Xây Dựng Chatbot AI Của Riêng Bạn: Hướng Dẫn Đầy Đủ Để Triển Khai Cục Bộ với ServBay, Python và ChromaDB (Không Cần Phụ Thuộc Bên Thứ Ba!)
Trong thời đại mà quyền riêng tư dữ liệu là tối quan trọng, việc thiết lập mô hình ngôn ngữ cục bộ (LLM) của riêng bạn cung cấp một giải pháp quan trọng cho cả công ty và cá nhân. Hướng dẫn này được thiết kế để hướng dẫn bạn qua quá trình tạo chatbot tùy chỉnh bằng cách sử dụng ServBay, Python 3 và ChromaDB, tất cả đều được lưu trữ cục bộ trên hệ thống của bạn. Chính xác, bạn không cần phải tải xuống bất kỳ phần mềm nào ngoại trừ Servbay.
 Dưới đây là những lý do chính tại sao bạn cần hướng dẫn này:
Dưới đây là những lý do chính tại sao bạn cần hướng dẫn này:
Tùy Chỉnh Hoàn Toàn: Việc lưu trữ ứng dụng Tạo Sinh Mở Rộng Truy Xuất (RAG) của riêng bạn tại cục bộ cho phép bạn toàn quyền kiểm soát cấu hình và cá nhân hóa của nó. Bạn có thể điều chỉnh mô hình để đáp ứng các yêu cầu cụ thể của mình mà không phụ thuộc vào dịch vụ của bên thứ ba.
Cải Thiện Quyền Riêng Tư: Thiết lập mô hình ngôn ngữ (LLM) của bạn tại cơ sở của bạn cho phép bạn bỏ qua những nguy hiểm của việc truyền thông tin nhạy cảm trực tuyến. Điều này đặc biệt quan trọng đối với các tổ chức xử lý dữ liệu riêng tư, vì việc đào tạo mô hình của bạn bằng tài nguyên cục bộ đảm bảo thông tin của bạn vẫn an toàn và được bảo vệ.
Đảm Bảo An Toàn Dữ Liệu: Dựa vào các mô hình LLM bên ngoài có thể khiến dữ liệu của bạn gặp phải các mối đe dọa bảo mật tiềm ẩn. Bằng cách triển khai mô hình của bạn cục bộ, bạn giảm thiểu những rủi ro này, giữ cho các tài liệu đào tạo của bạn, như tệp PDF, được bảo vệ trong môi trường của riêng bạn.
Kiểm Soát Quản Lý Dữ Liệu: Vận hành LLM của riêng bạn cho phép bạn tự do xử lý và thao tác dữ liệu chính xác như bạn mong muốn. Điều này bao gồm việc nhúng thông tin độc quyền của bạn vào kho lưu trữ vectơ ChromaDB, đảm bảo rằng quá trình xử lý dữ liệu của bạn phù hợp với các tiêu chuẩn và tiêu chí cụ thể của bạn.
Độc Lập Với Internet: Chạy chatbot của bạn cục bộ có nghĩa là bạn sẽ không phụ thuộc vào kết nối internet. Điều này đảm bảo dịch vụ nhất quán và quyền truy cập liên tục vào chatbot của bạn, ngay cả trong các tình huống bạn ngoại tuyến.
Hướng dẫn này sẽ giúp bạn xây dựng một chatbot cục bộ mạnh mẽ và an toàn, phù hợp với nhu cầu của bạn, mà không ảnh hưởng đến quyền riêng tư hoặc quyền kiểm soát.
Tạo Sinh Mở Rộng Truy Xuất (RAG)
Tạo Sinh Mở Rộng Truy Xuất (RAG) là một kỹ thuật tiên tiến kết hợp thế mạnh của truy xuất thông tin và tạo văn bản để tạo ra các phản hồi chính xác và phù hợp với ngữ cảnh hơn. Dưới đây là giải thích chi tiết về cách RAG hoạt động và tại sao nó lại có lợi:
RAG là gì?
RAG là một mô hình lai giúp tăng cường khả năng của các mô hình ngôn ngữ bằng cách kết hợp cơ sở tri thức bên ngoài hoặc kho lưu trữ tài liệu. Quá trình này bao gồm hai thành phần chính:
Truy xuất: Trong giai đoạn này, mô hình truy xuất các tài liệu hoặc mẩu thông tin liên quan từ một nguồn bên ngoài, chẳng hạn như cơ sở dữ liệu hoặc kho lưu trữ vectơ, dựa trên truy vấn đầu vào.
Tạo sinh: Thông tin được truy xuất sau đó được sử dụng bởi một mô hình ngôn ngữ tạo sinh để tạo ra một phản hồi mạch lạc và phù hợp với ngữ cảnh.
RAG hoạt động như thế nào?
- Đầu vào truy vấn: Người dùng nhập một truy vấn hoặc câu hỏi.
- Truy xuất tài liệu: Hệ thống sử dụng truy vấn để tìm kiếm cơ sở tri thức bên ngoài, truy xuất các tài liệu hoặc đoạn thông tin liên quan nhất.
- Tạo phản hồi: Mô hình tạo sinh xử lý thông tin được truy xuất, tích hợp nó với kiến thức của riêng mình để tạo ra một phản hồi chi tiết và chính xác.
- Đầu ra: Phản hồi cuối cùng, được làm phong phú với các chi tiết cụ thể và liên quan từ cơ sở tri thức, được trình bày cho người dùng.
Lợi ích của RAG
- Độ chính xác được nâng cao: Bằng cách tận dụng dữ liệu bên ngoài, các mô hình RAG có thể cung cấp câu trả lời chính xác và chi tiết hơn, đặc biệt là đối với các truy vấn cụ thể theo miền.
- Tính liên quan theo ngữ cảnh: Thành phần truy xuất đảm bảo rằng phản hồi được tạo ra dựa trên thông tin liên quan và cập nhật, cải thiện chất lượng tổng thể của phản hồi.
- Khả năng mở rộng: Các hệ thống RAG có thể dễ dàng mở rộng để kết hợp một lượng lớn dữ liệu, cho phép chúng xử lý nhiều loại truy vấn và chủ đề.
- Tính linh hoạt: Các mô hình này có thể được điều chỉnh cho các miền khác nhau bằng cách chỉ cần cập nhật hoặc mở rộng cơ sở tri thức bên ngoài, làm cho chúng có tính linh hoạt cao.
Tại sao nên sử dụng RAG cục bộ?
- Quyền riêng tư và bảo mật: Chạy mô hình RAG cục bộ đảm bảo rằng dữ liệu nhạy cảm vẫn an toàn và riêng tư, vì nó không cần phải được gửi đến các máy chủ bên ngoài.
- Tùy chỉnh: Bạn có thể điều chỉnh các quy trình truy xuất và tạo sinh cho phù hợp với nhu cầu cụ thể của mình, bao gồm tích hợp các nguồn dữ liệu độc quyền.
- Độc lập: Thiết lập cục bộ đảm bảo rằng hệ thống của bạn vẫn hoạt động ngay cả khi không có kết nối internet, cung cấp dịch vụ nhất quán và đáng tin cậy.
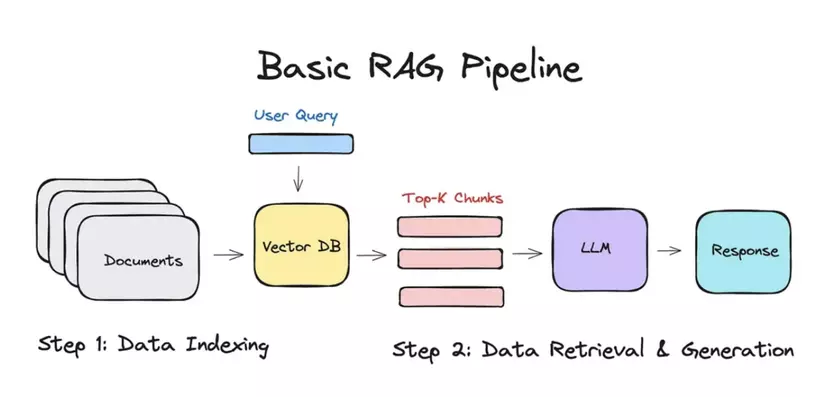
Bằng cách thiết lập ứng dụng RAG cục bộ với các công cụ như Ollama, Python và ChromaDB, bạn có thể tận hưởng những lợi ích của các mô hình ngôn ngữ tiên tiến trong khi vẫn duy trì quyền kiểm soát dữ liệu và các tùy chọn tùy chỉnh của mình.
ServBay
ServBay là một môi trường phát triển web cục bộ tích hợp, đồ họa và cài đặt chỉ bằng một cú nhấp chuột, được thiết kế đặc biệt cho các nhà phát triển web, nhà phát triển Python, nhà phát triển AI và nhà phát triển PHP. Phần mềm này đặc biệt phù hợp với macOS. Nó bao gồm một loạt các dịch vụ và công cụ phát triển web thường được sử dụng, bao gồm máy chủ web, cơ sở dữ liệu, ngôn ngữ lập trình, máy chủ thư, dịch vụ hàng đợi, v.v. ServBay nhằm mục đích cung cấp cho các nhà phát triển một môi trường phát triển tiện lợi, hiệu quả và thống nhất.
Các tính năng chính của ServBay
- Hỗ trợ nhiều phiên bản Python: Chạy đồng thời nhiều phiên bản Python để đáp ứng nhu cầu của các dự án khác nhau.
- Tên miền tùy chỉnh và hỗ trợ SSL: Dễ dàng định cấu hình tên miền cục bộ và chứng chỉ SSL để mô phỏng môi trường sản xuất thực.
- Hoạt động nhanh: Hỗ trợ khởi động khi khởi động, truy cập nhanh thông qua thanh menu và quản lý dòng lệnh để nâng cao hiệu quả phát triển.
- Quản lý dịch vụ thống nhất: Tích hợp Python, PHP, Node.js và Ollama, giúp dễ dàng quản lý nhiều dịch vụ phát triển.
- Môi trường hệ thống sạch: Tránh ô nhiễm hệ thống bằng cách chạy tất cả các dịch vụ trong môi trường biệt lập.
- Xâm nhập và chia sẻ mạng nội bộ: Hỗ trợ xâm nhập mạng nội bộ cho các trang web cục bộ, giúp dễ dàng chia sẻ kết quả phát triển với các thành viên trong nhóm.
Hướng dẫn cài đặt ServBay
- Yêu cầu: macOS 12.0 Monterey trở lên
- Tải xuống phiên bản ServBay mới nhất
Cài đặt:
- Nhấp đúp vào tệp .dmg đã tải xuống để mở nó.
- Trong cửa sổ mở ra, kéo biểu tượng ServBay.app vào thư mục Applications.

- Khi sử dụng ServBay lần đầu tiên, cần phải khởi tạo. Nói chung, bạn có thể chọn cài đặt mặc định hoặc tùy chọn chọn Ollama để hỗ trợ lập trình AI.

- Sau khi cài đặt xong, hãy mở ServBay.

- Nhập mật khẩu của bạn. Sau khi cài đặt xong, bạn có thể tìm thấy ServBay trong thư mục Applications.
- Truy cập giao diện chính.
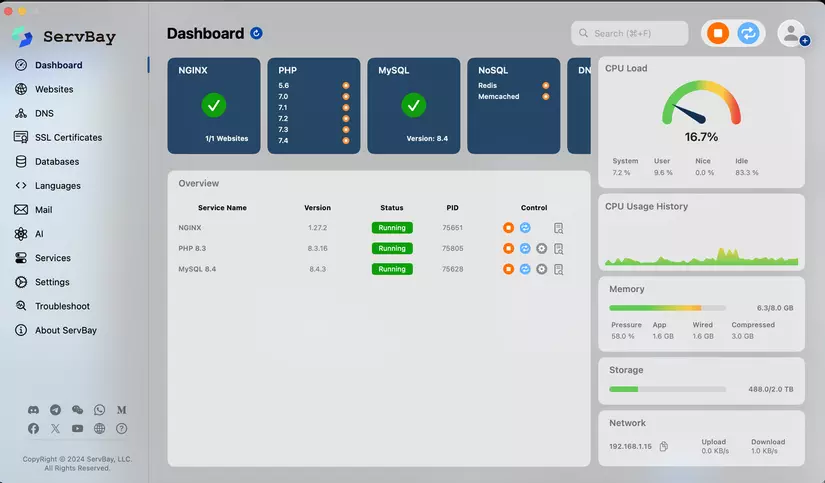
Ngoài Python, ServBay còn cung cấp hỗ trợ mạnh mẽ cho PHP và Node.js, bao gồm một loạt các phiên bản từ PHP 5.6 đến PHP 8.5 và Node.js 12 đến Node.js 23.
Một trong những tính năng chính của ServBay là khả năng chuyển đổi nhanh chóng giữa các phiên bản phần mềm khác nhau. Tính linh hoạt này rất cần thiết cho các nhà phát triển cần kiểm tra và triển khai ứng dụng trong các môi trường khác nhau.
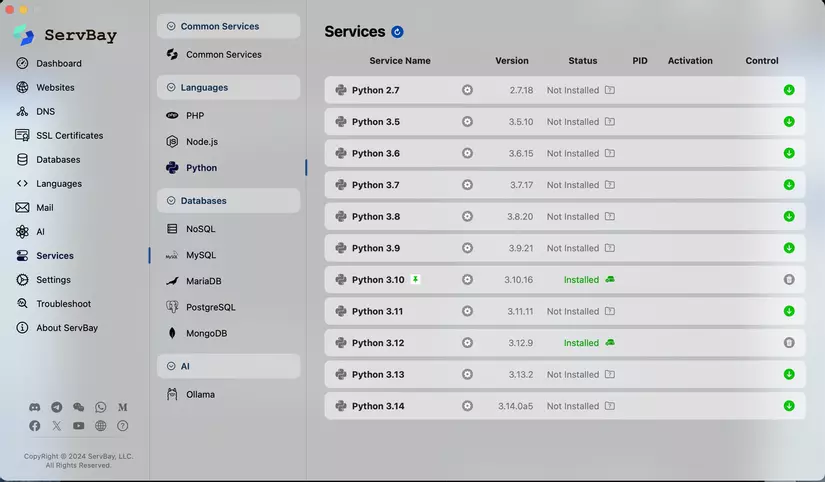
- Cài đặt tất cả các phiên bản Python bằng một cú nhấp chuột.
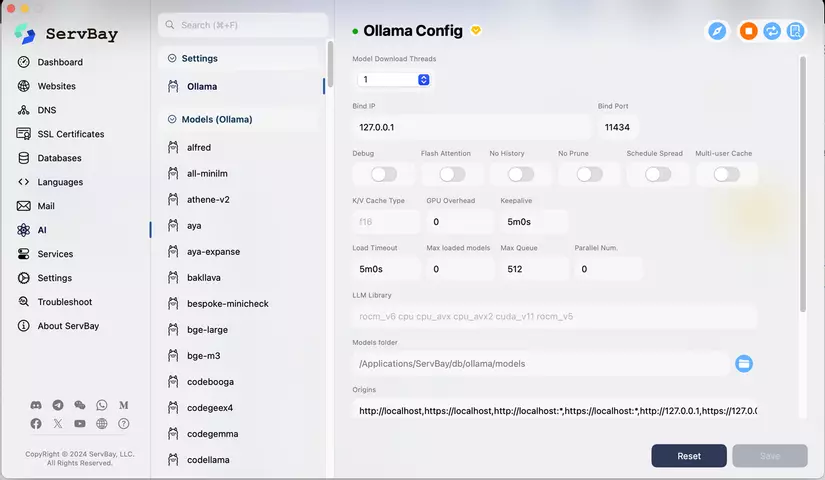
- Cài đặt tất cả các model Ollama bằng một cú nhấp chuột
Điều kiện tiên quyết
Trước khi đi sâu vào thiết lập, hãy đảm bảo bạn có sẵn các điều kiện tiên quyết sau:
- Python 3: Python là một ngôn ngữ lập trình linh hoạt mà bạn sẽ sử dụng để viết mã cho ứng dụng RAG của mình.
- ChromaDB: Một cơ sở dữ liệu vectơ sẽ lưu trữ và quản lý các nhúng dữ liệu của chúng ta.
- Servbay: Để tải xuống và phục vụ các LLM tùy chỉnh trong máy cục bộ của chúng ta.
Bước 1: Cài đặt Python 3 và thiết lập môi trường của bạn
Để cài đặt và thiết lập môi trường Python 3 của chúng ta, hãy làm theo các bước sau: Nhấp vào nút Python của Servbay, sau đó chọn một phiên bản Python. Sau đó, đảm bảo Python 3 của bạn được cài đặt và chạy thành công:
$ python3 --version # Python 3.12.9
Tạo một thư mục cho dự án của bạn. Ví dụ: local-rag:
$ mkdir local-rag
$ cd local-rag
Tạo một môi trường ảo có tên venv:
$ python3 -m venv venv
Kích hoạt môi trường ảo:
$ source venv/bin/activate
# Windows
# venv\Scripts\activate
Bước 2: Cài đặt ChromaDB và các phụ thuộc khác
Cài đặt ChromaDB bằng pip:
$ pip install --q chromadb
Cài đặt các công cụ Langchain để làm việc liền mạch với mô hình của bạn:
$ pip install --q unstructured langchain langchain-text-splitters
$ pip install --q "unstructured[all-docs]"
Cài đặt Flask để cung cấp ứng dụng của bạn dưới dạng dịch vụ HTTP:
$ pip install --q flask
Bước 3: Cài đặt Ollama
Để cài đặt Ollama, hãy làm theo các bước sau. Nhấp vào nút AI của Servbay, sau đó chọn một mô hình mà bạn thích.
Xây dựng ứng dụng RAG
Bây giờ bạn đã thiết lập môi trường của mình với Python, Ollama, ChromaDB và các phụ thuộc khác, đã đến lúc xây dựng ứng dụng RAG cục bộ tùy chỉnh của bạn. Trong phần này, chúng ta sẽ đi qua mã Python thực hành và cung cấp tổng quan về cách cấu trúc ứng dụng của bạn.
app.py
Đây là tệp ứng dụng Flask chính. Nó xác định các tuyến đường để nhúng tệp vào cơ sở dữ liệu vectơ và truy xuất phản hồi từ mô hình.
import os
from dotenv import load_dotenv
from flask import Flask, request, jsonify
from embed import embed
from query import query
from get_vector_db import get_vector_db
# Thiết lập thư mục tạm
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
os.makedirs(TEMP_FOLDER, exist_ok=True)
app = Flask(__name__)
@app.route('/embed', methods=['POST'])
def route_embed():
if 'file' not in request.files:
return jsonify({"error": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"error": "No selected file"}), 400
embedded = embed(file)
if embedded:
return jsonify({"message": "File embedded successfully"}), 200
return jsonify({"error": "File embedded unsuccessfully"}), 400
@app.route('/query', methods=['POST'])
def route_query():
data = request.get_json()
response = query(data.get('query'))
if response:
return jsonify({"message": response}), 200
return jsonify({"error": "Something went wrong"}), 400
if __name__ == '__main__':
app.run(host="0.0.0.0", port=8080, debug=True)
embed.py
Mô-đun này xử lý quá trình nhúng, bao gồm lưu các tệp đã tải lên, tải và chia dữ liệu, và thêm tài liệu vào cơ sở dữ liệu vectơ.
import os
from datetime import datetime
from werkzeug.utils import secure_filename
from langchain_community.document_loaders import UnstructuredPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from get_vector_db import get_vector_db
TEMP_FOLDER = os.getenv('TEMP_FOLDER', './_temp')
# Hàm kiểm tra xem tệp đã tải lên có được phép không (chỉ các tệp PDF)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in {'pdf'}
# Hàm lưu tệp đã tải lên vào thư mục tạm thời
def save_file(file):
# Lưu tệp đã tải lên với tên tệp an toàn và trả về đường dẫn tệp
timestamp = datetime.now().timestamp()
filename = f"{timestamp}_{secure_filename(file.filename)}"
file_path = os.path.join(TEMP_FOLDER, filename)
file.save(file_path)
return file_path
# Hàm tải và chia dữ liệu từ tệp PDF
def load_and_split_data(file_path):
# Tải tệp PDF và chia dữ liệu thành các đoạn
loader = UnstructuredPDFLoader(file_path=file_path)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=7500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
return chunks
# Hàm chính để xử lý quá trình nhúng
def embed(file):
# Kiểm tra xem tệp có hợp lệ không, lưu nó, tải và chia dữ liệu, thêm vào cơ sở dữ liệu và xóa tệp tạm thời
if file.filename != '' and file and allowed_file(file.filename):
file_path = save_file(file)
chunks = load_and_split_data(file_path)
db = get_vector_db()
db.add_documents(chunks)
db.persist()
os.remove(file_path)
return True
return False
query.py
Mô-đun này xử lý các truy vấn của người dùng bằng cách tạo nhiều phiên bản của truy vấn, truy xuất các tài liệu liên quan và cung cấp câu trả lời dựa trên ngữ cảnh.
import os
from langchain_community.chat_models import ChatOllama
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain.retrievers.multi_query import MultiQueryRetriever
from get_vector_db import get_vector_db
LLM_MODEL = os.getenv('LLM_MODEL', 'deepseek-r1:1.5b') # Hoặc model bạn chọn
# Hàm để lấy các mẫu nhắc để tạo các câu hỏi thay thế và trả lời dựa trên ngữ cảnh
def get_prompt():
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""Bạn là một trợ lý mô hình ngôn ngữ AI. Nhiệm vụ của bạn là tạo ra năm
phiên bản khác nhau của câu hỏi người dùng đã cho để truy xuất các tài liệu liên quan từ
một cơ sở dữ liệu vectơ. Bằng cách tạo ra nhiều góc nhìn về câu hỏi của người dùng,
mục tiêu của bạn là giúp người dùng vượt qua một số hạn chế của tìm kiếm tương đồng dựa trên khoảng cách.
Cung cấp các câu hỏi thay thế này được phân tách bằng dòng mới.
Câu hỏi gốc: {question}"""
)
template = """Trả lời câu hỏi CHỈ dựa trên ngữ cảnh sau:
{context}
Câu hỏi: {question}"""
prompt = ChatPromptTemplate.from_template(template)
return QUERY_PROMPT, prompt
# Hàm chính để xử lý quá trình truy vấn
def query(input):
if input:
# Khởi tạo mô hình ngôn ngữ với tên mô hình được chỉ định
llm = ChatOllama(model=LLM_MODEL)
# Lấy phiên bản cơ sở dữ liệu vectơ
db = get_vector_db()
# Lấy các mẫu nhắc
QUERY_PROMPT, prompt = get_prompt()
# Thiết lập trình truy xuất để tạo nhiều truy vấn bằng mô hình ngôn ngữ và dấu nhắc truy vấn
retriever = MultiQueryRetriever.from_llm(db.as_retriever(), llm, prompt=QUERY_PROMPT)
# Xác định chuỗi xử lý để truy xuất ngữ cảnh, tạo câu trả lời và phân tích cú pháp đầu ra
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
response = chain.invoke(input)
return response
return None
get_vector_db.py
Mô-đun này khởi tạo và trả về phiên bản cơ sở dữ liệu vectơ được sử dụng để lưu trữ và truy xuất các phần nhúng tài liệu.
import os
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.chroma import Chroma
CHROMA_PATH = os.getenv('CHROMA_PATH', 'chroma')
COLLECTION_NAME = os.getenv('COLLECTION_NAME', 'local-rag')
TEXT_EMBEDDING_MODEL = os.getenv('TEXT_EMBEDDING_MODEL', 'nomic-embed-text') # Hoặc model bạn chọn
def get_vector_db():
# Tạo một phiên bản của mô hình nhúng
embedding = OllamaEmbeddings(model=TEXT_EMBEDDING_MODEL, show_progress=True)
# Khởi tạo kho lưu trữ vectơ Chroma với các tham số được chỉ định
db = Chroma(
collection_name=COLLECTION_NAME,
persist_directory=CHROMA_PATH,
embedding_function=embedding
)
return db
Chạy ứng dụng của bạn!
Tạo tệp .env để lưu trữ các biến môi trường của bạn:
TEMP_FOLDER = './_temp'
CHROMA_PATH = 'chroma'
COLLECTION_NAME = 'local-rag'
LLM_MODEL = 'mistral' # Hoặc model bạn chọn
TEXT_EMBEDDING_MODEL = 'nomic-embed-text' # Hoặc model bạn chọn
Chạy tệp app.py để khởi động máy chủ ứng dụng của bạn:
$ python3 app.py
Khi máy chủ đang chạy, bạn có thể bắt đầu thực hiện các yêu cầu đến các điểm cuối sau:
Lệnh ví dụ để nhúng tệp PDF (ví dụ: resume.pdf):
#!/bin/bash
curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/Users/ban/Documents/works/tai_lieu.pdf # Thay bằng đường dẫn tệp của bạn
Phản hồi:
{
"message": "File embedded successfully"
}
Lệnh ví dụ để đặt câu hỏi cho mô hình của bạn:
$ curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "Nasser là ai?" }'
# Phản hồi (Ví dụ)
{
"message": "Nasser Maronie là một nhà phát triển Full Stack có kinh nghiệm trong phát triển ứng dụng web và di động. Anh ấy đã làm việc với tư cách là Kỹ sư Full Stack chính tại Ulventech, Kỹ sư Full Stack cấp cao tại Speedoc, Kỹ sư Frontend cấp cao tại Irvins và Kỹ sư phần mềm tại Tokopedia. Các ngăn xếp công nghệ của anh ấy bao gồm Typescript, ReactJS, VueJS, React Native, NodeJS, PHP, Golang, Python, MySQL, PostgresQL, MongoDB, Redis, AWS, Firebase và Supabase. Anh ấy có bằng Cử nhân về Hệ thống Thông tin của Đại học Amikom Yogyakarta."
}
Kết luận
Bằng cách làm theo các hướng dẫn này, bạn có thể chạy và tương tác hiệu quả với ứng dụng RAG cục bộ tùy chỉnh của mình bằng Python, Ollama và ChromaDB, phù hợp với nhu cầu của bạn. Điều chỉnh và mở rộng chức năng khi cần thiết để nâng cao khả năng của ứng dụng của bạn.
Bằng cách khai thác khả năng triển khai cục bộ, bạn không chỉ bảo vệ thông tin nhạy cảm mà còn tối ưu hóa hiệu suất và khả năng phản hồi. Cho dù bạn đang cải thiện tương tác của khách hàng hay hợp lý hóa các quy trình nội bộ, một ứng dụng RAG được triển khai cục bộ cung cấp sự linh hoạt và mạnh mẽ để thích ứng và phát triển theo yêu cầu của bạn.
All rights reserved
