Machine Learning thật thú vị
Bài đăng này đã không được cập nhật trong 4 năm
Loạt bài này gồm 5 phần, được dịch từ nguồn https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471#.ksejcntgw
Mình thấy loạt bài này tác giả rất thú vị nên mình sẽ dịch và cập nhật từng phần. Hy vọng sẽ giúp ích phần nào cho những bạn quan tâm tới lĩnh vực Học máy.
Có phải bạn đã từng nghe ai đó nói về Học Máy nhưng bạn chỉ hình dung được ý nghĩa mơ hồ về nó?
Loạt bài hướng dẫn này dành cho những ai đang tò mò về lĩnh vực Học Máy nhưng không biết bắt đầu từ đâu. Tôi hình dung rằng có rất nhiều người đã cố gắng đọc bài viết về học máy trên Wikipedia, đã thất vọng và từ bỏ mong móng ai đó sẽ đưa ra những giải thích ở mức độ cao hơn. Lọat bài viết này sẽ giúp bạn giải đáp về điều đó.
Mục đích là hướng tới tất cả mọi người - có nghĩa rằng bài viết sẽ được đề cập tới nhiều vấn đề tổng quan.
Machine Learning là gì?
Học Máy là ý tưởng rằng có những thuật toán di truyền có thể nói với bạn điều gì đó thú vị về một tập dữ liệu mà bạn không cần phải viết những đoạn mã tùy chỉnh cụ thể cho vấn đề đó. Thay vì phải viết mã, bạn cung cấp dữ liệu cho những thuật toán đó và nó xây dựng logic cho chính nó dựa trên dữ liệu.
Ví dụ, một trong số chúng là thuật toán phân lớp. Nó có thể phân chia dữ liệu vào nhiều nhóm khác nhau. Thuật toán phân lớp được dùng để nhận dạng chữ số tay cũng có thể được sử dụng để phân loại thư rác mà không cần thay đổi dòng mã nào. Chúng đều dùng chung một thuật toán nhưng được truyền vào các dữ liệu huấn luyện khác nhau do đó nó dẫn đến các logic phân lớp khác nhau.
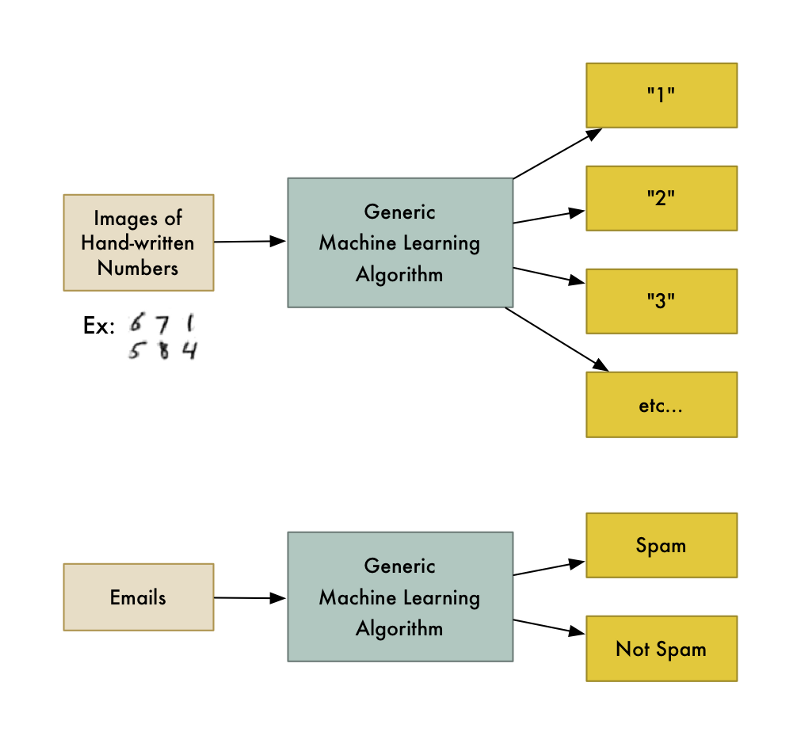
"Học Máy" là một thuật ngữ chung bao gồm rất nhiều loại giải thuật di truyền.
Hai loại thuật toán học máy
Bạn có thể nghĩ tới các thuật toán học máy với hai nhóm chính: Học có giám sát và Học không giám sát. Sự khác biệt giữa chúng rất đơn giản nhưng lại thực sự quan trọng.
Học có giám sát
Giả sử rằng bạn là một đại lý bất động sản. Doanh nghiệp của bạn đang phát triển, vì vậy bạn thuê nhiều các thực tập sinh làm đại lý giúp đỡ bạn. Nhưng có một vấn đề - bạn có thể xem qua một ngôi nhà và có một ý tưởng tuyệt vời về giá trị của ngôi nhà đó. Nhưng các học viên của bạn không có kinh nghiệm như bạn vì vậy họ không biết cách để định giá được ngôi nhà của họ.
Để giúp đỡ các học viên, bạn quyết định viết một ứng dụng nhỏ có thể ước lượng giá trị của ngôi nhà trong khu vực dựa trên kích cỡ, khu vực lân cận, ..., và những ngôi nhà tương tự đã được bán.
vi vậy bạn viết ra mọi lần ai đó bán mọt ngôi nhà ở thành phố của bạn trong 3 tháng. Với mỗi ngôi nhà, bạn viết ra một loạt các đặc điểm - số lượng phòng ngủ, diện tích, khu vực lân cận,... Nhưng quan trọng nhất, bạn viết ra được giá bán cuối cùng:
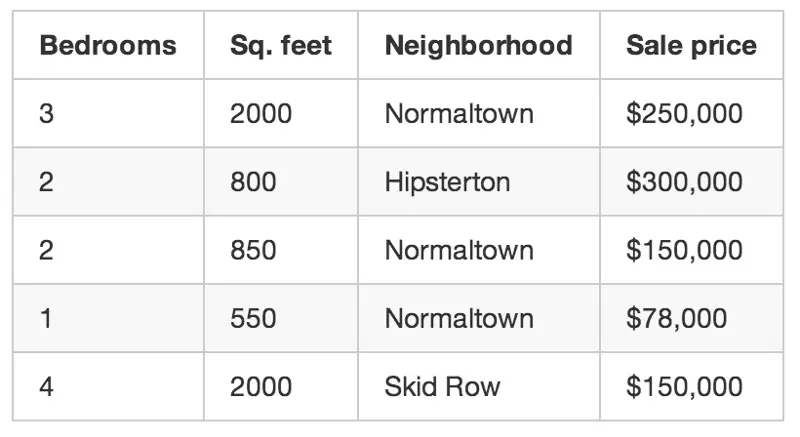
Sử dụng dữ liệu huấn luyện trên, chúng ta muốn tạo ra một chương trình có thể ước lượng được giá trị của những ngôi nhà khác trong khu vực của bạn:

Đó được gọi là Học có giám sát. Bạn biết được câu trả lời cho mỗi vấn đề và có thể đi ngược từ đó để tìm ra logic chung.
Để xây dựng nên ứng dụng, bạn đưa dữ liệu huấn luyện về mỗi ngôi nhà vào thuật toán học máy của bạn. Thuật toán cố gắng tìm ra những dạng toán cần thực hiện để những con số bạn đưa vào làm việc. 
Trong Học có giám sát, bạn đang cho phép máy tính tìm ra mối quan hệ đó cho bạn. Và một khi bạn biết rằng Toán học đã giải quyết được một tập hợp các vấn đề, bạn có thể sử dụng chúng để giải quyết bất kỳ vấn đề nào đó tương tự.
Học không giám sát
Quay trở lại với ví dụ ban đầu về đại lý bất động sản. Nếu như bạn không biết giá bán của mỗi ngôi nhà? Mặc dù bạn biết được kích thước, vị trí, mọi đặc điểm khác của ngôi nhà, nhưng bạn vẫn có thể làm được một vài điều rất cool. Đó gọi là học không giám sát.
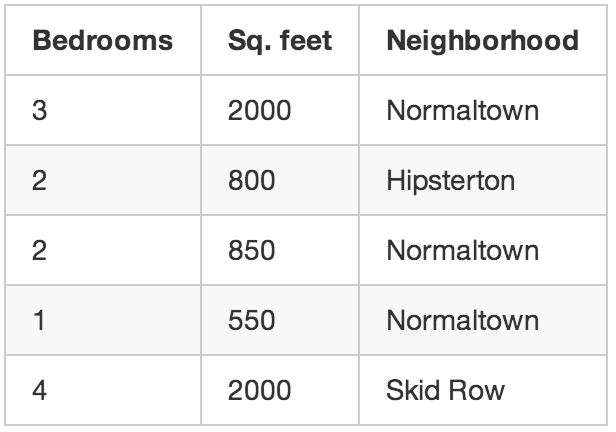
Mặc dù bạn không thể cốc gắng dự đoán một con số chính xác (về giá cả), bạn vẫn có thể làm một vài điều thú vị với học máy.
Điều này giống như một ai đó đưa cho bạn một danh sách các số trên một tờ giấy và bảo "Tôi thực sự không biết ý nghĩa của các con số đó nhưng có thể bạn sẽ tìm ra nếu như đây là một mô hình, một cách chia nhóm hoặc là điều gì đó - chúc may mắn!"
Vì vậy, bạn có thể làm gì với những dữ liệu này? Để bắt đầu, bạn có thể có một thuật toán tự động xác định các phân nhóm khác nhau trong dữ liệu của bạn. Có thể bạn sẽ tìm ra rằng những người mua nhà trong khu vực gần các trường đại học thực sự thích những ngôi nhà nhỏ với nhiều phòng ngủ, trong khi những người mua nhà ở ngoại ô thích những ngôi nhà có 3 phòng ngủ với diện tích sử dụng lớn hơn. Nắm rõ được sự khác nhau của những nhóm khách hàng có thể giúp bạn định hướng các nỗ lực tiếp thị.
Một điều thú vị nữa là bạn có thể tự động xác định được những ngôi nhà khác biết với phần chung. Có lẽ những ngôi nhà này là những biệt thự khổng lồ và bạn cso thể tập trung nhân viên bán hàng của bạn vào những khu vực đó bởi vì nó sẽ mang lại số tiền hoa hồng lớn hơn.
Phần còn lại của bài viết này sẽ tập trung vào học có giám sát, nhưng nó không có nghĩa rằng học không giám sắt ít thú vị hơn hay ít có ứng dụng thực tiễn hơn. Trong thực tế, học không giám sắt đang ngày càng trở nên quan trọng cũng như các thuật toán được cải thiện tốt hơn bởi vì nó có thể được sử dụng mà không cần phải dán nhãn dữ liệu với những câu trả lời đúng.
Việc để có thể ước tính được giá trị của một ngôi nhà thực sự có được xem như "learning"?
Với con người, bộ não có thể tiếp cận hầu hết mọi tình huống và học hỏi làm thế nào để giải quyết với những tình huống không có bắt kỳ chỉ dẫn rõ ràng nào. Nếu bạn làm công việc bán nhà trong một thời gian dài, bạn sẽ có một bản năng "cảm nhận" đúng giá của một ngôi nhà, cách tốt nhất để tiếp thị ngôi nhà đó, đối tượng khách hàng quan tâm tới ngôi nhà đó, ... Mục tiêu của Trí tuệ nhân tạo là để có thể nhân rộng khả năng này với máy tính.
Nhưng các thuật toán học máy hiện tại chưa đủ tốt - chúng chỉ làm việc khi tập trung vào những vấn đề cụ thể, giới hạn. Có lẽ một định nghĩa tốt hơn cho "learning" trong trường hợp này là "tìm ra một phương trình để giải quyết một vấn đề cụ thể dựa trên một số dữ liệu mẫu". Thật không may là cách diễn đạt đó không phải là cái tên tốt. Vì vậy chúng tôi kết thúc với cái tên gọi "Machine Learning" (Học máy).
Tất nhiên nếu bạn đọc bài viết này trong 50 năm tới, chúng tôi đã tìm ra thuật toán cho AI, sau đó toàn bộ bài viết này có vẻ như hơi kỳ lạ. Có thể ngừng đọc và đi nói với người máy của bạn đi làm một chiếc bánh sandwich - đó là tương lai của con người mà.
Hãy bắt đầu viết chương trình đó
Trước khi đọc tiếp, bạn có thể dành ra chút thời gian suy nghĩ xem cách viết chương trình định giá ngôi nhà như ví dụ bên trên.
Nếu như bạn không hề biết gì về học máy, bạn có thể sẽ cố gắng viết ra vài quy tắc để ước tính giá trị của một ngôi nhà như ví dụ sau:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
price_per_sqft = 100
# start with a base price estimate based on how big the place is
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
if num_of_bedrooms == 0:
# Studio apartments are cheap
price = price — 20000
else:
# places with more bedrooms are usually
# more valuable
price = price + (num_of_bedrooms * 1000)
return price
Nếu bạn dành thời gian để cải tiến chương trình này, bạn cũng sẽ hoàn thành mục đích với nó. Tuy nhiên, chương trình của bạn sẽ không bao giờ hoàn hảo và nó sẽ rất khó để duy trì khi giá cả thay đổi.
Liệu nó có trở nên tốt hơn không nếu như máy tính có thể tỉm ra cách thực hiện chức nằng này giúp bạn? Liệu ai sẽ quan tâm chính xác những việc chức năng này làm miễn là nó có thể trả về kết quả chính xác:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = <computer, plz do some math for me>
return price
Một cách thú vị để suy nghĩ về vấn đề này là coi giá cả như một món hầm ngon và các gia vị gồm số lượng phòng ngủ, diện tích và khu vực lân cận. Nếu bạn có thể tìm ra mức độ tác động tới giá của từng thành phần, khi đó có thể xác định chính xác tỉ lệ của các thành phần trong việc tạo nên giá trị cuối cùng của ngôi nhà.
Điều này sẽ làm rút gọn chức năng ban đầu của bạn tới mức thực sự đơn giản như sau:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * .841231951398213
# and a big pinch of that
price += sqft * 1231.1231231
# maybe a handful of this
price += neighborhood * 2.3242341421
# and finally, just a little extra salt for good measure
price += 201.23432095
return price
Hãy chú ý đến các con số được dùng trong hàm trên, chúng là những trọng số. Nếu chúng ta có thể xác định được các con số đó đồng nghĩa với việc chúng ta có thể dự đoán được giá của mọi ngôi nhà!
Một cách đơn giản để tìm ra được các trọng số đó được tiến hành như sau:
Bước 1:
Bắt đầu với các trọng số được gán giá trị là 1.0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# a little pinch of this
price += num_of_bedrooms * 1.0
# and a big pinch of that
price += sqft * 1.0
# maybe a handful of this
price += neighborhood * 1.0
# and finally, just a little extra salt for good measure
price += 1.0
return price
Bước 2:
Chạy thử nghiệm tất cả những ngôi nhà mà bạn biết và xem độ chênh lệch giá giữa con số dự đoán so với giá thực tế của từng ngôi nhà:
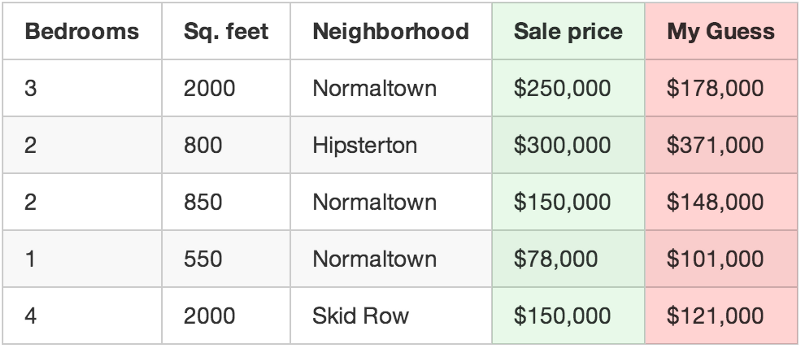
Giả sử bạn có 500 ngôi nhà, và con số của bạn tính được ít hơn $86,123,373. Đây chính là mức độ sai số mà chức năng của bạn đang thực hiện.
Bây giờ lấy tổng số chênh lệch chia đều cho 500. Gọi kết quả thu được là sai số trung bình của chức năng của bạn.
Nếu bạn có thể đưa sai số trung bình về 0 bằng cách điều chỉnh các trọng số, khi đó chức năng của bạn đã hoàn hảo. Nó có nghĩa rằng trong mọi trường hợp, chức năng của bạn dự đoán chính xác giá của mỗi ngôi nhà dựa trên dữ liệu đầu vào. Vì vậy mục đích của chúng ta - đưa sai số trung bình đó về thấp nhất có thể bằng cách thử nhiều trọng số khác nhau.
Bước 3:
Lặp lại bước 2 liên tục với sự kết hợp của các trọng số. Bất cứ sự kết hợp của các trọng số nào làm cho sai số gần với 0 nhất là những gì bạn cần. Khi bạn tìm ra được các trọng số đó, bạn đã giải quyết được vấn đề.
Đương nhiên bạn sẽ không thể thử mọi trường hợp có thể của các trọng số để tìm ra nhóm trọng số tốt nhất.
Để tránh mất rất nhiều thời gian, các nhà toán học đã tìm ra nhiều cách thông minh để nhanh chóng tìm được giá trị tốt cho những trọng số mà không cần phải nỗ lực quá nhiều. Sau đây là một cách:
Đầu tiên, viết một phương trình đơn giản biểu diễn ở bước 2:
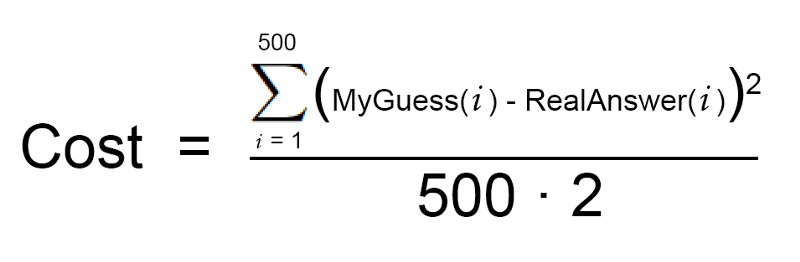
Sau đó viết lại chính xác phương trình trên, nhưng sử dụng một loạt các thuật ngữ toán học:
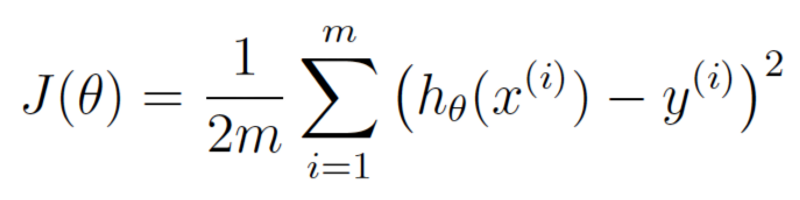
Phương trình trên thể hiện mức độ sai số giữa giá ước lượng và giá thực tế.
Nếu chúng ta đồ thị hóa phương trình lượng giá này cho tất cả các giá trị có thể của các trọng số number_of_bedrooms và sqft, chúng ta sẽ nhận được một đồ thị tương tự như sau:
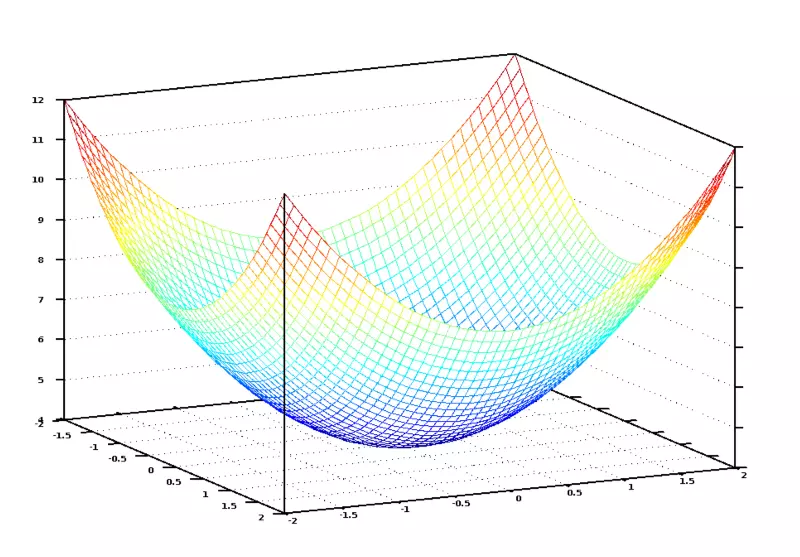
Trong đồ thị trên, điểm thấp nhất màu xanh da trời là nơi thể hiện sự sai số thấp nhất - vì vậy, chức năng của chúng ta đạt sai số thấp nhất. Vì vậy nếu chúng ta tìm được các trọng số để đạt tới điểm thấp nhất trong đồ thị, chúng ta sẽ giải quyết được vấn đề.
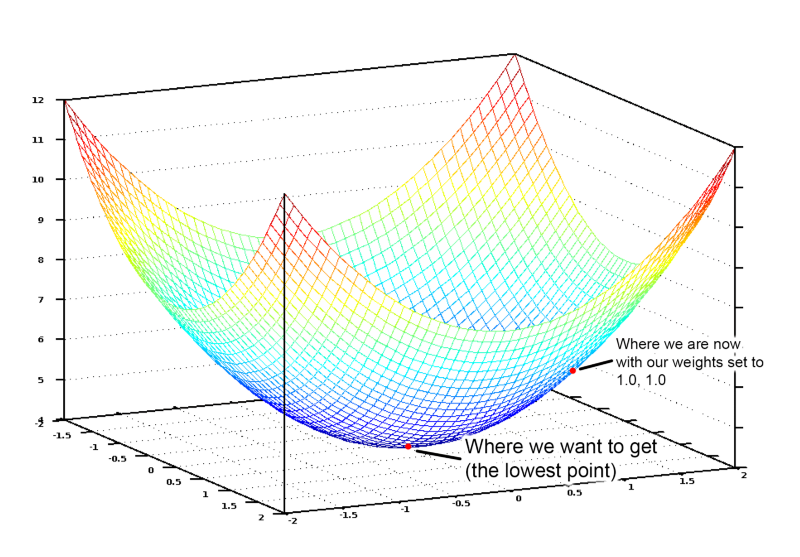
Vì vậy, chúng ta chỉ cần thực hiện những điều chỉnh các trọng số để tiến dần tới điểm thấp nhất của dồ thị.
Trên đây là tóm tắt tổng quát quá trình bạn tìm ra được các trọng số cho chức bạn đã viết. Nếu như bạn sử dụng một thư viện học máy có sẵn đề giải quyết vấn đề của bạn, quá trình trên đã được thực hiện sẵn trong thư viện đó rồi. Tuy nhiên, nó thực sự vẫn rất hữu ích để giúp bạn biết được điều gì đang diễn ra đằng sau thư viện đó.
Ba bước tôi mô tả trên đây được gọi là hồi quy tuyến tính đa biến. Bạn dự đoán một phương trình phù hợp với dữ liệu của tất cả ngôi nhà bạn có được thông tin. Sau đó bạn sử dụng phương trình đó để ước tính giá bán của những ngôi nhà mới. Đó là một ý tưởng thực sự mạnh và sẽ giúp ích bạn trong thực tế.
Nhưng trường hợp tôi mới đưa ra là khá đơn giản, nó sẽ không đúng trong mọi trường hợp khác. Lý do đơn giản là vì giá của một ngôi nhà sẽ không phải luôn luôn đi theo một đường tuyến tính.
May mắn vì chúng ta có nhiều cách để giải quyết vấn đề này. Có rất nhiều thuật toán học máy khác có thể xử lý dữ liệu phi tuyến tính (Neural network, SVM).
Học máy có phải là phép thuật không?
Một khi bạn bắt đầu nhận thấy rằng các kỹ thuật học máy có thể dễ dàng giải quyết các vấn đề dường như thực sự khó (nhận dạng chữ viết tay), bạn bắt đầu cảm thấy bạn có thể sử dụng học máy để giải quyết bất kỳ vấn đề gì với lượng dữ liệu vừa đủ. Chỉ đơn giản là cung cấp dữ liệu và ngồi đợi máy tính tìm ra các phương tình thỏa mãn với dữ liệu đó!
Nhưng rất quan trọng để ghi nhớ rằng học máy chỉ có thể làm việc nếu vấn đề đó có khả năng được giải quyết với những dữ liệu mà bạn có.
Ví dụ, nếu bạn xây dựng một mô hình dự đoán giá nhà dựa trên các loại cây được trồng trong chậu của ngôi nhà đó, nó sẽ không bao giờ khả thi.
Vì vậy hãy ghi nhớ rằng, nếu một chuyên gia không thể giải quyết một vấn đề với những dữ liệu có sẵn thì một máy tính có khả năng cũng sẽ không thể giải quyết dược nó. Thay vì vậy, hãy tập trung ào những vấn đề mà con người có thể làm được nhưng máy tính sẽ giúp chúng ta giải quyết vấn đề đó nhanh hơn rất nhiều.
Cảm ơn bạn đã theo dõi bài viết này. Tôi sẽ cập nhật các phần tiếp theo về sau.
All rights reserved
