Acloud.guru: Why Amazon DynamoDB isn’t for everyone
Bài đăng này đã không được cập nhật trong 4 năm
Theo read.acloud.guru Why Amazon DynamoDB isn’t for everyone
Refer Document:
- https://linuxacademy.com
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GuidelinesForTables.html
- https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
- https://www.allthingsdistributed.com/2017/10/a-decade-of-dynamo.html
- https://syslog.ravelin.com/you-probably-shouldnt-use-dynamodb-89143c1287ca
- https://read.acloud.guru/serverless-superheroes-lynn-langit-on-big-data-nosql-and-google-versus-aws-f4427dc8679c
- https://www.quora.com/Why-is-it-said-that-relational-SQL-databases-do-not-scale
- https://segment.com/blog/the-million-dollar-eng-problem/
Trong tuần qua, mình đã đọc bài viết từ Acloud.Guru "Why Amazon DynamoDB isn’t for everyone" - dựa trên nội dung bài viết này, mình hi vọng sẽ giúp người đọc hiểu rõ hơn các vấn đề mà AWS DynamoDB đang gặp phải,
Năm 2004, hoạt động kinh doanh của AWS gặp các vấn đề về giới hạn hạ tầng database trên nền tảng Oracle. Để đáp ứng hoạt động kinh doanh ngày càng phát triển, Amazon đã thiết kế Dynamo - nhằm đáp ứng các yêu cầu về hiệu suất, độ tin cậy cao và khả năng mở rộng liên tục (seamless scalability).
Amazon Dynamo là nền tảng của Amazon.com - Một loại database NoSQL dạng Key/Value. Vào năm 2012, AWS giới thiệu dịch vụ DynamoDB đến khách hàng, với hứa hẹn về khả năng mở rộng, sử dụng đơn giản, ... :rolling_eyes:
1. Basic concepts of DynamoDB
Đầu tiên cần hiểu cấu trúc table của DynamoDB:
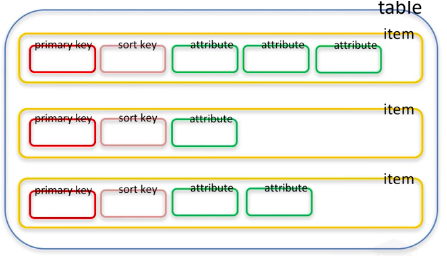
- Primary key: Là một index default - duy nhất trong mỗi Item của một table. Primary key có thể là simple (partition key) hoặc composite (partition key & sort key).
- Throughput: Khả năng Read/Write trên mỗi table.
- Read Capacity Unit (RCU): Cung cấp khả năng đọc mỗi giây cho một Item, có kích thước bé hơn 4KB.
- Write Capacity Unit(WCU): Cung cấp khả năng viết mỗi giây cho một Item, có kích thước bé hơn 1KB.
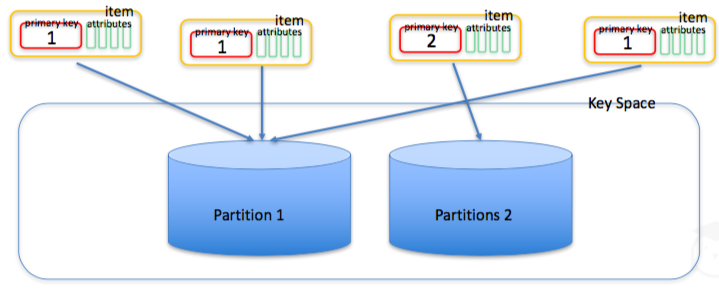
- Partition: Một partition là một "đơn vị lưu trữ data" của một table - khi lưu trữ data, DynamoDB phân chia các item của table vào nhiều partition, và phân phối data chủ yếu dựa trên giá trị partition key. Partition sẽ tự động Add/Remove dựa trên throughput được cung cấp cho table đó.
- Môt partition có thể support tối đa 3000 RCU or 1000 WCU.
- Một partition có thể chứa khoảng 10GB data.
- DynamoDB cũng hổ trợ Secondary Indexes để thực hiện các query và scan hiệu quả.
❖ Để đạt được toàn bộ năng lực RCU/WCU mà bạn đã cung cấp cho table, bạn cần đảm bảo workload trải đều trên tất cả các partition key :rolling_eyes: và hạn chế các "Hot Key" (nhiều Item được phân bố trên cùng một partition và thường xuyên bị query).
2. Why use DynamoDB?
Theo như nội dung bài biết, tác giả cho rằng AWS nên xem xét một dịch vụ đi kèm với DynamoDB, được gọi là "WhynamoDB"  Mỗi khi developer tạo một table DynamoDB mới, nó sẽ pop-up trên AWS Console và hỏi một câu đơn giản: "Why?"
Mỗi khi developer tạo một table DynamoDB mới, nó sẽ pop-up trên AWS Console và hỏi một câu đơn giản: "Why?"
Tất nhiên, để trả lời cho câu hỏi "Why use DynamoDB?" - không đơn giản như lời hứa của AWS về khả năng mở rộng liên tục.
Tác giả đã trao đổi với các kỹ sư và lập trình viên về kinh nghiệm của họ đối với DynamoDB, bên cạnh những câu chuyện thành công - nó cũng có nhiều thất bại 
Để hiểu nguyên nhân tại sao việc triển khai DynamoDB thành công trong khi các trường hợp khác thì thất bại, chúng ta sẽ đánh giá 2 tính năng quan trọng của DynamoDB - Simplicity & Scalability.
DynamoDB is simple — until it doesn’t scale
❖ Với DynamoDB, AWS thực sự đã đơn giản hóa các vấn đề cấu hình phức tạp - bạn không phải sử dụng bất kỳ công cụ Database Management Studio, không phải lo lắng về Database Driver và cũng không phải cấu hình các Cluster.
Chỉ đơn giản là tạo Primary Key, cung cấp RCU/WCU, sử dụng SDK và JSON để làm việc với DynamoDB. Với tính năng này, không có gì ngạc nhiên khi DynamoDB rất hấp dẫn đối với các developer.
Tuy nhiên, DynamoDB lưu trữ data dạng Key/Value, nó thực sự hoạt động tốt nếu bạn truy xuất các item cụ thể dựa trên Key. Các Query phức tạp hoặc Scan - đòi hỏi sử dụng index cẩn thận và rất khó viết, hoặc thậm chí không thể viết - ngay cả khi data của bạn không quá lớn và đã có kinh nghiệm với NoSQL.
Nguyên nhân do các developer không có nhiều kinh nghiệm về NoSQL so với SQL truyền thống, tác giả đã trao đổi với một số kỹ sư mà team của họ đã có kinh nhiệm với MongoDB - một document database, nhưng vẫn gặp vấn đề với DynamoDB.
Lynn Langit - một Superheroes - chuyên gia tư vấn về cloud data, đã cảnh báo các doanh nghiệp đang sử dụng các giải pháp NoSQL như DynamoDB. Cô chia sẽ câu chuyện về việc một khách hàng đã chuyển từ DynamoDB qua Aurora
❖ Tại điểm này, tác giả kết luận, SQL vẫn sẽ đáp ứng được mọi thứ bạn cần, dù nó có thể mất nhiều thời gian để cấu hình các thiết lập ban đầu hơn so với DynamoDB (simple), nhưng nó có thể giúp bạn khỏi lãng phí thời gian sau này.
Không phải DynamoDB là công nghệ tồi - mà là vì nó mới đối với bạn, và những thứ có vẻ "dễ, thuận tiện" sẽ làm bạn sml nếu không hiểu rõ nó

DynamoDB is scalable — until it isn’t simple
❖ Phần này bạn sẽ tìm hiểu vấn đề về "Hot Key", "Hot Partition" đối với các table lớn. AWS DynamoDB hứa hẹn về hiệu suất với khả năng mở rộng (scalable) liên tục - chỉ bị giới hạn bởi khả năng vật lý của AWS.
Để làm rõ vấn đề này, tác giả đã trao đổi với các khách hàng mà có hàng triệu item trong table. Những khách hàng này đang sử dụng DynamoDB với các item được phân phối tốt (well-distributed), search dựa trên Key/Value - tránh các query phức tạp và quan trọng nhất là ko gặp vấn đề về "Hot Key".
Các "Hot Key" chắc chắn là vấn đề nổi tiếng của DynamoDB, được giải thích rõ ở nhiều nơi, bao gồm cả AWS Document - Table
Mặc dù theo lý thuyết, DynamoDB có thể scale vô hạn, nhưng data của bạn tất nhiên sẽ không được lưu trữ trên một server duy nhất :rolling_eyes: Khi data của bạn lớn hơn khả năng của một partition (10GB), nó sẽ chia data vào các partition khác nhau.
Nếu table chỉ nằm trong một partition và nếu throughput Read/Write của application không vượt quá RCU/WCU của partition, thì application của bạn sẽ KHÔNG gặp bất kỳ vấn đề gì do số lượng partition.
Tuy nhiên, nếu bạn dự kiến mở rộng table vượt quá một partition, thì bạn nên cấu trúc lại application của bạn để sử dụng RCU/WCU một cách hiệu quả - tránh xảy ra các "Hot Key".
Với cách tính của DynamoDB, bạn chỉ có thể cung cấp RCU/WCU ở cấp độ toàn table - trải đều trên các partition - và việc tính toán số lượng partition sử dụng công thức như sau:
- (ReadCapacityUnits / 3000) + (Write CapacityUnits / 1000 ) = partitions (rounded up)
- sizeOfDataSet / 10 = partitions (rounded up)

Vậy, nếu bạn có một "Hot Key" trong dataset của bạn - một record mà bạn thường xuyên được truy cập - bạn cần phải đảm bảo rằng RCU/WCU được cung cấp trên table của bạn phải đủ cao để xử lý tất cả Query đó.
Kết quả là RCU/WCU mà bạn cần cho các partition khác - "Cold Key" - sẽ nhỏ hơn nhiều so với tổng năng lực mà bạn đã cung cấp cho table.
Rõ ràng là, nếu application của bạn đang sử dụng quá nhiều RCU trên một key, bạn sẽ cần phải cung cấp RCU vượt quá mức cần thiết trên tất cả các partition khác (điều này gây tốn kém chi phí ).
Tất nhiên, bạn có thể phân chia data vào nhiều table khác nhau - nhưng nếu bạn làm như vậy, bạn đã mất đi lợi thế về khả năng mở rộng mà DynamoDB đã hứa hẹn  - như đã đề cập ở trên .
- như đã đề cập ở trên .
Gần đây, Blog The Million Dollar Engineering Problem, chỉ ra vấn đề về "Hot Key" và cách mà Segment thực hiện để giảm đáng kể chi phí do RCU/WCU trên DynamoDB.
Mình sẽ giải thích một chút nội dung liên quan đến blog này.
Cách tính cost của AWS DynamoDB dựa trên throughput (RCU/WCU của table) - Hiểu đơn giản, nếu table của bạn cần càng nhiều RCU/WCU thì bạn sẽ phải trả càng nhiều tiền.
Như phân tích ở trên, tất cả các hoạt động Read/Write với cùng một key sẽ đi đến cùng một server & cùng một partition. Theo tài liệu chính thức từ DynamoDB, table phân chia các partions như sau:
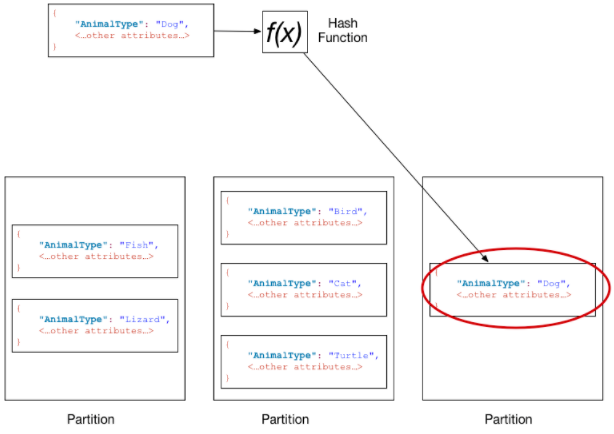
Hiểu một cách cơ bản, chúng ta nên phân bố hoạt động Read/Write một cách đồng đều, bạn sẽ không muốn một Partition/Server sẽ bị quá tải (Hot Key), trong khi các Server khác thì lại rỗi (Cold Key). Vấn đề là mặc dù Segment đã cung cấp khá nhiều capacity cho DynamoDB, nó vẫn bị nghẽn (throttling).
Khi Segment liên hệ với AWS Support, họ được cung cấp một biểu đồ nhiệt về tổng các partition - Họ nhận thấy rằng RCU/WCU thấp hơn nhiều so năng lực thực tế mà họ đã cung cấp cho table DynamoDB
- Y-axis ứng với số partition (Segment có 647 partition trên table này)
- X-access tương ứng với thời gian (giờ)
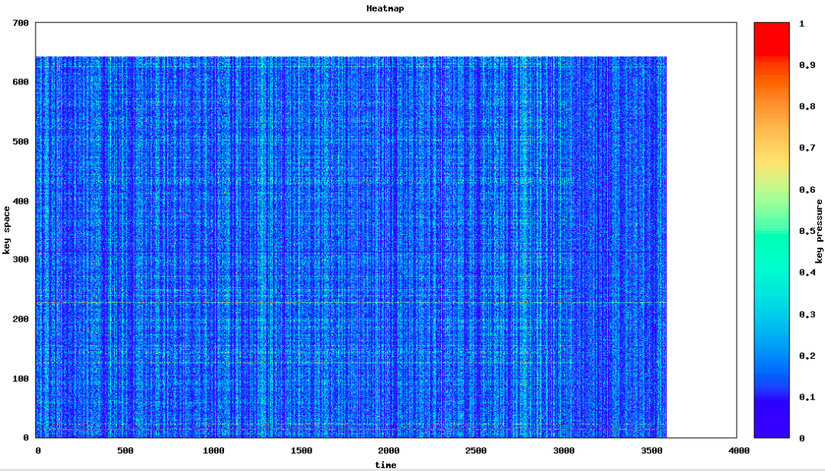
- Các Hot Partition - truy cập thường xuyên sẽ có màu đỏ; trong khi các Partition không được truy cập (Cold) sẽ có màu xanh da trời .
- Nhìn theo chiều dọc, các dòng dường như đều tốt, rất nhiều partition có màu xanh da trời, trải đều trên các key_space.
- Tuy nhiên, nếu bạn nhìn kỹ phía dưới - partition số 19, bạn sẽ thấy một vệt mỏng màu đỏ - Segment đã tìm thấy một partional bị chậm (Hot Key).
Dù vậy, bản đồ nhiệt chỉ cung cấp mức chi tiết ở level partition - chứ không phải ở level key; và không có cách nào để xác định được các Hot Key gặp vấn đề. Để xử lý, họ đã tốn nhiều thời gian và công sức - xác định các key khi xảy ra nghẽn (throttling), fix bugs trên chính code của họ - và có vẻ khó giải quyết triệt để
❖ Về trường hợp của Segment, tác giả đánh giá phần bản đồ nhiệt này được cung cấp từ AWS Support, chứ không phải tool monitor của Segment có thể làm được điều này. Nói cách khác, chúng ta phải liên lạc với team DynamoDB để có thể quan sát được các vấn đề trên chính database của mình.
Thực tế, Segment đã phải xử lý vấn đề Hot Key mà ko có phần mềm giám sát nào - và đây là điều mà chúng ta cần xem xét - Simplicity & Scalability..
DynamoDB được thiết kế như một hộp đen (black box) với rất ít quyền control từ người dùng. Service này giúp bạn dễ dàng sử dụng khi mới bắt đầu, nhưng ở môi trường production, bạn cần nhiều thông tin chi tiết hơn để tìm ra nguyên nhân vì sao data của bạn hoạt động không như mong muốn.
Bạn có thể tham khảo thêm vấn về của DynamoDB tại bài viết You probably shouldn’t use DynamoDB - Đề xuất một giải pháp tốt hơn DynamoDB là Google Bigtable 
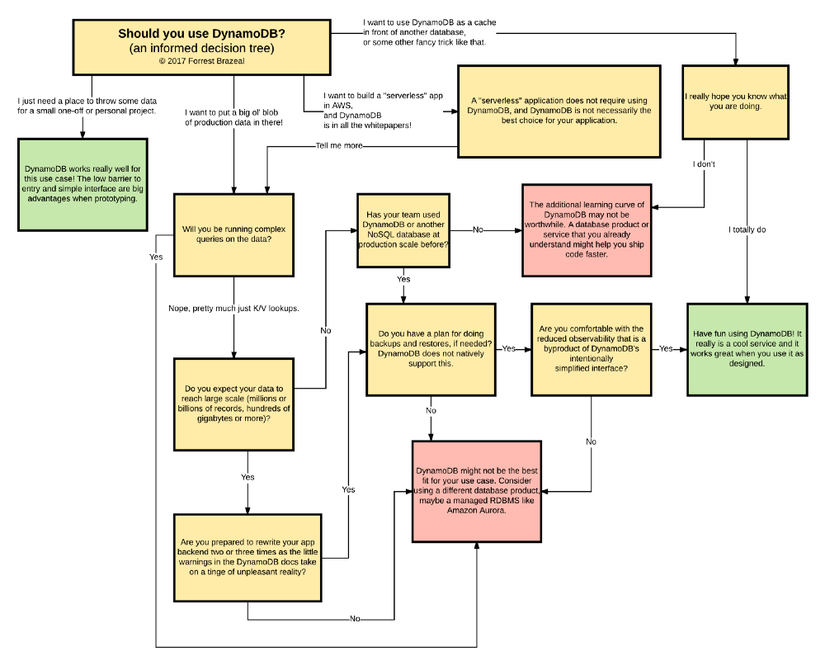
3. Introducing Amazon WhynamoDB
Cuối cùng, tác giả đưa ra một sơ đồ tư vấn - như thế nào để quyết định sử dụng DynamoDB hay không  - mình thấy nó khá là hữu ích.
- mình thấy nó khá là hữu ích.
Bài viết hơi dài, và còn nhiều hạn chế về kiến thức, nếu bạn nào có thắc mắc hoặc câu hỏi liên quan đến nội dung - vui lòng inbox

All rights reserved
