+1
tính khoảng cách tương đồng giữa 2 vector.
Xin chào mọi người, em có câu hỏi về sử lý ảnh, muốn tham khảo ý kiến ạ.
trước hết thì e có một ảnh như dưới đây.
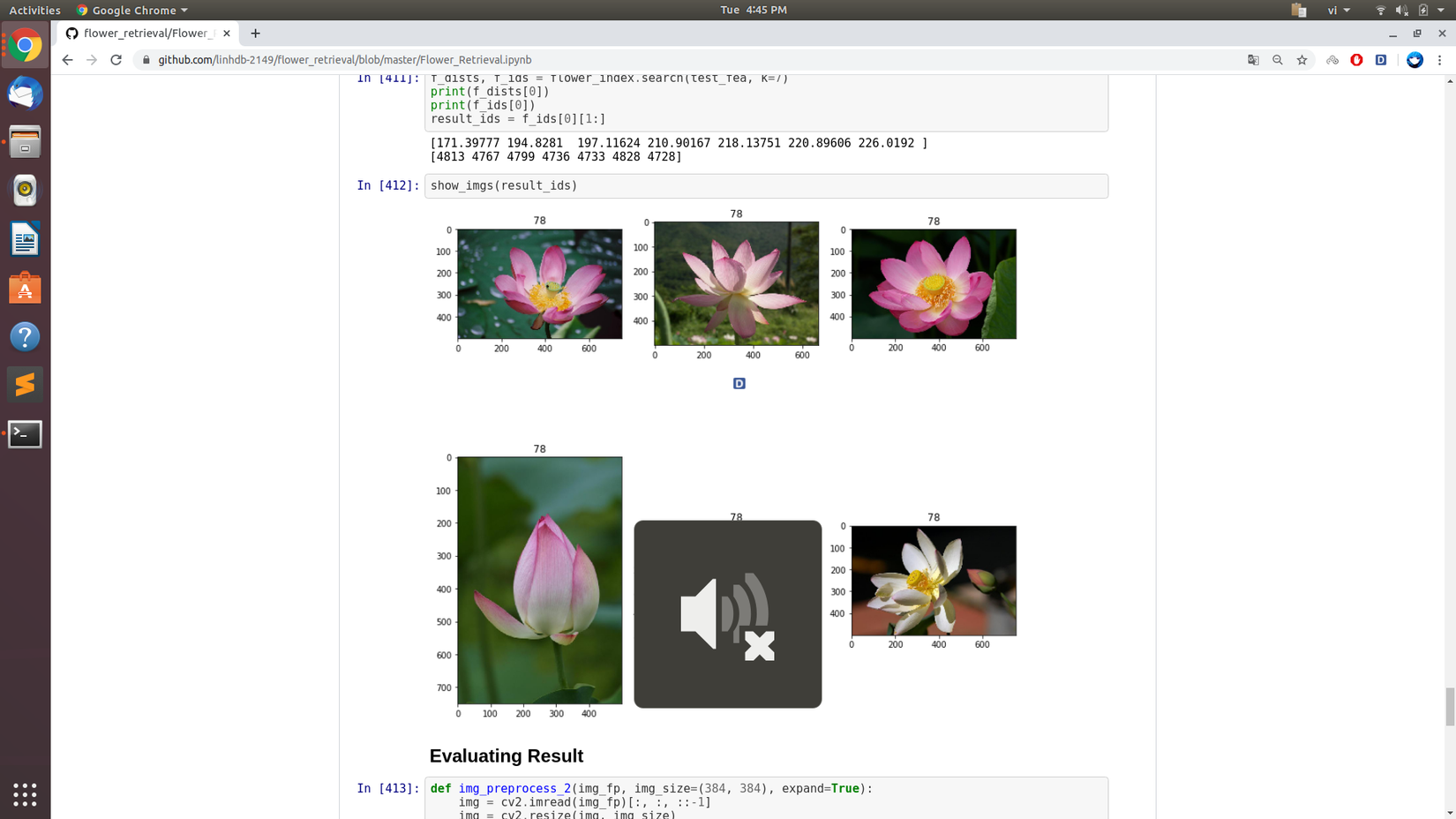
Mục tiêu của e là cần tìm ra bước ảnh tương đồng, e mới biết đến cách đánh index trong thư viện faiss , nhưng e muốn tìm xem có bao nhiêu thứ khác mình có thể làm với nó mà ko dùng đến thằng faiss kia mong mọi người cho em xin ý kiến, càng nhiều càng tốt , cảm ơn mọi người đã dành sự quan tâm. !
Thêm một bình luận
2 CÂU TRẢ LỜI
+4
Theo mình tìm hiểu, thì tìm ảnh tương đồng thì sẽ theo mô hình dưới.
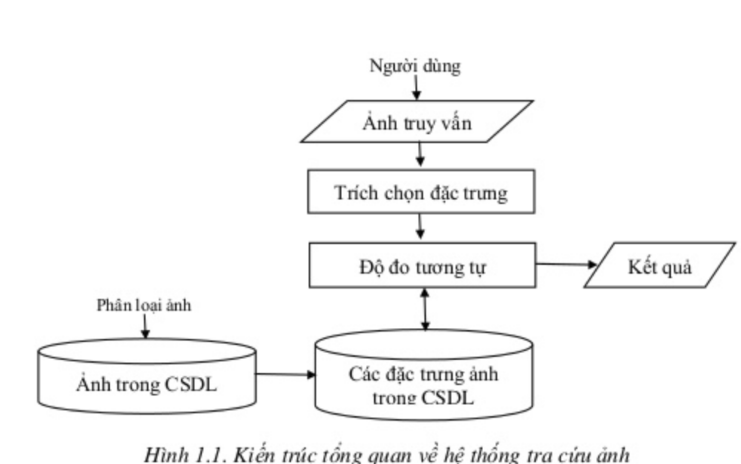
Với bài toán dữ liệu cơ sở dữ liệu nhỏ, bạn có thể đo độ tương đồng bằng các lấy vector đặc trưng của ảnh cần truy xuất trừ đi vector đặc trưng của từng ảnh trong cơ sở dữ liệu, rồi sắp xếp chọn ra những cái nhỏ nhất. Nhưng với cơ sở dữ liệu lớn thì bạn có thể tìm hiểu Locality Sensitive Hashing.
Với trích xuất đặc trưng nếu không dùng deep learning, bạn có thể dùng color histogram(1995), Histogram of oriented gradients Histogram of oriented gradients, gist descriptor,...Bạn có thể tham khảo 1 bài viết chi tiết với dùng thư viện OpenCV: https://medium.com/machine-learning-world/feature-extraction-and-similar-image-search-with-opencv-for-newbies-3c59796bf774
Nếu dùng deep learning thì bạn có thể tham khảo các bài báo bên dưới mình tim được với Deep mình không hiểu rõ  .
.
@nguyen.tien.datb Trả lời có tâm quá em ơi  ) )
) )
@QuangPH Em cũng có lần cần tìm hiểu về tìm ảnh tương đồng nên có lưu lại mấy trang tham khảo ạ 
@nguyen.tien.datb rất chi tiết luôn, cảm ơn bạn nhé.
+3
Theo mình cách đơn giản nhất là bạn encode các ảnh ra thành các vector rồi dùng kNN, kNN sẽ so sánh liệu đó với tất cả dữ liệu trọng tập huấn luyện và chọn ra k dữ liệu gần giống nhất. Trong k dữ liệu đó, kNN sẽ xem xét xem loại nào là loại chiếm đa số --> và sẽ đưa ra kết luận rằng tập dữ liệu cần xác định thuộc loại đó:
https://laptrinha2z.blogspot.com/2015/10/giai-thuat-k-lang-gieng-gan-knnk.html
@trungson077 đúng là mình làm như vậy luôn, dựa trên tư tưởng KNN, làm xong rồi, mình băn khoăn có thể xài thêm những pp nào khác để mình tham khảo và áp dụng luôn, rất cảm ơn bạn đã góp ý. !
@manhduydoan Mình thấy có 2 phương pháp phổ biến nhất để phân loại là dùng kNN và SVM, hoặc bạn có thể dùng thư viện annoy hoặc hnswlib bản chất 2 thằng này cũng là nearest neighbors.
