0
Xây dựng mô hình máy học sử dụng ít dữ liệu
Xin chào các bạn !.
Chuyện là mình đang xây dựng mô hình máy học về phân lớp hình ảnh.
Mình đang cải tiến mô hình để tăng độ chính xác với tập dữ liệu nhỏ do mình tạo ra.
Trong tập dữ liệu: tập training có 2 lớp mỗi có 20 mẫu, tập validation có 2 lớp mỗi lớp có 5 mẫu. Đây là dataset của mình. Toàn bộ code đều trong này. Mình đã làm theo hướng dẫn của trang Keras theo đường: link .
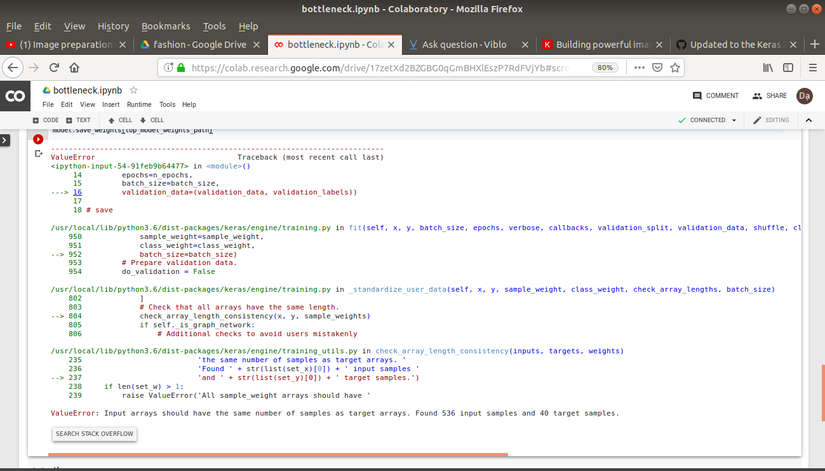
Nhưng khi huấn luyện thì lỗi như hình bên dưới. Mong mọi người có thể giúp mình.
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras import applications
# dimensions of images
# dimensions of images
img_width, img_height = 150, 150
# data
top_model_weights_path = 'bottleneck_fc_model.h5'
train_data_dir = "train"
validation_data_dir = "valid"
nb_train_samples = 40
nb_validation_samples = 10
n_epochs = 30
batch_size = 16
# features
bottleneck_features_train_file = 'bottleneck_features_train.npy'
bottleneck_features_validation_file = 'bottleneck_features_validation.npy'
def save_bottleneck_features():
if os.path.exists(bottleneck_features_validation_file) and os.path.exists(bottleneck_features_train_file):
return
datagen = ImageDataGenerator(rescale=1. / 255)
# build the VGG16 network
model = applications.VGG16(include_top=False, weights='imagenet')
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_train = model.predict_generator(
generator,
nb_train_samples // batch_size)
np.save(bottleneck_features_train_file,
bottleneck_features_train)
generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(
generator,
nb_validation_samples // batch_size)
np.save(bottleneck_features_validation_file, bottleneck_features_validation)
save_bottleneck_features()
# Load data from saved bottleneck features
train_data = np.load(bottleneck_features_train_file)
train_labels = np.array([0] * (nb_train_samples // 2) + [1] * (nb_train_samples // 2))
validation_data = np.load(bottleneck_features_validation_file)
validation_labels = np.array([0] * (nb_validation_samples // 2) + [1] * (nb_validation_samples // 2))
train_data.shape
(536, 4, 4, 512)
train_labels.shape
(40,)
validation_data.shape
(100, 4, 4, 512)
validation_labels.shape
(10,)
# Build model
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(1, activation="sigmoid"))
model.compile(
optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(
train_data, train_labels,
epochs=n_epochs,
batch_size=batch_size,
validation_data=(validation_data, validation_labels))
# save
model.save_weights(top_model_weights_path)
Nhưng lỗi như hình dưới
Thêm một bình luận
2 CÂU TRẢ LỜI
+3
Mình nghĩ bạn nên code lại cho dễ nhìn hơn, hoặc thử lại với bộ dữ liệu mới vì ít dữ liệu thế kia thì mình không dám chắc bạn huấn luyện được gì.
Còn vấn đề là code của bạn sai ở đâu và làm thế nào để cho nó chạy.
Bạn có 40 ảnh trong thư mục train, 10 trong valid, bạn sử dụng ImageDataGenerator để cố gắng tạo được nhiều dữ liệu hơn. Và kết quả là bạn có 536 train và 100 valid.
Nhưng, label bạn lại vẫn lấy từ đống dữ liệu ban đầu với kích thước là nb_train_samples = 40, nb_validation_samples = 10 nên nó lỗi thôi. Khi bạn làm thêm dữ liệu thì bạn cũng phải thêm nhãn chứ.
Để code của bạn chạy được. Bạn sửa lại chỗ sinh label này.
Từ:
# Load data from saved bottleneck features
train_data = np.load(bottleneck_features_train_file)
train_labels = np.array([0] * (nb_train_samples // 2) + [1] * (nb_train_samples // 2))
validation_data = np.load(bottleneck_features_validation_file)
validation_labels = np.array([0] * (nb_validation_samples // 2) + [1] * (nb_validation_samples // 2))
Sửa thành:
# Load data from saved bottleneck features
train_data = np.load(bottleneck_features_train_file)
train_labels = np.array([0] * (train_data.shape[0] // 2) + [1] * (train_data.shape[0] // 2))
validation_data = np.load(bottleneck_features_validation_file)
validation_labels = np.array([0] * (validation_data.shape[0] // 2) + [1] * (validation_data.shape[0] // 2))
Kết quả sau 30 epoch  :
:
Epoch 27/30
536/536 [==============================] - 0s 486us/step - loss: 0.6932 - acc: 0.4813 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 28/30
536/536 [==============================] - 0s 516us/step - loss: 0.6932 - acc: 0.4701 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 29/30
536/536 [==============================] - 0s 487us/step - loss: 0.6932 - acc: 0.4888 - val_loss: 0.6932 - val_acc: 0.5000
Epoch 30/30
536/536 [==============================] - 0s 520us/step - loss: 0.6932 - acc: 0.5000 - val_loss: 0.6932 - val_acc: 0.5000
Cảm ơn bạn nhiều nha
Không có gì bạn ơi  )
)
0
Số lượng dữ liệu và nhãn trong tập huấn luyện bạn truyền vào đang bị không bằng nhau:
train_labels.shape = (40,)
trong khi đó
train_data.shape = (536, 4, 4, 512)
cả hai đều phải là 40, bạn kiểm tra lại xem lỗi ở đâu nhé!
Đấy là vấn đề mình hỏi đó. Mình đã tìm lỗi cả ngày mà không biết lỗi chỗ nào mà gây ra như thế đó.
Bình luận này đã bị xóa
@Phuoc đợi mình xem lại code tí 
bạn xem lại chỗ này xem
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_train = model.predict_generator(
generator,
nb_train_samples)
np.save(bottleneck_features_train_file,
bottleneck_features_train)
Bình luận này đã bị xóa

@Phuoc model VGG16 của bạn cho đầu ra là (4, 4, 512)
mình nghĩ là dòng này
bottleneck_features_train = model.predict_generator(
generator,
nb_train_samples)
làm nó predict ra số lượng dữ liệu bị sai, vì mình thấy đầu ra của nó có tận 536 ảnh.
