YOLOv8-Pose Giải Pháp Cho Bài Toán Phát Hiện ID Card/ Biển Số Xe
1. Giới Thiệu

Trong lĩnh vực Computer Vision, pose estimation (ước tính tư thế) đã trở thành một trong những ứng dụng quan trọng đặc biệt là khi YOLOv8 ra đời với những cải tiến vượt bậc. Hôm nay mình sẽ phân tích Yolov8 -Pose từ đó mình sẽ hướng dẫn các bạn làm sao có thể huấn luyện được mô hình cụ thể là để giải quyết vấn đề mất các góc/ thông tin khi các bạn làm các bài toán như phát hiện biển số, căn cước, bằng lái xe,...

Chính vấn đề ảnh bị chéo góc như kia gây khó khăn cho việc chúng ta OCR và một số phương pháp để giải quyết vấn đề trên mà mình biết thông qua quá trình làm việc và tìm hiểu như:
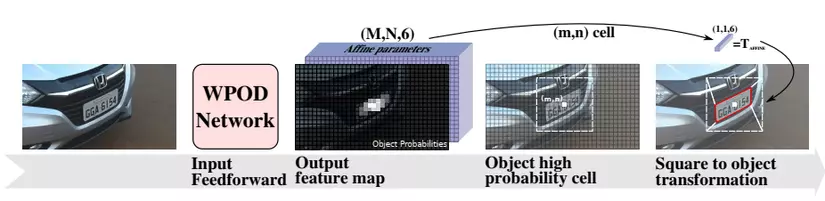
- Sử dụng WPOD để chuẩn hóa hình ảnh về hướng chính diện. Tuy nhiên, một hạn chế đáng chú ý ở phương pháp này là thời gian suy luận (inference time) lớn, dẫn đến việc làm chậm tổng thời gian chạy của toàn bộ pipeline hệ thống.
- Sử dụng việc label 4 góc theo thứ tự top left, top right, bottom right, bottom left cho qua mô hình Object Detection rồi từ đó crop phần ảnh cần xử lý.

Cách này khá hay và mình thấy rất nhiều công ty áp dụng tuy nhiên nó sẽ gặp phải một trường hợp False Positive khá nghiêm trọng đó chính là khi mà các bạn đặt căc cước ở gần các cạnh hay góc như mặt bàn góc vở,... thì mô hình Object Detection nó sẽ detect đấy là một trong 4 góc trên ví dụ như hình bên dưới:

- Còn một cách nữa đó chính là sử dụng Segmentation về bản chất thì Yolo pose với segmentation là khá tương đồng nhưng Segmentaion sẽ Không rõ ràng thứ tự các điểm (vì do postprocess mà ra). Việc biết thứ tự các điểm sẽ giúp ích rất nhiều thay vì không biết thứ tự các điểm.
=> Vậy giải pháp cho các vấn đề trên đó chính là sử dụng các keypoints được định nghĩa trong Yolov8-Pose để phát hiện biển số xe/ căn cước công dân,...
2. Cơ Chế Hoạt Động Của YOLOv8-Pose
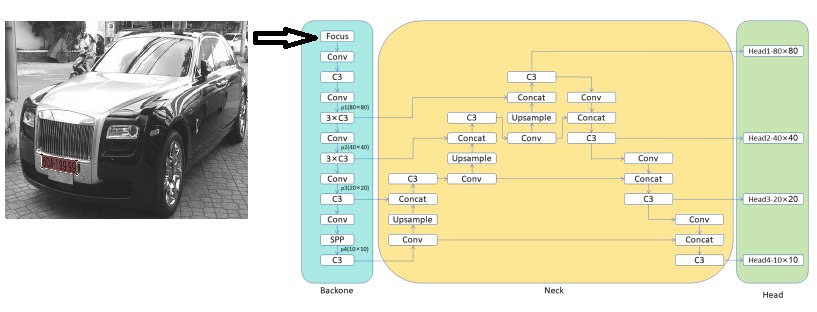
2.1 Kiến trúc mạng Neural
- Backbone: Sử dụng CSPDarknet làm xương sống với các khối Cross Stage Parital (CSP) để trích xuất đặc trưng.
- Neck: Tích hợp Feature Pyramid Network (FPN) để xử lý đối tượng ở nhiều tỷ lệ khác nhau.
- Head: Bao gồm 4 đầu giải mã (decouple head) ở các tỉ lệ khác nhau để đồng thời dự đoán các hộp giới hạn (bounding box) và điểm mốc (keypoint). Mỗi decouple head được thiết kế với 2 nhánh tương ứng:
- Nhánh phát hiện đối tượng (bounding box)
- Nhánh ước tính keypoints
2.2 Quá trình xử lý
2.2.1 Tiền xử lý ảnh
- Chuẩn hoá kích thước ảnh
- Áp dụng data augmentation
- Chuẩn hoá màu sắc và độ sáng
2.2.2 Phát hiện đối tượng
- Xác định bounding box cho mỗi đối tượng trong ảnh
- Tính toán confident score cho mỗi đối tượng được phát hiện
2.2.3 Ước tính keypoints
- Xác định number of keypoints (17 keypoint nếu dụng bộ dữ liệu COCO cho person pose estimation còn trong bài toán mình đang giải quyết sẽ là 4 keypoints)
- Tính toán độ tin cậy cho từng keypoints
- Kết nối các keypoints tạo thành skeleton (khung xương)
2.3 Hàm mất mát
YOLO-Pose sử dụng hai hàm loss chính là CIoU cho hộp giới hạn (bounding box) và OKS loss (Object Keypoint Similarity) cho các keypoint.
- CIoU loss:
- Được sử dụng cho việc giám sát hộp giới hạn
- Là một biến thể nâng cấp của hàm loss IOU, nó bất biến với tỉ lệ và trực tiếp tối ưu hoá chỉ số đánh giá (metrics)
- OKS loss:
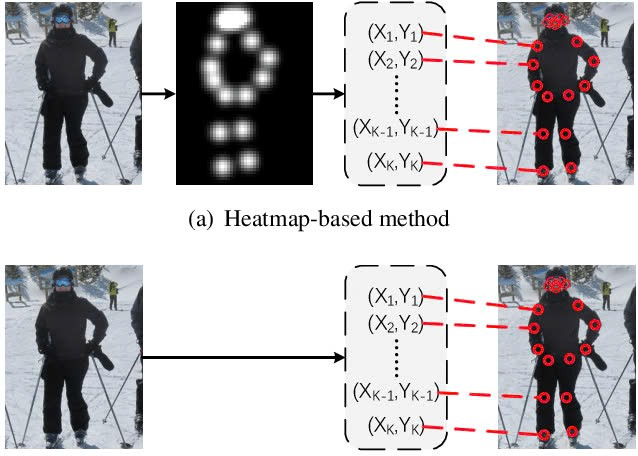
- Đây chính là điểm cải tiến của YOLO-Pose so với các phương pháp pose estimation cũ.
- Vượt trội hơn so với việc sử dụng loss L1, ổn định hơn trong quá trình huấn luyện. Mình sẽ nói chi tiết hơn về OKS loss, thông thường các phương pháp bottom-up dựa trên heatmap sử dụng hàm loss L1 để phát hiện keypoint. Tuy nhiên hàm loss L1 không phù hợp để đạt được OKS tối ưu. Hơn nữa L1 loss không tính đến tỉ lệ đối tượng hoặc loại keypoint. Vì heatmap là bản đồ xác suất nên không thể sử dụng OKS làm hàm loss trong phương pháp dự trên heatmap thuần tuý. OKS chỉ có thể được sử dụng làm hàm mất mát khi ta hồi quy trực tiếp vị trí các keypoint. YOLO-Pose không giống với các phương pháp bottom-up nó sẽ hồi quy trực tiếp các keypoint dựa trên toạ độ tâm của anchor. Điều này cho phép YOLO-Pose sử dụng OKS loss trực tiếp tối ưu hoá chỉ số của các metrics.
Tổng kết lại thì OKS loss mang lại một số lợi ích:
- Bất biến với tỉ lệ: OKS loss tự động điều chỉnh theo tỷ lệ của đối tượng, giúp mô hình hoạt động tốt hơn với các đối tượng có các kích thước khác nhau.
- Ưu tiên các keypoint quan trọng: Ví dụ các điểm chính trên đầu một người (mắt, mũi, tai,..) sẽ bị "phạt nặng" hơn cho cùng một lỗi ở cấp độ pixel so với các điểm khác trên cơ thể như (vai, gối, hông,..)
- Ổn định trong quá trình huấn luyện: OKS loss không bao giờ đạt đến trạng thái ổn định tương tự như dIoU loss giúp cho quá trình huấn luyện ổn định hơn so với L1 loss.
Tại sao OKS loss không ổn định lại tốt ở đây mình chỉ đoán đơn giản là vì lúc này nó sẽ cho phép mô tiếp tục học và cải thiện ngay cả khi dự đoán ban đầu kém. Điều này dẫn đến hiệu suất tổng thể tốt hơn và khả năng hội tụ nhanh hơn.
3. Huấn Luyện Mô Hình YOLOv8-Pose cho 4 keypoint
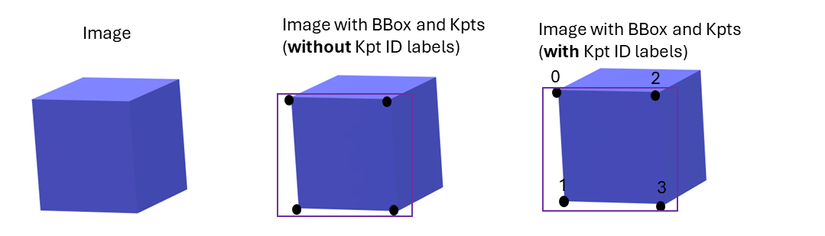
Sau khi các bạn gán dữ liệu như bình thường theo kiểu create polygons ở labelme ( 4 điểm ứng với 4 góc top-left, top-right, bottom-left, bottom-right nhé) ở file config data.yaml các bạn hãy sửa như này cho mình:
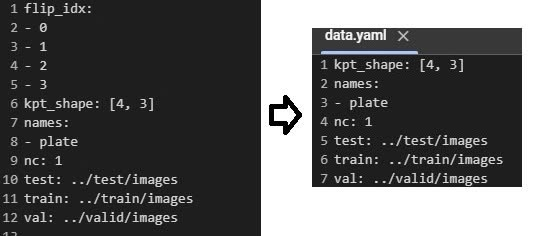
Lý do phải xoá flip_idx đi vì ở bài toán phát hiện biển số xe hoặc căn cước công dân không có tính đối xứng ngoài ra nó còn đảm bảo các keypoint-shape đúng format. Bạn có thể giữ tham số visibility trong kpt_shape[1] = 3 thể hiện có 3 giá trị 0,1,2 trong file txt khi làm dữ liệu thể hiện lần lượt là không nhìn thấy gì, thấy một phần và thấy hoàn toàn, kpt_shape[0] = 4 thì đơn giản vì đây chính là 4 keypoint chúng ta định nghĩa khi gán nhãn.
Một lưu ý nữa là khi huấn luyện sẽ có tham số flipup và flipur trong file arg.yaml chúng ta cũng sẽ thiết lập là 0 do tính không đối xứng của biển số và căn cước công dân, dưới đây là câu lệnh để huấn luyện:
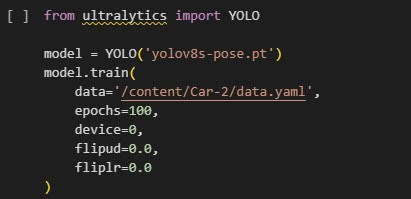
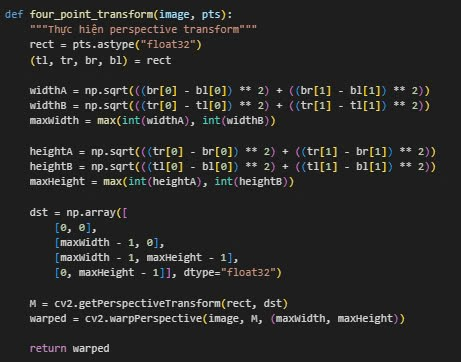
Sau khi huấn luyện xong và nhận về 4 keypoint ta sẽ viết thêm một hàm để thực hiện perspective transform như này:
Cuối cùng đây là kết quả, bởi vì mình train chỉ 50 epoch và sử dụng chỉ khoảng 100 ảnh cho huấn luyện nên các keypoint vẫn chưa nằm ở vị trí các góc của biển số, các bạn khi làm trong dự án thực tế cứ huấn luyện với data nhiều hơn nó sẽ cho kết quả tốt hơn mình nhé bởi vì mình đã làm cho công ty mình bằng phương pháp này nên các bạn cứ yên tâm à có thể thử tương tự với YOLO11-Pose nhé :v


4. Tài Liệu Tham Khảo
All rights reserved
