
[Write up] HTB Cyber Apocalypse 2023: Perfect Synchronization
Bài đăng này đã không được cập nhật trong 3 năm

Đề bài:
The final stage of your initialization sequence is mastering cutting-edge technology tools that can be life-changing. One of these tools is quipqiup, an automated tool for frequency analysis and breaking substitution ciphers. This is the ultimate challenge, simulating the use of AES encryption to protect a message. Can you break it?
File: https://drive.google.com/file/d/1CatzLbbv7syIxmybAO8zxUqdiqvr3IFI/view?usp=sharing
1. Phân tích mã nguồn
Đầu tiên chúng ta sẽ phân tích mã nguồn được cung cấp trong đề bài để xem chương trình mã hoá hoạt động như nào.
Dữ kiện đầu tiên chúng ta có được nằm ở dòng số 5. Ở dòng này sử dụng từ khoá assert của python để kiểm tra toàn bộ ký tự trong Flag. Nếu toàn bộ các ký tự thoả mãn một trong hai điều kiện sau thì chương trình có thể tiếp tục chạy:
- Điều kiện 1: ký tự là chữ in hoa trong bảng chữ cái từ A đến Z.
- Điều kiện 2: ký tự thuộc một trong số 4 ký tự: mở/đóng ngoặc nhọn, gạch dưới hoặc dấu cách.
assert all([x.isupper() or x in '{_} ' for x in MESSAGE])
Tiếp đến là phần chính của mã nguồn - class Cipher.
Trong hàm tạo __init__ của class đã thể hiện 3 tham số quan trọng nhất của phần mã hoá:
- Thuật toán mã hoá: AES mode ECB.
- Khoá mã hoá: sinh ngẫu nhiên chuỗi 16 ký tự.
- Salt: sinh ngẫu nhiên chuỗi 15 ký tự.
Trong hàm encrypt thể hiện phương thức mã hoá thông điệp gốc.
def encrypt(self, message):
return [self.cipher.encrypt(c.encode() + self.salt) for c in message]
Mỗi ký tự trong bản rõ sẽ được nối với chuỗi salt để tạo thành chuỗi 16 ký tự (vừa đủ cho 1 khối). Sau đó chuỗi này sẽ được tiến hành mã hoá bằng thuật toán AES theo chế độ ECB.
Sau khi mã hoá hoàn thành thì đầu ra sẽ được ghi lại vào tệp tin output.txt, mỗi ký tự sau khi qua mã hoá sẽ được in trên 1 dòng. Hiện trong tệp tin này có 1497 dòng, tức là đoạn văn bản gốc có 1497 ký tự.
2. Phân tích hướng tấn công
Ý tưởng 1: tấn công vào cơ chế mã hoá của chế độ ECB
Ý tưởng đầu tiên mình nghĩ ra khi nhìn thấy chế độ ECB là tấn công vào cơ chế hoạt động của chế độ này. Vì so với các chế độ mã khoá khác, thì chế độ ECB yếu hơn hẳn và có nhiều phương pháp tấn công vào hơn. Nhưng đây là một ý tưởng sai lầm.
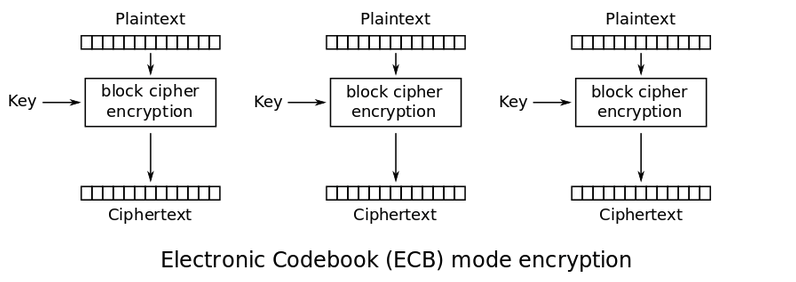
Bởi mặc dù chế độ ECB yếu hơn các chế độ khác về tính bảo mật, nhưng khi chỉ mã khoá duy nhất 1 khối = 16 byte thì không có sự khác biệt lớn giữa các chế độ mã hoá khối. Chúng chỉ khác nhau ở chỗ ECB không sử dụng IV để tránh trùng lặp khi thực hiện mã hoá một thông điệp; và ECB cũng chỉ đưa bản rõ vào hàm mã hoá, còn các chế độ khác có thể thực hiện phép xor giữa IV với bản rõ trước khi đưa vào hàm mã hoá, hoặc mã hoá IV rồi đem kết quả xor với bản rõ.
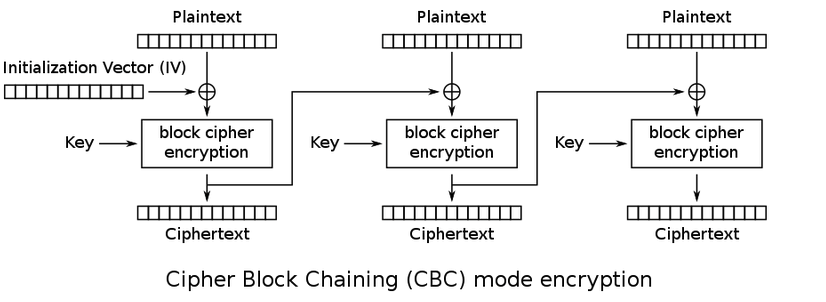
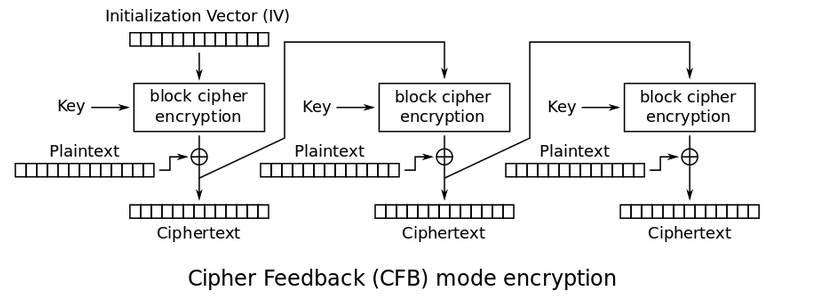
Ý tưởng 2: tấn công vào việc chỉ mã hoá một khối
Ý tưởng thứ hai mình nghĩ ra là lợi dụng điểm yếu của việc chỉ mã khoá một khối. Như đã phân tích ở phần 1, mỗi lần chạy hàm mã hoá AES chỉ mã hoá một xâu 16 byte <=> 16 ký tự. Điểm khiến mã khối an toàn hơn mã hoá dòng là do cơ chế hoạt động khiến cho kết quả mã hoá của khối sau phụ thuộc vào kết quả mã hoá của khối trước đó. Việc này khiến cho tổng thể bản mã hoá khó phá giải hơn, bắt buộc phải phá giải được toàn bộ bản mã hoá chứ không thể chỉ nhắm vào một phần trong bản mã hoá được.
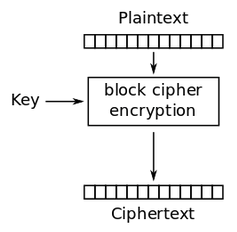
Trong 16 ký tự này thì chỉ có ký tự đầu tiên thay đổi, chính là một ký tự trong bản rõ; còn 15 ký tự sau đó là cố định, do salt chỉ sinh ngẫu nhiên 1 lần duy nhất. Suy ra trong số 1497 dòng kết quả mã hoá, chỉ có tổng cộng 30 đoạn mã hex khác nhau.
Nhưng việc sở hữu số lượng lớn bản mã và chỉ 1 ký tự đầu tiên của bản rõ, không biết salt, không biết key, thì việc brute force ra là không thể.
Ý tưởng 3: so sánh tần suất xuất hiện (phá mã hoá thay thế)
Trong đề bài cũng đã đề cập đến cụm từ tần suất - frequency, và công cụ quipqiup. Chỉ cần là người mới chơi CTF thì chắc cũng không xa lạ gì với công cụ quipqiup - công cụ dựa vào việc tính toán tần suất xuất hiện của mỗi ký tự và so sánh với từ điển tiếng Anh để giải các đoạn mã thay thế - substitution cipher. Quipqiup sẽ hiệu quả hơn khi phân tích 1 đoạn văn bản dài vì sẽ có đủ dữ kiện cho việc đối chiếu, trong trường hợp được cung cấp 1 vài đoạn đối chiếu thì tốc độ và độ chính xác của công cụ sẽ tăng lên.
Tại sao chúng ta cần đề cập đến quipqiup và mã hoá thay thế ở đây? Vì với số lượng 1497 ký tự thì khá tương đồng với độ dài của 1 đoạn văn, và có thể phương pháp đối chiếu dựa trên tần suất có thể sử dụng được để giải mã. Do quipqiup sẽ phân tích trên từng ký tự, mà sau khi qua mã hoá và hex encode thì mỗi ký tự trong văn bản gốc sẽ biến thành 32 ký tự nên việc sử dụng trực tiếp quipqiup hay các công cụ phân tích tần suất online bị hạn chế nhiều. Chúng ta sẽ cần tự code một chương trình phân tích tần suất. Đây thực ra chỉ là một đề bài lập trình cơ bản của các sinh viên đại học năm nhất.
Các xử lý cơ bản trong tool gồm: đếm số lần xuất hiện của mỗi đoạn mã hoá, thống kê theo tỉ lệ % xuất hiện, in ra trong bảng với thứ tự giảm dần theo số lần xuất hiện. Ngoài ra cũng bổ sung thêm một cột đối chiếu với tỉ lệ xuất hiện của các chữ cái trong bảng chữ cái Latin, thống kê theo từ điển tiếng anh. Về dữ liệu thống kê này thì đã có nhiều nơi đăng tải, mình lấy ở link: https://www3.nd.edu/~busiforc/handouts/cryptography/letterfrequencies.html
Cuối bảng so sánh sẽ bổ sung thêm 4 ký tự đặc biệt có trong Flag. Và đây là đoạn code của một sinh viên đã tốt nghiệp đại học (chẳng có gì hơn sinh viên năm nhất code):
import pandas as pd
a = []
b = []
f = open("/Users/tran.minh.nhat/Downloads/crypto_perfect_synchronization/output.txt", "r")
for line in f:
if line not in a:
a.append(line)
b.append(1)
else:
b[a.index(line)] += 1
sum = 0
for i in b:
sum += i
print(sum)
c = []
for i in b:
c.append(i / sum * 100)
d = ["E", "A", "R", "I", "O", "T", "N", "S", "L", "C", "U", "D", "P", "M", "H", "G", "B", "F", "Y", "W", "K", "V", "X", "Z", "J", "Q", "_", " ", "{", "}"]
df = pd.DataFrame({'Ciphertext' : a, 'Appear' : b, 'Frequency': c})
df = df.sort_values('Appear', ascending=[False])
df['Alphabet'] = d
print(df)
Kết quả như sau:
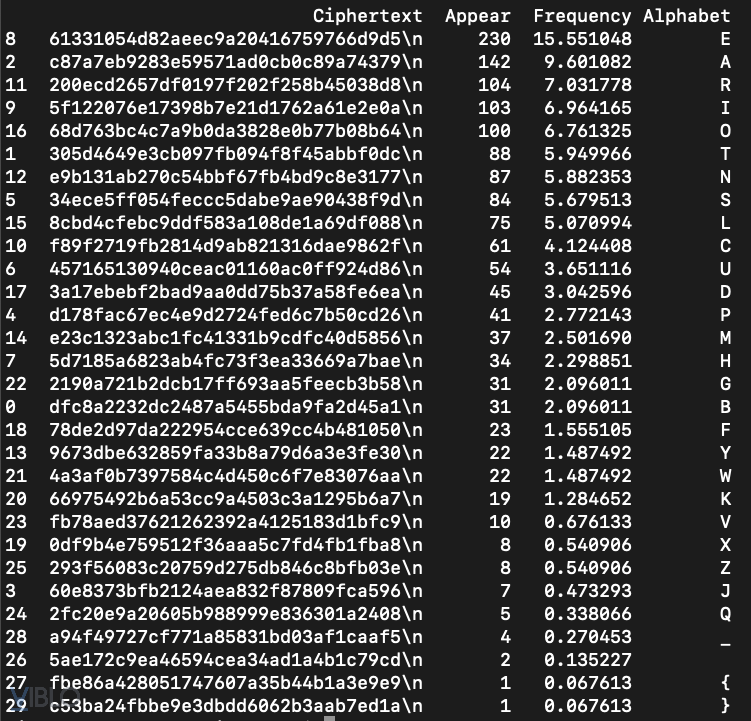
Và với một bộ óc tư duy yếu kém, sau mấy chục phút nhìn vào cái bảng trên thì mình mới nhận ra việc đánh giá này không có nhiều giá trị trong việc phá giải bản mã. Có các lí do như sau:
- Việc đối chiếu tần số chỉ mang tính tương đối. Kể cả các công cụ như quipqiup hẳn cũng phải thực hiện các so sánh với từ điển, số lượng ký tự trong một từ, so sánh ngữ nghĩa,... mới có thể cho ra các kết quả với độ chính xác cao.
- Dữ liệu này không "lí tưởng". Quipqiup có thể tính toán ra được vì nó biết cụ thể mỗi từ cấu thành từ bao nhiêu chữ cái, và nó cũng không cần so sánh các ký tự đặc biệt. Ở trường hợp này chúng ta còn có các phím cách (space). Vì phím cách cũng có mã ascii, cũng chuyển sang kiểu byte được, nên tất nhiên nó cũng được mã hoá. Có thể thấy rằng với số lượng từ lớn như này, không có cách nào để chúng ta biết được phím cách xuất hiện bao nhiêu lần.
Với hai lý do cơ bản trên, chúng ta không biết có bao nhiêu từ trong đoạn văn bản gốc, không biết mỗi từ có thể gồm bao nhiêu ký tự. Do đó việc tạo ra một công cụ như quipqiup, hay sử dụng nguyên lý phá mã thay thế để phá giải đoạn văn bản mã hoá này là không khả thi.
Ý tưởng 4: phán đoán dựa trên dữ kiện từ đề bài
Khi quanh quẩn trong đường cụt thì nên xoá bỏ hết tất cả và suy tính lại kỹ càng từ đầu. Sau khi bỏ đi các phương hướng cụt bên trên, mình đã ngẫm lại kỹ từng dữ kiện trong đề bài và tìm ra được phương hướng giải quyết.
Đầu tiên, cần nhận định rõ ràng rằng thuật toán mã hoá khối AES chế độ ECB được sử dụng ở đây nhằm bảo vệ nội dung bản rõ. Thuật toán không hề can thiệp vào trình tự xuất hiện của mỗi ký tự. Nếu bản rõ là ABC thì sau khi mã hoá, 3 đoạn mã hex phải tương ứng với thứ tự xuất hiện ban đầu, khi giải mã ngược lại phải ra được đúng thứ tự ABC.
=> Thứ tự các ký tự không bị thay đổi. Ở đây không liên quan gì đến mã hoá thay thế.
Thứ hai, mặc dù mã hoá thay thế không liên quan gì ở đây, nhưng tần suất xuất hiện chắc chắn mang tính mấu chốt để giải mã. Đoạn Flag chắc chắc được giấu trong một đoạn văn bản hoàn thiện, và chắc hẳn không đoạn văn bản hoàn thiện nào lại cần sự xuất hiện nhiều của 3 ký tự đặc biệt: { } _, đây là 3 ký tự đặc biệt sẽ xuất hiện trong Flag.
=> Tần suất xuất hiện của chúng sẽ là điểm mấu chốt để xác định vị trí của Flag trong bản mã hoá.
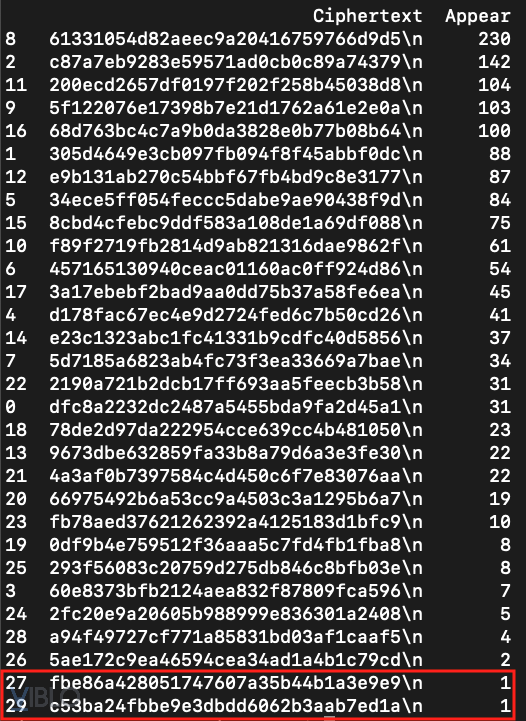
Với 2 nhận định trên, mình nhìn lại bảng kết quả từ tool tự code. Thấy rằng có 2 đoạn mã hex chỉ xuất hiện duy nhất 1 lần. Chắc chắn chúng là 2 ký tự đóng/mở ngoặc nhọn. Trong đó:
fbe86a428051747607a35b44b1a3e9e9có thứ tự 27 => tương ứng với ký tự{c53ba24fbbe9e3dbdd6062b3aab7ed1acó thứ tự 29 => tương ứng với ký tự}
Trong tệp tin output.txt thì ký tự mở ngoặc nhọn nằm ở dòng 1099, còn ký tự đóng ngoặc nhọn nằm ở dòng 1129. Giữa các dòng này chính là nội dung của Flag. Chúng ta sẽ copy toàn bộ từ dòng 1099 đến dòng 1129 sang một tệp tin khác để tiện phân tích, và cũng copy luôn cả 3 dòng phía trên dòng 1099 nữa, vì mình biết đây là 3 chữ cái HTB theo cấu trúc Flag.
Đoạn văn bản mới để phân tích riêng sẽ trông như sau:
3a17ebebf2bad9aa0dd75b37a58fe6ea H
68d763bc4c7a9b0da3828e0b77b08b64 T
9673dbe632859fa33b8a79d6a3e3fe30 B
fbe86a428051747607a35b44b1a3e9e9 {
5f122076e17398b7e21d1762a61e2e0a
a94f49727cf771a85831bd03af1caaf5
200ecd2657df0197f202f258b45038d8
e9b131ab270c54bbf67fb4bd9c8e3177
4a3af0b7397584c4d450c6f7e83076aa
2190a721b2dcb17ff693aa5feecb3b58
f89f2719fb2814d9ab821316dae9862f
c87a7eb9283e59571ad0cb0c89a74379
a94f49727cf771a85831bd03af1caaf5
200ecd2657df0197f202f258b45038d8
d178fac67ec4e9d2724fed6c7b50cd26
9673dbe632859fa33b8a79d6a3e3fe30 B
200ecd2657df0197f202f258b45038d8
68d763bc4c7a9b0da3828e0b77b08b64 T
e9b131ab270c54bbf67fb4bd9c8e3177
68d763bc4c7a9b0da3828e0b77b08b64 T
d178fac67ec4e9d2724fed6c7b50cd26
68d763bc4c7a9b0da3828e0b77b08b64 T
e9b131ab270c54bbf67fb4bd9c8e3177
8cbd4cfebc9ddf583a108de1a69df088
34ece5ff054feccc5dabe9ae90438f9d
a94f49727cf771a85831bd03af1caaf5
e9b131ab270c54bbf67fb4bd9c8e3177
200ecd2657df0197f202f258b45038d8
a94f49727cf771a85831bd03af1caaf5
66975492b6a53cc9a4503c3a1295b6a7
c87a7eb9283e59571ad0cb0c89a74379
5f122076e17398b7e21d1762a61e2e0a
fb78aed37621262392a4125183d1bfc9
c53ba24fbbe9e3dbdd6062b3aab7ed1a }
Dựa vào 5 ký tự đã biết thì chúng ta cũng dễ dàng tìm ra vị trí của 3 ký tự 'T' trong nội dung của Flag. Mục tiêu tiếp theo là cần xác định vị trí của các ký tự gạch dưới. Tương tự với phương pháp suy luận trước đó: một đoạn văn bản bình thường thì sẽ không xuất hiện nhiều ký tự gạch dưới, vì nó vô nghĩa trong các ngữ cảnh.
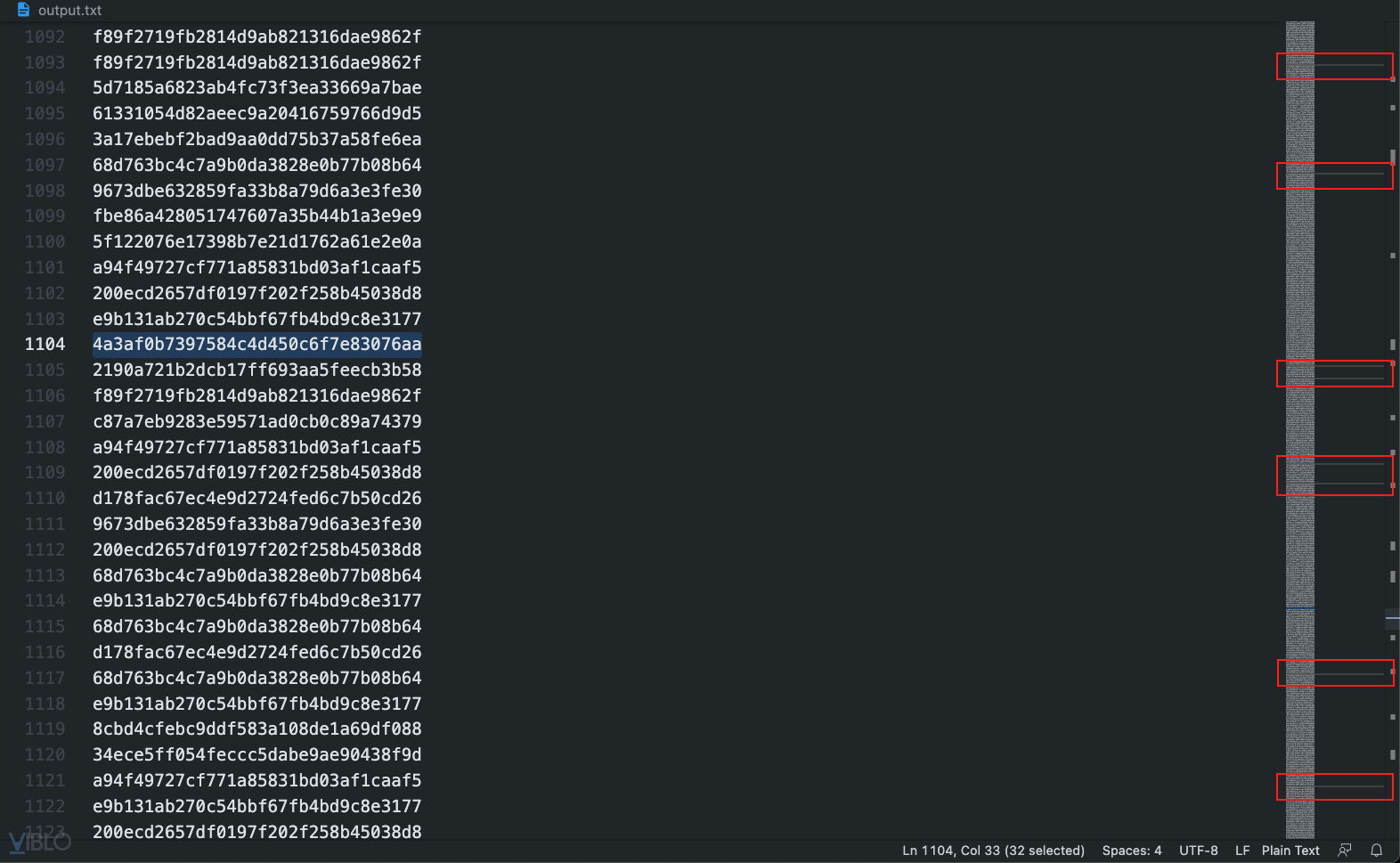
Nhờ có công cụ Visual Studio Code, chỉ cần click đúp vào một đoạn mã hex thì các đoạn giống như thế cũng sẽ được làm nổi lên, và hiển thị vị trí ở thanh điều hướng bên phải nữa. Nhờ thế chỉ cần click đúp lần lượt vào các đoạn mã hex nằm trong khoảng giữa 2 dấu đóng/mở ngoặc nhọn và theo dõi các đoạn được làm nổi ở thanh trượt bên phải. Nếu có đoạn hex nào chỉ xuất hiện nhiều lần trong khoảng giữa 2 dấu ngoặc nhọn thì đó là ký tự gạch dưới.
Xuất hiện rải rác trên toàn tệp tin như này thì chắc chắn không phải ký tự gạch dưới:
Còn chỉ xuất hiện ít trong đúng khu vực giữa 2 ký tự đóng/mở ngoặc nhọn như này thì chắc chắn là dấu gạch dưới:
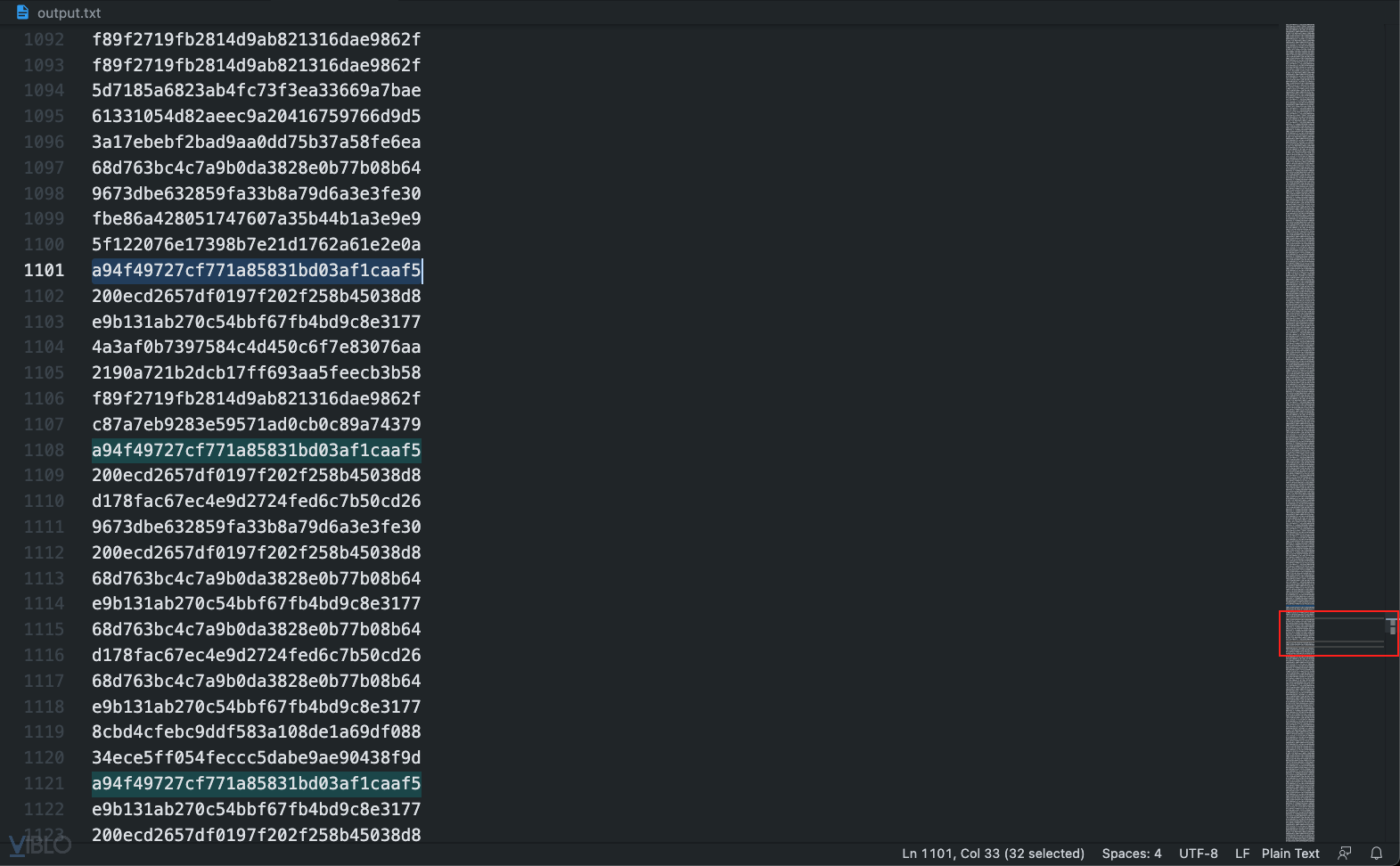
Chúng ta sẽ cập nhật thêm cho đoạn giải mã như sau:
3a17ebebf2bad9aa0dd75b37a58fe6ea H
68d763bc4c7a9b0da3828e0b77b08b64 T
9673dbe632859fa33b8a79d6a3e3fe30 B
fbe86a428051747607a35b44b1a3e9e9 {
5f122076e17398b7e21d1762a61e2e0a
a94f49727cf771a85831bd03af1caaf5 _
200ecd2657df0197f202f258b45038d8
e9b131ab270c54bbf67fb4bd9c8e3177
4a3af0b7397584c4d450c6f7e83076aa
2190a721b2dcb17ff693aa5feecb3b58
f89f2719fb2814d9ab821316dae9862f
c87a7eb9283e59571ad0cb0c89a74379
a94f49727cf771a85831bd03af1caaf5 _
200ecd2657df0197f202f258b45038d8
d178fac67ec4e9d2724fed6c7b50cd26
9673dbe632859fa33b8a79d6a3e3fe30 B
200ecd2657df0197f202f258b45038d8
68d763bc4c7a9b0da3828e0b77b08b64 T
e9b131ab270c54bbf67fb4bd9c8e3177
68d763bc4c7a9b0da3828e0b77b08b64 T
d178fac67ec4e9d2724fed6c7b50cd26
68d763bc4c7a9b0da3828e0b77b08b64 T
e9b131ab270c54bbf67fb4bd9c8e3177
8cbd4cfebc9ddf583a108de1a69df088
34ece5ff054feccc5dabe9ae90438f9d
a94f49727cf771a85831bd03af1caaf5 _
e9b131ab270c54bbf67fb4bd9c8e3177
200ecd2657df0197f202f258b45038d8
a94f49727cf771a85831bd03af1caaf5 _
66975492b6a53cc9a4503c3a1295b6a7
c87a7eb9283e59571ad0cb0c89a74379
5f122076e17398b7e21d1762a61e2e0a
fb78aed37621262392a4125183d1bfc9
c53ba24fbbe9e3dbdd6062b3aab7ed1a }
OK, logic đến đấy là ngưng. Từ giờ trở đi sẽ là đoán mò kết hợp sử dụng tool. Đoạn Flag hiện giờ còn như sau, các ký tự '?' là chưa biết: HTB{?_??????_??B?T?T?T???_??_????}.
Phần lẻ loi trơ rọi một ký tự ở đầu như kia chắc chắn là ký tự 'A' rồi. Vậy có thêm 2 chữ 'A'
=> HTB{A_??????_??B?T?T?T???_??_??A?}.
Đoạn có 2 dấu hỏi chấm thì mình cũng đoán mò, do trong tiếng Anh cũng không nhiều từ có 2 ký tự cho lắm. Dùng thêm cả cấu trúc ngữ pháp tiếng Anh để đoán cho chắc luôn. Ký tự đầu tiên là chữ 'A', vậy theo sau sẽ tạo thành cụm danh từ, mà sau danh từ hoặc cụm danh từ sẽ là động từ hoặc động từ to be. Không thể nghi ngờ gì nữa, chỗ 2 dấu hỏi chấm kia sẽ là động từ to be "IS".
=> HTB{A_SI????_S?BSTIT?TI??_IS_??A?}.
Tiếp theo xin đoán cụm từ thứ 3 trong nội dung Flag là "SUBSTITUTION", thực sự là vừa khít luôn.
=> HTB{A_SI????_SUBSTITUTION_IS_??A?}.
Còn 2 từ nữa để hoàn thành Flag, giờ là lúc thích hợp để sử dụng tà thuật. Mình tình cờ tìm được trang web chuyên hỗ trợ giải đố: http://www.yougowords.com
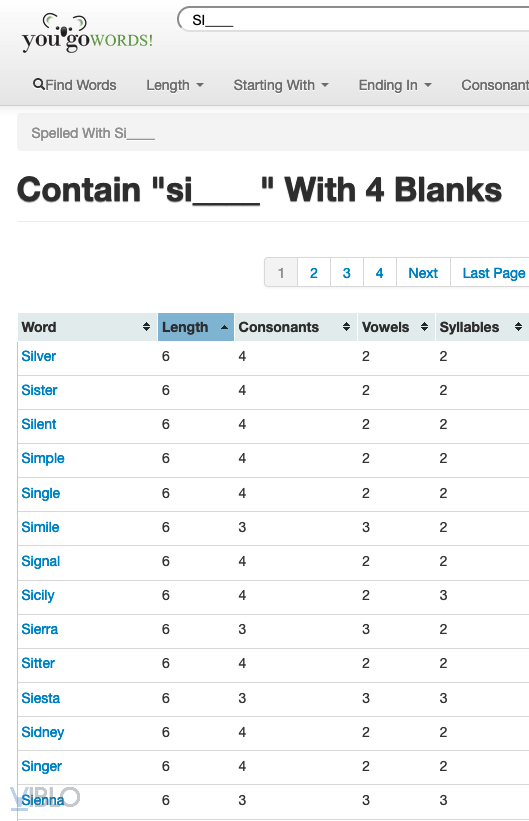
Hmmmm, bắt đầu với "SI" và theo sau là 4 ký tự với tổng độ dài của từ là 6 ký tự. Mọi người biết từ gì sẽ thích hợp trong trường hợp này rồi chứ? Mình thì đoán là "SIMPLE" đấy.
=> HTB{A_SIMPLE_SUBSTITUTION_IS_?EA?}.
Còn duy nhất 2 ký tự cuối trong cụm "?EA?". Đến đây thì thử các từ sao cho có nghĩa là được. 1 người biết tiếng Anh chắc chắn không mất nhiều lần để đoán ra đó là từ "WEAK" đâu nhỉ =)))))
Flag là: HTB{A_SIMPLE_SUBSTITUTION_IS_WEAK}
All rights reserved
