MySQL Indexing
Bài đăng này đã không được cập nhật trong 4 năm
Index là khái niệm cơ bản và vô cùng quan trọng trong MySQL. Tuy nhiên, không hiểu vì sao, với các lập trình viên mới, họ chỉ hiểu index với vai trò đánh chỉ mục, giúp phân biệt các bản ghi. Đương nhiên đó là 1 ích lợi của index, tuy nhiên phần quan trọng nhất index mang lại là tăng hiệu năng của MySQL. Ở bài viết trước, tôi đã cho bạn đọc thấy được lợi thế của việc sử dụng index bằng các phân tích câu lệnh EXPLAIN. Trong bài viết này, tôi sẽ cho bạn đọc thấy rõ hơn cách MySQL lưu trữ index như thế nào và một vài kiểu index, kỹ thuật đánh index trong MySQL.
MySQL lưu trữ index như thế nào
B-Tree
Như đã nói ở trên, index tăng hiệu năng cho MySQL. Vậy cụ thể là tăng gì?
Với các hệ quản trị cơ sở dữ liệu, có 2 thao tác chính là đọc và ghi. Ghi bao giờ cũng ít hơn rất nhiều so với đọc. Nó cũng dễ hiểu khi trong các hệ thống master-slave replication thì số lượng slave dùng riêng cho đọc luôn nhiều hơn rất nhiều so với số lượng master dùng cho ghi (đôi khi chỉ là 1 server). Việc index cải thiện chính là việc tăng hiệu năng của thao tác đọc. Hãy xem thử 1 thao tác đọc cơ bản trong MySQL.
SELECT * FROM users WHERE id = 1;
Vâng, một câu lệnh rất cơ bản, có thể hiểu nó đơn giản là: Tìm người dùng từ bảng users mà có id là 1. Bài toán của chúng ta trở thành bài toán tìm kiếm.
Để hỗ trợ cho công việc lưu trữ rồi tìm kiếm, từ khi còn ngồi ghế giảng đường, chúng ta đã biết đến rất nhiều cầu trúc dữ liệu khác nhau dùng cho tìm kiếm. Bạn có thể tham khảo từ search data structure trên wikipedia để thấy được cả tá cấu trúc dữ liệu, như sorted array, sorted linked list, hash table,...
MySQL không dùng cái gì quá mới mẻ. 2 storage engines phổ biến nhất MyISAM và InnoDB đều dùng B-Tree (thực ra InnoDB dùng B+ Tree, tuy nhiên sự khác biệt không quá lớn và tôi sẽ không nói ở đây). Cũng như các cấu trúc dữ liệu cho tìm kiếm khác, B-Tree giúp chúng ta không cần phải duyệt hết các bản ghi mà vẫn có thể tìm được kết quả mong muốn. Chúng ta sẽ khoan nói về lý do MySQL chọn B-Tree thay vì các cấu trúc dữ liệu khác (phần ý có lẽ sẽ đáng giá một bài viết khác), mà chúng ta sẽ cùng nhìn cách InnoDB lưu dữ liệu bằng B-Tree.
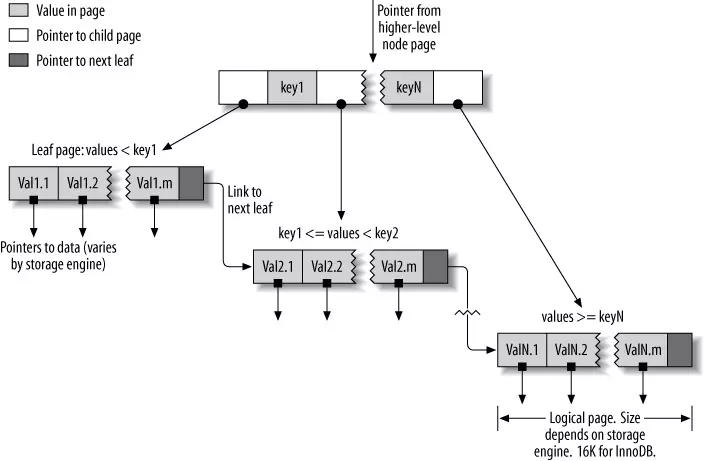
Index sử dụng cấu trúc B-Tree (High performance MySQL 3rd edition, p. 149)
Một đặc điểm của B-Tree là tất cả các lá đều có cùng khoảng cách đến gốc. Như chúng ta thấy trên hình, tất cả các lá đều có con trỏ đến dữ liệu. Dữ liệu ở đây có thể là cả 1 bản ghi, hay chỉ là con trỏ đến bản ghi tùy theo storage engine.
Hình vẽ trên khá cơ bản và chỉ nhằm mục đích giúp bạn đọc nhớ lại B-Tree, còn thực sự storage engine trong MySQL sử dụng B-Tree như thế nào, chúng ta cùng tìm hiểu phần tiếp theo.
Lưu trữ index trong InnoDB và MyISAM
2 storage engine phổ biến nhất của MySQL đều dùng B-Tree. Tuy nhiên cách lưu trữ lại rất khác biệt. Sự khác biệt này liên quan tới khái niệm clustered index.
Trong tài liệu Clustered and Secondary Indexes, các nhà phát triển MySQL khẳng định, Clustered indexchỉ có ở trong InnoDB và nó chính là Primary key theo khái niệm thông thường. Vậy Clustered index có nghĩa là gì?
Có 2 đặc điểm cơ bản của clustered index. 1 đến từ clustered, có nghĩa là bó - các key có giá trị gần nhau sẽ được xếp gần nhau. 2 là ở clustered index, các bản ghi (row) sẽ được lưu trữ cùng với key tại lá của B-Tree, chứ lá không chỉ lưu con trỏ đến bản ghi (và bản ghi thì lưu ở chỗ khác).
Để hiểu rõ hơn, chúng ta tìm hiểu một bài toán cụ thể và xem cách MyISAM lưu B-Tree nonclustered index khác với cách InnoDB lưu BTree clustered index như thế nào.
CREATE TABLE layout_test (
col1 NOT NULL,
col2 NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
);
MyISAM
Với MyISAM, các dòng trong bản ghi sẽ được đánh số từ 0 gọi là row number (con số này khác với primary key). Lá trong B-Tree sẽ lưu giá trị của dòng này, qua đó MyISAM có thể tìm đến bản ghi gốc từ giá trị của lá này.
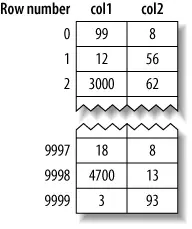
Đánh số dòng trong MyISAM (High performance MySQL 3rd edition, p.171)
Hình trên cho thấy MyISAM có thể tự động đánh số dòng trong các bản ghi. Và từ đó, primary key sẽ chỉ việc lưu trữ số dòng này trong B-Tree.
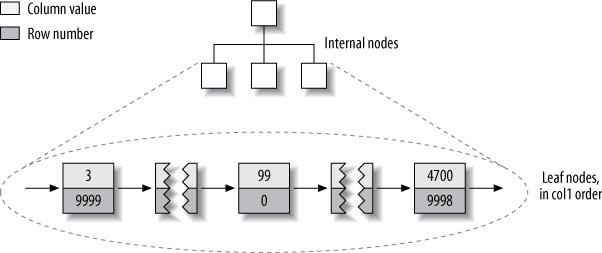
Lưu trữ primary key trong MyISAM (High performance MySQL 3rd edition, p.171)
Lợi ích của cách lưu trữ này là giúp giảm dung lượng cho B-Tree vì dữ liệu của bảng hầu như không lưu ở đó. Tuy nhiên điểm yếu là nếu thứ tự dòng thay đổi, thì sẽ phải cập nhật B-Tree.
InnoDB
Nếu như ở MyISAM, không có sự khác biệt giữa primary key và secondary key, vì cả hai đều link đến dòng của bảng, thì InnoDB lại khác biệt hoàn toàn.
Đầu tiên, primary key trong InnoDB (clustered index) sẽ lưu key và toàn bộ thông tin bản ghi (1 dòng trong bảng) ở lá của cây.
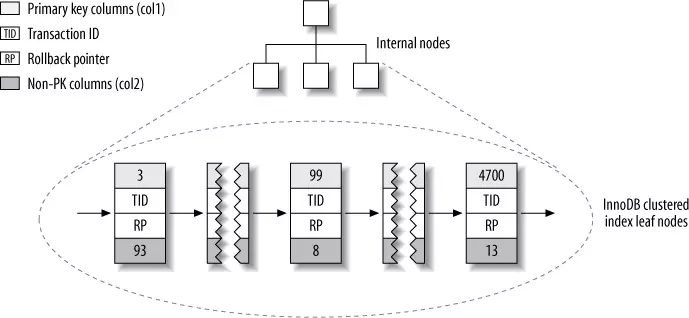
Lưu trữ primary key trong InnoDB (High performance MySQL 3rd edition, p.172)
Cách lưu trữ này giúp InnoDB không cần phải cập nhật lại giá trị của lá khi các dòng thay đổi như trong MyISAM. Thêm vào đó, do lưu trữ bản ghi ở lá luôn, nó giúp cho InnoDB tăng tốc độ truy vấn dữ liệu.
Sau primary key là secondary. Nếu ở MyISAM, secondary key lưu dòng của bản ghi, thì ở InnoDB, secondary key lưu primary key. Và từ primary key, thông qua clustered index sẽ tìm ra bản ghi với dữ liệu mong muốn. Mô hình cơ bản như sau.
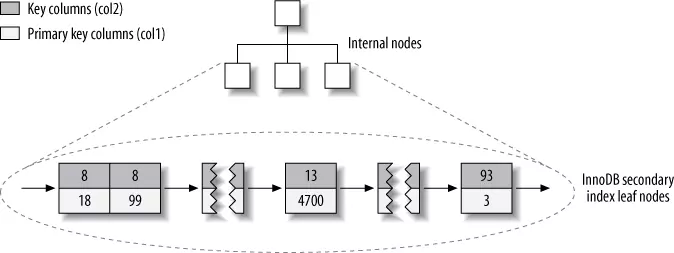
Lưu trữ secondary key trong InnoDB (High performance MySQL 3rd edition, p.173)
Kỹ thuật đánh index trong MySQL
Vậy là bạn đã biết MySQL lưu index như thế nào. Giờ chúng ta bắt đầu tìm hiểu một số kỹ thuật đánh index trong MySQL. Tôi chủ yếu tập trung vào InnoDB với B-Tree vì đó là storage engine và cấu trúc dữ liệu phổ biến nhất ở MySQL.
Multiple columns index
Đánh index theo nhiều cột không phải là quá mới mẻ, khi đi học chúng ta cũng biết điều này. Tuy nhiên, nó không hề dễ và rất nhiều người hiểu sai về nó. Việc hiểu sai về index nhiều cột dẫn đến nhưng hậu quả không đáng có khi triển khai hệ thống thực tế.
Ví dụ, chúng ta có bảng users như sau.
CREATE TABLE users (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('male, 'female') not null,
key(last_name, first_name, dob)
)
Index của chúng ta gồm ba cột, last_name, first_name, dob. Bạn nghĩ sao về hai truy vấn sau đây.
1
SELECT * FROM users WHERE last_name = "allen";
2
SELECT * FROM users WHERE first_name = "julia";
Mới nhìn qua có vẻ tương tự nhau, tuy nhiên sự thực thì câu truy vấn thứ 2 không hề dùng index, và nó sẽ rất nguy hiểm khi số lượng dữ liệu lớn lên. Vậy tại sao truy vấn thứ 2 không dùng index, chúng ta hãy cùng tìm hiểu cấu trúc B-Tree trong trường hợp này.
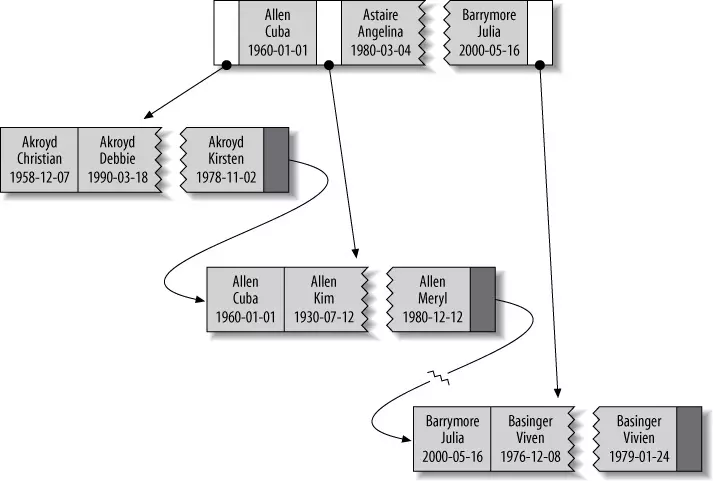
Lưu trữ multiple columns index trong InnoB (High performance MySQL 3rd edition, p.150)
Nhìn vào hình trên, chúng ta có thể thấy. Key được cấu tạo từ ba thành phần: last_name, first_name và dob. Chúng được sắp xếp theo thứ tự last_name, rồi mới đến first_name và dob. Do vậy, nếu tìm kiếm theo first_name, thì không thể sử dụng được key, do phép so sánh bắt đầu từ last_name.
Đến đây, chắc bạn đọc đã hiểu tại sao trường hợp 2 ở trên lại không hoạt động. Một cách tóm tắt, chúng ta có các trường hợp sau, trong đó index của B-Tree có thể sử dụng được.
-
Tìm toàn bộ dữ liệu trong key. Chúng ta có thể tìm chính xác người mang tên Cuba Allen sinh ngày 1-1 năm 1960.
-
Tìm theo phần bên trái. Chúng ta có thể tìm người có last_name là Allen. Khi đó, chỉ phần đầu tiên của key được sử dụng.
-
Tìm kiếm theo phần đầu của cột. Chúng ta có thể tìm theo phần đầu của cột với việc chỉ dùng phần đầu của key. Cụ thể, chúng ta có thể tìm tất cả những người có last name bắt đầu bằng chữ J.
-
Tìm theo một khoảng dữ liệu. Cũng với việc chỉ dùng phần đầu của key, chúng ta có thể tìm tất cả những người có last name nằm trong khoảng từ Allen đến Barymore.
-
Tìm chính xác một phần và tìm theo phần bên trái của phần khác. Với việc dùng phần thứ nhất và thứ hai của key, chúng ta có thể tìm những người có last name là Allen và first name bắt đầu bằng chữ K.
Hash Indexes
Với hầu hết mọi người, hash indexes là một khái niệm khá xa lạ. Bạn đã bao giờ tạo bảng theo cách này chưa?
create table testhash (
fname varchar(50) not null,
lname varchar(50) not null,
key using hash(fname)
) ENGINE=MEMORY;
Vâng, một bảng với hash index được tạo. Tuy nhiên chú ý rằng storage engine ở đây là MEMORY. Nó không phổ biến trong MySQL bởi chúng ta đã quá quen với InnoDB. Cách làm việc của hash index là tự động tạo ra một giá trị hash của cột rồi xây dựng BTree theo giá trị hash đó. Giá trị này có thể trùng nhau, và khi đó node của BTree sẽ lưu trữ một danh sách liên kết các con trỏ trỏ đến dòng của bạng. Hash index không thực sự phổ biến bởi nó không có phép tìm kiếm gần đúng, tìm kiếm trong một khoảng giá trị hay sắp xếp.
Hash index, dù không thực sự quá hữu hiệu nhưng trong một vài trường hợp vẫn có giá trị sử dụng. Hơn nữa, dù dùng InnoDB, chúng ta vẫn hoàn toàn có khả năng tự tạo hash index.
Cùng tìm hiểu một bài toán khá oái oăm sau: Chúng ta có cơ sở dữ liệu lưu trữ các URL, và không may lắm, khi khách hàng yêu cầu tìm kiếm đúng theo URL.
Ý tưởng đầu tiên nảy sinh, liệu chúng ta có nên đánh index cho URL. Nên nhớ URL được chấp nhận giá trị dài nhất là 2083 ký tự, vậy nếu đánh index cho trường này thì tối thiểu cần 2083 bytes cho khóa. Con số này quá lớn nếu biết rằng thông thường đánh index cho INT, chúng ta chỉ mất có 4 bytes cho key.
Lựa chọn đánh index cho cả url có vẻ không hợp lý lắm? Vậy giải pháp là gì? Câu trả lời là dùng hash index.
CREATE TABLE pseudohash (
id int unsigned not null auto_increment,
url varchar(2100) not null,
url_crc int unsigned not null default 0,
primary key (id),
key (url_crc)
);
Ở đây, chúng ta sử dụng hàm có sẵn của MySQL là CRC32 để tính hash cho url. Chúng ta sử dụng trigger để đảm bảo mỗi thao tác thêm, sửa url đều tự động cập nhật url_crc. Truy vấn select sẽ có dạng sau nếu chúng ta muốn tìm bản ghi có url là https://www.mysql.com.
SELECT * FROm pseudohash WHERE url_crc = CRC32("https://www.mysql.com") AND url = "https://www.mysql.com";
Do hàm CRC32 có thể trả ra các kết quả giống nhau với các đầu vào khác nhau, chúng ta cần điều kiện thứ 2 để chắc chắn tìm đúng bản ghi. Nhờ phép so sánh đầu tiên để tìm theo url_crc, chúng ta đã hạn chế được rất nhiều các bản ghi cần duyệt, qua đó tăng hiệu năng cho MySQL.
Tài liệu tham khảo
All rights reserved
