memory: Trạng thái của công việc đang tiến hành. Những bước nào đã hoàn thành, những tài liệu nào đã được xem xét, những quyết định nào đã được đưa ra, ai đã phê duyệt, những ngoại lệ nào còn tồn đọng. Quan trọng đối với các workflow như chốt sổ tài chính, quản lý case procurement hoặc ứng phó sự cố.
- User memory: Các sở thích hoặc context cụ thể về một người dùng—định dạng báo cáo ưa thích, mô hình làm việc. Có thể cải thiện trải nghiệm nhưng phải được quản lý cẩn thận do các vấn đề về quyền riêng tư và công bằng.
- Institutional memory: Kiến thức tổ chức lâu dài hơn. Các mô hình ngoại lệ lặp đi lặp lại, các phương pháp xử lý đã hiệu quả trước đây, phản hồi của con người về các đề xuất của agent, kiến thức vận hành lặp đi lặp lại. Có giá trị nhất cho việc cải tiến liên tục, nhưng cũng rủi ro nhất nếu không được quản lý.
Không có memory, agent hoạt động như thể bị mất trí nhớ vận hành. Mọi case đều bắt đầu từ con số không. Việc bàn giao giữa các phiên làm việc kém. Các quyết định trước đó bị bỏ qua. Phản hồi của con người bị mất. Các workflow dài trở nên mong manh.
Trong IT operations, một agent xử lý các sự cố định kỳ nên nhớ runbook nào đã hiệu quả trước đây, người phê duyệt có liên quan là ai và các phụ thuộc hệ thống nào là nguyên nhân gốc rễ phổ biến. Trong collections, một agent nên nhớ các cam kết thanh toán trước đó, phản hồi của khách hàng và các hành động tiếp theo đã thực hiện—để nó không gửi các thông tin liên lạc mâu thuẫn.
Enterprise memory yêu cầu bốn kỷ luật tối thiểu: lưu trữ (cái gì được lưu, trong bao lâu, khi nào bị xóa), quyền riêng tư (memory có thể chứa dữ liệu nhạy cảm, vì vậy việc lưu trữ và sử dụng phải tuân theo các chính sách truy cập nghiêm ngặt), kiểm toán (công ty phải có khả năng giải thích memory nào đã được sử dụng để đưa ra một đề xuất) và hiệu chỉnh (nếu agent lưu trữ một kết luận sai, phản hồi của con người phải có khả năng sửa hoặc gắn cờ memory đó).
Quyết Định Kiến Trúc Quyết Định Lòng Tin
RAG, knowledge graphs và memory không thay thế lẫn nhau. Chúng bổ sung cho nhau. RAG giúp agent truy xuất kiến thức liên quan từ tài liệu. Knowledge graphs giúp agent hiểu các mối quan hệ thực thể kinh doanh. Memory giúp agent duy trì tính liên tục qua các phiên, workflow và kiến thức vận hành.
Trong một workflow doanh nghiệp trưởng thành, cả ba hoạt động cùng nhau. Trong xử lý ngoại lệ procurement, RAG truy xuất chính sách mua hàng và điều khoản hợp đồng có liên quan, graph hiển thị mối quan hệ giữa người yêu cầu, danh mục, nhà cung cấp, hợp đồng và đường dẫn phê duyệt, và memory nhớ lại rằng một trường hợp tương tự trước đây đã bị từ chối do tài liệu không đầy đủ. Trong chốt sổ tài chính, RAG truy xuất hướng dẫn kế toán và SOP chốt sổ, graph lập bản đồ mối quan hệ thực thể-tài khoản-sổ nhật ký-kiểm soát, và memory lưu trữ lịch sử các ngoại lệ và quyết định của người kiểm soát trước đó.
Đây là lúc context layer trở thành một execution layer, không chỉ là một search layer.
Áp Dụng Vào H
All rights reserved
